Initiation à la programmation PYTHON pour l’administrateur systèmes#
Accueil des stagiaires#
Présentation du centre de formation
Présentation du formateur
Règles de vie
Individuelles
Collectives
Présentation interactive des stagiaires
Horaires et logistique (pauses, repas, locaux, service administratif, etc.)
Présentation de la formation
Prérequis (Utilisation poste travail Windows ou Unix, savoir installer une application, bases de l’algorithmique et de l’administration systèmes)
Attentes sur la formation
Plan du cours
Présentation et installation des outils du langage#
Approche interactive avec les stagiaires pour créer le groupe.
Avez-vous déjà programmé ? Avez-vous déjà programmé en Python ?Conception et modélisations#
Comment approchez-vous le développement d’une application ?Structure (UML : Visual paradigm, StarUML 3, PyUML pour éclipse, PlantUML pour visual studio, Pynsource, Graphor, Umbrello, le papier et le crayon)
Interactions (Concurrences : SA-RT, logique avec l’algèbre de Boole, etc.)
Données (Sql avec Merise, nosql, bases graphes, etc.)
Optimisations (recettes, patrons de conception, etc.)
Réalités des développeurs#
Développement logiciel (approche produit) : Modélisation conceptuelle vers code.
Développeurs ingénieurs systèmes déploiements/exploitation/matériels (approche opérationnelle) : Fonctions vers code.
Développeur WEB (approche interfaces) : Apparence/Ergonomie vers code.
Bonnes pratiques#
Modèle (données) Vues (interfaces utilisateurs ou applicatives) Contrôleur (opérations entre les données et les interfaces)
Keep It Simple Stupid et «modulaire» (découpage en plus petit programmes ou en objets simples)
Respecter les standards des normes d’interopérabilités (lire les normes), et ne pas réinventer la roue avec le code (voir la catastrophe des clients de messagerie avec maildir et l’obligation de passer par imap pour en avoir les fonctionnalités sur le client MUA).
Maintenabilité et compréhension du code pour les autres (documentation, composants, déploiement, maintenance).
Lire https://www.laurentbloch.org/Data/SI-Projets-extraits/livre008.html pour ceux qui veulent aller plus loin sur le sujet.
Distribuer sous forme papier.Les environnements systèmes#
EnvironnementUNIX/Linux sous Windows#
SSH et Telnet#
Vous pouvez vous connecter à distance avec un terminal texte sur un serveur Unix/Linux en telnet (sans sécurité), ou de façon très sécurisé en ssh en l’installant directement depuis Windows. Ceci est utile si l’on veut dans un environnement Unix/Linux administrer, développer ou faire des tests de qualifications avec une infrastructure proche de celle réelle de production (Modèle V ou DEVOPS).
Serveur X#
Vous pouvez vous connecter à un un client graphique Unix/Linux sous Windows en installant le serveur graphique VcXsrv. Utile si on veut tester des interfaces graphiques Unix/Linux à distance sous Windows ou se connecter en mode graphique sur une application en tant qu’utilisateur Unix/Linux.
RDP#
Unix/Linux supporte l’installation d’un client RDP sur vos serveurs pour se connecter avec une session terminal serveur Windows en tant que client utilisateur Unix graphique.
Nomachine/freenx ou X2GO (optimisation X)#
Un serveur graphique Windows Nomachine ou X2GO doit être installé sous Windows pour avoir une connexion client Unix/Linux graphique.
VNC#
Linux permet aussi le partage de session graphique active d’un utilisateur Unix/Linux. C’est alors l’utilisation d’un serveur Unix/Linux (TightVNC, X11Vnc ou Vino) avec un client VNC à installer sous Windows.
Phase de test de la maîtrise par les stagiaires du poste de travail, et réglages des problèmes techniques des postes de travail. Réglages des problèmes techniques de début de cours.Linux sous Windows#
Lorsque nous souhaitons utiliser Unix/Linux sous Windows pour administrer, développer, tester nous passons habituellement par une solution de virtualisation. Les logiciels Hyper-V ou VirtualBox permettent de virtualiser une distribution Unix/Linux de son choix avec Windows. Néanmoins, Windows 10 permet d’accéder à Linux depuis Windows assez simplement.
Activer le mode développeur de Windows 10#
Avant toutes choses, il convient d’activer le mode développeur dans Windows. Cliquer sur le bouton Démarrer, aller dans Paramètres puis choisissez Mise à jour et sécurité.

Cliquer ensuite sur Pour les développeurs dans la colonne de gauche.
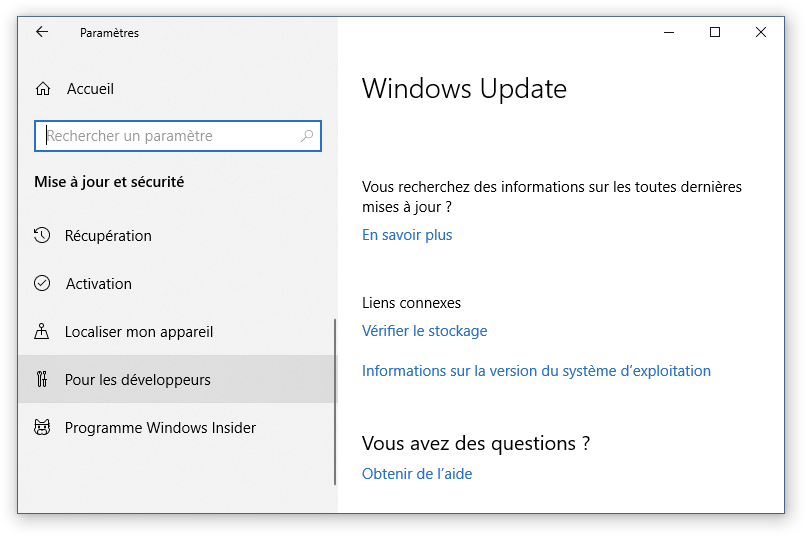
Sélectionner le Mode développeur, une fenêtre vous demandera d’activer le mode développeur :
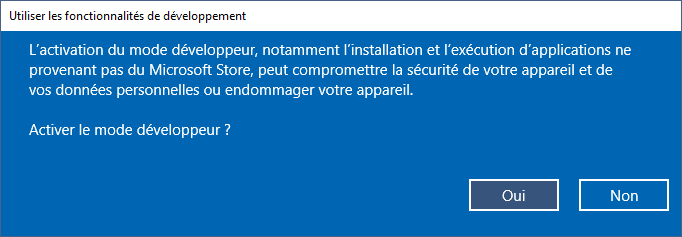
Cliquer sur Oui. La recherche du package en mode développeur débute :
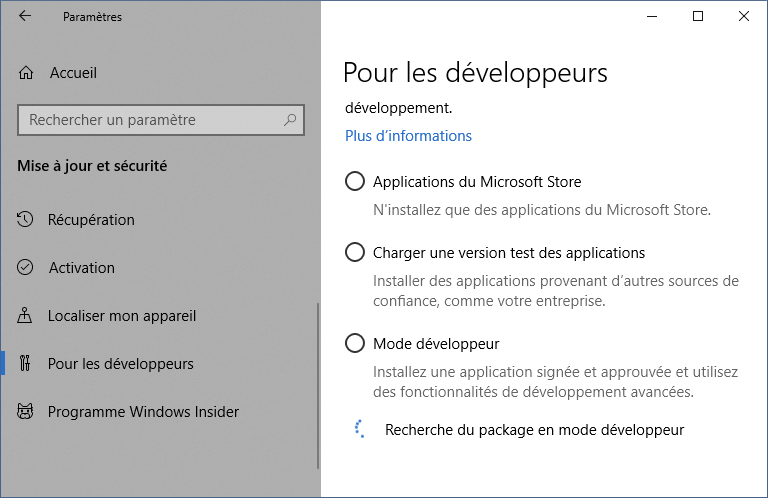
Il vous sera ensuite demandé de redémarrer l’ordinateur. Après le redémarrage, le package en mode développeur est installé et les outils à distance pour le Bureau sont désormais activés.
Installer le sous-système Windows pour Linux#
Nous devons maintenant installer un sous-système Windows pour faire fonctionner Linux. Cliquer sur le bouton Démarrer, Paramètres puis Applications :

Dans la colonne de droite, cliquer sur Programmes et fonctionnalités dans la section Paramètres associés. Dans la colonne de gauche, cliquer sur Activer ou désactiver des fonctionnalités Windows. Cochez l’option Sous-système Windows pour Linux puis cliquer sur le bouton OK.
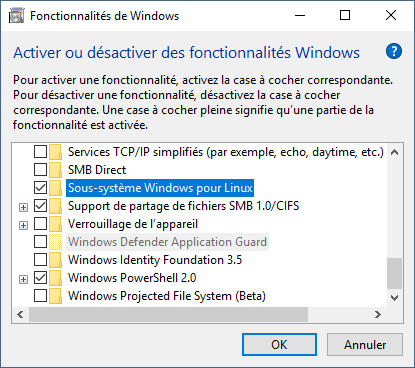
Les fichiers vont être installés, puis Windows vous demande de redémarrer l’ordinateur. Cliquer sur le bouton Redémarrer maintenant.
Choisir une distribution Linux pour Windows#
Nous avons activé le mode développeur et installé le sous-système Windows pour Linux, nous devons maintenant installer une distribution Linux fonctionnant avec Windows 10. Pour lancer Linux, il nous suffira de taper la commande Bash dans le champ de recherche en bas à gauche :
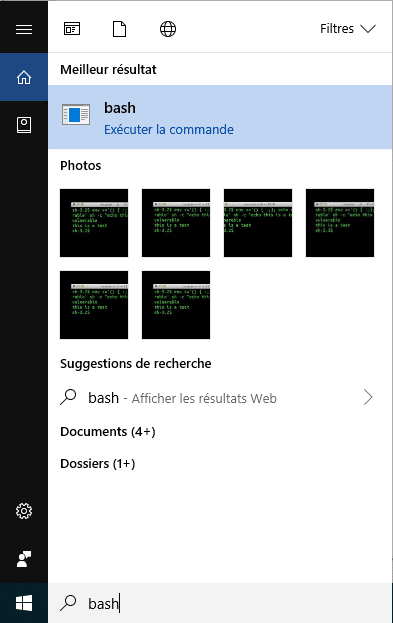
La fenêtre bash.exe s’ouvre alors :

Nous n’avons pas encore installé Linux, mais nous avons le shell Unix Bash sous Windows.
Windows nous invite alors à installer Linux en indiquant un lien. Dans votre navigateur, saisissez alors l’URL https://aka.ms/wslstore. Microsoft Store va alors s’ouvrir et vous demander de choisir votre distribution Linux compatible avec Windows.
Les distributions suivantes sont proposées Ubuntu, Debian, Fedora, openSUSE, SUSE Linux Enterprise Server, Kali Linux, etc.
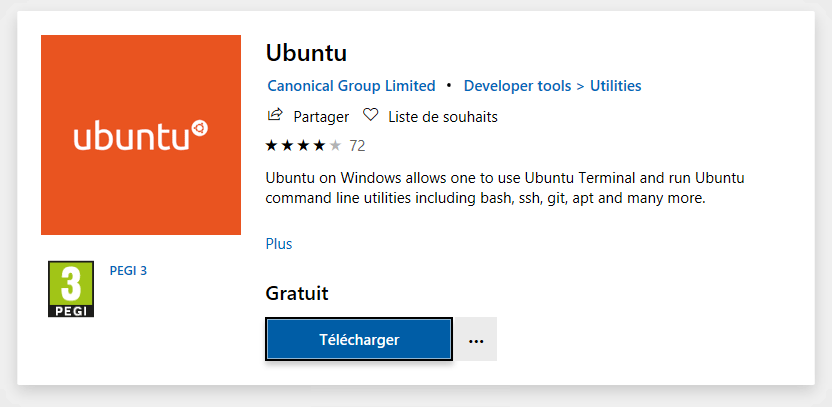
Nous choisissons Ubuntu pour ce cours (plus modèle en V avec une base Debian).
Après avoir cliqué sur Ubuntu, cliquer sur le bouton Télécharger. Après téléchargement et installation, cliquer sur le bouton Lancer.
Installer Linux#
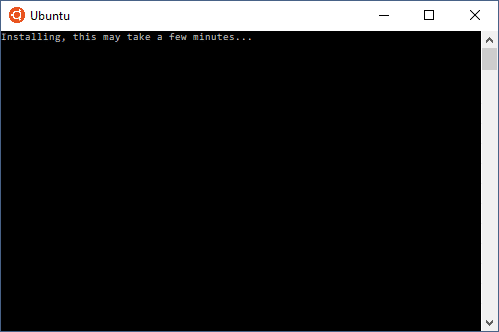
Voilà maintenant votre système Linux prêt à être installé sous Windows.
Lancer à nouveau la commande bash dans le champ de recherche. Le premier lancement permettra d’installer définitivement Ubuntu sous Windows :
Vous devrez alors saisir un login de votre choix ainsi qu’un mot de passe :
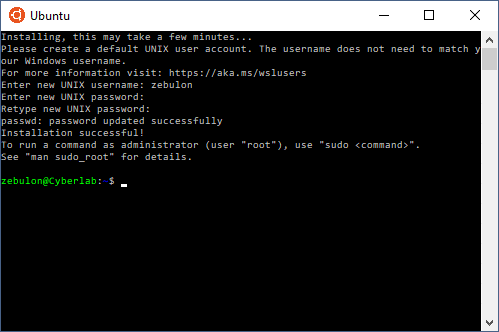
Ubuntu est maintenant prêt à être utilisé en ligne de commande, votre disque dur étant déjà monté.
Environnements Windows sous MAC OS#
PowerShell#
installer PowerShell :
Lancer un shell
$ brew cask install powershell
Enfin, vérifiez que votre installation fonctionne correctement :
$ pwsh
Quand de nouvelles versions de PowerShell sont publiées, mettez à jour les formules de Homebrew et mettez à niveau PowerShell :
$ brew update
$ brew upgrade powershell –cask
Environnements Windows sous Linux#
PowerShell#
PowerShell pour Linux est distribué par Microsoft pour les référentiels de packages afin de faciliter l’installation et les mises à jour à partir de Windows.
utilisateur@MachineUbuntu:~$ sudo snap install --classic powershell
utilisateur@MachineUbuntu:~$ sudo snap remove powershell
La méthode recommandée est la suivante pour une distribution Debian#
Inscrivez le référentiel de logiciels Microsoft pour Ubuntu
Téléchargements des clés de cryptages CPG des dépôts de Microsoft
utilisateur@MachineUbuntu:~$ wget -q
https://packages.microsoft.com/config/ubuntu/21.04/packages-microsoft-prod.deb
Enregistrer ces clés Microsoft dans le répertoire d’installation de logiciels
utilisateur@MachineUbuntu:~$ sudo dpkg -i packages-microsoft-prod.deb
Mise à jour de la liste des logiciels installables
utilisateur@MachineUbuntu:~$ sudo apt update
Installer Powershell
Après l’inscription du dépôt logiciel Microsoft, vous pouvez installer PowerShell
Installation
utilisateur@MachineUbuntu:~$ sudo apt install -y powershell liblttng-ust0 liburcu6 liblttng-ust-ctl4
Démarrer PowerShell
utilisateur@MachineUbuntu:~$ pwsh
PowerShell 7.1.3
Copyright (c) Microsoft Corporation.
https://aka.ms/powershell
Type 'help' to get help.
PS /home/utilisateur> exit
Serveurs RDP (TSE)#
Vous pouvez vous connecter en mode graphique sur un serveur Linux distant en TSE avec le protocole RDP en installant XRDP :
utilisateur@MachineUbuntu:~$ sudo apt install gnome-session gnome-terminal
utilisateur@MachineUbuntu:~$ sudo apt -y install xrdp
utilisateur@MachineUbuntu:~$ sudo systemctl status xrdp
utilisateur@MachineUbuntu:~$ sudo adduser xrdp ssl-cert
Pensez à désinstaller le serveur graphique de vos serveurs Linux de production pour la sécurité (sous Ubuntu sudo apt remove xserver-xorg-video-all ou sudo apt remove xserver-xorg-driver-all)
L’édition de code Python#
L’édition de code est une question d’ergonomie personnelle.
Certains préfèrent la méthode manuelle pour tout contrôler de leur poste de travail (système et comprendre ce qu’ils utilisent et font). Pour ne pas s’enfermer dans un environnement de travail fournisseur logiciel et permettre l’interopérabilité. Ils se tourneront alors vers un éditeur de texte évolué avec des plugins plus ou moins automatisés pour garder le contrôle de leur poste de travail (ingénieurs systèmes).
D’autres adorent l’automatisation de leur production de développement et ne veulent se concentrer que sur le code. Ils se tourneront alors vers un «Integrated Developpement Environnement» le plus intégré que possible et standard (développeurs).
Et encore d’autres aiment s’enferment dans des technologies fournisseurs et se tournent vers des Rapid Application Développement (informatique non cœur de métier) qui ont le défaut de la non optimisation du code et d’être des usines à gaz.
Éditeurs de texte avec coloration syntaxique et plugins (l’IDE c’est le système d’exploitation. Pour les geeks comme moi ;-p)
Idle (IDE minimaliste natif de python)
Pyscripter (IDE gratuit débutants pour Windows)
Eric (IDE purement python)
Éclipse (IDE professionnel industriel avec l’extension PyDev pour le développement Python)
Visual studio (IDE/RAD .Net professionnel Windows avec l’extension PTVS=Python Tools for Visual Studio)
Boaconstructor (RAD Python + wxPython)
Visual python (RAD Python + Tkinter)
Installer un éditeur de code#
Exercice :
Le stagiaire installe l’éditeur de son choix.
Distribuer sous forme papier la procédure pour Visual studio voir https://docs.microsoft.com/fr-fr/visualstudio/python/installing-python-support-in-visual-studio?view=vs-2019
Présentation de Visual studio ?
Distribuer sous forme papier la procédure pour éclipse avec PyDev :
installer https://www.liclipse.com/download.html
Pour éclipse seul voir https://www.eclipse.org/downloads/packages/installer
Pour le plugin voir https://koor.fr/Python/Tutorial/python_ide_pydev.wp
Ou pour les manuels et les pros de l’éditeur texte (allergiques aux IDE et qui veulent contrôler ce qu’il y a sous le capot), installation de notepad++ par exemple https://notepad-plus-plus.org/downloads/.
Interpréteurs#
Python est un langage de haut niveau, c’est à dire que l’on n’a pas à tenir compte des contraintes du système d’exploitation, comme la gestion du matériel ou de la mémoire avec le code par exemple.
Python est un langage interprété, c’est-à-dire que son code pour s’exécuter n’a pas besoin d’être «compilé» (traduit dans le langage machine) pour une architecture matérielle. Il s’exécute avec l’interpréteur Python de l’architecture matérielle.
En tant que langage interprété, lorsque nous installons Python, nous installons un interpréteur.
En réalité Python est un langage semi-interprété, l’interpréteur Python va passer par une étape de compilation qui ne produira pas un code adapté à la machine, mais un code intermédiaire. Souvent appelé byte code, celui-ci sera le code réel interprété par l’interpréteur Python de l’environnement matériel du système d’exploitation.
Il existe de nombreux interpréteurs Python écrits dans différents langages qui fonctionnent sur différentes architectures matérielles et systèmes d’exploitations.
Cpython : L’interpréteur «classique» écrit en C
Pypy : Un interpréteur écrit en… Python
Jython : Un interpréteur écrit en Java qui permet d’accéder en Python aux bibliothèques d’objets Java
IronPython : Un interpréteur écrit en .Net et intégré à Visual Studio
PythonNet (.Net) : Un interpréteur distribué avec vos développements d’applications .Net
Rustpython : Un interpréteur écrit en Rust, langage système bas niveau (comme le C, mais plus moderne et très à la mode actuellement)
etc.
Installer Python#
Exercice :
Distribuer la procédure sous forme papier (Windows, MAC, Linux) https://openclassrooms.com/fr/courses/4262331-demarrez-votre-projet-avec-python/4262506-installez-python
Voir la doc https://docs.python.org/fr/3/using/index.html
Mode Interactif#
On peut essentiellement distinguer trois types d’interpréteurs interactifs Python :
python : l’interpréteur interactif classique et basique intégré à Python.
IPython (intégré avec Jupyter Notebook, le mode ordinateur de présentations scientifiques ou d’Intelligence Artificielle) : Un interpréteur interactif adapté à l’affichage en temps réel de courbes et graphiques dessinés avec Matplotlib.
BPython (le mode test de codes ou d’exposés pédagogiques de codes) : Un interpréteur interactif amélioré grâce à l’utilisation de la coloration syntaxique, la mise à disposition d’un historique des commandes, la complétion automatique, l’auto indentation, etc.
Suivant nos besoins d’utilisation de Python en mode interactif nous pourrons être amenés à évoluer de l’interpréteur python classique vers un des deux autres types (IPython ou BPython).
Exercice :
utilisateur@MachineUbuntu:~$ python3
Python 3.9.4 (default, Apr 4 2021, 19:38:44)
[GCC 10.2.1 20210401] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> help()
Welcome to Python 3.9's help utility!
If this is your first time using Python, you should definitely check out
the tutorial on the Internet at https://docs.python.org/3.8/tutorial/.
Enter the name of any module, keyword, or topic to get help on writing
Python programs and using Python modules. To quit this help utility and
return to the interpreter, just type "quit".
To get a list of available modules, keywords, symbols, or topics, type
"modules", "keywords", "symbols", or "topics". Each module also comes
with a one-line summary of what it does; to list the modules whose name
or summary contain a given string such as "spam", type "modules spam".
help> quit
You are now leaving help and returning to the Python interpreter.
If you want to ask for help on a particular object directly from the
interpreter, you can type "help(object)". Executing "help('string')"
has the same effect as typing a particular string at the help> prompt.
>>> help(quit)
Help on Quit in module _sitebuiltins object:
class Quit(builtins.object)
| Quit(name, eof)
|
| Methods defined here:
|
| __call__(self, code=None)
| Call self as a function.
|
| __init__(self, name, eof)
| Initialize self. See help(type(self)) for accurate signature.
|
| __repr__(self)
| Return repr(self).
|
|
| Data descriptors defined here:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
(END)
q
>>> quit()
Les mots clé#
Les fonctions de base de Python#
Mode interprété#
Exercice :
Créer le répertoire répertoire_de_développement :
utilisateur@MachineUbuntu:~$ mkdir -p repertoire_de_developpement/1_Mode_interprété; cd repertoire_de_developpement/1_Mode_interprété
Créer dans ce répertoire le fichier mon_1er_programme.py avec l’éditeur de code choisi, et le modifier comme suit :
1#! /usr/bin/env python3
2# -*- coding: utf8 -*-
3
4print('Bonjour à toutes et tous !')
Le shebang, représenté par #!, c’est un en-tête d’un fichier texte qui indique au système d’exploitation (de type Unix) que ce fichier n’est pas un fichier binaire mais un script (ensemble de commandes) ; sur la même ligne est précisé l’interpréteur permettant d’exécuter ce script.
Exécuter le programme :
utilisateur@MachineUbuntu:~/repertoire_de_developpement/1_Mode_interprété$ python3 mon_1er_programme.py
Ou sur Unix le rendre exécutable (chmod u+x) et le lancer en ligne de commande comme une simple application :
utilisateur@MachineUbuntu:~/repertoire_de_developpement/1_Mode_interprété$ chmod u+x mon_1er_programme.py ; ./mon_1er_programme.py
Conversion Python 2 vers Python 3#
$ python2.7
Python 2.7.18 (default, Sep 5 2020, 11:17:26)
[GCC 10.2.0] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> type('chaine') # bits => encodée
<type 'str'>
>>> type(u'chaine') # unicode => décodée
<type 'unicode'>
$ python3
Python 3.8.5 (default, Sep 5 2020, 10:50:12)
[GCC 10.2.0] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> type("chaine") # unicode => decodée
<class 'str'>
>>> type(b"chaine") # bits => encodée
<class 'bytes'>
Votre but, c’est de n’avoir dans votre code que des chaînes de type ‘unicode’.
En Python 3, c’est automatique. Toutes les chaînes sont de type ‘unicode’ (appelé ‘str’ dans cette version) par défaut. En Python 2 en revanche, il faut préfixer la chaîne par un u pour avoir de l’unicode.
Python 2 vient de prendre fin le 1er janvier 2020.
Donc si vous utilisez un interpréteur Python 2, dans votre code, TOUTES vos chaînes unicode doivent être déclarées ainsi :
u"votre chaîne"
Si vous voulez, vous pouvez activer le comportement de Python 3 dans Python 2 en mettant ceci au début de CHACUN de vos modules pour vous aider à migrer vos scripts et programmes :
from __future__ import unicode_literals
Ceci n’affecte que le fichier en cours, jamais les autres modules. On peut également le mettre au démarrage d’iPython.
Résumé pour migrer Python 2 :
Réglez votre éditeur sur UTF8.
Mettez # coding: utf8 au début de vos modules.
Préfixez toutes vos chaînes de u ou faites
from __future__ import unicode_literalsen début de chaque module.
Si vous ne faites pas cela, votre code marchera uniquement avec Python 2. Et un jour, quand Python 2 ne pourra plus être déployer, il ne marchera plus. Plus du tout.
Donner sous forme papier http://sametmax.com/lencoding-en-python-une-bonne-fois-pour-toute/ si besoins de migrations de python2 vers python3
Mode Compilé#
La compilation en python existe, c’est «Cython» ou «LPython».
Révision de code#
Lorsque l’on développe un logiciel, ce dernier est voué à évoluer. On ne part malheureusement pas de l’idée pour aboutir immédiatement au programme fini.
Même si les spécifications sont précises, il y aura toujours de petits bugs à corriger et donc des lignes de codes seront modifiées, supprimées ou ajoutées. Mais que se passe-t-il lorsque plusieurs développeurs travaillent sur le même fichier ou programme, ou lorsqu’une correction n’en est pas une et qu’il faut revenir en arrière ?
C’est là qu’interviennent les logiciels de gestion de versions concurrentes, vision collective, ou de révision de code, vision individuelle.
Git : le standard de fait en mode décentralisé.
Visualsource : celui de Microsoft
Bazaar
Mercurial
dinosaures (rcs, svn) etc.
Installer un logiciel de révision de code sur le poste de développement#
Exercice :
Distribuer procédure installation de git voir https://openclassrooms.com/fr/courses/5641721-utilisez-git-et-github-pour-vos-projets-de-developpement/6113016-installez-git-sur-votre-ordinateur
Documentation voir https://git-scm.com/book/fr/v2
Installer git#
utilisateur@MachineUbuntu:~/repertoire_de_developpement/1_Mode_interprété$ cd .. ; sudo apt update; sudo apt upgrade
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo apt install git
Configurer git#
Récupérer le fichier github/gitignore et le renommer en .gitignore dans le répertoire :
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ wget https://raw.githubusercontent.com/github/gitignore/master/Python.gitignore ; mv Python.gitignore .gitignore
Ajouter en début de fichier de .gitignore :
# Ignore itself
.gitignore
Mettre en place la coloration syntaxique dans git :
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git config --global color.ui auto
Définir l’utilisateur de git avec son adresse courriel :
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git config --global user.name "Prénom NOM"
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git config --global user.email "utilisateur@domaine-perso.fr"
Configurer les paramètres de la sauvegarde des identifiants de connections aux dépôts distants :
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git config --global http.sslVerify false
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git config --global http.postBuffer 524288000
Initialiser le dépôt git et ajouter le fichier Python «mon_1er_programme.py» :
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git init
…
Dépôt Git vide initialisé dans /home/utilisateur/repertoire_de_developpement/.git/
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git status
Sur la branche master
Aucun commit
Fichiers non suivis:
(utilisez "git add <fichier>…" pour inclure dans ce qui sera validé)
"1_Mode_interpr\303\251t\303\251/"
aucune modification ajoutée à la validation mais des fichiers non suivis sont présents (utilisez "git add" pour les suivre)
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git add .
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git status
Sur la branche master
Aucun commit
Modifications qui seront validées :
(utilisez "git rm --cached <fichier>…" pour désindexer)
nouveau fichier : "1_Mode_interpr\303\251t\303\251/mon_1er_programme.py"
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git commit -m "Ajout du fichier mon_1er_programme.py"
[master (commit racine) dd36b76] Ajout du fichier mon_1er_programme.py
1 file changed, 4 insertions(+)
create mode 100755 "1_Mode_interpr\303\251t\303\251/mon_1er_programme.py"
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git status
Sur la branche master
rien à valider, la copie de travail est propre
Environnement virtuel PYTHON 3#
L’ensemble des paquets Python installés par votre distribution, dans votre système Linux, a été bien testé par les intégrateurs de la distribution. Il faut donc autant que possible installer les outils/bibliothèques Python avec les outils d’administration des paquets de votre système pour vos applications informatiques Python du poste de travail .
L’installation de paquets Python par l’intermédiaire d’outils tierces risque de casser cet écosystème système bien testé.
Lorsque l’on fait du développement le besoin d’ajouter des paquets d’outils/bibliothèques Python au delà de votre système d’exploitation est une nécessité. C’est votre projet de programmation Python qui l’impose.
Donc l’utilisation de ces outils/bibliothèques sont propre à vos projets de développements Python. Ils peuvent alors rentrer en conflit de versions avec les applications Python de votre système Linux, Mac, Windows ou autres.
Afin d’isoler ces ajouts d’outils/bibliothèques du système de votre environnement poste de travail, nous allons créer pour vos projets des environnements virtuels de développement Python, avec des outils et des bibliothèques propre à ces environnements.
venv#
C’est l’environnement virtuel standard de Python. Pour l’installer :
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo apt install -y python3-venv python3-pip
Création de l’environnement virtuel Python :
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ python3 -m venv .env
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ source .env/bin/activate
(.env) utilisateur@MachineUbuntu:~/repertoire_de_developpement$ deactivate
L’application pip servira alors d’outil d’installation des outils et bibliothèque Python pour ces environnements virtuels.
pipenv#
Installation de pipenv :
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo apt install pipenv
Création de l’environnement virtuel Python :
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ pipenv shell
Creating a virtualenv for this project…
Using /usr/bin/python3 (3.9.4) to create virtualenv…
⠋created virtual environment CPython3.9.4.final.0-64 in 232ms creator
CPython3Posix(dest=/home/utilisateur/.local/share/virtualenvs/repertoire_de_developpement-hIqPJnF9, clear=False, no_vcs_ignore=False, global=False)
seeder FromAppData(download=False, pip=bundle, setuptools=bundle, wheel=bundle, via=copy, app_data_dir=/home/utilisateur/.local/share/virtualenv)
added seed packages: pip==20.3.4, pkg_resources==0.0.0, setuptools==44.1.1, wheel==0.34.2
activators BashActivator,CShellActivator,FishActivator,PowerShellActivator,PythonActivator,XonshActivator
Virtualenv location: /home/utilisateur/.local/share/virtualenvs/repertoire_de_developpement-hIqPJnF9
Creating a Pipfile for this project…
Spawning environment shell (/bin/bash). Use 'exit' to leave.
(repertoire_de_developpement-hIqPJnF9) utilisateur@MachineUbuntu:~/repertoire_de_developpement$ exit
Documentation#
Documenter le code (annotations des variables, docstring)
Génération de la documentation (Sphinx, doxygen, docutil, pdoc3, pydoctor, etc.)
Syntaxes (restructured text, markdown, asciidoc, mediawiki, html, etc.)
Nous reviendrons plus tard dans ce cours sur l’utilisation de la documentation dans Python.
Mise en place du système de documentation du code, architecture et scripts (Sphinx).
Installer les logiciels de la documentation :
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ source .env/bin/activate
(.env) utilisateur@MachineUbuntu:~/repertoire_de_developpement$ pip install sphinx sphinx-intl
Créer la documentations :
(.env) utilisateur@MachineUbuntu:~/repertoire_de_developpement$ mkdir docs; cd docs
(.env) utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ sphinx-quickstart
Bienvenue dans le kit de démarrage rapide de Sphinx 3.2.1.
Please enter values for the following settings (just press Enter to
accept a default value, if one is given in brackets).
Selected root path: .
You have two options for placing the build directory for Sphinx output.
"source" and "build" directories within the root path.
> Séparer les répertoires build et source (y/n) [n]: y
The project name will occur in several places in the built documentation.
> Nom du projet: Documentation sur l’initiation à la programmation Python pour l’administrateur systèmes
> Nom(s) de l\'auteur: Prénom NOM
> version du projet []:
If the documents are to be written in a language other than English,
you can select a language here by its language code. Sphinx will then
translate text that it generates into that language.
For a list of supported codes, see https://www.sphinx-doc.org/en/master/usage/configuration.html#confval-language.
> Langue du projet [en]: fr
Fichier en cours de création /home/utilisateur/repertoire_de_developpement/docs/source/conf.py.
Fichier en cours de création /home/utilisateur/repertoire_de_developpement/docs/source/index.rst.
Fichier en cours de création /home/utilisateur/repertoire_de_developpement/docs/Makefile.
Fichier en cours de création /home/utilisateur/repertoire_de_developpement/docs/make.bat.
Terminé : la structure initiale a été créée.
You should now populate your master file /home/utilisateur/repertoire_de_developpement/docs/source/index.rst and create other documentation
source files. Use the Makefile to build the docs, like so:
make builder
where "builder" is one of the supported builders, e.g. html, latex or linkcheck.
(.env) utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ rmdir build ; mv source sources-documents
modifier les fichiers «Makefile» et «make.bat», dans lesquels il faudra adapter le contenu de la variable «SOURCEDIR».
Makefile :
SOURCEDIR = sources-documents
BUILDDIR = documentation
make.bat :
set SOURCEDIR=sources-documents
set BUILDDIR=documentation
Pour générer la doc sous Linux, c’est très simple, il suffit d’ouvrir un terminal dans le dossier du projet et de taper la commande suivante :
(.env) utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ make html ; cd ..
(.env) utilisateur@MachineUbuntu:~/repertoire_de_developpement$ deactivate
Si vous n’avez pas la commande make, il vous faudra l’installer. Ça peut se faire avec la commande suivante si vous utilisez Debian, Ubuntu ou l’un de leurs dérivés :
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ sudo apt install build-essential
Si vous êtes sous Windows et que vous utilisez Git Bash, il vous faudra utiliser la commande suivante pour générer votre documentation :
$ ./make.bat html
Voir la documentation générée «…/repertoire_de_developpement/docs/documentation/html/index.html» avec un navigateur web.
Sauvegarder la structure de documentation#
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git add .
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git status
Sur la branche master
Votre branche est à jour avec 'origin/master'.
Modifications qui seront validées :
(utilisez "git restore --staged <fichier>..." pour désindexer)
nouveau fichier : docs/Makefile
nouveau fichier : docs/documentation/doctrees/environment.pickle
nouveau fichier : docs/documentation/doctrees/index.doctree
nouveau fichier : docs/documentation/html/.buildinfo
nouveau fichier : docs/documentation/html/_sources/index.rst.txt
nouveau fichier : docs/documentation/html/_static/_stemmer.js
nouveau fichier : docs/documentation/html/_static/alabaster.css
nouveau fichier : docs/documentation/html/_static/basic.css
nouveau fichier : docs/documentation/html/_static/custom.css
nouveau fichier : docs/documentation/html/_static/doctools.js
nouveau fichier : docs/documentation/html/_static/documentation_options.js
nouveau fichier : docs/documentation/html/_static/file.png
nouveau fichier : docs/documentation/html/_static/jquery-3.5.1.js
nouveau fichier : docs/documentation/html/_static/jquery.js
nouveau fichier : docs/documentation/html/_static/language_data.js
nouveau fichier : docs/documentation/html/_static/minus.png
nouveau fichier : docs/documentation/html/_static/plus.png
nouveau fichier : docs/documentation/html/_static/pygments.css
nouveau fichier : docs/documentation/html/_static/searchtools.js
nouveau fichier : docs/documentation/html/_static/translations.js
nouveau fichier : docs/documentation/html/_static/underscore-1.3.1.js
nouveau fichier : docs/documentation/html/_static/underscore.js
nouveau fichier : docs/documentation/html/genindex.html
nouveau fichier : docs/documentation/html/index.html
nouveau fichier : docs/documentation/html/objects.inv
nouveau fichier : docs/documentation/html/search.html
nouveau fichier : docs/documentation/html/searchindex.js
nouveau fichier : docs/make.bat
nouveau fichier : docs/sources-documents/conf.py
nouveau fichier : docs/sources-documents/index.rst
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git commit -m "Structure de la documentation du projet"
[master 31c720b] Structure de la documentation du projet
31 files changed, 17692 insertions(+)
create mode 100644 docs/Makefile
create mode 100644 docs/documentation/doctrees/environment.pickle
create mode 100644 docs/documentation/doctrees/index.doctree
create mode 100644 docs/documentation/html/.buildinfo
create mode 100644 docs/documentation/html/_sources/index.rst.txt
create mode 100644 docs/documentation/html/_static/alabaster.css
create mode 100644 docs/documentation/html/_static/base-stemmer.js
create mode 100644 docs/documentation/html/_static/basic.css
create mode 100644 docs/documentation/html/_static/custom.css
create mode 100644 docs/documentation/html/_static/doctools.js
create mode 100644 docs/documentation/html/_static/documentation_options.js
create mode 100644 docs/documentation/html/_static/file.png
create mode 100644 docs/documentation/html/_static/french-stemmer.js
create mode 100644 docs/documentation/html/_static/jquery-3.5.1.js
create mode 100644 docs/documentation/html/_static/jquery.js
create mode 100644 docs/documentation/html/_static/language_data.js
create mode 100644 docs/documentation/html/_static/minus.png
create mode 100644 docs/documentation/html/_static/plus.png
create mode 100644 docs/documentation/html/_static/pygments.css
create mode 100644 docs/documentation/html/_static/searchtools.js
create mode 100644 docs/documentation/html/_static/translations.js
create mode 100644 docs/documentation/html/_static/underscore-1.12.0.js
create mode 100644 docs/documentation/html/_static/underscore.js
create mode 100644 docs/documentation/html/genindex.html
create mode 100644 docs/documentation/html/index.html
create mode 100644 docs/documentation/html/objects.inv
create mode 100644 docs/documentation/html/search.html
create mode 100644 docs/documentation/html/searchindex.js
create mode 100644 docs/make.bat
create mode 100644 docs/sources-documents/conf.py
create mode 100644 docs/sources-documents/index.rst
Débogages#
Si vous avez un bogue non banal, c’est là que les stratégies de débogage vont rentrer en ligne de compte. Le problème doit être isolé dans un petit nombre de lignes de code, hors frameworks ou code applicatif.
Pour déboguer un problème donné :
Faites échouer le code de façon fiable : trouvez un cas de test qui fait échouer le code à chaque fois.
Diviser et conquérir : une fois que vous avez un cas de test échouant, isolez le code coupable.
Quel module.
Quelle fonction.
Quelle ligne de code.
Isolez une petite erreur reproductible (permet de définir un cas de test à implémenter).
Changez une seule chose à chaque fois, l’archiver dans la révision de code, et ré-exécutez le cas de test d’échec.
Utilisez le débogueur (pour Python pdb) pour comprendre ce qui ne va pas.
Prenez des notes et soyez patient, ça peut prendre un moment.
Une fois que vous avez procédé à cette étape, isolez un petit bout de code reproduisant le bogue et corrigez celui-ci en utilisant ce bout de code, ajoutez le code de test dans votre suite de test (Unittest).
Le débogueur Python pdb#
Installation de pdb#
utilisateur@MachineUbuntu:~/repertoire_de_developpement$sudo apt install python3-ipdb
Déboguer avec pdb#
Les façons de lancer le débogueur :
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ mkdir 2_Debug ; cd 2_Debug
Créer le fichier «error.py» dans le dossier «repertoire_de_developpement/2_Debug»
1#! /usr/bin/env python3
2# -*- coding: utf8 -*-
3
4dividende = 5
5nombres = [5, 4, 3, 2, 1, 0]
6for diviseur in nombres:
7 print('Valeur du rapport : %s' % (dividende/diviseur))
Postmortem#
pdb est invoqué (exécuté) pour déboguer un script.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/2_Debug$ python3 -m pdb error.py
>/home/utilisateur/repertoire_de_developpement/2_Debug/error.py(4)<module>()
-> dividende = 5
(pdb) q
Pour arrêter le débogage (prompt pdb) tapez q.
Lancez le module avec le débogueur#
utilisateur@MachineUbuntu:~/repertoire_de_developpement/2_Debug$ ipython3 error.py
ou
utilisateur@MachineUbuntu:~/repertoire_de_developpement/2_Debug$ ipython3
In [1]:%run error.py
pour sortir du débogueur (prompt In [num]:%) tapez quit.
Exécution pas à pas du débogueur#
utilisateur@MachineUbuntu:~/repertoire_de_developpement/2_Debug$ ipython3 -c '%run -d error.py'
ou
utilisateur@MachineUbuntu:~/repertoire_de_developpement/2_Debug$ ipython3
In [1]: %run -d error.py
Continuez dans le code avec n(ext), next saute à la prochaine déclaration de code dans le contexte d’exécution courant :
ipdb> n
Placez un point d’arrêt à la ligne 7 en utilisant b 7 :
ipdb> b 7
Continuez l’exécution jusqu’au prochain point d’arrêt avec c(ontinue) :
ipdb> c
Continuez dans le code avec s(tep), step va traverser les contextes d’exécution, c’est-à-dire permettre l’exploration à l’intérieur des appels de fonction :
ipdb> s
Visualiser l’état d’une variable avec print() :
ipdb> print(diviseur)
Arrêter le débogage :
ipdb> q
Quitter le débogueur :
In [3]: quit
Appeler le débogueur à l’intérieur du module#
import pdb; pdb.set_trace()
Les commandes du débogueur#
l (list) |
Liste le code à la position courante |
u(p) |
Monte à la pile d’appel |
d(own) |
Descend à la pile d’appel |
n(ext) |
Exécute la prochaine ligne (ne va pas à l’intérieur d’une nouvelle fonction) |
s(tep) |
Exécute la prochaine déclaration (va à l’intérieur d’une nouvelle fonction) |
bt |
Affiche la pile d’appel |
a |
Affiche les variables locales |
!command |
Exécute la commande Python donnée (par opposition à une commande pdb) |
utilisateur@MachineUbuntu:~/repertoire_de_developpement/2_Debug$ cd ..
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git add .
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git commit -m "Ajout des exemples de débogages"
La Gestion des Warnings d’exécution#
Attention cet exemple fonctionne jusqu’à Python 3.9. Pour les versions postérieures les modules obsolètes hérités de Python2 ne sont plus pris en charge.
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ mkdir 3_Interpreteur_alerts ; cd 3_Interpreteur_alerts
Créer le fichier «monscript.py» dans le dossier «repertoire_de_developpement/3_Interpreteur_alerts»
1#! /usr/bin/env python3
2# -*- coding: utf8 -*-
3
4import formatter
5
6print('Bonjour %s' % 'Moi')
Exécution de python avec les Warnings :
python3 -Wd monscript.py
utilisateur@MachineUbuntu:~/repertoire_de_developpement/3_Interpreteur_alerts$ python3 -Wd monscript.py
monscript.py:4: DeprecationWarning: the formatter module is deprecated
import formatter
Bonjour Moi
Pour l’activer par défaut pour toutes les alertes :
python3 -Wa
À chaque mise à jour de version de python, pour son code il est important de vérifier les warnings.
Ceux-ci nous informe de l’obsolescence des bibliothèques ou des fonctions de python que nous utilisons. Cela permet de préparer et corriger le code python de nos applications développées pour les migrations futures de vos systèmes informatiques et de leurs bibliothèques/frameworks.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/3_Interpreteur_alerts$ cd ..
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git add .
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git commit -m "Ajout des exemples de warnings d’exécution"
Tests Unitaires#
Tests unitaires en python (Unittest et doctest)
Frameworks de tests (Unittest, Robot, Pytest, Doctest, Nose2, Testify)
Les tests unitaires permettent de vérifier (tester) des éléments particuliers d’un programme.
Par exemple si un programme contient plusieurs parties de code autonome, les tests unitaires permettront de vérifier leurs présences, le fonctionnement de chacune des parties suivant un comportement attendu.
La mise en place de tests unitaires permet de s’assurer que la correction de bugs, ou le développement de nouvelles fonctions, n’entraînera pas de régressions au niveau du code.
Nous verrons ultérieurement au cours de cette formation le module Python Unittest
Architecture des tests
Les valeurs de retour des tests
Les différents tests de Unittest
Exécution de l’ensemble des tests
Mise en place de l’infrastructure, créer le répertoire tests :
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ mkdir tests ; touch tests/README.md
Contenu du fichier «README.md»
1# Tests unitaires du code Python
Sauvegarder la structure de tests#
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git add .
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git status
Sur la branche master
Votre branche est à jour avec 'origin/master'.
Modifications qui seront validées :
(utilisez "git restore --staged <fichier>..." pour désindexer)
nouveau fichier : tests/README.md
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git commit -m "Ajout de la structure de tests"
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ cd ..
L’industrialisation du code DEVOPS#
Gitlabs
Github/Azure
BitbucketInstaller l’infrastructure DEV/OPS
Nous allons installer GitLab avec Docker. De plus, nous utiliserons Ubuntu 21.04 comme système d’exploitation principal.
Prérequis:
Serveur Ubuntu 21.04
Min 4 Go de RAM
Privilèges root
Qu’allons nous faire?
Configurer le DNS local
Installer Docker
Tester Docker
Installer Gitlab
Configurer et tester Gitlab
Autorisations pour Docker et le Runner
Configurer et tester le Runner
Tester les Pages de Gitlab
Configurer le DNS local#
Vous avez besoin d’un nom de domaine avec un enregistrement A valide pointant vers votre serveur GitLab.
Installer une interface réseau virtuelle#
Éditer «/etc/systemd/network/10-virtualeth0.netdev»
1[NetDev]
2Name = virtualeth0
3Kind = dummy
Éditer «/etc/systemd/network/10-virtualeth0.network»
1[Match]
2Name = virtualeth0
3
4[Network]
5Address = 10.10.10.1/24
6Address = fd00::/8
utilisateur@MachineUbuntu:~$ sudo systemctl start systemd-networkd
utilisateur@MachineUbuntu:~$ sudo systemctl enable systemd-networkd
utilisateur@MachineUbuntu:~$ ip a
…
3: virtualeth0: <BROADCAST,NOARP,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether 9a:3c:56:42:f5:c9 brd ff:ff:ff:ff:ff:ff
inet 10.10.10.1/24 brd 10.10.10.255 scope global virtualeth0
valid_lft forever preferred_lft forever
inet6 fd00::/8 scope global
valid_lft forever preferred_lft forever
inet6 fe80::983c:56ff:fe42:f5c9/64 scope link
valid_lft forever preferred_lft forever
…
Configuration du client dhcp adaptée au DNS local#
Pour pouvoir ajouter le serveur DNS local à «/etc/resolv.conf» il faut renseigner l’option «prepend» qui permet l’ajout du serveur DNS local en début de la liste des serveurs DNS fournit automatiquement par DHCP.
Éditer «/etc/dhcp/dhclient.conf»
prepend domaine-perso.fr 10.10.10.1 fd00::
Vérifier les DNS présents :
utilisateur@MachineUbuntu:~$ nmcli dev show | grep DNS
IP4.DNS[1]: yyy.yyy.yyy.yyy
IP4.DNS[1]: yyy.yyy.yyy.yyy
IP6.DNS[1]: yyyy:yyyy:yyyy::yyyy
IP6.DNS[2]: yyyy:yyyy:yyyy::yyyy
IP6.DNS[3]: yyyy:yyyy:yyyy::yyyy
utilisateur@MachineUbuntu:~$ resolvectl dns
Global:
Link 2 (enp0sxx):
Link 3 (wlx803xxxxx): yyyy:yyyy:yyyy::yyyy yyyy:yyyy:yyyy::yyyy yyyy:yyyy:yyyy::yyyy yyy.yyy.yyy.yyy
Link 4 (wlo1): yyy.yyy.yyy.yyy
Link 6 (virtualeth0):
Définir le domaine local de la machine Ubuntu#
utilisateur@MachineUbuntu:~$ sudo hostnamectl set-hostname MachineUbuntu.domaine-perso.fr --static
utilisateur@MachineUbuntu:~$ hostname -d
domaine-perso.fr
Installer les applications de base#
utilisateur@MachineUbuntu:~$ sudo apt install bind9 bind9utils bind9-dnsutils bind9-doc bind9-host net-tools
utilisateur@MachineUbuntu:~$ sudo systemctl status named
utilisateur@MachineUbuntu:~$ sudo systemctl enable named
Configuration du DNS local#
Éditer «/etc/bind/named.conf.options»
options {
directory "/var/cache/bind";
// Pour des raisons de sécurité.
// Cache la version du serveur DNS pour les clients.
version "Pas pour les crackers";
listen-on { 127.0.0.1; 10.10.10.1; };
listen-on-v6 { ::1; fd00::; };
allow-query { 127.0.0.1; 10.10.10.1; ::1; fd00::; };
// Optionnel - Comportement par défaut de BIND en récursions.
recursion yes;
// Récursions autorisées seulement pour les interfaces clients
allow-recursion { 127.0.0.1; 10.10.10.0/24; ::1; fd00::/8; };
dnssec-validation auto;
// Activer la journalisation des requêtes DNS
querylog yes;
};
Vérifier la validité de la configuration, et redémarrer le serveur DNS si la configuration est OK.
utilisateur@MachineUbuntu:~$ sudo named-checkconf
utilisateur@MachineUbuntu:~$ sudo systemctl restart named
Ajout du server DNS local à la liste des serveurs DNS de systemd-resolved.
Éditer «/etc/systemd/resolved.conf»
DNS=10.10.10.1 fd00::
utilisateur@MachineUbuntu:~$ sudo systemctl restart systemd-resolved
utilisateur@MachineUbuntu:~$ nmcli general reload
Tests du serveur DNS#
Vérifications du serveur#
utilisateur@MachineUbuntu:~$ sudo rndc status
version: BIND 9.16.8-Ubuntu (Stable Release) <id:539f9f0> (Pas pour les crackers)
running on MachineUbuntu.domaine-perso.fr: Linux x86_64 5.11.0-31-generic #33-Ubuntu SMP Wed Aug 11 13:19:04 UTC 2021
boot time: Thu, 26 Aug 2021 06:13:19 GMT
last configured: Thu, 26 Aug 2021 06:13:19 GMT
configuration file: /etc/bind/named.conf
CPUs found: 4
worker threads: 4
UDP listeners per interface: 4
number of zones: 102 (97 automatic)
debug level: 0
xfers running: 0
xfers deferred: 0
soa queries in progress: 0
query logging is ON
recursive clients: 0/900/1000
tcp clients: 0/150
TCP high-water: 0
server is up and running
Vérifier le fonctionnement de bind sur le port 53
utilisateur@MachineUbuntu:~$ sudo lsof -i:53
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
named 5624 bind 37u IPv4 54315 0t0 UDP localhost:domain
named 5624 bind 38u IPv4 54316 0t0 UDP localhost:domain
named 5624 bind 39u IPv4 54317 0t0 UDP localhost:domain
named 5624 bind 40u IPv4 54318 0t0 UDP localhost:domain
named 5624 bind 42u IPv4 51987 0t0 TCP localhost:domain (LISTEN)
named 5624 bind 43u IPv4 54319 0t0 UDP MachineUbuntu.domaine-perso.fr:domain
named 5624 bind 44u IPv4 54320 0t0 UDP MachineUbuntu.domaine-perso.fr:domain
named 5624 bind 45u IPv4 54321 0t0 UDP MachineUbuntu.domaine-perso.fr:domain
named 5624 bind 46u IPv4 54322 0t0 UDP MachineUbuntu.domaine-perso.fr:domain
named 5624 bind 47u IPv4 51988 0t0 TCP MachineUbuntu.domaine-perso.fr:domain (LISTEN)
named 5624 bind 48u IPv6 54323 0t0 UDP ip6-localhost:domain
named 5624 bind 49u IPv6 54324 0t0 UDP ip6-localhost:domain
named 5624 bind 50u IPv6 54325 0t0 UDP ip6-localhost:domain
named 5624 bind 51u IPv6 54326 0t0 UDP ip6-localhost:domain
named 5624 bind 52u IPv6 51989 0t0 TCP ip6-localhost:domain (LISTEN)
named 5624 bind 53u IPv6 54327 0t0 UDP MachineUbuntu.domaine-perso.fr:domain
named 5624 bind 54u IPv6 54328 0t0 UDP MachineUbuntu.domaine-perso.fr:domain
named 5624 bind 55u IPv6 54329 0t0 UDP MachineUbuntu.domaine-perso.fr:domain
named 5624 bind 56u IPv6 54330 0t0 UDP MachineUbuntu.domaine-perso.fr:domain
named 5624 bind 58u IPv6 54331 0t0 TCP MachineUbuntu.domaine-perso.fr:domain (LISTEN)
systemd-r 5799 systemd-resolve 12u IPv4 52844 0t0 UDP localhost:domain
systemd-r 5799 systemd-resolve 13u IPv4 52845 0t0 TCP localhost:domain (LISTEN)
Vérifier l’écoute réseau sur le port 53
utilisateur@MachineUbuntu:~$ sudo netstat -alnp | grep -i :53
tcp 0 0 127.0.0.53:53 0.0.0.0:* LISTEN 5799/systemd-resol
tcp 0 0 127.0.0.1:53 0.0.0.0:* LISTEN 5624/named
tcp 0 0 10.10.10.1:53 0.0.0.0:* LISTEN 5624/named
tcp6 0 0 fd00:::53 :::* LISTEN 5624/named
tcp6 0 0 ::1:53 :::* LISTEN 5624/named
udp 0 0 127.0.0.53:53 0.0.0.0:* 5799/systemd-resol
udp 0 0 127.0.0.1:53 0.0.0.0:* 5624/named
udp 0 0 10.10.10.1:53 0.0.0.0:* 5624/named
udp 0 0 0.0.0.0:5353 0.0.0.0:* 771/avahi-daemon: r
udp6 0 0 fd00:::53 :::* 5624/named
udp6 0 0 ::1:53 :::* 5624/named
udp6 0 0 :::5353 :::* 771/avahi-daemon: r
Vérifier que le système Ubuntu écoute le serveur DNS
utilisateur@MachineUbuntu:~$ resolvectl dns
Global: 10.10.10.1 fd00::
Link 2 (enp0sxx): yyyy:yyyy:yyyy::yyyy yyy.yyy.yyy.yyy
Link 3 (virtualeth0):
Link 4 (wlx803xxxxx): yyyy:yyyy:yyyy::yyyy yyyy:yyyy:yyyy::yyyy yyyy:yyyy:yyyy::yyyy yyy.yyy.yyy.yyy
Link 5 (wlox): yyy.yyy.yyy.yyy
utilisateur@MachineUbuntu:~$ dig MachineUbuntu +noall +answer
MachineUbuntu. 0 IN A 127.0.1.1
utilisateur@MachineUbuntu:~$ dig MachineUbuntu.domaine-perso.fr +noall +answer
MachineUbuntu.domaine-perso.fr. 0 IN A 10.10.10.1
MachineUbuntu.domaine-perso.fr. 0 IN A aaa.aaa.aaa.aaa
MachineUbuntu.domaine-perso.fr. 0 IN A bbb.bbb.bbb.bbb
…
utilisateur@MachineUbuntu:~$ dig bidon +noall +answer
utilisateur@MachineUbuntu:~$ dig bidon.domaine-perso.fr +noall +answer
Si UFW est activé, ouvrir le port DNS sur UFW.
utilisateur@MachineUbuntu:~$ sudo ufw allow from 192.168.0.0/16 to any port 53 proto udp
Éditer «/etc/bind/named.conf.local» pour définir la zone DNS
zone "domaine-perso.fr" {
type master;
file "/etc/bind/db.domaine-perso.fr";
};
zone "10.10.10.in-addr.arpa" {
type master;
file "/etc/bind/db.10.10.10";
};
zone "0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.d.f.ip6.arpa." {
type master;
file "/etc/bind/db.fd00";
};
utilisateur@MachineUbuntu:~$ sudo named-checkconf
Éditer «/etc/bind/db.domaine-perso.fr» pour définir les alias DNS
$TTL 15m
@ IN SOA @ root (
2021082512 ; n° série
1h ; intervalle de rafraîchissement esclave
15m ; intervalle de réessaie pour l’esclave
1w ; temps d’expiration de la copie esclave
1h ) ; temps de cache NXDOMAIN
IN NS @
IN A 10.10.10.10
IN AAAA fd00::a
IN MX 2 courriel
; domaine vers adresse IP
gitlab IN A 10.10.10.1
gitlab IN AAAA fd00::
courriel IN A 10.10.10.2
courriel IN AAAA fd00::2
documentation IN A 10.10.10.3
documentation IN AAAA fd00::3
* IN A 10.10.10.10
* IN AAAA fd00::a
Éditer «/etc/bind/db.10.10.10» pour définir les alias inverse DNS
$TTL 15m
@ IN SOA gitlab.domaine-perso.fr. root.domaine-perso.fr. (
2021082512 ; n° série
1h ; intervalle de rafraîchissement esclave
15m ; intervalle de réessaie pour l’esclave
1w ; temps d’expiration de la copie esclave
1h ) ; temps de cache NXDOMAIN
IN NS gitlab.domaine-perso.fr.
; IP vers nom de domaine DNS
1 IN PTR gitlab.domaine-perso.fr.
2 IN PTR courriel.domaine-perso.fr.
3 IN PTR documentation.domaine-perso.fr.
10 IN PTR domaine-perso.fr.
Éditer «/etc/bind/db.fd00» pour définir les alias inverse DNS
$TTL 15m
@ IN SOA gitlab.domaine-perso.fr. root.domaine-perso.fr. (
2021082512 ; n° série
1h ; intervalle de rafraîchissement esclave
15m ; intervalle de réessaie pour l’esclave
1w ; temps d’expiration de la copie esclave
1h ) ; temps de cache NXDOMAIN
IN NS gitlab.domaine-perso.fr.
; IPv6 vers nom de domaine DNS
0 IN PTR gitlab.domaine-perso.fr.
2 IN PTR courriel.domaine-perso.fr.
3 IN PTR documentation.domaine-perso.fr.
a IN PTR domaine-perso.fr.
utilisateur@MachineUbuntu:~$ sudo systemctl restart named
Vérifier la résolution DNS#
utilisateur@MachineUbuntu:~$ dig ANY domaine-perso.fr +noall +answer
domaine-perso.fr. 6444 IN SOA domaine-perso.fr. root.domaine-perso.fr. 2021082512 3600 900 604800 3600
domaine-perso.fr. 6444 IN NS domaine-perso.fr.
domaine-perso.fr. 6444 IN A 10.10.10.10
domaine-perso.fr. 6444 IN AAAA fd00::a
domaine-perso.fr. 6444 IN MX 2 courriel.domaine-perso.fr.
utilisateur@MachineUbuntu:~$ dig ANY gitlab.domaine-perso.fr +noall +answer
gitlab.domaine-perso.fr. 6444 IN A 10.10.10.1
gitlab.domaine-perso.fr. 6444 IN AAAA fd00::
utilisateur@MachineUbuntu:~$ dig ANY courriel.domaine-perso.fr +noall +answer
courriel.domaine-perso.fr. 6444 IN A 10.10.10.2
courriel.domaine-perso.fr. 6444 IN AAAA fd00::2
utilisateur@MachineUbuntu:~$ dig ANY documentation.domaine-perso.fr +noall +answer
documentation.domaine-perso.fr. 6444 IN A 10.10.10.3
documentation.domaine-perso.fr. 6444 IN AAAA fd00::3
utilisateur@MachineUbuntu:~$ dig ANY bidon.domaine-perso.fr +noall +answer
bidon.domaine-perso.fr. 6444 IN A 10.10.10.10
bidon.domaine-perso.fr. 6444 IN AAAA fd00::a
Vérifier la résolution externe#
utilisateur@MachineUbuntu:~$ dig google.com +noall +answer
google.com. 16 IN A 216.58.223.110
google.com. 32 IN AAAA 2a00:…::200e
…
Vérifier la résolution inverse#
Vous pouvez utiliser la commande host ou dig -x
utilisateur@MachineUbuntu:~$ host 10.10.10.1
1.10.10.10.in-addr-arpa domain name pointer gitlab.domaine-perso.fr.
utilisateur@MachineUbuntu:~$ dig -x 10.10.10.1 +noall +answer
1.10.10.10.in-addr.arpa. 900 IN PTR gitlab.domaine-perso.fr.
utilisateur@MachineUbuntu:~$ dig -x fd00:: +noall +answer
a.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.d.f.ip6.arpa. 900 IN PTR gitlab.domaine-perso.fr.
utilisateur@MachineUbuntu:~$ dig -x 10.10.10.2 +noall +answer
1.10.10.10.in-addr.arpa. 900 IN PTR courriel.domaine-perso.fr.
utilisateur@MachineUbuntu:~$ dig -x fd00::2 +noall +answer
2.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.d.f.ip6.arpa. 900 IN PTR courriel.domaine-perso.fr.
utilisateur@MachineUbuntu:~$ dig -x 10.10.10.3 +noall +answer
1.10.10.10.in-addr.arpa. 900 IN PTR documentation.domaine-perso.fr.
utilisateur@MachineUbuntu:~$ dig -x fd00::3 +noall +answer
3.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.d.f.ip6.arpa. 900 IN PTR documentation.domaine-perso.fr.
utilisateur@MachineUbuntu:~$ dig -x 10.10.10.10 +noall +answer
1.10.10.10.in-addr.arpa. 900 IN PTR domaine-perso.fr.
utilisateur@MachineUbuntu:~$ dig -x fd00::a +noall +answer
a.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.d.f.ip6.arpa. 900 IN PTR domaine-perso.fr.
Paramétrer définitivement votre DNS pour gitlab#
Éditer «/etc/bind/db.domaine-perso.fr» pour définir les alias DNS définitifs
…
IN NS @
IN A 10.10.10.1
IN AAAA fd00::
IN MX 1 courriel
; domaine vers adresse IP
gitlab IN A 10.10.10.1
gitlab IN AAAA fd00::
courriel IN A 10.10.10.1
courriel IN AAAA fd00::1
* IN A 10.10.10.1
* IN AAAA fd00::
Éditer «/etc/bind/db.10.10.10» pour définir les alias inverse DNS
$TTL 15m
@ IN SOA gitlab.domaine-perso.fr. root.domaine-perso.fr. (
2021082512 ; n° série
1h ; intervalle de rafraîchissement esclave
15m ; intervalle de réessaie pour l’esclave
1w ; temps d’expiration de la copie esclave
1h ) ; temps de cache NXDOMAIN
IN NS gitlab.domaine-perso.fr.
; IP vers nom de domaine DNS
1 IN PTR gitlab.domaine-perso.fr.
1 IN PTR courriel.domaine-perso.fr.
1 IN PTR domaine-perso.fr.
Éditer «/etc/bind/db.fd00» pour définir les alias inverse DNS
$TTL 15m
@ IN SOA gitlab.domaine-perso.fr. root.domaine-perso.fr. (
2021082512 ; n° série
1h ; intervalle de rafraîchissement esclave
15m ; intervalle de réessaie pour l’esclave
1w ; temps d’expiration de la copie esclave
1h ) ; temps de cache NXDOMAIN
IN NS gitlab.domaine-perso.fr.
; IPv6 vers nom de domaine DNS
0 IN PTR gitlab.domaine-perso.fr.
0 IN PTR domaine-perso.fr.
1 IN PTR courriel.domaine-perso.fr.
utilisateur@MachineUbuntu:~$ sudo systemctl restart named
utilisateur@MachineUbuntu:~$ dig -x 10.10.10.1 +noall +answer
1.10.10.10.in-addr.arpa. 900 IN PTR gitlab.domaine-perso.fr.
1.10.10.10.in-addr.arpa. 900 IN PTR domaine-perso.fr.
1.10.10.10.in-addr.arpa. 900 IN PTR courriel.domaine-perso.fr.
utilisateur@MachineUbuntu:~$ dig -x fd00:: +noall +answer
0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.d.f.ip6.arpa. 900 IN PTR gitlab.domaine-perso.fr.
0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.d.f.ip6.arpa. 900 IN PTR domaine-perso.fr.
utilisateur@MachineUbuntu:~$ dig -x fd00::1 +noall +answer
1.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.d.f.ip6.arpa. 900 IN PTR courriel.domaine-perso.fr.
Installer Docker#
Installer les applications de base :
utilisateur@MachineUbuntu:~$ sudo apt install docker.io curl openssh-server ca-certificates postfix mailutils
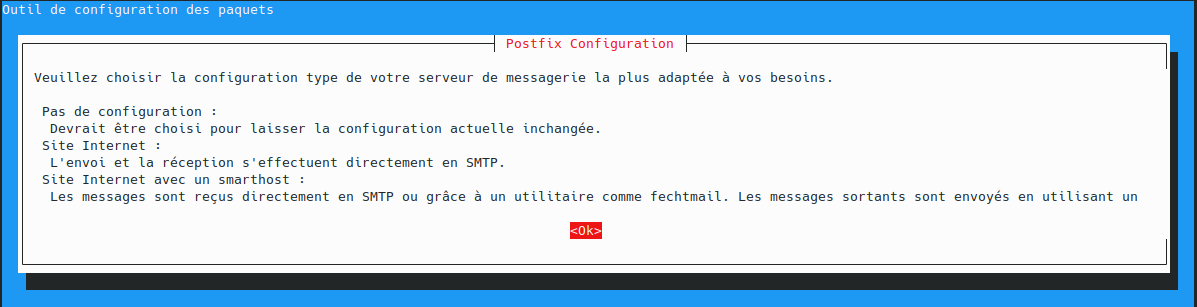
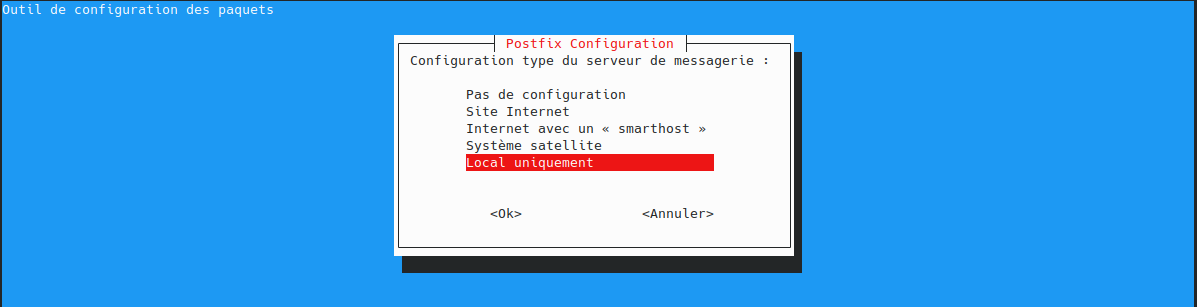
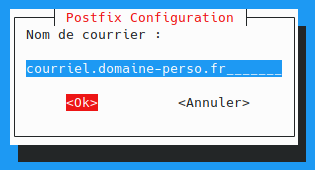
Autorisez le compte utilisateur à utiliser docker :
utilisateur@MachineUbuntu:~$ sudo usermod -aG docker $USER
Démarrez le service docker et ajoutez-le au démarrage du système :
utilisateur@MachineUbuntu:~$ sudo systemctl start docker
Vérifiez le bon fonctionnement du service docker à l’aide de la commande systemctl ci-dessous.
utilisateur@MachineUbuntu:~$ systemctl status docker
● docker.service - Docker Application Container Engine
Loaded: loaded (/lib/systemd/system/docker.service; enabled; vendor preset: enabled)
Active: active (running) since Fri 2020-10-09 11:07:10 CEST; 47s ago
TriggeredBy: ● docker.socket
Docs: https://docs.docker.com
Main PID: 6241 (dockerd)
Tasks: 12
Memory: 38.6M
CGroup: /system.slice/docker.service
└─6241 /usr/bin/dockerd -H fd://
--containerd=/run/containerd/containerd.sock
q
Activez le service au démarrage.
utilisateur@MachineUbuntu:~$ sudo systemctl enable docker
utilisateur@MachineUbuntu:~$ ip a
…
4: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default qlen 1000
link/ether 02:42:a3:0c:9c:fb brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fa80::42:a3ff:fe0c:9cfb/64 scope link
valid_lft forever preferred_lft forever
…
Éditer «/etc/bind/named.conf.option» pour ajouter l’interface de docker
options {
directory "/var/cache/bind";
// Pour des raisons de sécurité.
// Cache la version du serveur DNS pour les clients.
version "Pas pour les crackers";*
listen-on { 127.0.0.1; 10.10.10.1; 172.17.0.1; };
listen-on-v6 { ::1; fd00::; fe80::42:a3ff:fe0c:9cfb; };
// Optionnel - Comportement par défaut de BIND en récursions.
recursion yes;
allow-query { 127.0.0.1; 10.10.10.1; ::1; fd00::; 172.17.0.0/16; fe80::42:a3ff:fe0c:9cfb; };
// Récursions autorisées seulement pour les interfaces clients
allow-recursion { 127.0.0.1; 10.10.10.0/24; ::1; fd00::/8; 172.17.0.0/16; fe80::42:a3ff:fe0c:9cfb; };
dnssec-validation auto;
// Activer la journalisation des requêtes DNS
querylog yes;
};
utilisateur@MachineUbuntu:~$ sudo named-checkconf
Redémarrer votre Ubuntu pour valider les modifications
utilisateur@MachineUbuntu:~$ reboot
Tester Docker#
Après vous être reconnecter sous Ubuntu, vérifiez dans un terminal que docker fonctionne bien en exécutant la commande docker docker run hello-world ci-dessous.
utilisateur@MachineUbuntu:~$ docker run hello-world
Unable to find image 'hello-world:latest' locally
latest: Pulling from library/hello-world
0e03bdcc26d7: Pull complete
Digest: sha256:ffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff
Status: Downloaded newer image for hello-world:latest
Hello from Docker!
This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps:
1. The Docker client contacted the Docker daemon.
2. The Docker daemon pulled the "hello-world" image from the Docker Hub.
(amd64)
3. The Docker daemon created a new container from that image which runs the executable that produces the output you are currently reading.
4. The Docker daemon streamed that output to the Docker client, which sent it to your terminal.
To try something more ambitious, you can run an Ubuntu container with:
$ docker run -it ubuntu bash
Share images, automate workflows, and more with a free Docker ID: https://hub.docker.com/
For more examples and ideas, visit: https://docs.docker.com/get-started/
utilisateur@MachineUbuntu:~$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
dcd0d025b44b hello-world "/hello" 19 seconds ago Exited (0) 16 seconds ago elegant_torvalds
Nous sommes maintenant prêts à installer GitLab.
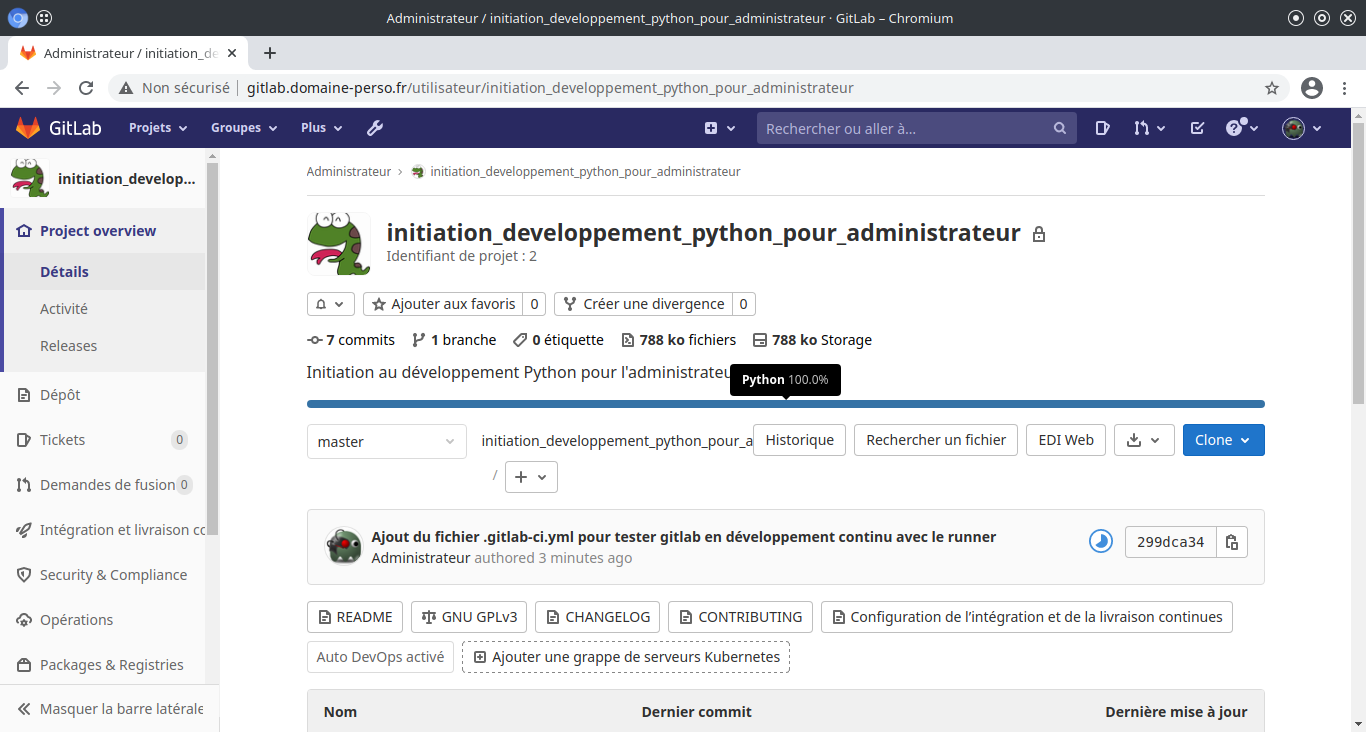
Installer GitLab#
GitLab est un gestionnaire de référentiels open source basé sur Rails (langage Rubis) développé par la société GitLab. Il s’agit d’un gestionnaire de révisions de code WEB basé sur git qui permet à votre équipe de collaborer sur le codage, le test et le déploiement d’applications. GitLab fournit plusieurs fonctionnalités, notamment les wikis, le suivi des problèmes, les révisions de code et les flux d’activité.
Téléchargez le paquet d’installation GitLab pour Ubuntu et l’installer#
Installation longue (prévoir une image VM ou USB ?)
https://packages.gitlab.com/gitlab/gitlab-ce et choisissez la dernière version gitlab-ce pour ubuntu xenial
utilisateur@MachineUbuntu:~/gitlab$ wget https://packages.gitlab.com/gitlab/gitlab-ce/packages/ubuntu/focal/gitlab-ce_14.1.3-ce.0_amd64.deb/download.deb
utilisateur@MachineUbuntu:~/gitlab$ sudo apt update ; sudo EXTERNAL_URL="http://gitlab.domaine-perso.fr" dpkg -i download.deb
Paramétrer GitLab#
utilisateur@MachineUbuntu:~/gitlab$ sudo gitlab-ctl show-config
utilisateur@MachineUbuntu:~/gitlab$ sudo chmod o+r /etc/gitlab/gitlab.rb
utilisateur@MachineUbuntu:~/gitlab$ sudo nano /etc/gitlab/gitlab.rb
external_url "http://gitlab.domaine-perso.fr"
# Pour activer les fonctions artifacts (tester la qualité du code, déployer sur un serveur distant en SSH, etc.)
gitlab_rails['artifacts_enabled'] = true
# pour générer la doc et l’afficher avec Gitlab
pages_external_url "http://documentation.domaine-perso.fr"
utilisateur@MachineUbuntu:~/gitlab$ sudo openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout /etc/gitlab/trusted-certs/MachineUbuntu.key -out /etc/gitlab/trusted-certs/MachineUbuntu.crt
utilisateur@MachineUbuntu:~/gitlab$ sudo gitlab-ctl reconfigure
Configurer et tester GitLab#
Saisissez dans un navigateur l’URL gitlab.domaine-perso.fr
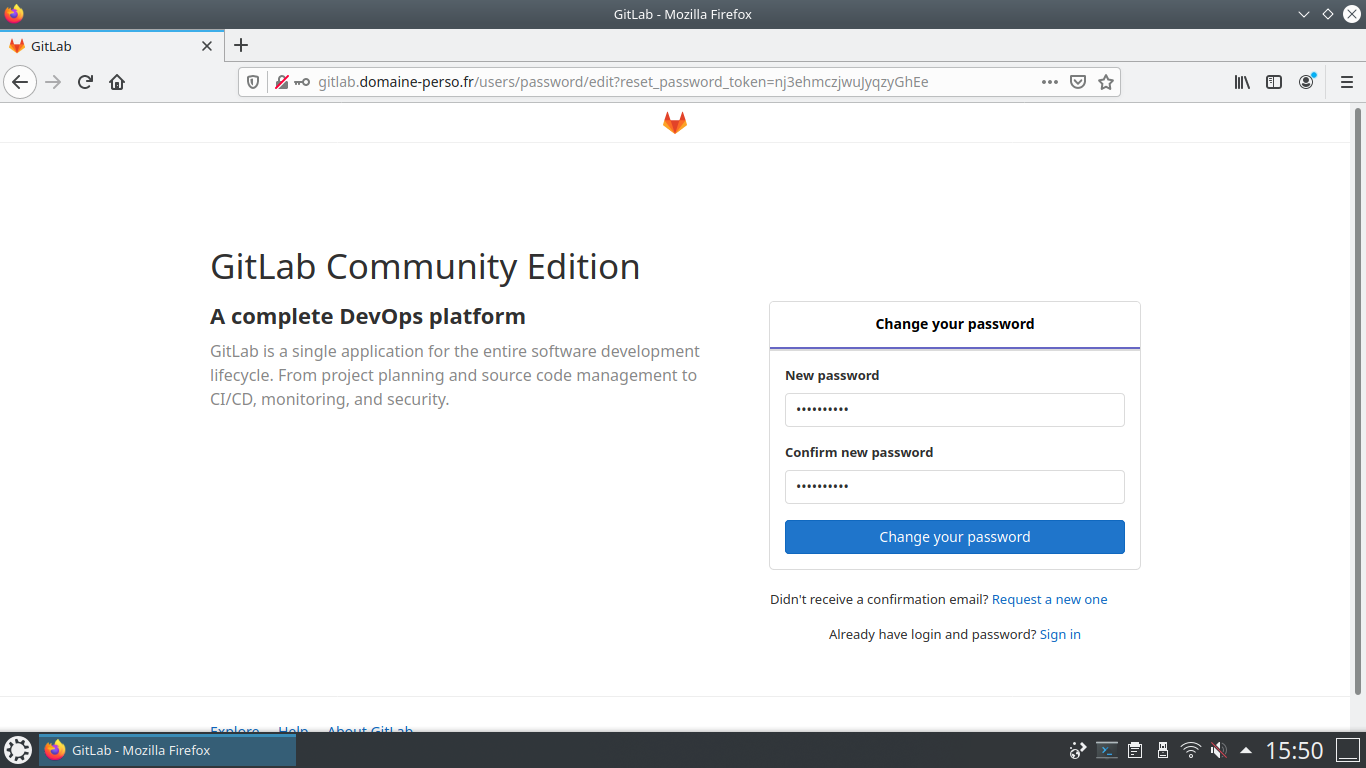
Si vous n’avez pas la fenêtre d’initialisation du mot de passe :
utilisateur@MachineUbuntu:~/gitlab$ sudo gitlab-rake "gitlab:password:reset"
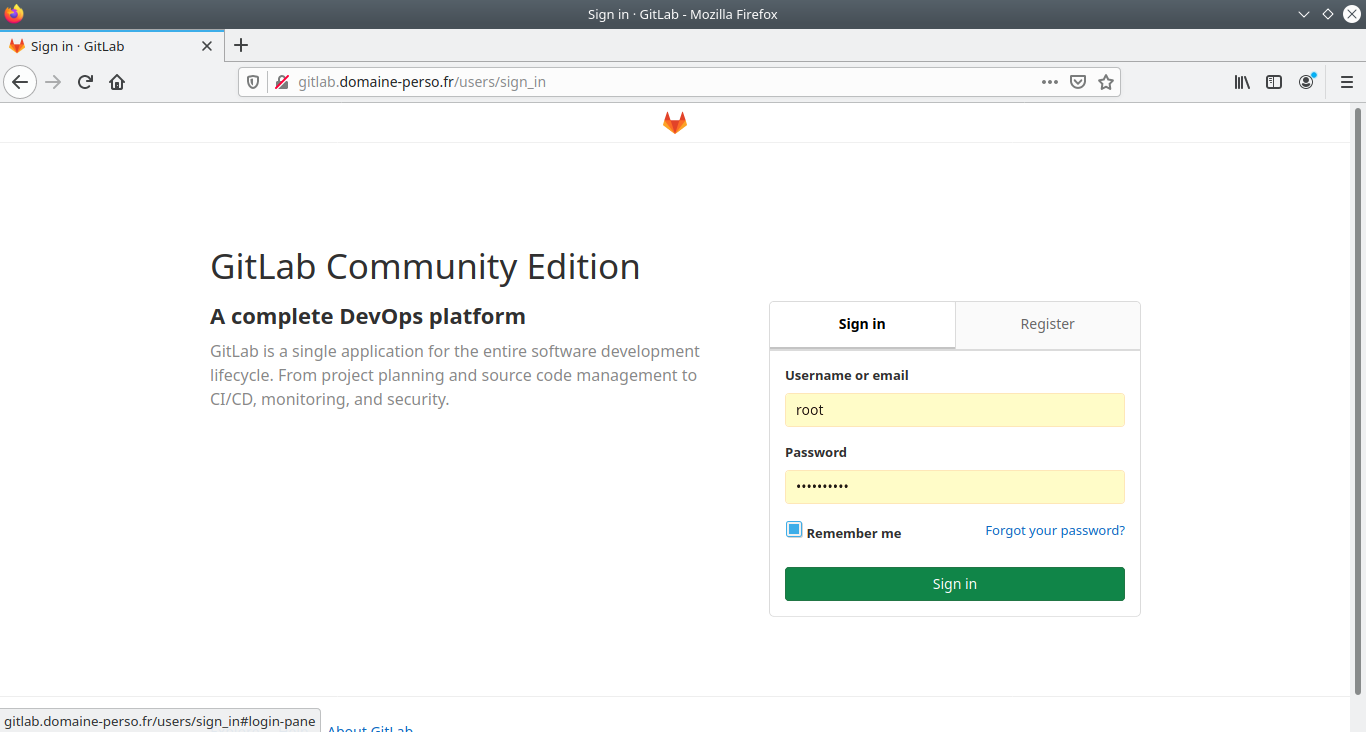
Tapez la touche F5 pour rafraîchir l’affichage de votre navigateur.
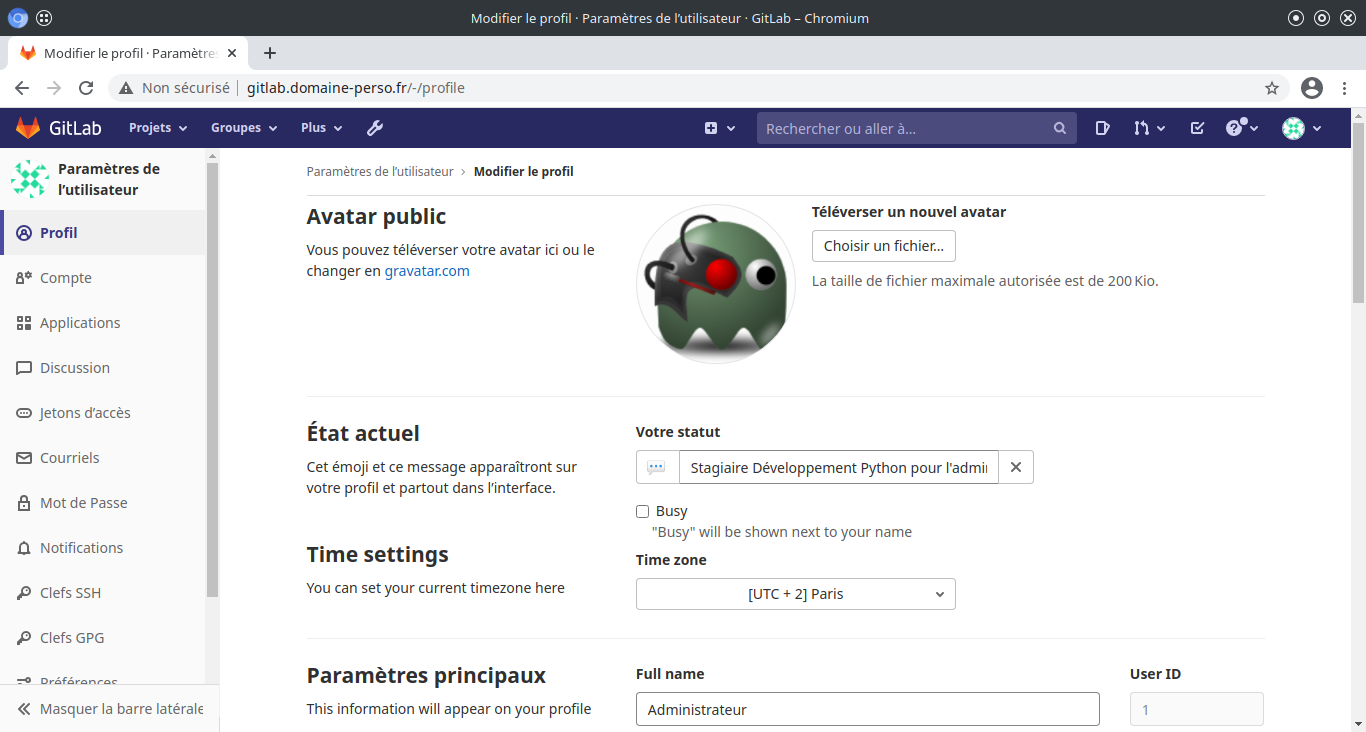
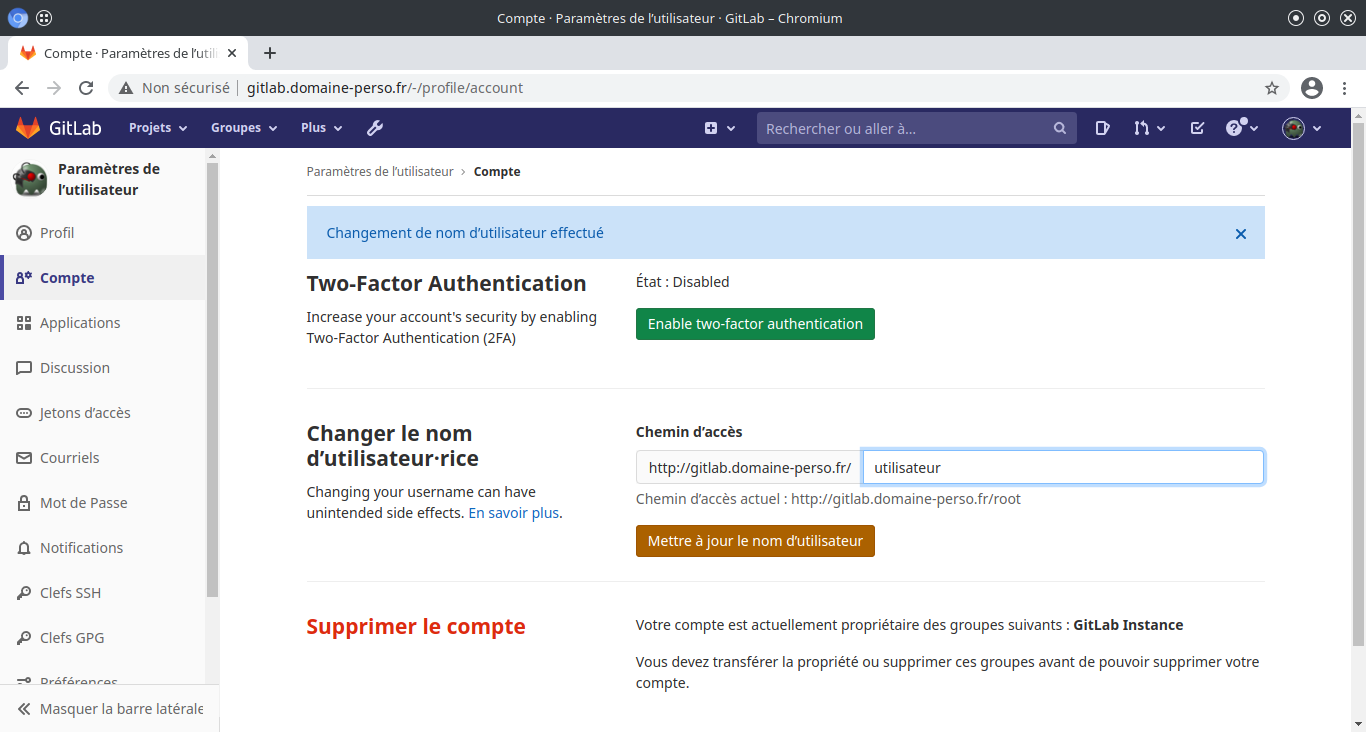

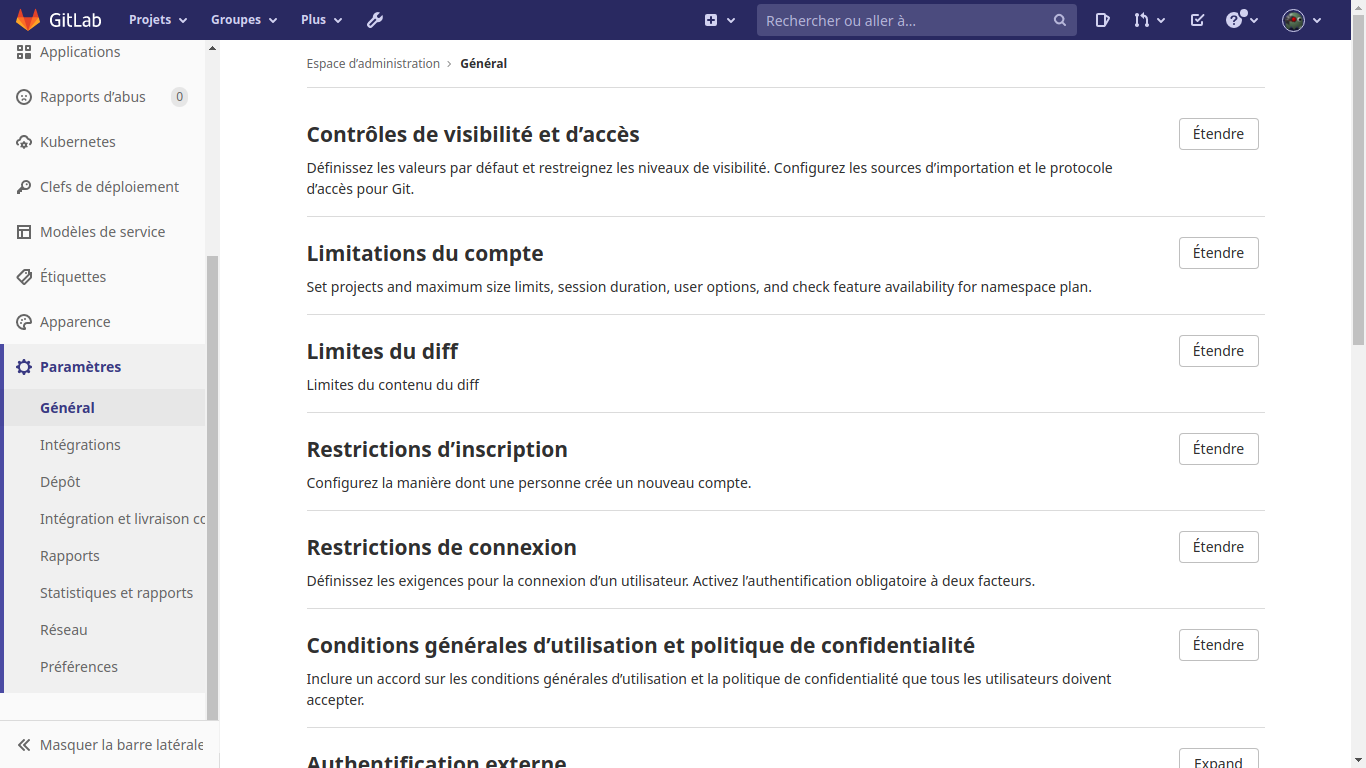
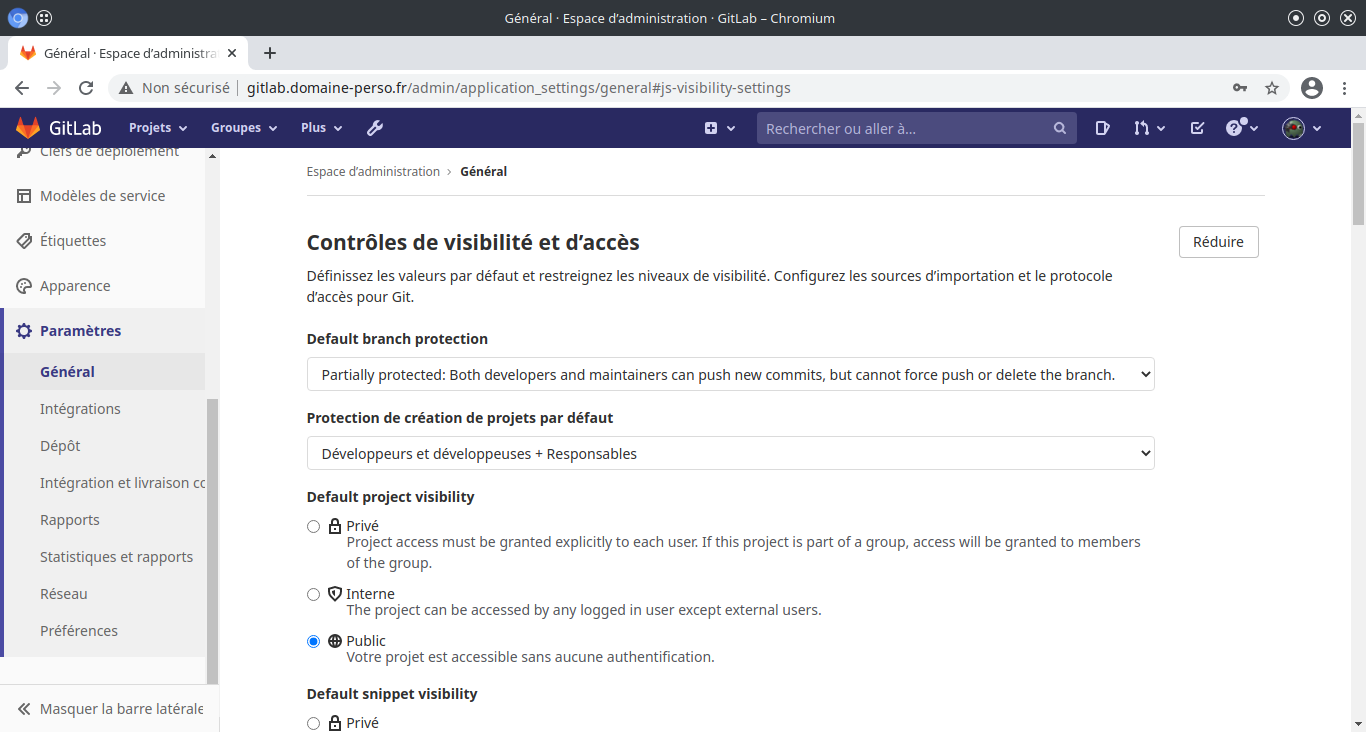
Intégrer le dépot git local dans Gitlab :
utilisateur@MachineUbuntu:~/$ cd repertoire_de_developpement
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git config credential.helper store
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git remote add origin http://gitlab.domaine-perso.fr/utilisateur/initiation_developpement_python_pour_administrateur.git
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git push -u origin --all
Username for 'http://gitlab.domaine-perso.fr': utilisateur
Password for 'http://gitlab.domaine-perso.fr': motdepasse
Énumération des objets: 51, fait.
Décompte des objets: 100% (43/43), fait.
Compression par delta en utilisant jusqu’à 4 fils d’exécution
Compression des objets: 100% (43/43), fait.
Écriture des objets: 100% (51/51), 180.78 Kio \| 4.89 Mio/s, fait.
Total 51 (delta 3), réutilisés 0 (delta 0), réutilisés du pack 0 To http://gitlab.domaine-perso.fr/utilisateur/initiation_developpement_python_pour_administrateur.git
* [new branch] master → master
La branche 'master' est paramétrée pour suivre la branche distante 'master' depuis 'origin'.
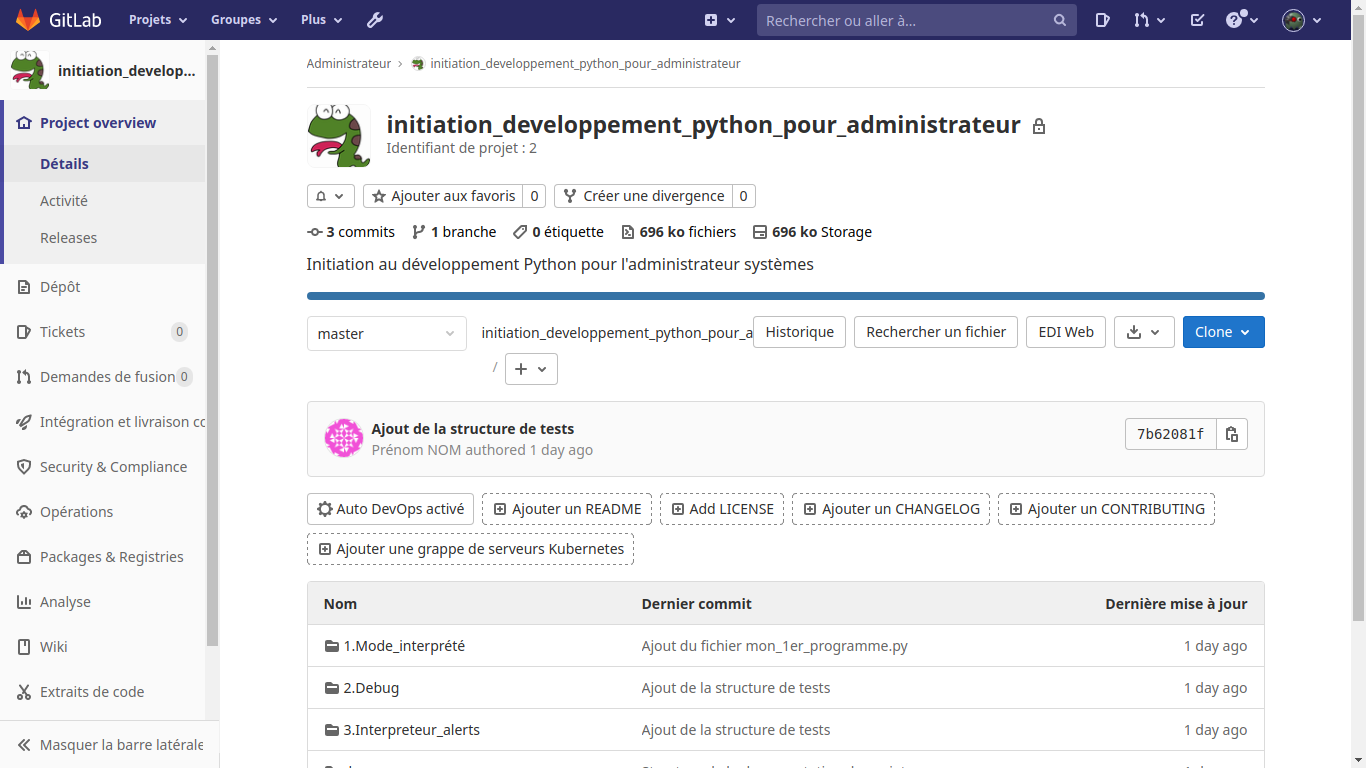
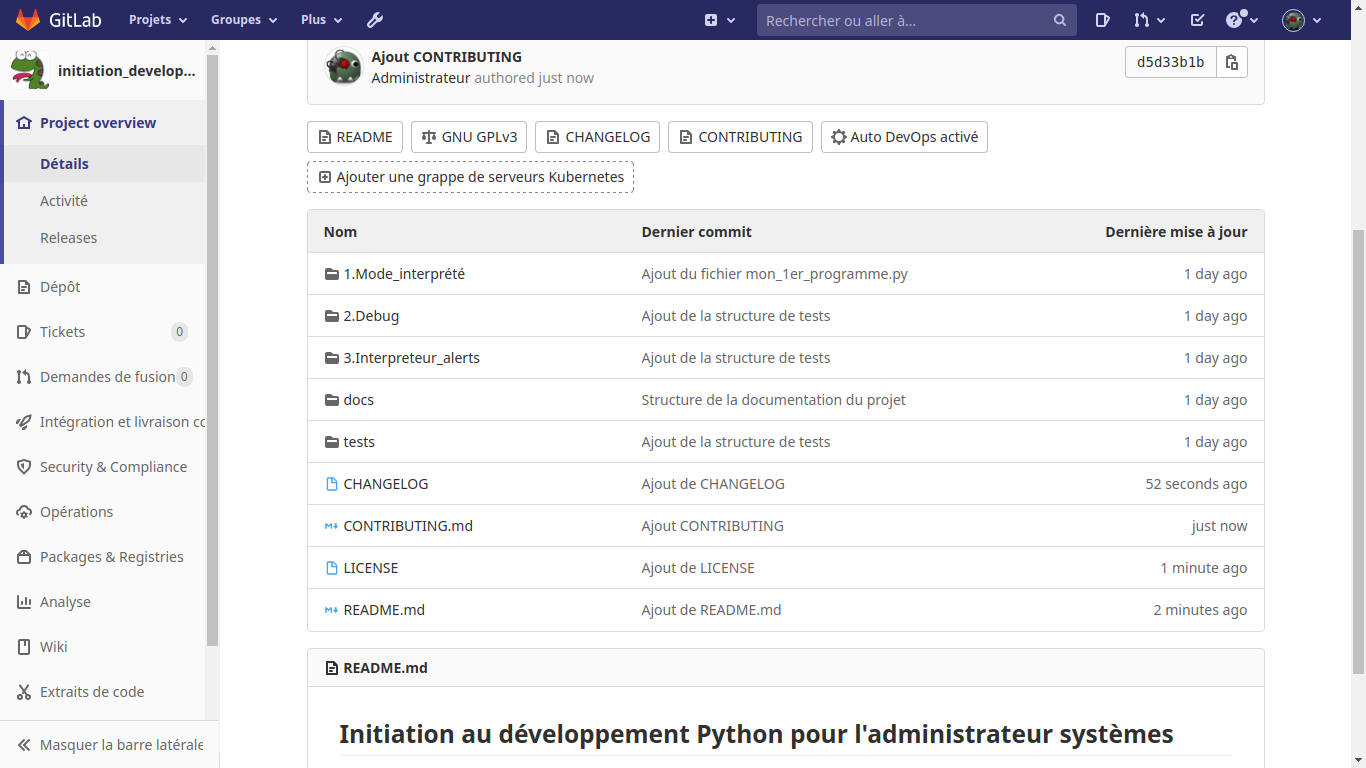
Vous pouvez maintenant récupérer les nouveaux fichiers d’information Gitlab (CHANGELOG, CONTRIBUTING.md, LICENSE et README.md) dans votre projet local :
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git fetch
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git merge
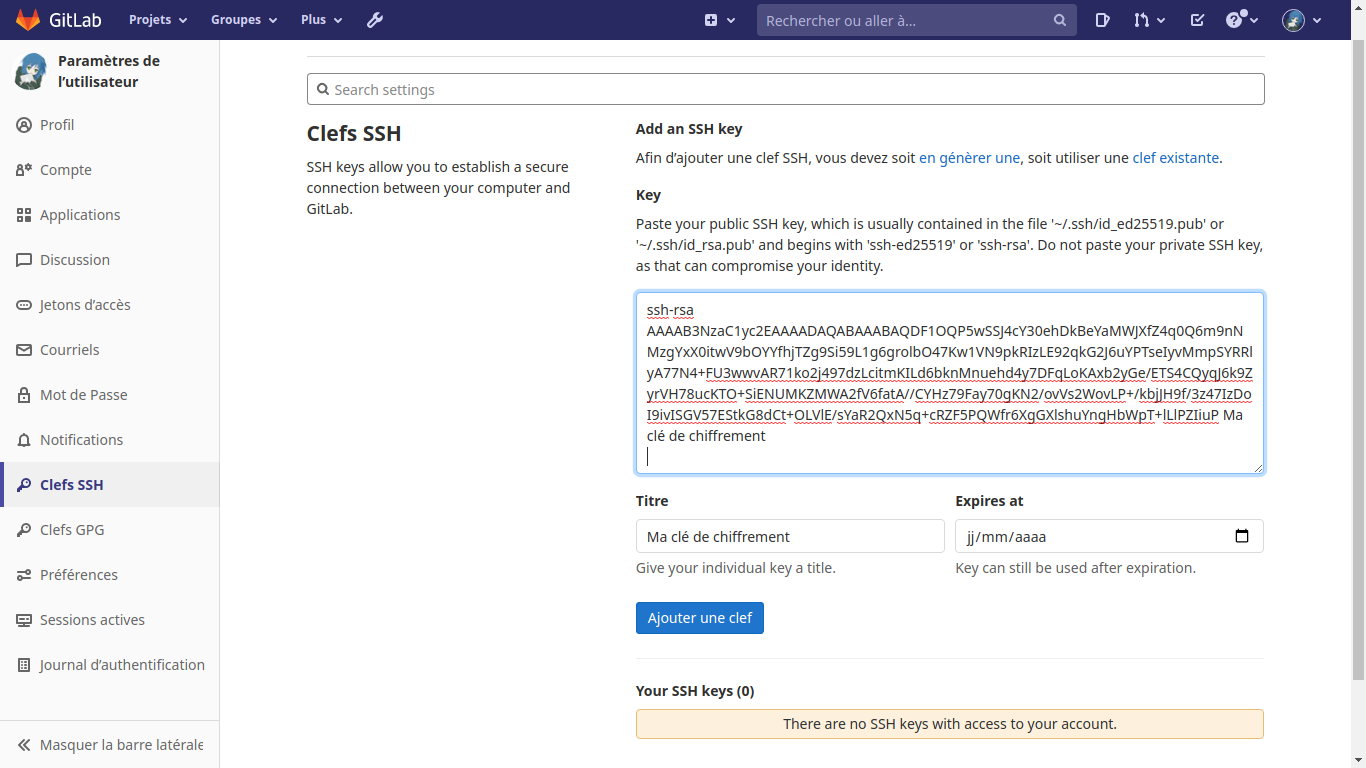
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ ssh-keygen -t rsa -b 2048 -C "Ma clé de chiffrement"
Generating public/private rsa key pair.
Enter file in which to save the key(/home/utilisateur/.ssh/id_rsa):
Created directory '/home/utilisateur/.ssh'.
Enter passphrase (empty for no passphrase): motdepasse
Enter same passphrase again: motdepasse
Your identification has been saved in /home/utilisateur/.ssh/id_rsa
Your public key has been saved in /home/utilisateur/.ssh/id_rsa.pub
The key fingerprint is: SHA256:n60tA2JwGV0tptwB48YrPT6hQQWrxGYhEVegfnO9GXM Ma clé de chiffrement
The key's randomart image is:
+---[RSA 2048]----+
| +o+ooo+o.. |
| = ..=..+ . |
| . = o+++ o |
| . +.oo+o.. |
| . +o+ S E |
| . oo=.X o |
| ...=.o . |
| .oo |
| .o. |
+----[SHA256]-----+

Copier le contenu du fichier «/home/utilisateur/.ssh/id-rsa.pub»
Autorisations pour Docker et le Runner#
Cette étape consiste à créer un certificat pour autoriser Docker à interagir avec le registre et le Runner.
Pour le registre :
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo mkdir -p /etc/docker/certs.d/MachineUbuntu:5000
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo ln -s /etc/gitlab/trusted-certs/MachineUbuntu.crt /etc/docker/certs.d/MachineUbuntu:5000/ca.crt
Pour le runner :
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo mkdir -p /etc/gitlab-runner/certs
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo ln -s /etc/gitlab/trusted-certs/MachineUbuntu.crt /etc/gitlab-runner/certs/ca.crt
Configurer et tester le Runner#
Activation du runner dans docker
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ docker run --rm -it -v /etc/gitlab-runner:/etc/gitlab-runner gitlab/gitlab-runner register
Unable to find image 'gitlab/gitlab-runner:latest' locally
latest: Pulling from gitlab/gitlab-runner
a31c7b29f4ad: Pull complete
d843a3e4344f: Pull complete
cf545e7bed9f: Pull complete
c863409f4294: Pull complete
ba06fc4b920b: Pull complete
Digest: sha256:79692bb4b239cb2c1a70d7726e633ec918a6af117b68da5eac55a00a85f38812
Status: Downloaded newer image for gitlab/gitlab-runner:latest
Runtime platform arch=amd64 os=linux pid=7 revision=8925d9a0 version=14.2.0
Running in system-mode.
Enter the Gitlab instance URL (for example, https://gitlab.com/):
Pour activer le runner :
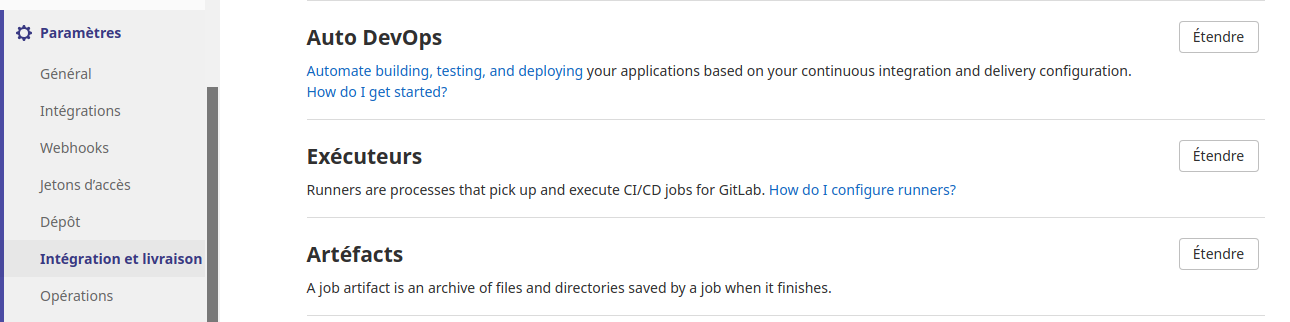
Choisir l’option «Exécuteurs» et click sur le bouton «Étendre».
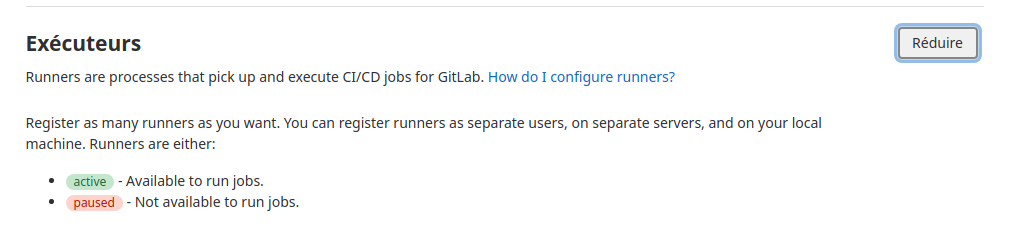
Aller dans «Spécific runners» dans l’option Exécuteurs.
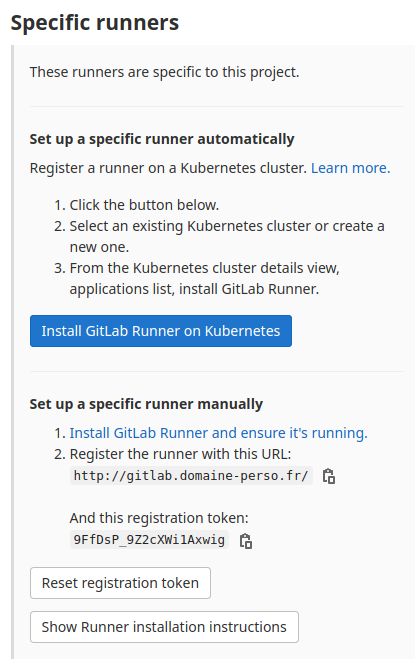
Informations pour déclarer le runner pour le projet.
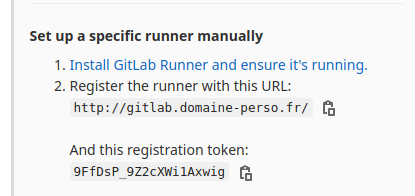
Enter the GitLab instance URL (for example, https://gitlab.com/): http://gitlab.domaine-perso.fr/
Enter the registration token: 9FfDsP_9Z2cXWi1Axwig
Enter a description for the runner: [75d626bde768]: Runner Developpement Python 3
Enter tags for the runner (comma-separated): runner
Registering runner... succeeded runner=Tzzfs5xc
Enter an executor: kubernetes, custom, docker-ssh, shell, docker+machine, docker-ssh+machine, docker, parallels, ssh, virtualbox: docker
Enter the default Docker image (for example, ruby:2.6): python:latest
Runner registered successfully. Feel free to start it, but if it's running already the config should be automatically reloaded!
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo chmod o+r /etc/gitlab-runner/config.toml
Changez dans «/etc/gitlab-runner/config.toml» :
concurrent = 1
check_interval = 0
[session_server]
session_timeout = 1800
[[runners]]
name = "Runner Developpement Python 3"
url = "http://gitlab.domaine-perso.fr/"
token = "9FfDsP_9Z2cXWi1Axwig"
executor = "docker"
pull_policy = "if-not-present"
[runners.custom_build_dir]
[runners.cache]
[runners.cache.s3]
[runners.cache.gcs]
[runners.cache.azure]
[runners.docker]
tls_verify = false
image = "python:latest"
privileged = false
disable_entrypoint_overwrite = false
oom_kill_disable = false
disable_cache = false
volumes = ["/var/run/docker.sock:/var/run/docker.sock", "/cache"]
shm_size = 0
Vous pouvez démarrer le Runner
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ docker run -d --restart always --name gitlab-runner -v /etc/gitlab-runner:/etc/gitlab-runner -v /var/run/docker.sock:/var/run/docker.sock gitlab/gitlab-runner:latest
c9f30b11275ac803ebb17209441c7e0b6351c60d9f0ddadc17c8b0a7ae9cbb96
Autorisez le registre pour la machine ubuntu
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo ln -s /etc/docker/certs.d/MachineUbuntu\:5000/ca.crt /usr/local/share/ca-certificates/MachineUbuntu.crt
utilisateur@MachineUbuntu:~/**\ **repertoire_de_developpement**\ $ sudo update-ca-certificates
Si tout se passe bien vous obtenez le message :
Updatting certificates in /etc/ssl/certs...
1 added, 0 removed; done.
Running hooks in /etc/ca-certificates/update.d...
done.
Dans «Specific runners» de l’option «Exécuteurs» du sous menu «Intégration et livraison» du menu «Paramètres» du projet apparaît le runner en exécution
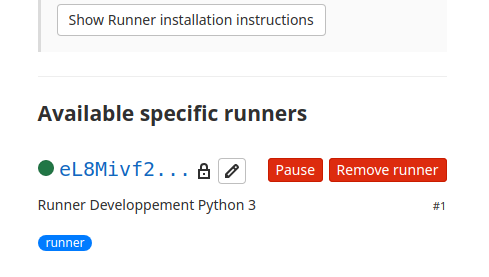
Mettre en pause le runner avec le bouton «Pause».
Cliquez sur l’icone  pour éditer les options du runner, et sélectionnez «Indique si l’exécuteur peut choisir des tâches sans étiquettes (tags)» :
pour éditer les options du runner, et sélectionnez «Indique si l’exécuteur peut choisir des tâches sans étiquettes (tags)» :

Modifier aussi le temps «Durée maximale d’exécution de la tâche» avec «30m»
Relancer l’exécution du runner pour valider les modifications.
Tester le fonctionnement du runner#
Éditer le fichier «.gitlab-ci.yml» dans repertoire_de_developpement.
travail-de-construction:
stage: build
script:
- echo "Bonjour, $GITLAB_USER_LOGIN !"
travail-de-tests-1:
stage: test
script:
- echo "Ce travail teste quelque chose"
travail-de-tests-2:
stage: test
script:
- echo "Ce travail teste quelque chose, mais prend plus de temps que travail-de-test-1."
- echo "Une fois les commandes echo terminées, il exécute la commande de veille pendant 20 secondes"
- echo "qui simule un test qui dure 20 secondes de plus que travail-de-test-1."
- sleep 20
deploiement-production:
stage: deploy
script:
- echo "Ce travail déploie quelque chose de la branche $CI_COMMIT_BRANCH."
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git add .
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git commit -m "Test du runner dans Gitlab"
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git push
On peut voir l’activité en cours du runner avec l’icône : 
Dans le sous menu «Pipelines» du menu «Intégration et livraison» du projet on peut voir les taches d’exécution du runner :
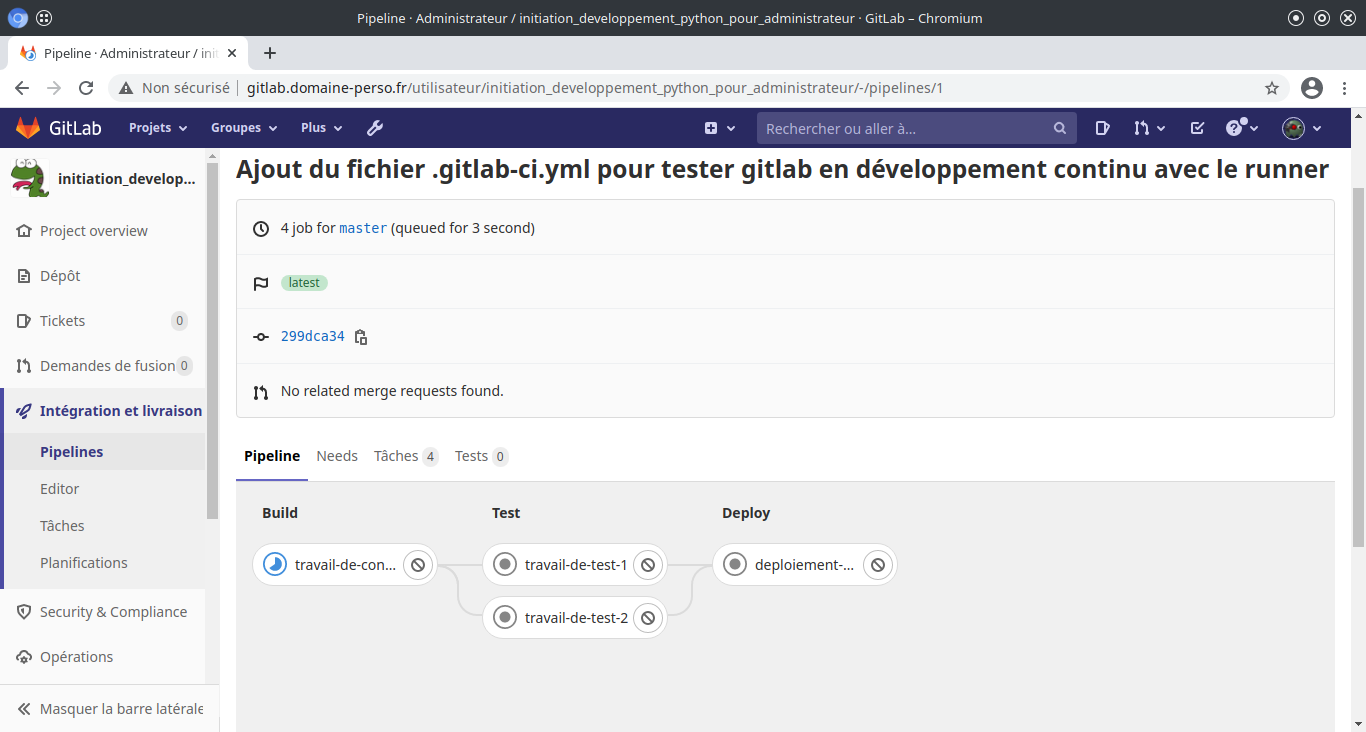
On voit ici la tache «Travail-de-construction» en cours dans la phase de «Build» de l’exécuteur.
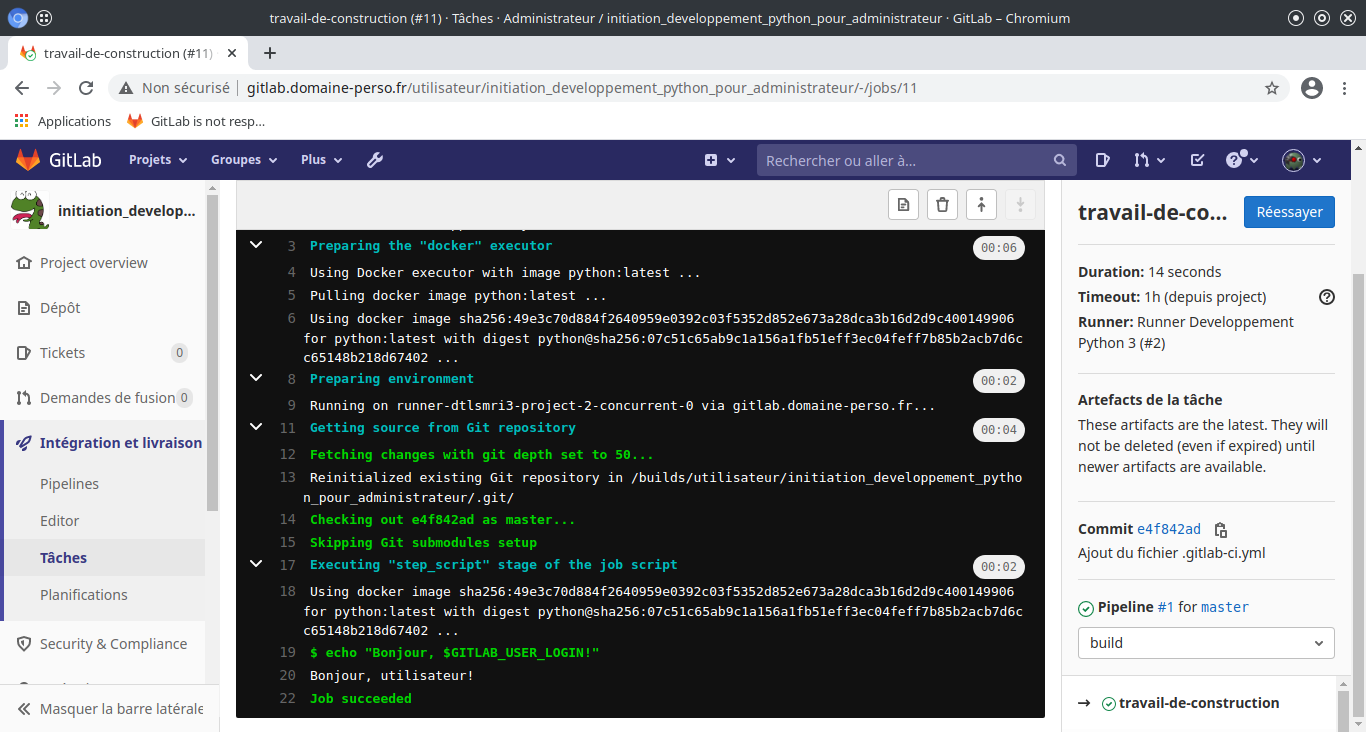
Si on clique sur cette icône on voit les opérations en cours de la tache :
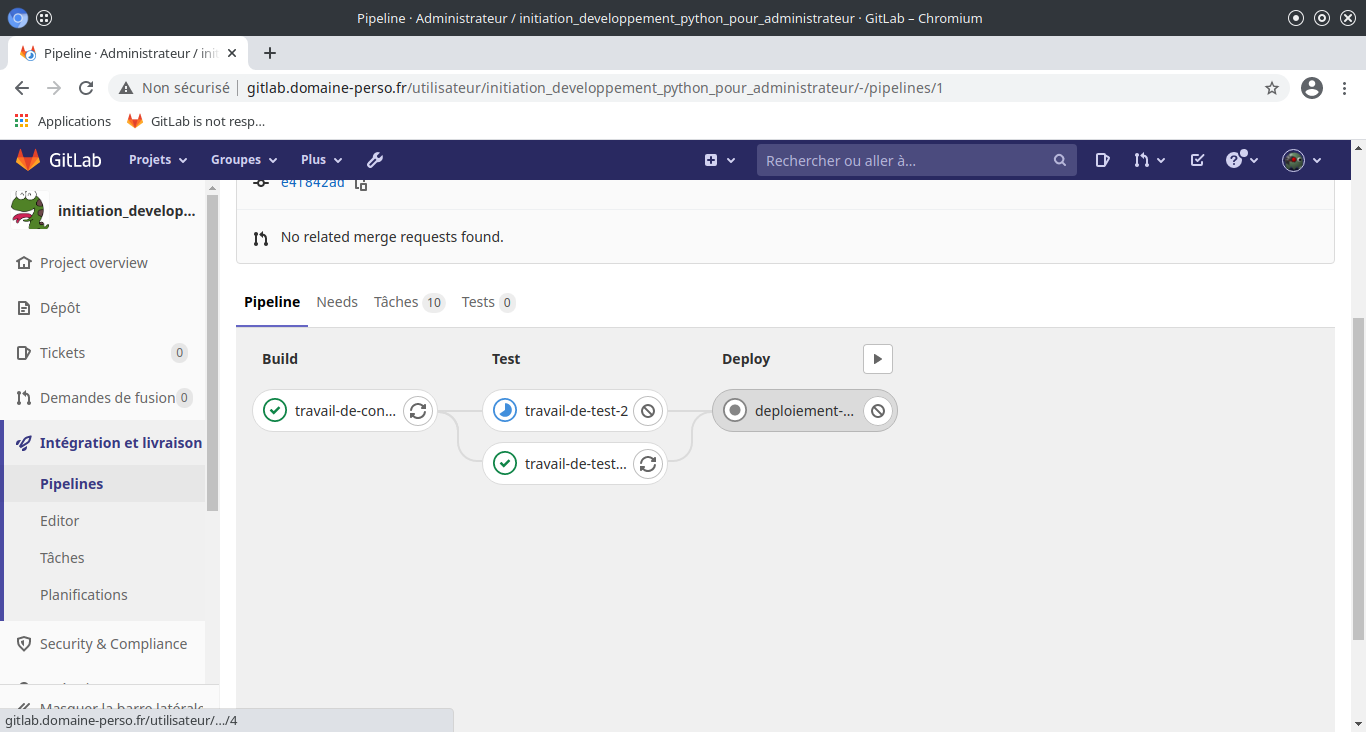
Une fois la tache réussi, l’exécuteur passe dans la phase d’exécution des tests.
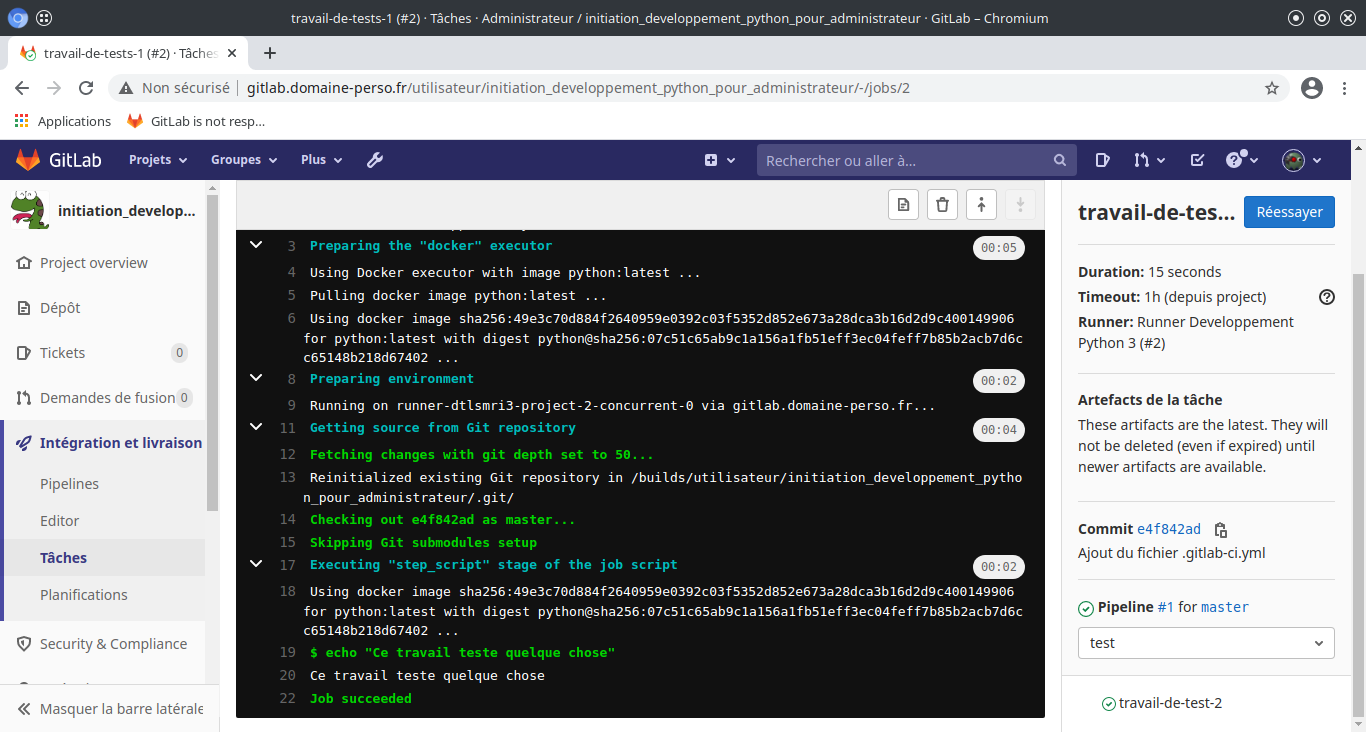
On peut voir le résultat en cliquant sur les icônes des taches de tests.
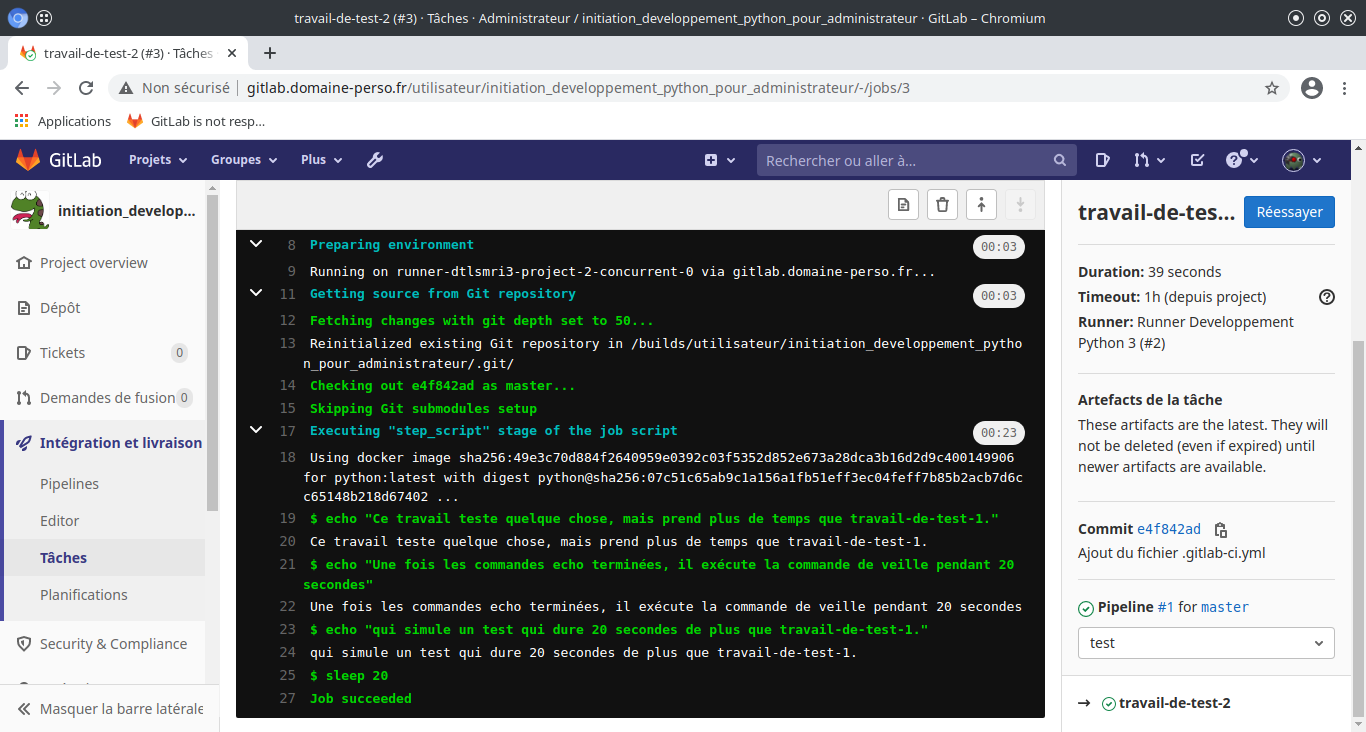
Puis après l’exécuteur passe dans la phase «Deploy».
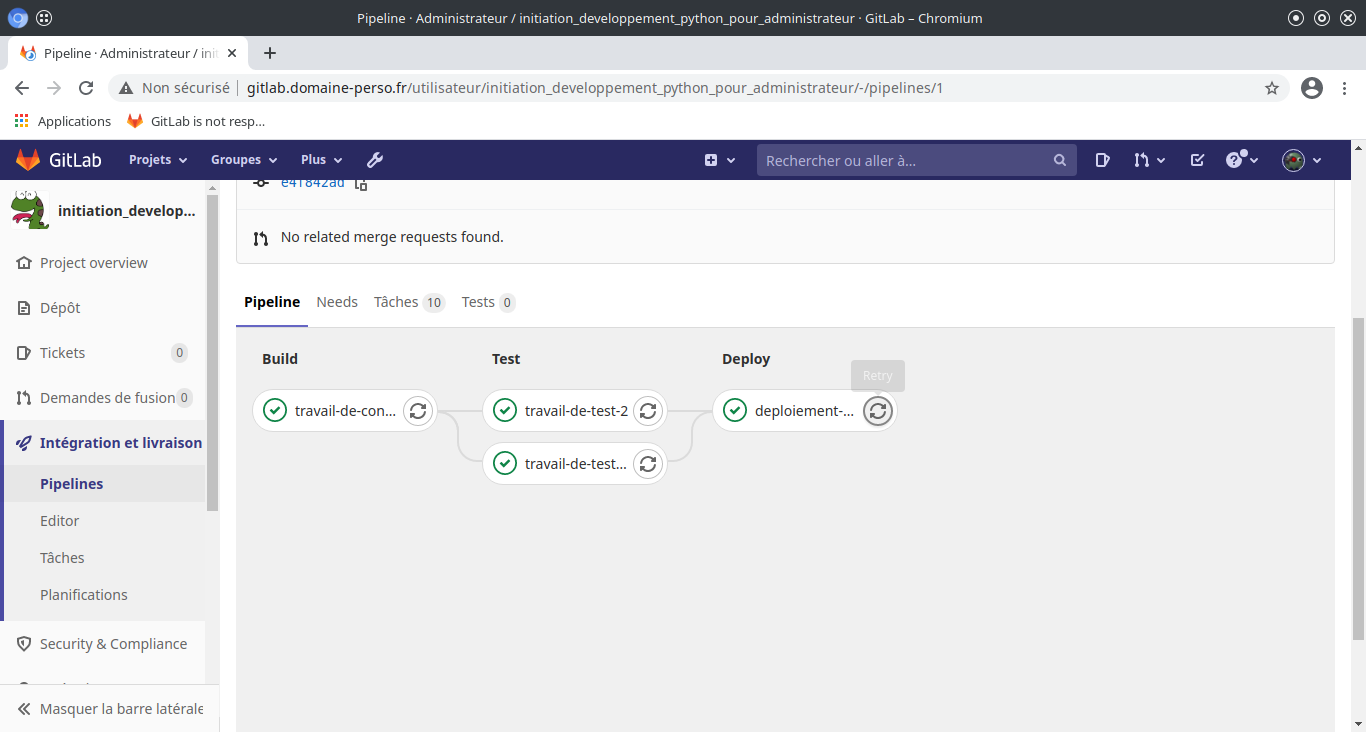
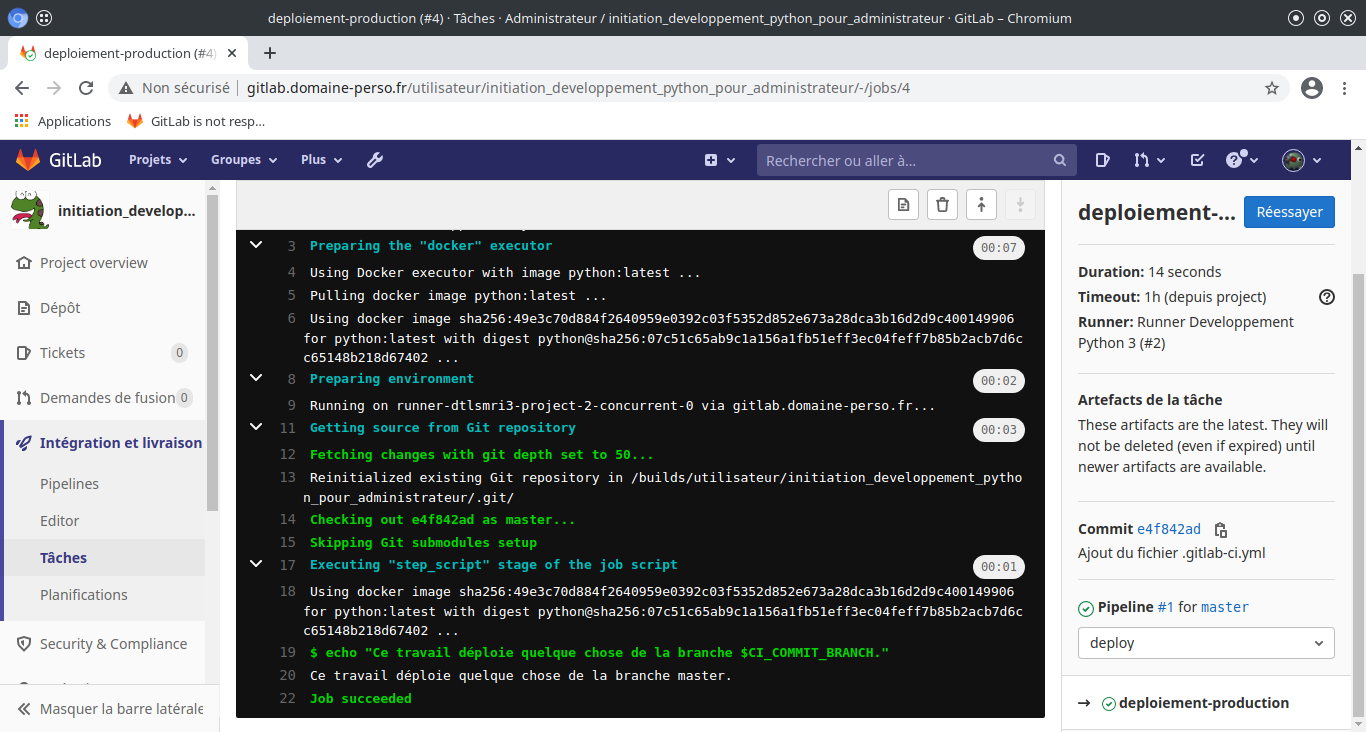
Test du déploiement docker :
default:
image: python:latest
Pour plus d’informations sur Gitlab et son utilisation SocialGouv/tutoriel-gitlab, https://makina-corpus.com/blog/metier/2019/gitlab-astuces-projets.
Tester les Pages GitLab#
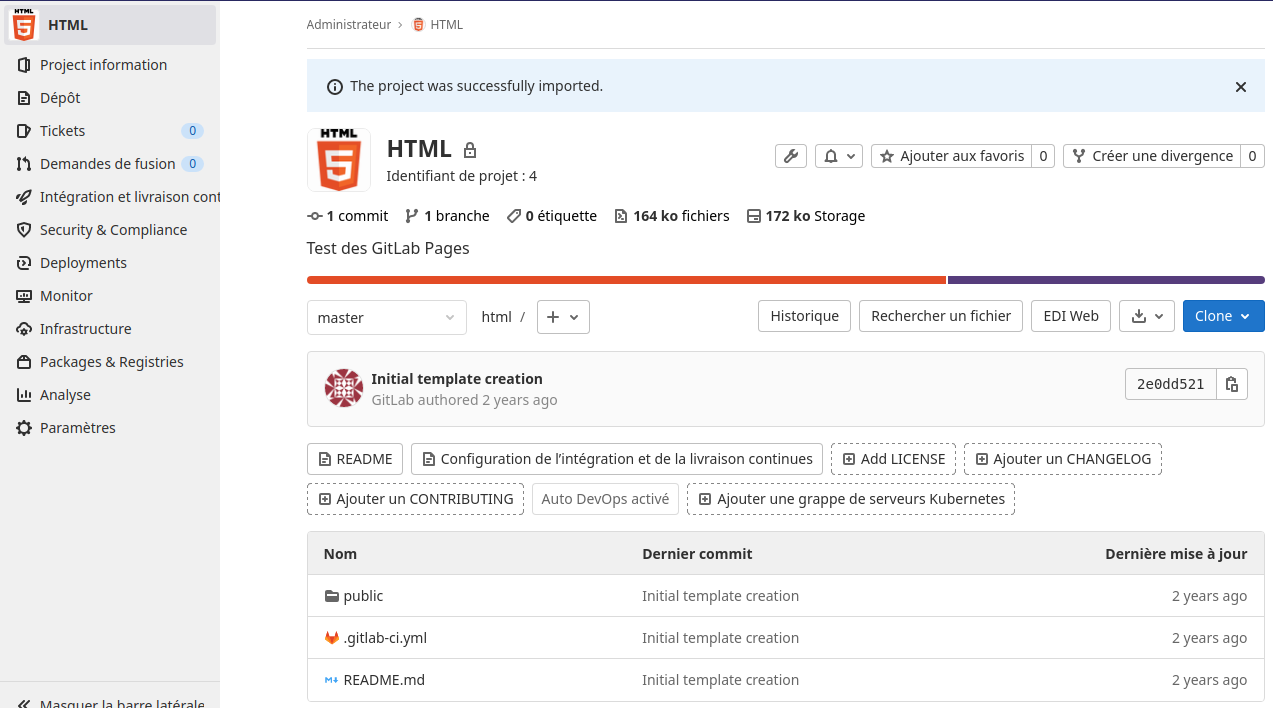
Créer un projet de rendu de pages HTML#
Créer un nouveau projet
Création depuis un modèle
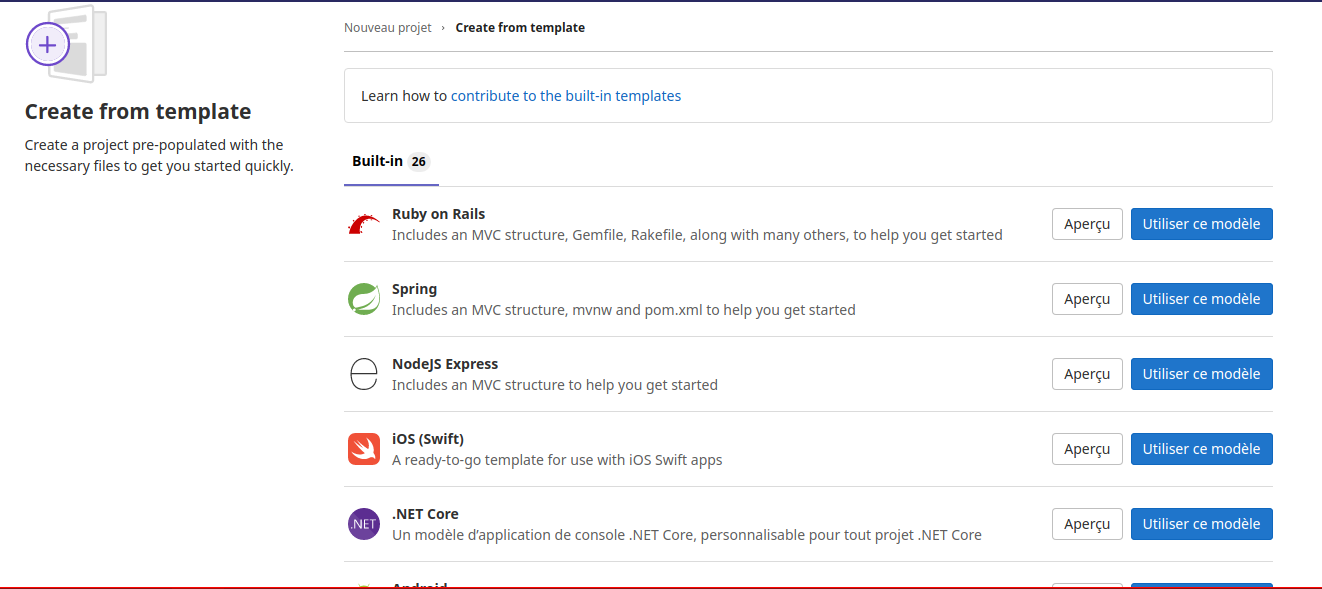
Choisir «Pages/Plain HTML» comme modèle
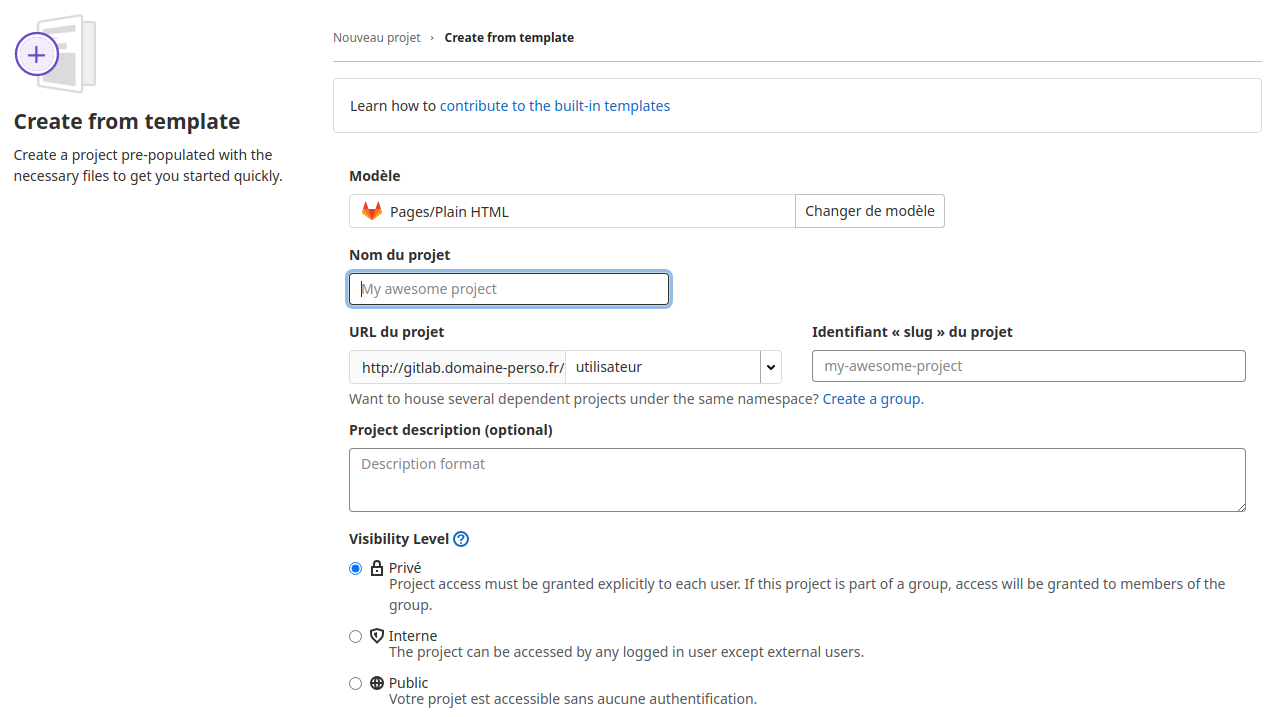
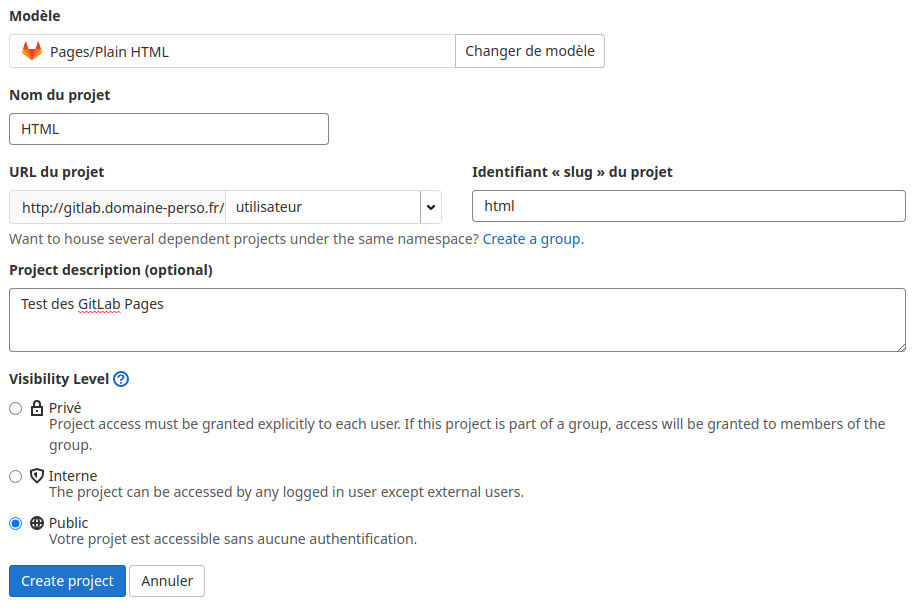
Renseignez :
le nom du projet «HTML»
La description du projet «Test des GitLab Pages»
Le niveau de sécurité «Public»
Créer le «runner» pour ce projet#
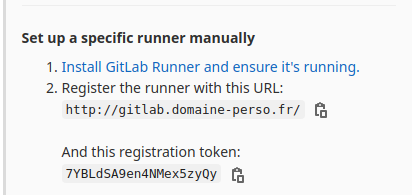
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ docker run --rm -it -v /etc/gitlab-runner:/etc/gitlab-runner gitlab/gitlab-runner register
Runtime platform arch=amd64 os=linux pid=7 revision=8925d9a0 version=14.2.0
Running in system-mode.
Enter the GitLab instance URL (for example, https://gitlab.com/): http://gitlab.domaine-perso.fr/
Enter the registration token: 7YBLdSA9en4NMex5zyQy
Enter a description for the runner: [75d626bde768]: Runner Test Pages GitLab
Enter tags for the runner (comma-separated): runner
Registering runner... succeeded runner=Tzzfs5xc
Enter an executor: kubernetes, custom, docker-ssh, shell, docker+machine, docker-ssh+machine, docker, parallels, ssh, virtualbox: docker
Enter the default Docker image (for example, ruby:2.6): alpine:latest
Runner registered successfully. Feel free to start it, but if it's running already the config should be automatically reloaded!
Changez dans «/etc/gitlab-runner/config.toml» :
concurrent = 1
check_interval = 0
[session_server]
session_timeout = 1800
[[runners]]
name = "Runner Developpement Python 3"
url = "http://gitlab.domaine-perso.fr/"
token = "9FfDsP_9Z2cXWi1Axwig"
executor = "docker"
[runners.custom_build_dir]
[runners.cache]
[runners.cache.s3]
[runners.cache.gcs]
[runners.cache.azure]
[runners.docker]
tls_verify = false
image = "python:latest"
privileged = false
disable_entrypoint_overwrite = false
oom_kill_disable = false
disable_cache = false
volumes = ["/var/run/docker.sock:/var/run/docker.sock", "/cache"]
shm_size = 0
[[runners]]
name = "Runner Test Pages GitLab"
url = "http://gitlab.domaine-perso.fr/"
token = "7YBLdSA9en4NMex5zyQy"
executor = "docker"
pull_policy = "if-not-present"
[runners.custom_build_dir]
[runners.cache]
[runners.cache.s3]
[runners.cache.gcs]
[runners.cache.azure]
[runners.docker]
tls_verify = false
image = "alpine:latest"
privileged = false
disable_entrypoint_overwrite = false
oom_kill_disable = false
disable_cache = false
volumes = ["/var/run/docker.sock:/var/run/docker.sock", "/cache"]
shm_size = 0
Vous pouvez configurer et redémarrer le Runner
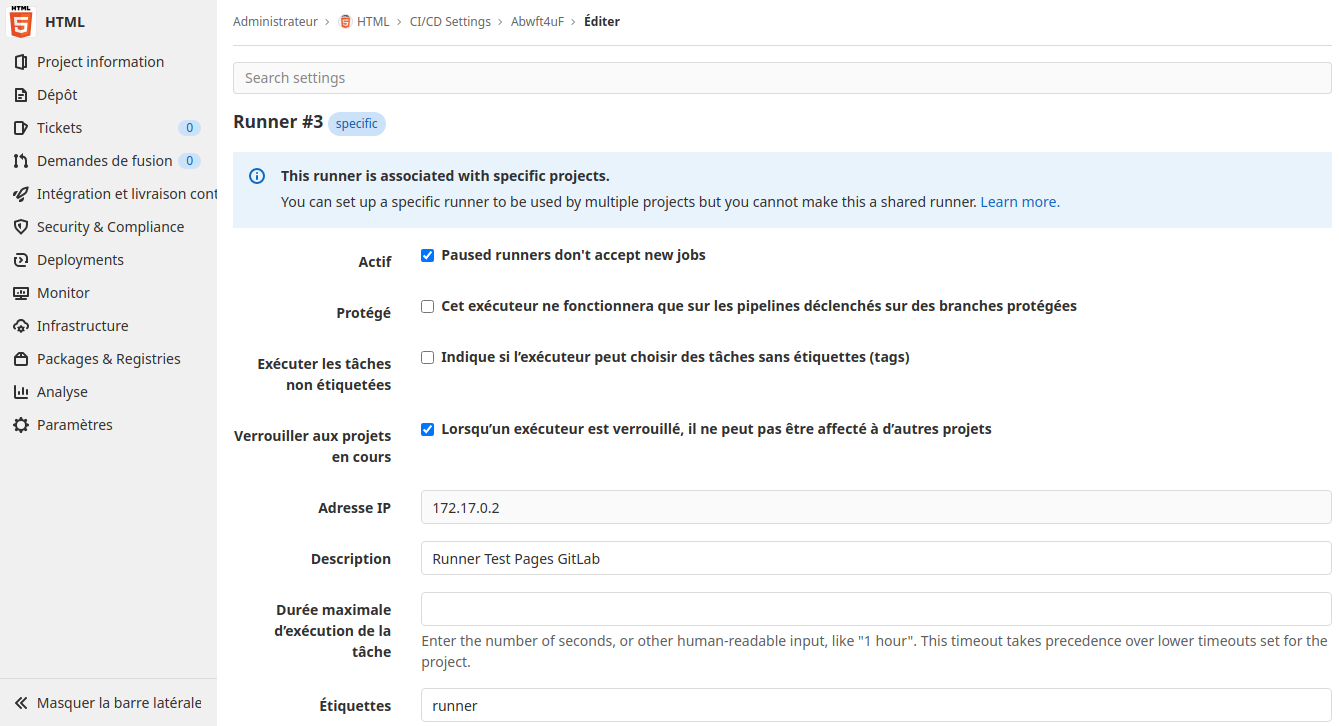
Modifiez l’option «Indique si l’exécuteur peut choisir des tâches sans étiquettes (tags)» pour l’activer. Et préciser une durrée maximale d’exécution de «30m»
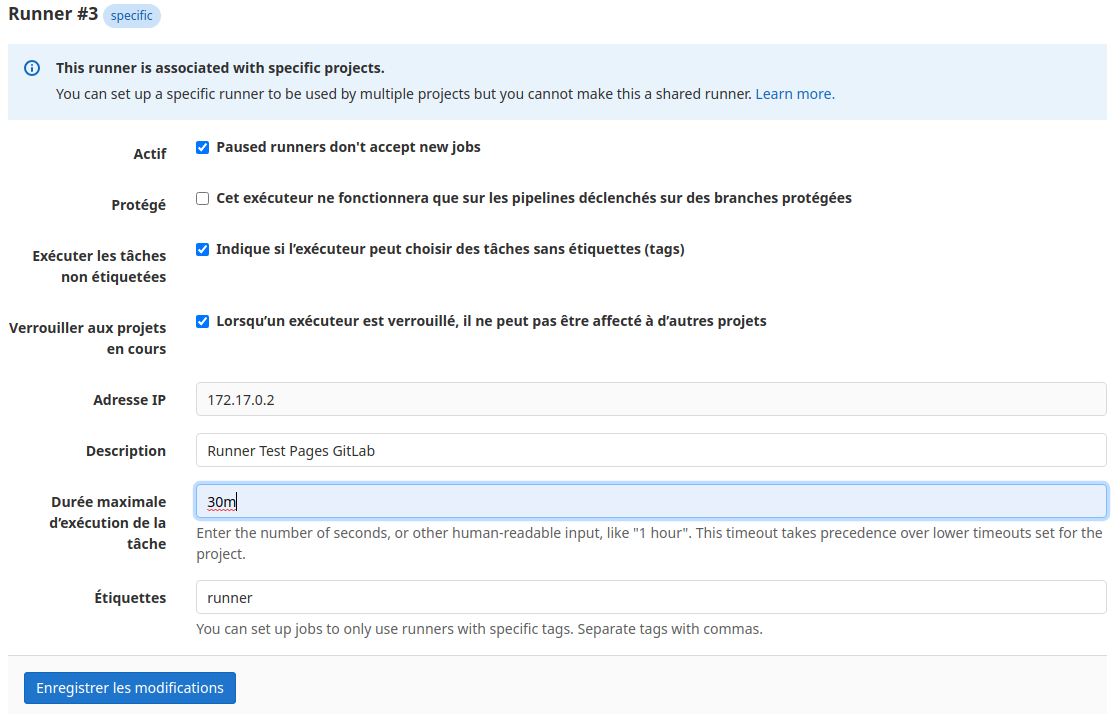
Enregirtrer les modifications et relancer le runner
Déployer et tester le HTML dans une Pages GitLab#
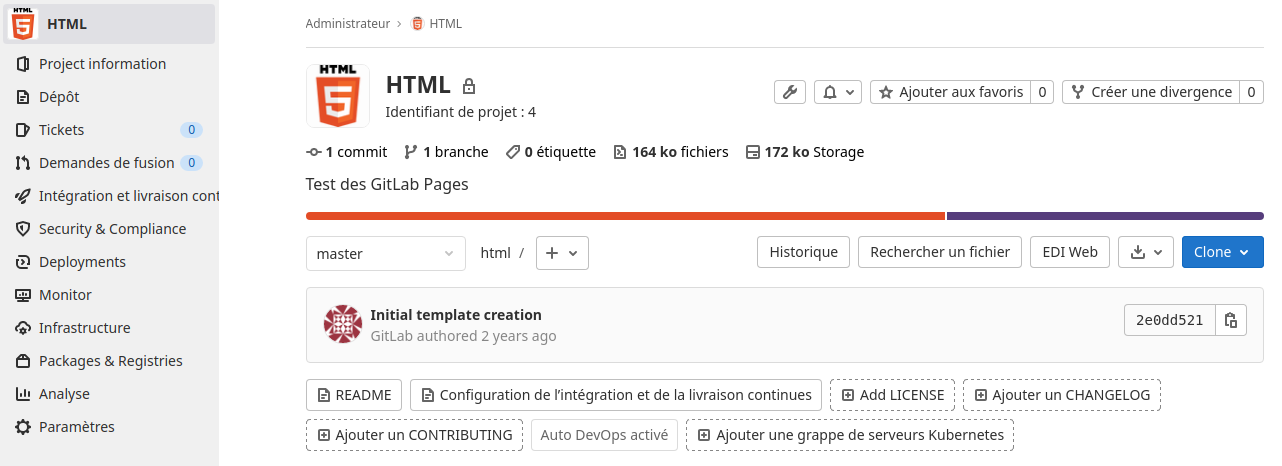
Éditer le fichier «gitlab-ci.yml» avec GitLab en cliquant sur le bouton 
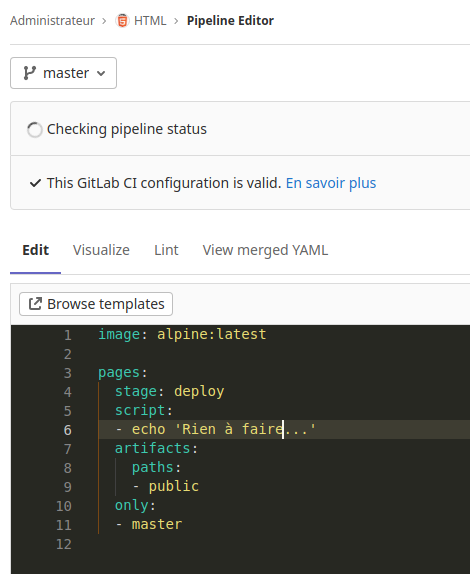
Renseigner le Message de commit «Mise à jour du fichier .gitlab-ci.yml pour le lancement du runner». Puis cliquer sur le bouton «Commit changes»

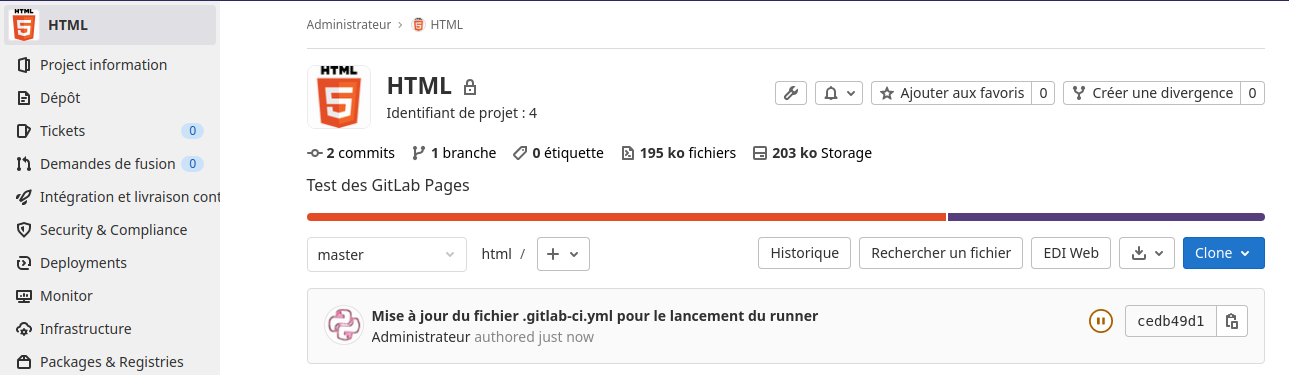
Cliquer sur la tache «Pages» sans annuler la tache ( l’icône Cancel de l’image )
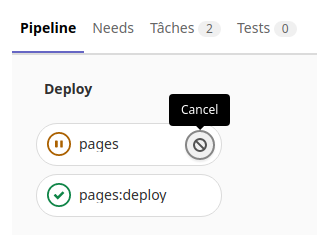
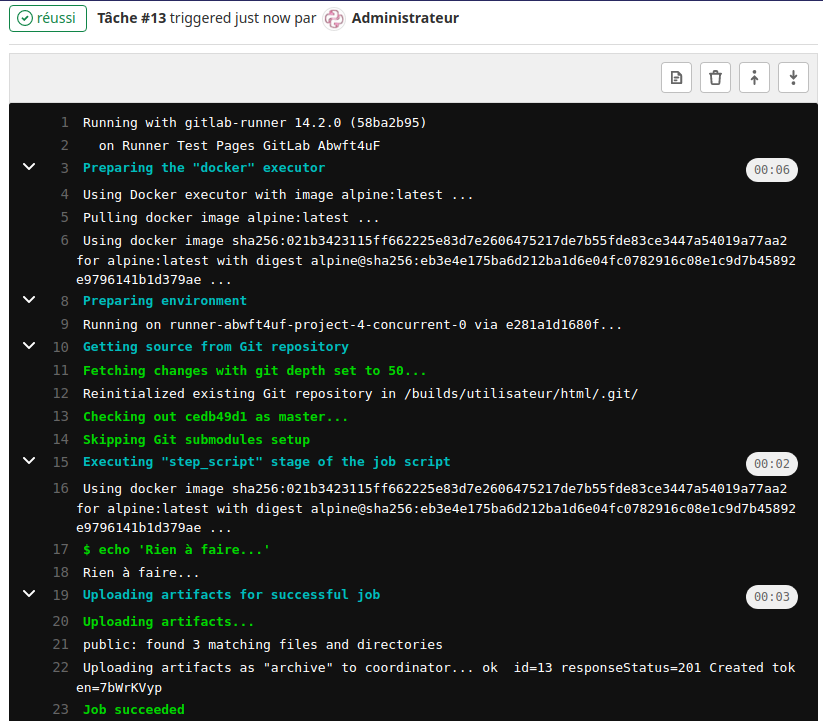
Dans le menu «Dépôt» avec le sous menu «Commits» on peut voir la réussite de la tâche suite au commit.

Maintenant il ne manque plus qu’a récupérer le site web de la page html.
Pour cela allons dans le menu «Paramètres», le sous menu «Pages» du projet.
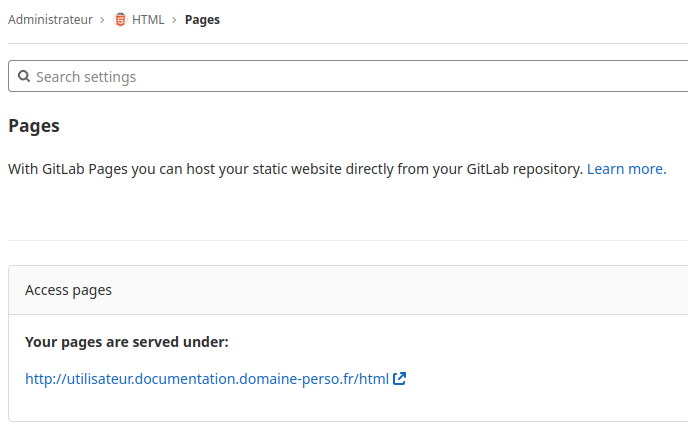
La présence du lien «http://utilisateur.documentation.domaine-perso.fr/html» nous confirme que GitLab fonctionne avec les Pages.
Un click sur ce lien et on vérifie l’accès au site web.
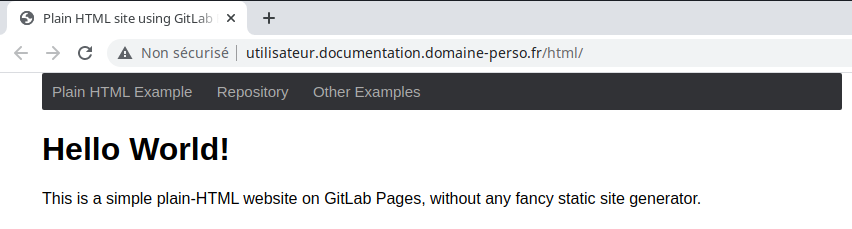
Supprimez le projet («Paramètres/Général/Advenced/Delete project»), et nettoyez le runner de test «Runner Test Pages GitLab» du fichier «/etc/gitlab-runner/config.toml».
Les principaux éléments de syntaxe#
Syntaxe et grammaire Python#
Plusieurs choses sont nécessaires pour écrire un code lisible : la syntaxe, l’organisation du code, le découpage en fonctions (et possiblement en classes que nous verrons avec les objets), mais souvent, aussi, le bon sens.
Pour cela, les «PEP» pour Python Enhancement Proposal (proposition d’amélioration de Python) peuvent nous aider.
Distribuer document pep8.pdf.On va aborder dans ce chapitre sans doute la plus célèbre des PEP, à savoir la PEP 8 https://www.python.org/dev/peps/pep-0008/, qui est incontournable lorsque l’on veut écrire du code Python correctement.
La «Style Guide for Python Code» est une des plus anciennes PEP (les numéros sont croissants avec le temps). Elle consiste en un nombre important de recommandations sur la syntaxe de Python.
Il est vivement recommandé de lire la PEP 8 en entier au moins une fois pour avoir une bonne vue d’ensemble en complément de ce cours. On ne présentera ici qu’un rapide résumé de cette PEP 8.
L’identation#
Dans la plus part des langages de programmation, l’indentation du code (c’est-à-dire la manière d’écrire le code en laissant des espaces de décalage en début des lignes) est laissée au choix éclairé du développeur. Mais, force est de constater, parfois le développeur n’est pas des plus experts pour rendre lisible par les autres, et même lui même, son code…
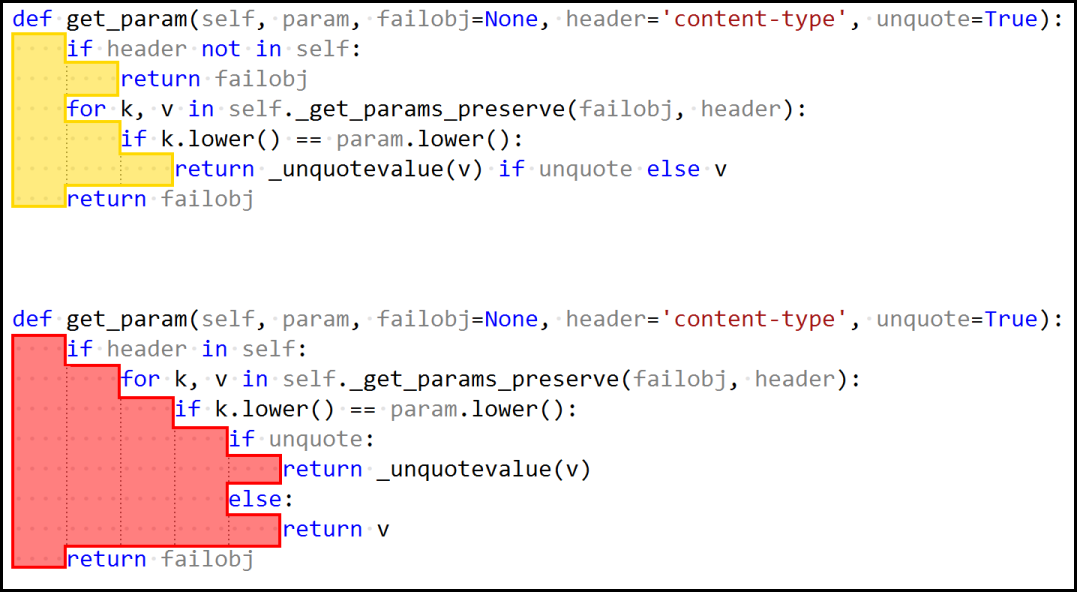
Python oblige donc le développeur à structurer son code à l’aide des indentations : ce sont elles qui détermineront les blocs (séquences d’instructions liées) et non les accolades comme dans la majorité des langages.
Les blocs de code sont déterminés par :
La présence du caractère «:» en fin de ligne ;
Une indentation des lignes suivantes à l’aide de tabulations ou d’espaces.
Attention à ne pas mélanger les tabulations avec les espaces pour l’indentation, Python n’aime pas ça du tout. Votre code ne fonctionnera pas et vous n’obtiendrez pas de message d’erreur explicite. Je conseille l’utilisation de quatre caractères espace pour faire une indentation.
Les commentaires#
Commentaires sur une ligne :
>>> # Ceci est le premier commentaire
>>> bidon = 1 # et ceci est le second commentaire
>>> # ... et là le troisième!
>>> "# Ceci n’est pas un commentaire parce qu’il est entre guillemets."
Commentaires sur plusieurs lignes :
>>> """
... Ceci est un commentaire
... en plusieurs lignes
... qui sera ignoré lors de l'exécution
... """
Chaînes de caractères#
Les chaînes de caractères (ou chaînes) sont des séquences de lettres et de nombres, ou, en d’autres termes, des morceaux de textes. Elles sont entourées par deux guillemets.
Par exemple :
>>> "Bonjour, Python!"
Comment faire si vous voulez insérer des guillemets «"» à l’intérieur d’une chaîne ?
Si vous essayez à l’interpréteur :
>>> "J'ai dit "Wow!" très fort"
File "<stdin>", line 1
"J'ai dit "Wow!" très fort"
^
SyntaxError: invalid syntax
Cela génère une erreur.
Le problème est que Python voit une chaîne, "J'ai dit " suivie de quelque chose qui n’est pas une chaîne: Wow! . Ce n’est pas ce que nous voulions!
Python propose deux moyens simples d’insérer des guillemets à l’intérieur d’une chaîne.
Vous pouvez commencer et terminer une chaîne littérale avec des apostrophes «'» à la place des guillemets, par exemple :
>>> 'bla bla'
Les guillemets peuvent ainsi être placés à l’intérieur :
>>> 'Tu as dit "Wow!" très fort.'
Vous pouvez placer une barre oblique inversée suivie du guillemet ou de l’apostrophe (" ou ' ). Cela s’appelle une séquence d’échappement.
Python va supprimer la barre oblique inversée et n’afficher que le guillemet ou l’apostrophe à l’intérieur de la chaîne. A cause des séquences d’échappement, la barre oblique inversée (\) est un symbole spécial.
Pour l’inclure dans une chaîne, il faut l’échapper avec une deuxième barre oblique inversée, en d’autres termes, il faut écrire \ dans votre chaîne littérale.
Voici un exemple que vous pouvez tester avec l’interpréteur :
>>> 'L\'exemple avec un apostrophe.'
>>> "Voici un \"échappement\" de guillemets"
>>> "Un exemple d’échappement \
... pour écrire sur plusieurs lignes\
... un texte long"
Majuscules et Minuscules (Variables, instructions, fonctions, objets)#
Nous abordons ici les règles de nommage.
Voir document pep8.pdf déjà distribué.Les noms de variables, de fonctions et de modules doivent être de la forme :
ma_variable
fonction_test_27()
mon_module
C’est-à-dire en minuscules avec un caractère «souligné» _ («tiret du bas» ou underscore en anglais) pour séparer les différents «mots» dans le nom.
Les constantes sont écrites en majuscules :
MA_CONSTANTE
VITESSE_LUMIÈRE
Les noms de classes et les exceptions sont de la forme :
MaClasse
MonException
Pensez à donner à vos variables des noms qui ont du sens.
Évitez autant que possible les a1, a2, i, truc, toto…
Les noms de variables à un caractère sont néanmoins autorisés pour les boucles et les indices :
>>> ma_liste = [1, 3, 5, 7, 9, 11]
>>> for i in range(len(ma_liste)):
... ma_liste[i]
...
...
1
3
5
7
9
11
Enfin, des noms de variable à une lettre peuvent être utilisés lorsque cela a un sens mathématique (par exemple, les noms x, y et z évoquent des coordonnées cartésiennes).
Gestion des espaces#
La PEP 8 recommande d’entourer les opérateurs +, -, /, *, ==, !=, >=, not, in, and, or… d’un espace, avant et après.
Par exemple :
# code recommandé
ma_variable = 3 + 7
mon_texte = "souris"
mon_texte == ma_variable
# code non recommandé :
ma_variable=3+7
mon_texte="souris"
mon_texte== ma_variable
Il n’y a, par contre, pas d’espace à l’intérieur des crochets [], des accolades {} et des parenthèses () :
# code recommandé :
ma_liste[1]
mon_dico{"clé"}
ma_fonction(argument)
# code non recommandé :
ma_liste[ 1 ]
mon_dico{"clé" }
ma_fonction( argument )
Ni juste avant la parenthèse ( ouvrante d’une fonction ou le crochet { ouvrant d’une liste ou d’un dictionnaire :
# code recommandé :
ma_liste[1]
mon_dico{"clé"}
ma_fonction(argument)
# code non recommandé :
ma_liste [1]
mon_dico {"clé"}
ma_fonction (argument)
On met un espace après les caractères : et , (mais pas avant) :
# code recommandé :
ma_liste = [1, 2, 3]
mon_dico = {"clé1": "valeur1", "clé2": "valeur2"}
ma_fonction(argument1, argument2)
# code non recommandé :
ma_liste = [1 , 2 ,3]
mon_dico = {"clé1":"valeur1", "clé2":"valeur2"}
ma_fonction (argument1 ,argument2)
Par contre, pour les tranches de listes, on ne met pas d’espace autour du : :
# code recommandé :
ma_liste = [1, 3, 5, 7, 9, 1]
ma_liste[1:3]
ma_liste[1:4:2]
ma_liste[::2]
# code non recommandé :
ma_liste[1 : 3]
ma_liste[1: 4:2 ]
ma_liste[ : :2]
Enfin, on n’ajoute pas plusieurs espaces autour du = ou des autres opérateurs pour faire joli :
# code recommandé :
x1 = 1
x2 = 3
x_old = 5
# code non recommandé :
x1 = 1
x2 = 3
x_old = 5
Les règles de base d’écriture des fonctions/procédures#
Maintenant que vous êtes prêt à écrire des programmes plus longs et plus complexes, il est temps de parler du style de codage. La plupart des langages peuvent être écrits (ou plutôt formatés) selon différents styles ; certains sont plus lisibles que d’autres. Rendre la lecture de votre code plus facile aux autres est toujours une bonne idée, et adopter un bon style de codage peut énormément vous y aider.
Utilisez des indentations de 4 espaces et pas de tabulations. 4 espaces constituent un bon compromis entre une indentation courte (qui permet une profondeur d’imbrication plus importante) et une longue (qui rend le code plus facile à lire). Les tabulations introduisent de la confusion et doivent être proscrites autant que possible.
Faites en sorte que les lignes ne dépassent pas 79 caractères, au besoin en insérant des retours à la ligne (actuellement cela a évolué vers 127). Vous facilitez ainsi la lecture pour les utilisateurs qui n’ont qu’un petit écran et, pour les autres, cela leur permet de visualiser plusieurs fichiers côte à côte.
Utilisez des lignes vides pour séparer les fonctions et les classes, ou pour scinder de gros blocs de code à l’intérieur de fonctions.
Lorsque c’est possible, placez les commentaires sur leurs propres lignes.
Utilisez les chaînes de documentation.
Utilisez des espaces autour des opérateurs et après les virgules, mais pas juste à l’intérieur des parenthèses :
a = f(1, 2) + g(3, 4).Nommez toujours vos classes et fonctions de la même manière ; la convention est d’utiliser une notation UpperCamelCase pour les classes, et minuscules_avec_trait_bas pour les fonctions et méthodes. Utilisez toujours
selfcomme nom du premier argument des méthodes (voyez Une première approche des classes pour en savoir plus sur les classes et les méthodes).N’utilisez pas d’encodage exotique dès lors que votre code est censé être utilisé dans des environnements internationaux. Par défaut, Python travaille en UTF-8. Préférez les caractères du simple ASCII pour votre code. N’utilisez pas de caractères exotiques lorsque votre code est censé être utilisé dans des environnements internationaux.
Utilisation de Python comme calculatrice#
L’interpréteur agit comme une simple calculatrice. Vous pouvez lui entrer une expression et il vous affiche la valeur.
Distribuer document codage_nombres.pdf.La syntaxe des expressions est simple, les opérateurs +, -, * et / fonctionnent comme dans la plupart des langages (par exemple, Pascal ou C) ; les parenthèses peuvent être utilisées pour faire des regroupements. Par exemple :
>>> 2 + 2
4
>>> 50 - 5 \ 6
20
>>> (50 - 5 * 6) / 4
5.0
>>> 8 / 5 # la division retourne toujours un nombre à virgule flottant
1.6
Les nombres entiers (comme 2, 4, 20) sont de type int, alors que les décimaux (comme 5.0, 1.6) sont de type float.
Les divisions / donnent toujours des float.
Utilisez l’opérateur // pour effectuer des divisions entières, afin d’obtenir un résultat entier.
Pour obtenir le reste d’une division entière, utilisez l’opérateur % :
>>> 17 / 3 # la division classique renvoie un nombre à virgule flottante
5.666666666666667
>>> 17 // 3 # division entière, ne tient pas compte du reste
5
>>> 17 % 3 # l’opérateur % retourne le reste de la division
2
>>> 5 * 3 + 2 # le quotien * diviseur + reste
17
En Python, il est possible de calculer des puissances avec l’opérateur ** :
>>> 5 ** 2 # 5 au carré
25
>>> 2 ** 7 # 2 à la puissance 7
128
Les nombres à virgule flottante sont tout à fait admis (Python utilise le point «.» comme séparateur entre la partie entière et la partie décimale des nombres, c’est la convention anglo-saxonne), les opérateurs avec des opérandes de types différents convertissent l’opérande de type entier en type virgule flottante :
>>> 4 * 3.75 - 1
14.0
En plus des int et des float, il existe les Décimal et les Fraction avec l’utilisation d’une bibliothèque.
Python gère aussi les nombres complexes, en utilisant le suffixe «j» ou «J» pour indiquer la partie imaginaire (tel que 3+5j).
>>> (3+5j) * (3-5j)
(34+0j)
>>> _.conjugate()
(34+0j)
>>> (34+0j).real
34.0
>>> 34 + 0j
(34+0j)
>>> _.imag
0.0
Les variables#
L’affectation dans le code#
Le signe égal = est utilisé pour affecter une valeur à une variable.
Dans ce cas, aucun résultat n’est affiché avant l’invite suivante :
>>> largeur = 20
>>> hauteur = 5 * 9
>>> largeur * hauteur
900
Si une variable n’est pas définie (si aucune valeur ne lui a été affectée), son utilisation produit une erreur :
>>> n # Essaye d'accéder à une variable non définie
Traceback (most recent call last):
File "<input>", line 1, in <module>
n # Essaye d'accéder à une variable non définie
NameError: name 'n' is not defined
En mode interactif, la dernière expression affichée est affectée à la variable _. Ainsi, lorsque vous utilisez Python comme calculatrice, cela vous permet de continuer des calculs facilement, par exemple :
>>> taxe = 12.5 / 100
>>> prix = 100.50
>>> prix * taxe
12.5625
>>> prix + _
113.0625
>>> round(_, 2)
113.06
Cette variable doit être considérée comme une variable en lecture seule par l’utilisateur. N’affectez pas de valeur explicitement à _. Vous créeriez ainsi une variable locale indépendante, avec le même nom, qui masquerait la variable native et son fonctionnement magique.
L’affectation au clavier#
La fonction input#
>>> nom = input('Saisissez votre nom : ')
Saisissez votre nom : PERSONNE
>>> 'Bonjour ' + nom
'Bonjour PERSONNE'
L’affectation par variables passées à un script#
Passage d’arguments en ligne de commande#
Python supporte complètement la création de programmes qui peuvent être lancés en ligne de commande, à l’aide d’arguments et de drapeaux longs ou cours pour spécifier diverses options.
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ mkdir 4_Passage_paramètres ; cd 4_Passage_paramètres
utilisateur@MachineUbuntu:~/repertoire_de_developpement/4_Passage_paramètres$ nano litparams.py ; chmod u+x litparams.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import sys
for arg in sys.argv:
print(arg)
utilisateur@MachineUbuntu:~/repertoire_de_developpement/4_Passage_paramètres$ ./litparams.py -a --help bidon
utilisateur@MachineUbuntu:~/repertoire_de_developpement/4_Passage_paramètres$ nano litargs.py ; chmod u+x litargs.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import sys
print('Nombre d\'arguments :', len(sys.argv), 'arguments.')
print('Liste des arguments :', str(sys.argv))
utilisateur@MachineUbuntu:~/repertoire_de_developpement/4_Passage_paramètres$ ./litargs.py -a --help bidon ; cd ..
L’affichage d’informations#
Il existe bien des moyens de présenter les sorties d’un programmes ; les données peuvent être affichées sous une forme lisible par un être humain ou sauvegardées dans un fichier pour une utilisation future. Cette partie présente quelques possibilités.
À l’écran du terminal#
print()
Formatage de données#
Souvent vous voudrez plus de contrôle sur le formatage de vos sorties chaîne de caractères et aller au delà d’un affichage de valeurs séparées par des espaces. Il y a plusieurs moyens de formater ces chaînes de caractères pour l’affichage
Les expressions formatées f' {} '#
Commencez une chaîne de caractère avec f ou F avant d’ouvrir vos guillemets doubles ou simple. Dans ces chaînes de caractère, vous pouvez entrer des expressions Python entre les accolades {} qui peuvent contenir des variables ou des valeurs littérales.
>>> année = 2005
>>> évènement = 'Sky'
>>> f'En {année} : {évènement}'
'En 2005 : Sky'
La méthode str.format()#
Les chaînes de caractères exige un plus grand effort manuel. Vous utiliserez toujours les accolades {} pour indiquer où une variable sera substituée et suivant des détails sur son formatage. Vous devrez également fournir les informations à formater.
>>> votes_oui = 42572654
>>> votes_non = 43132495
>>> pourcentage = votes_oui / (votes_oui + votes_non)
>>> '{:-9} votes OUI {:2.2%}'.format(votes_oui, pourcentage)
' 42572654 votes OUI 49.67%'
Concaténations de tranches de chaînes#
Enfin, vous pouvez construire des concaténations de chaînes vous-même et modifier leur format texte, et ainsi créer n’importe quel agencement.
Le type des chaînes a des méthodes utiles pour aligner des chaînes, pour afficher suivant une taille fixe, suivant la casse, etc.
>>> s = 'coucou mon texte'
>>> dir(s)
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isascii', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
La bibliothèque de fonctions «string» contient une classe Template qui permet aussi de remplacer des valeurs au sein de chaînes de caractères, en utilisant des marqueurs comme $x, et en les remplaçant par les valeurs d’un dictionnaire, mais sa capacité à formater les chaînes est plus limitée.
La sortie en chaînes de caractères#
Lorsqu’un affichage basique suffit, pour afficher simplement une variable pour en inspecter le contenu, vous pouvez convertir n’importe quelle valeur ou objet en chaîne de caractères en utilisant la fonction repr() ou la fonction str().
La fonction str() est destinée à représenter les valeurs sous une forme lisible par un être humain.
La fonction repr() est destinée à générer des représentations qui puissent être lues par l’interpréteur (ou qui lèvera une SyntaxError s’il n’existe aucune syntaxe équivalente).
Pour les objets qui n’ont pas de représentation humaine spécifique, str() renvoie la même valeur que repr().
Beaucoup de valeurs, comme les nombres ou les structures telles que les listes ou les dictionnaires, ont la même représentation en utilisant les deux fonctions. Les chaînes de caractères, en particulier, ont deux représentations distinctes.
Quelques exemples :
>>> s = 'Bonjour à tous :-)'
>>> str(s)
'Bonjour à tous :-)'
>>> repr(s)
"'Bonjour à tous :-)'"
>>> str(1/7)
'0.14285714285714285'
>>> x = 10 * 3.25
>>> y = 200 * 200
>>> s = 'La valeur de x est ' + repr(x) + ', et celle de y est ' + repr(y) + '...'
>>> print(s)
La valeur de x est 32.5, et celle de y est 40000...
>>> # repr() ajoute les guillemets et les barres obliques inverses d'une chaîne
>>> salut = 'Bonjour à tous :-)\n'
>>> salutations = repr(salut)
>>> print(salutations)
'Bonjour à tous :-)\n'
>>> # L'argument de repr() peut être n'importe quel objet Python
>>> repr((x, y, ('bidon', 'œufs')))
"(32.5, 40000, ('bidon', 'œufs'))"
Les chaînes de caractères formatées (f-strings)#
Les chaînes de caractères formatées f'' (aussi appelées f-strings) vous permettent d’inclure la valeur d’expressions Python dans des chaînes de caractères en les préfixant avec «f» ou «F» et écrire des expressions comme {expression}.
L’expression peut être suivie d’un spécificateur de format. Cela permet un plus grand contrôle sur la façon dont la valeur est rendue. L’exemple suivant arrondit pi à trois décimales après la virgule :
>>> import math
>>> print(f'La valeur de pi est approximativement {math.pi:.3f}.')
La valeur de pi est approximativement 3.142.
Donner un entier après les “:” f'{variable:10}' indique la largeur minimale de ce champ en nombre de caractères. C’est utile pour faire de jolis tableaux :
>>> table = {'Sylvie': 4127, 'Jacques': 4098, 'David': 7678}
>>> for nom, téléphone in table.items():
... print(f'{nom:10} ==> {téléphone:10d}')
...
...
Sylvie ==> 4127
Jacques ==> 4098
David ==> 7678
D’autres modificateurs peuvent être utilisés pour convertir la valeur avant son formatage. «!a» applique la fonction ascii(), «!s» applique la fonction :str(), et «!r» applique la fonction repr() :
>>> animaux = 'rats Womp'
>>> print(f'Mon aéroglisseur est plein de {animaux}.')
Mon aéroglisseur est plein de rats Womp.
>>> print(f'Mon aéroglisseur est plein de {animaux!r}.')
Mon aéroglisseur est plein de 'rats Womp'.
Pour plus d’informations sur ces spécifications de formats, voir dans le guide Python en ligne «Mini-langage de spécification de format».
La méthode de chaîne de caractères format()#
L’utilisation de base de la méthode str.format() ressemble à ceci :
>>> print('Le {} nous dit "{}!"'.format('Sith', 'utilise le coté obscur de la force'))
Le Sith nous dit "utilise le coté obscur de la force!"
Les accolades et les caractères à l’intérieur (appelés les champs de formatage) sont remplacés par les objets passés en paramètres à la méthode str.format(). Un nombre entre accolades se réfère à la position de l’objet passé à la méthode str.format().
>>> print('{0} et {1}'.format('bidon', 'pub'))
bidon et pub
>>> print('{1} et {0}'.format('bidon', 'pub'))
pub et bidon
Si des arguments nommés sont utilisés dans la méthode str.format(), leurs valeurs sont utilisées en se basant sur le nom des arguments
>>> print('Cet aliment {nourriture} est {qualité}.'.format(nourriture = 'hamburger', qualité='chimique'))
Cet aliment hamburger est chimique.
Les arguments positionnés et nommés peuvent être combinés arbitrairement :
>>> print('L’histoire de {0}, {1}, et {autre}.'.format('Bernard', 'Martin', autre='George'))
L’histoire de Bernard, Martin, et George.
Si vous avez une chaîne de formatage vraiment longue que vous ne voulez pas découper, il est possible de référencer les variables à formater par leur nom plutôt que par leur position. Utilisez simplement un dictionnaire et la notation entre crochets «[]» pour accéder aux clés.
>>> table = {'Sylvie': 4127, 'Jacques': 4098, 'Daniel': 8637678}
>>> print('Jacques: {0[Jacques]:d}; Sylvie: {0[Sylvie]:d}; ' 'Daniel: {0[Daniel]:d}'.format(table))
Jacques: 4098; Sylvie: 4127; Daniel: 8637678
Vous pouvez obtenir le même résultat en passant le tableau comme des arguments nommés en utilisant la notation «**».
>>> table = {'Sylvie': 4127, 'Jacques': 4098, 'Daniel': 8637678}
>>> print('Jacques: {Jacques:d}; Sylvie: {Sylvie:d}; Daniel: {Daniel:d}'.format(**table))
Jacques: 4098; Sylvie: 4127; Daniel: 8637678
C’est particulièrement utile en combinaison avec la fonction native vars() qui renvoie un dictionnaire contenant toutes les variables locales.
A titre d’exemple, les lignes suivantes produisent un ensemble de colonnes alignées de façon ordonnée donnant les entiers, leurs carrés et leurs cubes :
>>> for x in range(1, 11):
... print('{0:2d} {1:3d} {2:4d}'.format(x, x*x, x*x*x))
...
...
1 1 1
2 4 8
3 9 27
4 16 64
5 25 125
6 36 216
7 49 343
8 64 512
9 81 729
10 100 1000
Pour avoir une description complète du formatage des chaînes de caractères avec la méthode str.format(), lisez «Syntaxe de formatage de chaîne».
Logs Système#
Utiliser logging#
Nous allons aborder ici en avance un module logging qui fournit un ensemble de fonctions pour une utilisation simple d’affichages de logs dans une application avec une possibilité de filtrage de la verbosité.
Ces fonctions sont debug(), info(), warning(), error() et critical().
Pour déterminer quand employer la journalisation, voyez la table ci-dessous, qui vous indique, pour chaque tâche parmi les plus communes, l’outil approprié.
Tâche que vous souhaitez mener |
Le meilleur outil pour cette tâche |
|---|---|
Affiche la sortie console d’un script en ligne de commande ou d’un programme lors de son utilisation ordinaire |
|
Rapporter des évènements qui ont lieu au cours du fonctionnement normal d’un programme (par exemple pour suivre un statut ou examiner des dysfonctionnements) |
ou pour une sortie très détaillée à visée diagnostique |
Émettre un avertissement (warning en anglais) en relation avec un évènement particulier au cours du fonctionnement d’un programme |
dans le code de la bibliothèque si le problème est évitable et l’application cliente doit être modifiée pour éliminer cet avertissement si l’application cliente ne peut rien faire pour corriger la situation mais l’évènement devrait quand même être noté |
Rapporter une erreur lors d’un évènement particulier en cours d’exécution |
Lever une exception |
Rapporter la suppression d’une erreur sans lever d’exception (par exemple pour la gestion d’erreur d’un processus de long terme sur un serveur) |
au mieux, selon l’erreur spécifique et le domaine d’application |
Les fonctions de journalisation sont nommées d’après le niveau ou la sévérité des évènements qu’elles suivent. Les niveaux standards et leurs applications sont décrits ci-dessous (par ordre croissant de sévérité) :
Niveau |
Pourqoi c’est utilisé |
|---|---|
DEBUG |
Information détaillée, intéressante seulement lorsqu’on diagnostique un problème. |
INFO |
Confirmation que tout fonctionne comme prévu. |
WARNING |
L’indication que quelque chose d’inattendu a eu lieu, ou de la possibilité d’un problème dans un futur proche (par exemple « espace disque faible »). Le logiciel fonctionne encore normalement. |
ERROR |
Du fait d’un problème plus sérieux, le logiciel n’a pas été capable de réaliser une tâche. |
CRITICAL |
Une erreur sérieuse, indiquant que le programme lui-même pourrait être incapable de continuer à fonctionner. |
Le niveau par défaut est WARNING, ce qui signifie que seuls les évènements de ce niveau et au-dessus sont suivis, sauf si le paquet logging est configuré pour faire autrement.
Les évènements suivis peuvent être gérés de différentes façons. La manière la plus simple est de les afficher dans la console. Une autre méthode commune est de les écrire dans un fichier.
Un exemple simple#
Un exemple très simple est :
>>> import logging
>>> logging.warning('Attention!') # affiche un message dans la console
WARNING:root:Attention!
>>> logging.info('C’est bon relâche la pression') # n’imprime rien
Si vous entrez ces lignes dans un script que vous exécutez, vous verrez WARNING:root:Attention! » affiché dans la console. Le message INFO n’apparaît pas parce que le niveau par défaut est WARNING. Le message affiché inclut l’indication du niveau et la description de l’évènement fournie dans l’appel à logging, ici «Attention!». Ne vous préoccupez pas de la partie «root» pour le moment : nous détaillerons ce point plus bas. La sortie elle-même peut être formatée de multiples manières si besoin. Les options de formatage seront aussi expliquées plus bas.
Enregistrer les évènements dans un fichier#
Il est très commun d’enregistrer les évènements dans un fichier, c’est donc ce que nous allons regarder maintenant. Il faut essayer ce qui suit avec un interpréteur Python nouvellement démarré, ne poursuivez pas la session commencée ci-dessus :
>>> import logging
>>> logging.basicConfig(filename='./exemple.log', encoding='utf-8', level=logging.DEBUG)
>>> logging.debug('Ce message doit aller dans le fichier journal')
>>> logging.info('Celui là aussi')
>>> logging.warning('Et encore celui-ci')
>>> logging.error('Et des trucs non-ASCII aussi, comme Fêtes de Noël')
Modifié dans la version 3.9: L’argument d’encodage a été ajouté.
Dans les versions antérieures de Python ou lorsqu’il n’est pas spécifié, l’encodage utilisé est la valeur par défaut utilisée par open().
Bien que cela ne soit pas montré dans l’exemple ci-dessus, un argument d’erreurs peut également maintenant être passé, qui détermine comment les erreurs de codage sont gérées. Pour les valeurs disponibles et les valeurs par défaut, consultez la documentation de open().
Maintenant, si nous ouvrons le fichier «exemple.log» et lisons ce qui s’y trouve, on trouvera les messages de log :
DEBUG:root:Ce message doit aller dans le fichier journal
INFO:root:Celui là aussi
WARNING:root:Et encore celui-ci
ERROR:root:Et des trucs non-ASCII aussi, comme Fêtes de Noël
Cet exemple montre aussi comment on peut régler le niveau de journalisation qui sert de seuil pour le suivi. Dans ce cas, comme nous avons réglé le seuil à DEBUG, tous les messages ont été écrits.
Régler le niveau de journalisation d’un script#
Si vous souhaitez régler le niveau de journalisation à partir d’une option de la ligne de commande comme :
--log=INFO
Créer avec votre éditeur de texte le fichier «niveau_journalisation.py».
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ mkdir 5_Niveau_journalisation ; cd 5_Niveau_journalisation
utilisateur@MachineUbuntu:~/repertoire_de_developpement/5_Niveau_journalisation$ nano niveau_journalisation.py ; chmod u+x niveau_journalisation.py
#! /usr/bin/env python3
# -*- coding: utf8 -*-
import argparse, logging
# Récupère l'argument de la ligne de commande du paramètre log et le met dans la variable loglevel
params = argparse.ArgumentParser()
params.add_argument('--log')
args = params.parse_args()
loglevel = args.log
# Défini le niveau de journalisation
if loglevel:
numeric_level = getattr(logging, loglevel.upper())
else:
numeric_level = logging.DEBUG
# Teste si le paramètre est valide
if not isinstance(numeric_level, int):
raise ValueError('Niveau de journalisation invalide : %s' % loglevel)
# Configure le niveau de journalisation et le fichier où journaliser
logging.basicConfig(filename='niveau.log', filemode='w', level=numeric_level)
# Messages de tests
logging.error('Message erreur')
logging.warning('Message alerte')
logging.info('Message information')
logging.debug('Message debug')
Vous passez la valeur du paramètre donné à l’option --log dans une variable loglevel. L’appel à basicConfig() doit être fait avant un appel à debug(), info(), etc. Si vous exécutez le script plusieurs fois sans l’option «filemode», les messages des exécutions successives sont ajoutés au fichier «niveau.log».
Si vous voulez que chaque exécution reprenne un fichier vierge, sans conserver les messages des exécutions précédentes, vous devez spécifier l’argument filemode à 'w'. Le texte n’est plus ajouté au fichier de log, donc les messages des exécutions précédentes sont perdus.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/5_Niveau_journalisation$ ./niveau_journalisation.py
utilisateur@MachineUbuntu:~/repertoire_de_developpement/5_Niveau_journalisation$ cat niveau.log
ERROR:root:Message erreur
WARNING:root:Message alerte
INFO:root:Message information
DEBUG:root:Message debug
utilisateur@MachineUbuntu:~/repertoire_de_developpement/5_Niveau_journalisation$ python3 ./niveau_journalisation.py --log=DEBUG
utilisateur@MachineUbuntu:~/repertoire_de_developpement/5_Niveau_journalisation$ cat niveau.log
ERROR:root:Message erreur
WARNING:root:Message alerte
INFO:root:Message information
DEBUG:root:Message debug
utilisateur@MachineUbuntu:~/repertoire_de_developpement/5_Niveau_journalisation$ python3 ./niveau_journalisation.py --log=INFO
utilisateur@MachineUbuntu:~/repertoire_de_developpement/5_Niveau_journalisation$ cat niveau.log
ERROR:root:Message erreur
WARNING:root:Message alerte
INFO:root:Message information
utilisateur@MachineUbuntu:~/repertoire_de_developpement/5_Niveau_journalisation$ python3 ./niveau_journalisation.py --log=WARNING
utilisateur@MachineUbuntu:~/repertoire_de_developpement/5_Niveau_journalisation$ cat niveau.log
ERROR:root:Message erreur
WARNING:root:Message alerte
utilisateur@MachineUbuntu:~/repertoire_de_developpement/5_Niveau_journalisation$ python3 ./niveau_journalisation.py --log=ERROR
utilisateur@MachineUbuntu:~/repertoire_de_developpement/5_Niveau_journalisation$ cat niveau.log
ERROR:root:Message erreur
utilisateur@MachineUbuntu:~/repertoire_de_developpement/5_Niveau_journalisation$ python3 ./niveau_journalisation.py --log=BIDON ; cd ..
Traceback (most recent call last):
File "./niveau_journalisation.py", line 14, in <module>
numeric_level = getattr(logging, loglevel.upper())
AttributeError: module 'logging' has no attribute 'BIDON'
Modifier le format du message affiché#
Pour changer le format utilisé pour afficher le message, vous devez préciser le format que vous souhaitez employer :
>>> import logging
>>> logging.basicConfig(format='%(levelname)s:%(message)s', level=logging.DEBUG)
>>> logging.debug('Message d’analyse de code')
DEBUG:Message d’analyse de code
>>> logging.basicConfig(format='Mon programme %(levelname)s:%(lineno)d:%(pathname)s:%(message)s', level=logging.DEBUG, force=True)
>>> logging.debug('Message d’analyse de code')
Mon programme DEBUG:1:<bpython-input-7>:Message d’analyse de code
>>> logging.info('Message d’information')
Mon programme INFO:1:<bpython-input-8>:Message d’information
>>> logging.warning('Attention!')
Mon programme WARNING:1:<bpython-input-9>:Attention!
GUI#
Gui intégré client lourd (Windows, gtk, qt, etc.).
Gui web (remi, django, etc.).
On verra cela plus loin dans le cours.
Les types de variables#
Logique#
Booléen#
>>> a = True
>>> type(a)
<class 'bool'>
>>> b = False
>>> type(b)
<class 'bool'>
Les tests
>>> a = 10 > 9
>>> a
True
>>> a = 10 == 9
>>> a
False
Les valeurs vraie
>>> bool("abc")
True
>>> bool(123)
True
>>> bool(["apple", "cherry", "banana"])
True
Les valeurs Nules
bool(False)
bool(None)
bool(0)
bool("")
bool(())
bool([])
bool({})
Chaînes de caractères#
Chaîne de caractère ASCII#
Python 3
byte()
Python 2
str()
Chaîne de caractère Unicode#
Python 3
str()
Python 2
unicode()
Manipulation des chaînes de caractères#
Python sait manipuler des chaînes de caractères, qui peuvent être exprimées de différentes manières. Elles peuvent être écrites entre guillemets anglo-saxon simples ('…') ou entre guillemets anglo-saxon doubles ("…") sans distinction. \ peut aussi être utilisé pour protéger un guillemet :
>>> 'inutile bidon' # simples quotes
'inutile bidon'
>>> 'L\'apostrophe' # utilise \\' pour échapper le simple quote…
"L'apostrophe"
>>> "L'apostrophe" # …ou on utilise des doubles quotes
"L'apostrophe"
>>> 'Son nom est "Personne"'
'Son nom est "Personne"'
>>> "Son nom est \"Personne\""
'Son nom est "Personne"'
>>> 'Python c’est "l\'avenir"'
'Python c’est "l\'avenir"'
En mode interactif, l’interpréteur affiche les chaînes de caractères entre guillemets. Les guillemets et autres caractères spéciaux sont protégés avec des barres obliques inverses (backslash en anglais). Bien que cela puisse être affiché différemment de ce qui a été entré (les guillemets peuvent changer), les deux formats sont équivalents. La chaîne est affichée entre guillemets si elle contient un guillemet simple et aucun guillemet, sinon elle est affichée entre guillemets simples. La fonction print() affiche les chaînes de manière plus lisible, en retirant les guillemets et en affichant les caractères spéciaux qui étaient protégés par une barre oblique inverse :
>>> print('Python c’est "l\'avenir"')
Python c’est "l'avenir"
>>> s = 'Première ligne.\nSeconde ligne.' # \n c’est nouvelle ligne
>>> s # sans print(), \n est incluse dans la sortie
'Première ligne.\nSeconde ligne.'
>>> print(s) # avec print(), \n est traduit comme une nouvelle ligne
Première ligne.
Seconde ligne.
Si vous ne voulez pas que les caractères précédés d’un \ soient interprétés comme étant spéciaux, utilisez les chaînes brutes (raw strings en anglais) en préfixant la chaîne d’un r :
>>> print('C:\son\nom') # \n veut dire nouvelle ligne!
C:\son
om
>>> print(r'C:\son\nom') # avec r avant le quote
C:\son\nom
Les chaînes de caractères peuvent s’étendre sur plusieurs lignes. Utilisez alors des triples guillemets, simples ou doubles : '''…''' ou """…""". Les retours à la ligne sont automatiquement inclus, mais on peut l’empêcher en ajoutant \ à la fin de la ligne. L’exemple suivant :
>>> print("""\
... Utilisation: programme [OPTIONS]
... -h Affiche ce message d’utilisation
... -H nomMachine Nom de la machine où se connecter
... """)
produit l’affichage suivant (notez que le premier retour à la ligne n’est pas inclus) :
Utilisation: programme [OPTIONS]
-h Affiche ce message d’utilisation
-H nomMachine Nom de la machine où se connecter
Les chaînes peuvent être concaténées (collées ensemble) avec l’opérateur «+» et répétées avec l’opérateur «*» :
>>> # 2 fois 'an', suivit par 'as'
>>> 2 * 'an' + 'as'
'ananas'
Plusieurs chaînes de caractères, écrites littéralement (c’est-à-dire entre guillemets), côte à côte, sont automatiquement concaténées.
>>> 'Py' 'thon'
'Python'
Cette fonctionnalité est surtout intéressante pour couper des chaînes trop longues :
>>> texte = ('Mettez plusieurs chaînes entre les parenthèses '
... 'pour les avoir réunis.')
>>> texte
'Mettez plusieurs chaînes entre les parenthèses pour les avoir réunis.'
Cela ne fonctionne cependant qu’avec les chaînes littérales, pas avec les variables ni les expressions :
>>> prefixe = 'Py'
>>> prefixe 'thon' # impossible de concaténer une variable et une chaîne littérale
File "<input>", line 1
prefixe 'thon' # impossible de concaténer une variable et une chaîne littérale
^
SyntaxError: invalid syntax
>>> ('un' * 3) 'ium'
File "<input>", line 1
('un' * 3) 'ium'
^
SyntaxError: invalid syntax
Pour concaténer des variables, ou des variables avec des chaînes littérales, utilisez l’opérateur «+» :
>>> prefixe + 'thon'
'Python'
Les chaînes de caractères peuvent être indexées (ou indicées, c’est-à-dire que l’on peut accéder aux caractères par leur position), le premier caractère d’une chaîne étant à la position 0. Il n’existe pas de type distinct pour les caractères, un caractère est simplement une chaîne de longueur 1 :
Pour visualiser la façon dont les indices fonctionnent
Position : 1 2 3 4 5 6
+---+---+---+---+---+---+
| P | y | t | h | o | n |
+---+---+---+---+---+---+
Indice : 0 1 2 3 4 5
Exemples :
>>> mot = 'Python'
>>> mot[0] # caractère en position 1
'P'
>>> mot[5] # caractère en position 6
'n'
Les indices peuvent également être négatifs, on compte alors en partant de la droite. Par exemple :
Pour visualiser la façon dont les indices négatifs fonctionnent
Position : 1 2 3 4 5 6
+---+---+---+---+---+---+
| P | y | t | h | o | n |
+---+---+---+---+---+---+
Indice : -6 -5 -4 -3 -2 -1
Exemples :
>>> mot[-1] # dernier caractère
'n'
>>> mot[-2] # avant-dernier caractère
'o'
>>> mot[-6]
'P'
Notez que, comme -0 égale 0, les indices négatifs commencent par -1.
En plus d’accéder à un élément par son indice, il est aussi possible de « trancher » (slice en anglais) une chaîne. Accéder à une chaîne par un indice permet d’obtenir un caractère, trancher permet d’obtenir une sous-chaîne :
Pour mémoriser la façon dont les tranches fonctionnent, vous pouvez imaginer que les indices pointent entre les caractères, le côté gauche du premier caractère ayant la position 0. Le côté droit du dernier caractère d’une chaîne de n caractères a alors pour indice n.
Position : 1 2 3 4 5 6
+---+---+---+---+---+---+
| P | y | t | h | o | n |
+---+---+---+---+---+---+
0 1 2 3 4 5 6
-6 -5 -4 -3 -2 -1
La première ligne de nombres donne la position des indices 0…6 dans la chaîne ; la deuxième ligne donne l’indice négatif correspondant. La tranche de i à j est constituée de tous les caractères situés entre les bords libellés i et j, respectivement.
Pour des indices non négatifs, la longueur d’une tranche est la différence entre ces indices, si les deux sont entre les bornes. Par exemple, la longueur de mot[1:3] est 2.
Exemples :
>>> mot[0:2] # caractères de la position 1 (inclus) à 3 (exclus)
'Py'
>>> mot[2:5] # caractères de la position 3 (inclus) à 6 (exclus)
'tho'
>>> mot[-6:-4] # caractères de la position 1 (inclus) à 3 (exclus)
'Py'
>>> mot[-4:-1] # caractères de la position 3 (inclus) à 6 (exclus)
'tho'
Notez que le début est toujours inclus et la fin toujours exclue. Cela assure que s[:i] + s[i:] est toujours égal à s :
>>> mot[:2] + mot[2:]
'Python'
>>> mot[:4] + mot[4:]
'Python'
Les valeurs par défaut des indices de tranches ont une utilité ; le premier indice vaut zéro par défaut (c.-à-d. lorsqu’il est omis), le deuxième correspond par défaut à la taille de la chaîne de caractères
>>> mot[:2] # caractère du début à la position 3 (exclu)
'Py'
>>> mot[4:] # caractères de la position 5 (inclus) à la fin
'on'
>>> mot[-2:] # caractères de l'avant-dernier (inclus) à la fin
'on'
Utiliser un indice trop grand produit une erreur :
>>> mot[42] # le mot n'a que 6 caractères
Traceback (most recent call last):
File "<input>", line 1, in <module>
mot[42] # le mot n'a que 6 caractères
IndexError: string index out of range
Cependant, les indices hors bornes sont gérés silencieusement lorsqu’ils sont utilisés dans des tranches :
>>> mot[4:42]
'on'
>>> mot[42:]
''
Les chaînes de caractères, en Python, ne peuvent pas être modifiées. On dit qu’elles sont immuables. Affecter une nouvelle valeur à un indice dans une chaîne produit une erreur :
>>> mot[0] = 'J'
Traceback (most recent call last):
File "<input>", line 1, in <module>
mot[0] = 'J'
TypeError: 'str' object does not support item assignment
>>> mot[2:] = 'py'
Traceback (most recent call last):
File "<input>", line 1, in <module>
mot[2:] = 'py'
TypeError: 'str' object does not support item assignment
Si vous avez besoin d’une chaîne différente, vous devez en créer une nouvelle :
>>> 'J' + mot[1:]
'Jython'
>>> mot[:2] + 'py'
'Pypy'
La fonction native len() renvoie la longueur d’une chaîne :
>>> s = 'anticonstitutionnellement'
>>> len(s)
25
Nombres#
Vu avec la calculatrice python
Nombre entier optimisé (int)#
Python 2
int()
Nombre entier de taille arbitraire (long int)#
Python 3
int()
Python 2
long()
Nombre à virgule flottante#
float()
Nombre complexe#
complex()
Données multiples#
Python connaît différents types de données combinés, utilisés pour regrouper plusieurs valeurs.
Liste de longueur fixe#
tuple()
le tuple (ou n-uplet, dénomination que nous utiliserons dans la suite de cette documentation).
Un n-uplet consiste en différentes valeurs séparées par des virgules, par exemple :
>>> t = 12345, 54321, 'hello!'
>>> t[0]
12345
>>> t
(12345, 54321, 'hello!')
>>> # Les tuples peuvent être imbriqués
>>> u = t, (1, 2, 3, 4, 5)
>>> u
((12345, 54321, 'hello!'), (1, 2, 3, 4, 5))
>>> # Les tuples sont immuables
>>> t[0] = 88888
Traceback (most recent call last):
File "<input>", line 1, in <module>
t[0] = 88888
TypeError: 'tuple' object does not support item assignment
>>> # mais ils peuvent contenir des objets mutables
>>> v = ([1, 2, 3], [3, 2, 1])
>>> v
([1, 2, 3], [3, 2, 1])
Comme vous pouvez le voir, les n-uplets sont toujours affichés entre parenthèses, de façon à ce que des n-uplets imbriqués soient interprétés correctement ; ils peuvent être saisis avec ou sans parenthèses, même si celles-ci sont souvent nécessaires (notamment lorsqu’un n-uplet fait partie d’une expression plus longue). Il n’est pas possible d’affecter de valeur à un élément d’un n-uplet ; par contre, il est possible de créer des n-uplets contenant des objets muables, comme des listes.
Si les n-uplets peuvent sembler similaires aux listes, ils sont souvent utilisés dans des cas différents et pour des raisons différentes. Les n-uplets sont immuables et contiennent souvent des séquences hétérogènes d’éléments qui sont accédés par « dissociation » (unpacking en anglais, voir plus loin) ou par indice (ou même par attributs dans le cas des namedtuples). Les listes sont souvent muables et contiennent des éléments généralement homogènes qui sont accédés par itération sur la liste.
Un problème spécifique est la construction de n-uplets ne contenant aucun ou un seul élément : la syntaxe a quelques tournures spécifiques pour s’en accommoder. Les n-uplets vides sont construits par une paire de parenthèses vides ; un n-uplet avec un seul élément est construit en faisant suivre la valeur par une virgule (il n’est pas suffisant de placer cette valeur entre parenthèses). Pas très joli, mais efficace.
Par exemple :
>>> vide = ()
>>> singleton = 'bonjour', # <-- noter la virgule de fin
>>> len(vide)
0
>>> len(singleton)
1
>>> singleton
('bonjour',)
L’instruction t = 12345, 54321, 'hello !' est un exemple d’une agrégation de n-uplet (tuple packing en anglais) : les valeurs «12345», «54321» et «hello !» sont agrégées ensemble dans un n-uplet. L’opération inverse est aussi possible :
>>> x, y, z = t
Ceci est appelé, de façon plus ou moins appropriée, une distribution de séquence (sequence unpacking en anglais) et fonctionne pour toute séquence placée à droite de l’expression. Cette distribution requiert autant de variables dans la partie gauche qu’il y a d’éléments dans la séquence. Notez également que cette affectation multiple est juste une combinaison entre une agrégation de n-uplet et une distribution de séquence.
Les ensembles#
set()
Python fournit également un type de donnée pour les ensembles. Un ensemble est une collection non ordonnée sans élément dupliqué. Des utilisations basiques concernent par exemple des tests d’appartenance ou des suppressions de doublons. Les ensembles savent également effectuer les opérations mathématiques telles que les unions, intersections, différences et différences symétriques.
Des accolades ou la fonction set() peuvent être utilisés pour créer des ensembles. Notez que pour créer un ensemble vide, {} ne fonctionne pas, cela crée un dictionnaire vide. Utilisez plutôt set().
Voici une brève démonstration :
>>> panier = {'pomme', 'orange', 'pomme', 'poire', 'orange', 'banane'}
>>> print(panier) # montre que les doublons ont été supprimés
{'poire', 'pomme', 'banane', 'orange'}
>>> 'orange' in panier # test d'adhésion rapide
True
>>> 'digitaire' in panier # la digitaire est une plante
False
>>> # Démontrer les opérations d'ensemble sur des lettres uniques à partir de deux mots
>>> a = set('abracadabra')
>>> b = set('alacazam')
>>> a # lettres uniques dans a
{'b', 'a', 'c', 'r', 'd'}
>>> a - b # lettres en a mais pas en b
{'r', 'b', 'd'}
>>> a | b # lettres en a ou b ou les deux
{'b', 'a', 'c', 'r', 'm', 'l', 'z', 'd'}
>>> a & b # lettres en a et b
{'a', 'c'}
>>> a ^ b # lettres en a ou b mais pas les deux
{'r', 'b', 'm', 'l', 'z', 'd'}
Il est possible d’écrire des expressions dans des ensembles :
>>> a = {x for x in 'abracadabra' if x not in 'abc'}
>>> a
{'r', 'd'}
Liste de longueur variable#
list()
Le plus souple est la liste, qui peut être écrit comme une suite, placée entre crochets, de valeurs (éléments) séparées par des virgules. Les listes et les chaînes de caractères ont beaucoup de propriétés en commun, comme l’indiçage et les opérations sur des tranches. Les éléments d’une liste ne sont pas obligatoirement tous du même type, bien qu’à l’usage ce soit souvent le cas.
>>> carrés = [1, 4, 9, 16, 25]
>>> carrés
[1, 4, 9, 16, 25]
Comme les chaînes de caractères (et toute autre type de séquence), les listes peuvent être indicées et découpées :
>>> carrés[0] # l'indexation renvoie l'élément
1
>>> carrés[-1]
25
>>> carrés[-3:] # slicing renvoie une nouvelle liste
[9, 16, 25]
Toutes les opérations par tranches renvoient une nouvelle liste contenant les éléments demandés. Cela signifie que l’opération suivante renvoie une copie distincte de la liste :
>>> carrés[:]
[1, 4, 9, 16, 25]
Les listes gèrent aussi les opérations comme les concaténations :
>>> carrés + [36, 49, 64, 81, 100]
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
Mais à la différence des chaînes qui sont immuables, les listes sont muables : il est possible de modifier leur contenu :
>>> cubes = [1, 8, 27, 63, 125] # Quelque chose ne va pas ici
>>> 4 ** 3 # le cube de 4 est 64, pas 63!
64
>>> cubes[3] = 64 # remplacer la mauvaise valeur
>>> cubes
[1, 8, 27, 64, 125]
Il est aussi possible d’ajouter de nouveaux éléments à la fin d’une liste avec la méthode append() (les méthodes sont abordées plus tard) :
>>> cubes.append(216) # ajouter le cube de 6
>>> cubes.append(7 ** 3) # et le cube de 7
>>> cubes
[1, 8, 27, 64, 125, 216, 343]
Des affectations de tranches sont également possibles, ce qui peut même modifier la taille de la liste ou la vider complètement :
>>> lettres = ['a', 'b', 'c', 'd', 'e', 'f', 'g']
>>> lettres
['a', 'b', 'c', 'd', 'e', 'f', 'g']
>>> # remplacer certaines valeurs
>>> lettres[2:5] = ['C', 'D', 'E']
>>> lettres
['a', 'b', 'C', 'D', 'E', 'f', 'g']
>>> # maintenant supprimez-les
>>> lettres[2:5] = []
>>> lettres
['a', 'b', 'f', 'g']
>>> # effacer la liste en remplaçant tous les éléments par une liste vide
>>> lettres[:] = []
>>> lettres
[]
La primitive len() s’applique aussi aux listes :
>>> lettres = ['a', 'b', 'c', 'd']
>>> len(lettres)
4
Il est possible d’imbriquer des listes (c’est à dire de créer des listes contenant d’autres listes).
Par exemple :
>>> a = ['a', 'b', 'c']
>>> n = [1, 2, 3]
>>> x = [a, n]
>>> x
[['a', 'b', 'c'], [1, 2, 3]]
>>> x[0]
['a', 'b', 'c']
>>> x[0][1]
'b'
Premiers pas vers la programmation#
Bien entendu, on peut utiliser Python pour des tâches plus compliquées que d’additionner deux et deux. Par exemple, on peut écrire le début de la suite de Fibonacci comme ceci :
>>> # Série de Fibonacci
>>> # la somme de deux éléments définit le suivant
>>> a, b = 0, 1
>>> while a < 10:
... print(a)
... a, b = b, a+b
...
...
0
1
1
2
3
5
8
Cet exemple introduit plusieurs nouvelles fonctionnalités.
La première ligne contient une affectation multiple : les variables a et b se voient affecter simultanément leurs nouvelles valeurs 0 et 1. Cette méthode est encore utilisée à la dernière ligne, pour démontrer que les expressions sur la partie droite de l’affectation sont toutes évaluées avant que les affectations ne soient effectuées. Ces expressions en partie droite sont toujours évaluées de la gauche vers la droite.
La boucle while s’exécute tant que la condition (ici : a < 10) reste vraie. En Python, comme en C, tout entier différent de zéro est vrai et zéro est faux. La condition peut aussi être une chaîne de caractères, une liste, ou en fait toute séquence ; une séquence avec une valeur non nulle est vraie, une séquence vide est fausse. Le test utilisé dans l’exemple est une simple comparaison. Les opérateurs de comparaison standards sont écrits comme en C : < (inférieur), > (supérieur), == (égal), <= (inférieur ou égal), >= (supérieur ou égal) et != (non égal).
Le corps de la boucle est indenté : l’indentation est la méthode utilisée par Python pour regrouper des instructions. En mode interactif, vous devez saisir une tabulation ou des espaces pour chaque ligne indentée. En pratique, vous aurez intérêt à utiliser un éditeur de texte pour les saisies plus compliquées ; tous les éditeurs de texte dignes de ce nom disposent d’une fonction d’auto-indentation. Lorsqu’une expression composée est saisie en mode interactif, elle doit être suivie d’une ligne vide pour indiquer qu’elle est terminée (car l’analyseur ne peut pas deviner que vous venez de saisir la dernière ligne). Notez bien que toutes les lignes à l’intérieur d’un bloc doivent être indentées au même niveau.
La fonction print() écrit les valeurs des paramètres qui lui sont fournis. Ce n’est pas la même chose que d’écrire l’expression que vous voulez afficher (comme nous l’avons fait dans l’exemple de la calculatrice), en raison de la manière qu’a print() de gérer les paramètres multiples, les nombres décimaux et les chaînes. Les chaînes sont affichées sans apostrophe et une espace est insérée entre les éléments de telle sorte que vous pouvez facilement formater les choses, comme ceci :
>>> i = 256*256
>>> print('La valeur de i est', i)
La valeur de i est 65536
Le paramètre nommé end peut servir pour enlever le retour à la ligne ou pour terminer la ligne par une autre chaîne :
>>> a, b = 0, 1
>>> while a < 1000:
... print(a, end=',')
... a, b = b, a+b
...
...
0,1,1,2,3,5,8,13,21,34,55,89,144,233,377,610,987,>>>
Lexique à distribuer :
Le type liste dispose de méthodes supplémentaires. Voici toutes les méthodes des objets de type liste :
list.append(x)
Ajoute un élément à la fin de la liste. Équivalent à a[len(a):] = [x].
list.extend(iterable)
Étend la liste en y ajoutant tous les éléments de l’itérable. Équivalent à a[len(a):] = iterable.
list.insert(i, x)
Insère un élément à la position indiquée. Le premier argument est la position de l’élément courant avant lequel l’insertion doit s’effectuer, donc a.insert(0, x) insère l’élément en tête de la liste et a.insert(len(a), x) est équivalent à a.append(x).
list.remove(x)
Supprime de la liste le premier élément dont la valeur est égale à x. Une exception ValueError est levée s’il n’existe aucun élément avec cette valeur.
list.pop([i])
Enlève de la liste l’élément situé à la position indiquée et le renvoie en valeur de retour. Si aucune position n’est spécifiée, a.pop() enlève et renvoie le dernier élément de la liste (les crochets autour du i dans la signature de la méthode indiquent que ce paramètre est facultatif et non que vous devez placer des crochets dans votre code ! Vous retrouverez cette notation fréquemment dans le Guide de Référence de la Bibliothèque Python).
list.clear()
Supprime tous les éléments de la liste. Équivalent à del a[:].
list.index(x[, start[, end]])
Renvoie la position du premier élément de la liste dont la valeur égale x (en commençant à compter les positions à partir de zéro). Une exception ValueError est levée si aucun élément n’est trouvé.
Les arguments optionnels start et end sont interprétés de la même manière que dans la notation des tranches et sont utilisés pour limiter la recherche à une sous-séquence particulière. L’indice renvoyé est calculé relativement au début de la séquence complète et non relativement à start.
list.count(x)
Renvoie le nombre d’éléments ayant la valeur x dans la liste.
list.sort(key=None, reverse=False)
Ordonne les éléments dans la liste (les arguments peuvent personnaliser l’ordonnancement, voir sorted() pour leur explication).
list.reverse()
Inverse l’ordre des éléments dans la liste.
list.copy()
Renvoie une copie superficielle de la liste. Équivalent à a[:].
Exemple suivant utilise la plupart des méthodes des listes :
>>> fruits = ['orange', 'pomme', 'poire', 'banane', 'kiwi', 'pomme', 'banane']
>>> fruits.count('pomme')
2
>>> fruits.count('mandarine')
0
>>> fruits.index('banane')
3
>>> fruits.index('banane', 4) # Trouver la prochaine banane à partir d'une position 4
6
>>> fruits.reverse()
>>> fruits
['banane', 'pomme', 'kiwi', 'banane', 'poire', 'pomme', 'orange']
>>> fruits.append('raisin')
>>> fruits
['banane', 'pomme', 'kiwi', 'banane', 'poire', 'pomme', 'orange', 'raisin']
>>> fruits.sort()
>>> fruits
['banane', 'banane', 'kiwi', 'orange', 'poire', 'pomme', 'pomme', 'raisin']
>>> fruits.pop()
'raisin'
>>> fruits
['banane', 'banane', 'kiwi', 'orange', 'poire', 'pomme', 'pomme']
Vous avez probablement remarqué que les méthodes telles que insert, remove ou sort, qui ne font que modifier la liste, n’affichent pas de valeur de retour (elles renvoient None) 1. C’est un principe respecté par toutes les structures de données variables en Python.
Une autre chose que vous remarquerez peut-être est que toutes les données ne peuvent pas être ordonnées ou comparées. Par exemple, [None, “hello”, 10] ne sera pas ordonné parce que les entiers ne peuvent pas être comparés aux chaînes de caractères et None ne peut pas être comparé à d’autres types. En outre, il existe certains types qui n’ont pas de relation d’ordre définie. Par exemple, 3+4j < 5+7j n’est pas une comparaison valide.
Approfondir chez soit ou au travail voir https://docs.python.org/fr/3/tutorial/datastructures.html#using-lists-as-stacks et la suite
Dictionnaire#
dict()
Un autre type de donnée très utile, natif dans Python, est le dictionnaire (voir Les types de correspondances — dict). Ces dictionnaires sont parfois présents dans d’autres langages sous le nom de « mémoires associatives » ou de « tableaux associatifs ». À la différence des séquences, qui sont indexées par des nombres, les dictionnaires sont indexés par des clés, qui peuvent être de n’importe quel type immuable ; les chaînes de caractères et les nombres peuvent toujours être des clés. Des n-uplets peuvent être utilisés comme clés s’ils ne contiennent que des chaînes, des nombres ou des n-uplets ; si un n-uplet contient un objet muable, de façon directe ou indirecte, il ne peut pas être utilisé comme une clé. Vous ne pouvez pas utiliser des listes comme clés, car les listes peuvent être modifiées en place en utilisant des affectations par position, par tranches ou via des méthodes comme append() ou extend().
Le plus simple est de considérer les dictionnaires comme des ensembles de paires clé: valeur, les clés devant être uniques (au sein d’un dictionnaire). Une paire d’accolades crée un dictionnaire vide : {}. Placer une liste de paires clé:valeur séparées par des virgules à l’intérieur des accolades ajoute les valeurs correspondantes au dictionnaire ; c’est également de cette façon que les dictionnaires sont affichés.
Les opérations classiques sur un dictionnaire consistent à stocker une valeur pour une clé et à extraire la valeur correspondant à une clé. Il est également possible de supprimer une paire clé-valeur avec del. Si vous stockez une valeur pour une clé qui est déjà utilisée, l’ancienne valeur associée à cette clé est perdue. Si vous tentez d’extraire une valeur associée à une clé qui n’existe pas, une exception est levée.
Exécuter list(d) sur un dictionnaire d renvoie une liste de toutes les clés utilisées dans le dictionnaire, dans l’ordre d’insertion (si vous voulez qu’elles soient ordonnées, utilisez sorted(d)). Pour tester si une clé est dans le dictionnaire, utilisez le mot-clé in.
Voici un petit exemple utilisant un dictionnaire :
>>> téléphone = {'daniel': 4098, 'paul': 4139}
>>> téléphone['luc'] = 4127
>>> téléphone
{'daniel': 4098, 'paul': 4139, 'luc': 4127}
>>> téléphone['daniel']
4098
>>> del téléphone['paul']
>>> téléphone['sami'] = 4127
>>> téléphone
{'daniel': 4098, 'luc': 4127, 'sami': 4127}
>>> list(téléphone)
['daniel', 'luc', 'sami']
>>> sorted(téléphone)
['daniel', 'luc', 'sami']
>>> 'luc' in téléphone
True
>>> 'daniel' not in téléphone
False
Le constructeur dict() fabrique un dictionnaire directement à partir d’une liste de paires clé-valeur stockées sous la forme de n-uplets :
>>> dict([('paul', 4139), ('luc', 4127), ('daniel', 4098)])
{'paul': 4139, 'luc': 4127, 'daniel': 4098}
De plus, il est possible de créer des dictionnaires par compréhension depuis un jeu de clef et valeurs :
>>> {x: x**2 for x in (2, 4, 6)}
{2: 4, 4: 16, 6: 36}
Lorsque les clés sont de simples chaînes de caractères, il est parfois plus facile de spécifier les paires en utilisant des paramètres nommés :
>>> dict(paul=4139, luc=4127, daniel=4098)
{'paul': 4139, 'luc': 4127, 'daniel': 4098}
Autres#
Fichier#
File
Absence de type#
NoneType
Absence d’implémentation#
NotImplementedType
fonction#
Function
module#
module
Les fonctions intégrées#
Lexique pédagogique à fournir «Les fonctions de base» :
Détermination du type d’une variable#
type()
Conversion de types#
bool()
Convertit en booléen : "0", "" et "None" donnent "False" et le reste "True".
int()
Permet de modifier une variable en entier. Provoque une erreur si cela n’est pas possible.
str()
Permet de transformer la plupart des variables d’un autre type en chaînes de caractère.
float()
Permet la transformation en flottant.
repr()
Similaire à « str ». Voir la partie sur les objets.
eval()
Évalue le contenu de son argument comme si c’était du code Python.
long() # Python 2
Transforme une valeur en long.
Voir les propriétés des fonctions#
Fonction d’aide sur les fonctions Python#
help()
Fonction de visualisation des propriétés et méthodes des fonctions Python#
dir()
La fonction interne dir() est utilisée pour trouver quels noms sont définis par un module. Elle donne une liste de chaînes classées par ordre lexicographique :
>>> import math, sys
>>> dir(math)
['__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'acos', 'acosh', 'asin', 'asinh', 'atan', 'atan2', 'atanh', 'ceil', 'comb', 'copysign', 'cos', 'cosh', 'degrees', 'dist', 'e', 'erf', 'erfc', 'exp', 'expm1', 'fabs', 'factorial', 'floor', 'fmod', 'frexp', 'fsum', 'gamma', 'gcd', 'hypot', 'inf', 'isclose', 'isfinite', 'isinf', 'isnan', 'isqrt', 'lcm', 'ldexp', 'lgamma', 'log', 'log10', 'log1p', 'log2', 'modf', 'nan', 'nextafter', 'perm', 'pi', 'pow', 'prod', 'radians', 'remainder', 'sin', 'sinh', 'sqrt', 'tan', 'tanh', 'tau', 'trunc', 'ulp']
Sans paramètre, dir() liste les noms actuellement définis :
>>> a = [1, 2, 3, 4, 5]
>>> import math
>>> cos = math.cos
>>> dir()
['__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__', 'a', 'b', 'cos', 'cubes', 'fruits', 'help', 'i', 'lettres', 'math', 'n', 'sys', 'téléphone', 'x']
Notez qu’elle liste tous les types de noms : les variables, fonctions, modules, etc.
dir() ne liste ni les fonctions primitives, ni les variables internes. Si vous voulez les lister, elles sont définies dans le module builtins :
>>> import builtins
>>> dir(builtins)
['ArithmeticError', 'AssertionError', 'AttributeError', 'BaseException', 'BlockingIOError', 'BrokenPipeError', 'BufferError', 'BytesWarning', 'ChildProcessError', 'ConnectionAbortedError', 'ConnectionError', 'ConnectionRefusedError', 'ConnectionResetError', 'DeprecationWarning', 'EOFError', 'Ellipsis', 'EnvironmentError', 'Exception', 'False', 'FileExistsError', 'FileNotFoundError', 'FloatingPointError', 'FutureWarning', 'GeneratorExit', 'IOError', 'ImportError', 'ImportWarning', 'IndentationError', 'IndexError', 'InterruptedError', 'IsADirectoryError', 'KeyError', 'KeyboardInterrupt', 'LookupError', 'MemoryError', 'ModuleNotFoundError', 'NameError', 'None', 'NotADirectoryError', 'NotImplemented', 'NotImplementedError', 'OSError', 'OverflowError', 'PendingDeprecationWarning', 'PermissionError', 'ProcessLookupError', 'RecursionError', 'ReferenceError', 'ResourceWarning', 'RuntimeError', 'RuntimeWarning', 'StopAsyncIteration', 'StopIteration', 'SyntaxError', 'SyntaxWarning', 'SystemError', 'SystemExit', 'TabError', 'TimeoutError', 'True', 'TypeError', 'UnboundLocalError', 'UnicodeDecodeError', 'UnicodeEncodeError', 'UnicodeError', 'UnicodeTranslateError', 'UnicodeWarning', 'UserWarning', 'ValueError', 'Warning', 'ZeroDivisionError', '_', '__build_class__', '__debug__', '__doc__', '__import\__', '__loader__', '__name__', '__package__', '__spec__', 'abs', 'all', 'any', 'ascii', 'bin', 'bool', 'breakpoint', 'bytearray', 'bytes', 'callable', 'chr', 'classmethod', 'compile', 'complex', 'copyright', 'credits', 'delattr', 'dict', 'dir', 'divmod', 'enumerate', 'eval', 'exec', 'exit', 'filter', 'float', 'format', 'frozenset', 'getattr', 'globals', 'hasattr', 'hash', 'help', 'hex', 'id', 'input', 'int', 'isinstance', 'issubclass', 'iter', 'len', 'license', 'list', 'locals', 'map', 'max', 'memoryview', 'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'print', 'property', 'quit', 'range', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'vars', 'zip']
L’identification des objets#
id()
>>> id(cos)
140293507063376
Zoom sur fonctions et propriétés#
Range#
Si vous devez itérer sur une suite de nombres, la fonction native range() est faite pour cela. Elle génère des suites arithmétiques :
>>> for i in range(5):
... print(i)
...
...
0
1
2
3
4
Le dernier élément fourni en paramètre ne fait jamais partie de la liste générée ; range(10) génère une liste de 10 valeurs, dont les valeurs vont de 0 à 9. Il est possible de spécifier une valeur de début et une valeur d’incrément différentes (y compris négative pour cette dernière, que l’on appelle également parfois le “pas”) :
>>> tuple(range(5, 10))
(5, 6, 7, 8, 9)
>>> tuple(range(0, 10, 3))
(0, 3, 6, 9)
>>> tuple(range(-10, -100, -30))
(-10, -40, -70)
Une chose étrange se produit lorsqu’on affiche un range :
>>> print(range(10))
range(0, 10)
L’objet renvoyé par range() se comporte presque comme une liste, mais ce n’en est pas une. Cet objet génère les éléments de la séquence au fur et à mesure de l’itération, sans réellement produire la liste en tant que telle, économisant ainsi de l’espace.
On appelle de tels objets des iterable, c’est-à-dire des objets qui conviennent à des fonctions ou constructions qui s’attendent à quelque chose duquel ils peuvent tirer des éléments, successivement, jusqu’à épuisement. Nous avons vu que l’instruction for est une de ces constructions, et un exemple de fonction qui prend un itérable en paramètre est sum() :
>>> sum(range(4)) # 0 + 1 + 2 + 3
6
Plus loin nous voyons d’autres fonctions qui donnent des itérables ou en prennent en paramètre. Si vous vous demandez comment obtenir une liste à partir d’un range, voilà la solution :
>>> list(range(4))
[0, 1, 2, 3]
Chaînes de caractères#
split() : sépare une chaîne en liste#
Fractionne une chaîne de caractères Python suivant un délimiteur. Si le paramètre du nombre de divisions est spécifié split() retourne seulement dans la liste les premiers élément fractionnés suivant la quantité demandée.
Syntaxe :
str.split(str="", num=string.count(str))
Paramètres :
str : séparateur, espaces par défaut.
num : le nombre de divisions.
Valeur de retour :
Renvoie une liste de chaînes après division.
Exemples
L’exemple suivant montre la distribution de split() :
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
chaine = "Ligne1-abcdef \\nLigne2-abc \\nLigne3-abcd"
print(chaine.split())
print(chaine.split(' ', 1))
Exemple du résultat de sortie ci-dessus :
['Ligne1-abcdef', 'Ligne2-abc', 'Ligne3-abcd']
['Ligne1-abcdef', '\nLigne2-abc \\nLigne3-abcd']
join() : Concatène une liste de caractères#
Transforme une liste en chaîne avec le séparateur en préfixe ("".join(MaListe)).
Syntaxe :
string.join(iterable)
Paramètres :
La méthode join() prend un seul paramètre.
iterable(Obligatoire) : Tout objet itérable où toutes les valeurs renvoyées sont des chaînes
Valeur de retour :
La méthode join() renvoie une chaîne créée en joignant les éléments d’un itérable par un séparateur.
Exemple
Joindre tous les éléments d’un tuple dans une chaîne, en utilisant le caractère «|» comme séparateur :
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
tupl = ("Python", "Rust", "Julia")
résultat = "|".join(tupl)
print(résultat)
Sortie :
Python|Rust|Julia
Joignez tous les éléments d’un dictionnaire dans une chaîne, en utilisant le caractère «#» comme séparateur :
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
dict = {"nom": "Alexandre", "age": "25"}
résultat = "#".join(dict)
print(résultat)
résultat = "#".join(dict.values())
print(résultat)
Sortie :
nom#age
Alexandre#25
Les modules#
Lorsque vous quittez et entrez à nouveau dans l’interpréteur Python, tout ce que vous avez déclaré dans la session précédente est perdu. Afin de rédiger des programmes plus longs, vous devez utiliser un éditeur de texte, préparer votre code dans un fichier et exécuter Python avec ce fichier en paramètre. Cela s’appelle créer un script. Lorsque votre programme grandit, vous pouvez séparer votre code dans plusieurs fichiers. Ainsi, il vous est facile de réutiliser du code écrit pour un programme dans un autre sans avoir à les copier.
Pour gérer cela, Python vous permet de placer des définitions dans un fichier et de les utiliser dans un script ou une session interactive. Un tel fichier est appelé un module et les définitions d’un module peuvent être importées dans un autre module ou dans le module main (qui est le module qui contient vos variables et définitions lors de l’exécution d’un script au niveau le plus haut ou en mode interactif).
Un module est un fichier contenant des définitions et des instructions (des fonctions, des classes et des variables.). Son nom de fichier est le nom du module suffixé de «.py».
À l’intérieur d’un module, son propre nom est accessible par la variable __name__. Ce module, avec ses variables, fonctions ou classes, peut être chargé à partir d’un autre module ; c’est ce que l’on appelle l’importation.
__name__ et __main__#
Lorsque l’interpréteur exécute un module, la variable __name__ sera définie comme __main__ si le module en cours d’exécution est le programme principal.
>>> print(" __name__ est défini à {}".format(__name__))
__name__ est défini à __main__
Mais si le code importe le module depuis un autre module, la variable __name__ sera définie sur le nom de ce module. Jetons un œil à un exemple.
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ mkdir 7_Modules ; cd 7_Modules
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ nano ./mon_module.py
Créez un module Python nommé mon_module.py et saisissez ce code à l’intérieur:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# Module de fichier Python
print("Mon module __name__ est défini à {}".format(__name__))
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ python3
Python 3.9.4 (default, Apr 4 2021, 19:38:44)
[GCC 10.2.1 20210401] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import mon_module
Mon module __name__ est défini à mon_module
>>> quit()
Gestion des imports#
La façon habituelle d’utiliser __name__ et __main__ ressemble à ceci avec le script mon_module_2.py:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# Module de fichier Python
print("Mon module __name__ est défini à {}".format(__name__))
if __name__ == "__main__":
print("Fichier exécuté directement")
else:
print("Fichier exécuté comme importé")
Ce qui nous donne à l’exécution directe du module python :
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ chmod u+x ./mon_module_2.py
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./mon_module_2.py
Mon module __name__ est défini à __main__
Fichier exécuté directement
Et à l’exécution comme module :
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ python3
Python 3.9.4 (default, Apr 4 2021, 19:38:44)
[GCC 10.2.1 20210401] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import mon_module_2
Mon module __name__ est défini à mon_module
Fichier exécuté comme importé
>>> quit()
Les bibliothèques de fonctions ou d’objets#
Les modules PYTHON#
Lexique pédagogique à fournir Les bibliothèques de fonctions ou d’objets.
Le dépôt de modules Python#
Pip#
Une des forces de Python est la multitude de bibliothèques disponibles (près de 6000 bibliothèques gravitent autour du projet Django).
Par exemple installer une bibliothèque peut vite devenir ennuyeux:
trouver le bon site,
la bonne version de la bibliothèque,
l’installer,
trouver ses dépendances,
etc.
Il existe une solution qui vous permet de télécharger très simplement une bibliothèque pip.
PIP c’est quoi ?#
Pip est un système de gestion de paquets utilisé pour installer et gérer des librairies écrites en Python. Vous pouvez trouver une grande partie de ces librairies dans le Python Package Index (ou PyPI). Pip empêche les installations partielles en annonçant toutes les exigences avant l’installation.
pip install librairie
Vous pouvez choisir la version qui vous intéresse :
pip install librairie==2.2
Supprimer une librairie :
pip uninstall librairie
Mettre à jour une librairie :
pip install librairie --upgrade
Revenir sur une version antérieure :
pip install librairie==2.1 --upgrade
Rechercher une nouvelle librairie :
pip search librairie
Vous indiquer quelles librairies ne sont plus à jour :
pip list --outdated
Afficher toutes les librairies installées et leur version :
pip freeze
Exporter la liste des librairies, vous pourrez la réimporter ailleurs :
pip freeze > lib.txt
Importer la liste de librairie comme ceci :
pip install -r lib.txt
Créer un gros zip qui contient toutes les dépendances :
pip bundle <nom_du_bundle>.pybundle -r lib.txt
Pour installer les librairies :
pip install <nom_du_bundle>.pybundle
Pour installer depuis un dépôt distant (Voir la section du support VCS) :
pip install git+https://github.com/chemin/monmodule.git#egg=monmodule
Pour le lien ver le support VCS : https://pip.pypa.io/en/stable/reference/pip_install/#vcs-support
Voir plus d’informations https://docs.python.org/fr/3.6/installing/index.html
Les modules de gestion des paramètres de la ligne de commande#
Modules dépréciés#
Python fourni un module getopt(déprécié depuis Python 3.7) ou optparse (déprécié depuis Python 3.2) qui vous aident à analyser les options et les arguments de la ligne de commande. Le module getopt fournit deux fonctions et une exception pour activer l’analyse des arguments de ligne de commande.
Supposons que nous voulions passer deux noms de fichiers via la ligne de commande et que nous voulions également donner une option pour vérifier l’utilisation du script. L’utilisation en ligne de commande du script est la suivante :
test.py -i <fichier_en_entrée> -o <fichier_de_sortie>
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import sys, getopt
def main(argv):
fichierentre = ''
fichiersortie = ''
try:
opts, args = getopt.getopt(argv,"hi:o:",["ifile=","ofile="])
except getopt.GetoptError:
print('utilisation : test.py -i <fichier_en_entrée> -o <fichier_de_sortie>')
sys.exit(2)
for opt, arg in opts:
if opt == '-h':
print('utilisation : test.py -i <fichier_en_entrée> -o <fichier_de_sortie>')
sys.exit()
elif opt in ("-i", "--ifile"):
fichierentre = arg
elif opt in ("-o", "--ofile"):
fichiersortie = arg
print('Le fichier en entré est', fichierentre)
print('Le fichier en sortie est', fichiersortie)
if __name__ == "__main__":
main(sys.argv[1:])
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ test.py -h
utilisation: test.py -i <fichier_en_entrée> -o <fichier_en_entrée>
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ test.py -i BMP -o
utilisation: test.py -i <fichier_en_entrée> -o <fichier_en_entrée>
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ test.py -i input.txt -o output.cvs
Le fichier en entré est input.txt
Le fichier en sortie est output.cvs
Argparse#
Le module argparse remplace getopt et optparse. Il facilite l’écriture d’interfaces de ligne de commande conviviales. Le programme définit les arguments dont il a besoin et argparse trouvera comment les analyser à partir de sys.argv. Le module argparse génère également automatiquement des messages d’aide et d’utilisation, et émet des erreurs lorsque les utilisateurs donnent au programme des arguments non valides.
Utilisation du module#
Construction du parseur.
parser = argparse.ArgumentParser(description = 'ma description')On peut donner une description qui terminera dans l’aide d’usage.
Ajout d’un argument de la ligne de commande.
parser.add_argument('-foo')
'-foo'est un argument optionnel (non obligatoire). C’est parce que cela commence par «-» ou «--».Pour avoir un argument positionnel (obligatoire), saisir
'foo'.
Parcourir les arguments.
args = parser.parse_args()Agit automatiquement sur sys.argv
On peut alors accéder aux valeurs des arguments en faisant directement : args.foo
On peut aussi récupérer les valeurs sous forme de dictionnaire avec : vars(args)
On peut explicitement imprimer l’aide avec : parser.print_help()
On peut explicitement imprimer l’usage simplifié de la commande par : parser.print_usage()
Ajout d’options#
parser.add_argument('-f', '--foo')
On peut utiliser l’arguments optionnel simplifié -f ou nommé --foo en ligne de commande.
parser.add_argument('-foo', help='what -foo does', metavar='fValue')
Nom de l’argument -foo dans les messages d’utilisation avec l’option metavar= ainsi que l’aide sur l’option avec help=.
parser.add_argument('-foo', dest='fVal')
La valeur pourra être accédée après parsing avec args.fVal plutôt qu’avec args.foo.
parser.add_argument('-foo', required=True)
L’argument est obligatoire.
parser.add_argument('-foo', action='store_true')
L’argument ne prend pas de valeur et renvoi True si présent (False sinon).
parser.add_argument('-foo', action='append')
L’argument renvoi une liste de valeurs avec autant d’éléments que le nombre de fois où l’argument est présent.
Par exemple : 2 valeurs si «-foo a -foo b».
parser.add_argument('-foo', choices=['a', 'b', 'c'])
L’argument doit prendre l’une des valeurs indiquée.
parser.add_argument('-foo', default='test')
Donne une valeur par défaut.
parser.add_argument('-foo', type=int)
Indique que l’argument doit être un entier plutôt qu’une chaîne de caractères (défaut). On peut utiliser int, float, str, complex.
Exemples#
Fichier argparse1.py :
Implémentation minimale.
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import argparse
parser = argparse.ArgumentParser()
parser.parse_args()
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse1.py
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7\_Modules$ ./argparse1.py --help
usage: argparse1.py [-h]
optional arguments:
-h, --help show this help message and exit
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse1.py foo
usage: argparse1.py [-h]
argparse1.py: error: unrecognized arguments: foo
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse1.py --verbose
usage: argparse1.py [-h]
argparse1.py: error: unrecognized arguments: --verbose
Voilà ce qu’il se passe :
Exécuter le script sans aucun paramètre a pour effet de ne rien afficher sur la sortie d’erreur. Ce n’est pas très utile.
La deuxième commande commence à montrer l’intérêt du module argparse. On n’a quasiment rien fait mais on a déjà un beau message d’aide . L’option --help (pas besoin de la préciser), que l’on peut aussi raccourcir en -h.
Préciser quoi que ce soit d’autre comme argument de la ligne de commande entraîne une erreur.
Même si on reçoit aussi un argument optionnel non défini.
Fichier argparse2.py :
Comment passer un argument de ligne de commande ?
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("echo")
args = parser.parse_args()
print(args.echo)
On a ajouté la méthode add_argument() que l’on utilise pour préciser quels paramètres de lignes de commandes le programme peut accepter. Dans le cas présent, c’est echo pour que cela corresponde à sa fonction. Utiliser le programme nécessite maintenant que l’on précise un paramètre.
La méthode parse_args() renvoie les données des arguments de la ligne de commande, dans le cas présent : echo.
argparse affecte automatiquement la variable comme par «magie». C’est à dire que nous n’avons pas besoin de préciser dans quelle variable la valeur est stockée. Vous pouvez remarquer aussi que le nom de variable args.echo est le même que l’argument en chaîne de caractères donné à la méthode add_argument("echo").
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse2.py
usage: argparse2.py [-h] echo
argparse2.py: error: the following arguments are required: echo
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse2.py --help
usage: argparse2.py [-h] echo
positional arguments:
echo
optional arguments:
-h, --help show this help message and exit
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse2.py monparamètre
monparamètre
Voilà ce qu’il se passe :
Sans arguments la commande renvoie l’aide simplifiée avec le message d’erreur.
Nous voyons l’aide du programme avec la commande «--help».
Avec le bon argument on affiche la valeur de l’argument saisie.
Notez cependant que, même si l’affichage d’aide paraît bien , il n’est pas aussi utile qu’il pourrait l’être. Par exemple, on peut lire que echo est un argument positionnel mais on ne peut pas savoir ce que cela fait autrement qu’en le devinant ou en lisant le code source.
Fichier argparse3.py :
Comment afficher une aide plus précise pour un argument de la ligne de commande ?
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("echo", help="renvoi la valeur du paramètre que vous avez passé")
args = parser.parse_args()
print(args.echo)
Nous ajoutons simplement le paramètre help="" à la méthode add_argument().
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse3.py -h
usage: argparse3.py [-h] echo
positional arguments:
echo echo renvoi la valeur du paramètre que vous avez passé
optional arguments:
-h, --help show this help message and exit
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse3.py monparamètre
monparamètre
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse3.py monparamètre etunautre
usage: argparse3.py [-h] echo
argparse3.py: error: argument square: invalid int value: 'etunautre'
Nous observons bien que le message d’aide est plus précis.
Cela fonctionne avec une valeur atribuée au paramètre positioné «echo».
Cela ne prend qu’un paramètre.
Fichier argparse4.py :
Comment calculer le carré d’un nombre en ligne de commande ?
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("carré", help="affiche le carré du nombre passé en argument")
args = parser.parse_args()
print(args.carré**2)
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse4.py 4
Traceback (most recent call last):
File "./argparse4.py", line 8, in <module>
print(args.carré**2)
TypeError: unsupported operand type(s) for \*\* or pow(): 'str' and 'int'
Cela n’a pas très bien fonctionné. C’est parce que argparse traite les paramètres que l’on donne comme des chaînes de caractères, à moins qu’on ne lui indique de faire autrement.
Fichier argparse5.py :
Comment traiter le paramètre d’entrée comme un entier ?
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("carré", help="affiche le carré du nombre passé en argument", type=int)
args = parser.parse_args()
print(args.carré**2)
Nous ajoutons simplement le paramètre type=int à la méthode add_argument().
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse5.py 4
16
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7\_Modules$ ./argparse5.py quatre
usage: argparse5.py [-h] carré
argparse5.py: error: argument carré: invalid int value: 'quatre'
Cela a bien fonctionné. Maintenant le programme va même s’arrêter si l’entrée n’est pas un entier avant de procéder à l’exécution.
Fichier argparse6.py :
Comment ajouter un paramètre optionnel ?
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import** **argparse**
parser = argparse.ArgumentParser()
parser.add_argument("--verbosity", help="augmente la verbosité de sortie")
args = parser.parse_args()
if args.verbosity :
print("verbosité activée")
On rajoute «-» ou «--» pour montrer que l’argument de ligne de commande est bien optionnel, il n’y aura alors pas d’erreur si on exécute le programme sans celui-ci.
Notez que par défaut, si une option n’est pas utilisée, la variable associée, dans le cas présent args.verbosity, prend la valeur None. C’est pour cela quelle échoue au test if.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse6.py --verbosity 1
verbosité activée
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse6.py
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse6.py --help
usage: argparse6.py [-h] [--verbosity VERBOSITY]
optional arguments:
-h, --help show this help message and exit
--verbosity VERBOSITY
augmente la verbosité de sortie
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse6.py --verbosity
usage: argparse6.py [-h] [--verbosity VERBOSITY]
argparse6.py: error: argument --verbosity: expected one argument
Validation de la verbosité
La commande sans paramètre ne retourne rien et n’est pas en erreur.
Le message d’aide est un peu différent quand on utilise l’option --verbosity si on ne précise pas une valeur.
Le paramètre optionnel --verbosity demande impérativement une valeur d’attribution.
L’exemple ci-dessus accepte obligatoirement une valeur entière arbitraire pour --verbosity, mais seul l’état (vrai/faux) de présence du paramètre est réellement utile pour notre commande.
Fichier argparse7.py :
Comment prendre en compte l’état booléen de présence d’un argument ?
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--verbose", help="augmente la verbosité de sortie", action="store_true")
args = parser.parse_args()
if args.verbose:
print("verbosité activée")
Notez que maintenant on précise avec le paramètre action= dans add_argument() un état booléen. Et on lui donne la valeur "store_true". Cela signifie que si l’argument de ligne de commande est précisée, la valeur True est assignée à args.verbose. Ne rien préciser renvoie la valeur False.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse7.py --verbose
verbosité activée
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse7.py
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse7.py --help
usage: argparse7.py [-h] [--verbose]
optional arguments:
-h, --help show this help message and exit
--verbose augmente la verbosité de sortie
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse7.py --verbose 1
usage: argparse7.py [-h] [--verbose]
argparse7.py: error: unrecognized arguments: 1
Maintenant le paramètre est plus une option qu’un paramètre qui nécessite une valeur. On a même changé le nom du paramètre pour qu’il corresponde à cette idée.
Pas d’aide retournée.
Notez que l’aide est différente avec l’option «--verbose».
Dans l’esprit de ce que sont vraiment les options de la ligne de commande, pas des paramètres, quand vous tentez de préciser une valeur de paramètre l’aide simplifiée d’usage et une erreur sont renvoyées.
Si vous êtes familier avec l’utilisation de la ligne de commande, vous avez dû remarquer que nous n’avons pas abordé les raccourcies des paramètres.
Fichier argparse8.py :
Comment ajouter un raccourcie de paramètre de la ligne de commande ?
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("-v", "--verbose", help="augmente la verbosité de sortie", action="store_true")
args = parser.parse_args()
if args.verbose:
print("verbosité activée")
Nous allons simplement en ajouter un au code avec "-v" en amont de "--verbose" dans les options de add_argument(). Sachez que le dernier paramètre saisi est la clé de paramètre, ici c’est "--verbose", les autres en amont sont des raccourcies, ici "-v".
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse8.py -v
verbosité activée
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse8.py --help
usage: argparse8.py [-h] [-v]
optional arguments:
-h, --help show this help message and exit
-v, --verbose augmente la verbosité de sortie
Notez que la nouvelle option est aussi indiquée dans l’aide.
Fichier argparse9.py :
Comment maintenant ajouter un argument positionné (obligatoire) supplémentaire ?
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("carré", type=int, help="affiche le carré du nombre passé en argument")
parser.add_argument("-v", "--verbose", action="store_true", help="augmente la verbosité de sortie")
args = parser.parse_args()
reponse = args.carré**2
if args.verbose:
print("le carré de {} est égal à {}".format(args.carré, reponse))
else:
print(reponse)
Nous avons ajouté un argument positionné de type entier «carré» dans le code en ajoutant un autre appel à la méthode add_argument().
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse9.py
usage: argparse9.py [-h] [-v] carré
argparse9.py: error: the following arguments are required: carré
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse9.py 4
16
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse9.py 4 --verbose
le carré de 4 est égal à 16
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse9.py --verbose 4
le carré de 4 est égal à 16
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse9.py -v 4
le carré de 4 est égal à 16
L’option d’argument positionné apparaît dans l’aide, et on remarque que les argument optionnels sont entre crochets. L’argument positionné n’étant pas saisie l’aide renvoie un message d’erreur.
Le calcul de la valeur fonctionne bien
Notez que l’ordre importe peu avec les autres commandes passées.
Fichier argparse10.py :
Qu’en est-il si nous donnons à ce programme la possibilité d’avoir plusieurs niveaux de verbosité, et que celui-ci les prend en compte ?
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("carré", type=int, help="affiche le carré du nombre passé en argument")
parser.add_argument("-v", "--verbosity", type=int, help="augmente la verbosité de sortie")
args = parser.parse_args()
reponse = args.carré**2
if args.verbosity == 2:
print("le carré de {} est égal à {}".format(args.carré, reponse))
elif args.verbosity == 1:
print("{}² = {}".format(args.carré, reponse))
else:
print(reponse)
Ajout dans le code de tests de niveau de verbosité.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse10.py 4
16
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse10.py 4 -v
usage: argparse10.py [-h] [-v VERBOSITY] carré
argparse10.py: error: argument -v/--verbosity: expected one argument
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse10.py 4 -v 1
4² = 16
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse10.py 4 -v 2
le carré de 4 est égal à 16
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse10.py 4 -v 3
16
Tout semble bon sauf pour le dernier cas. Notre programme contient un bogue.
Fichier argparse11.py :
Comment restreindre les valeurs que --verbosity accepte ?
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("carré", type=int, help="affiche le carré du nombre passé en argument")
parser.add_argument("-v", "--verbosity", type=int, choices=[0, 1, 2], help="augmente la verbosité de sortie")
args = parser.parse_args()
reponse = args.carré**2
if args.verbosity == 2:
print("le carré de {} est égal à {}".format(args.carré, reponse))
elif args.verbosity == 1:
print("{}² = {}".format(args.carré, reponse))
else:
print(reponse)
On ajoute l’option choices=[] à la méthode add_argument().
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse11.py 4 -v 3
usage: argparse11.py [-h] [-v {0,1,2}] carré
argparse11.py: error: argument -v/--verbosity: invalid choice: 3 (choose from 0, 1, 2)
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse11.py 4 -h
usage: argparse11.py [-h] [-v {0,1,2}] carré
positional arguments:
carré affiche le carré du nombre passé en argument
optional arguments:
-h, --help show this help message and exit
-v {0,1,2}, --verbosity {0,1,2} augmente la verbosité de sortie
Notez que ce changement est pris en compte à la fois dans le message d’erreur et dans le texte d’aide.
Essayons maintenant une approche différente pour jouer sur la verbosité. Cela correspond également à comment le programme CPython gère ses propres paramètres de verbosité (jetez un œil sur la sortie de la commande python --help) :
Fichier argparse12.py :
Comment compter le nombre fois où un paramètre est saisi ?
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("carré", type=int, help="affiche le carré du nombre passé en argument")
parser.add_argument("-v", "--verbosity", action="count", help="augmente la verbosité de sortie")
args = parser.parse_args()
reponse = args.carré**2
if args.verbosity == 2:
print("le carré de {} est égal à {}".format(args.carré, reponse))
elif args.verbosity == 1:
print("{}² = {}".format(args.carré, reponse))
else:
print(reponse)
Nous avons introduit une autre action "count" à la méthode add_argument(), pour compter le nombre d’occurrences d’un argument optionnel en particulier :
Oui, c’est maintenant d’avantage une option (similaire à action="store_true") de la version précédente de notre script. C’est plus logique pour comprendre le message d’erreur.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse12.py 4
16
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7\_Modules$ ./argparse12.py 4 -v
4² == 16
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse12.py 4 -vv
le carré de 4 est égal à 16
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse12.py 4 --verbosity --verbosity
le carré de 4 est égal à 16
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse12.py 4 -v 1
usage: argparse12.py [-h] [-v] carré
argparse12.py: error: unrecognized arguments: 1
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse12.py 4 -h
usage: argparse12.py [-h] [-v] carré
positional arguments:
carré affiche le carré du nombre passé en argument
optional arguments:
-h, --help show this help message and exit
-v, --verbosity augmente la verbosité de sortie
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse12.py 4 -vvv
16
La commande calcule le carré
Cela se comporte de la même manière que l’action
"store_true".Maintenant voici une démonstration de ce que l’action
"count"fait. Vous avez sûrement vu ce genre d’utilisation auparavant. Et si vous ne spécifiez pas l’option -v, cette option prendra la valeurNone.Comme on s’y attend, en spécifiant l’option dans sa forme longue, on devrait obtenir la même sortie.
Une valeur passé en paramètre génère une erreur.
Affiche l’aide normalement
La dernière sortie du programme montre que celui-ci contient un bogue.
Malheureusement, notre sortie d’aide n’est pas très informative à propos des nouvelles possibilités de notre programme, mais cela peut toujours être corrigé en améliorant sa documentation (en utilisant l’argument help).
Fichier argparse13.py :
Comment améliorer la documentation de l’exercice précédent et corriger le bogue ?
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("carré", type=int, help="affiche le carré du nombre passé en argument")
parser.add_argument("-v", "--verbosity", action="count", help="augmente la verbosité de sortie")
args = parser.parse_args()
reponse = args.carré**2
# corection: remplacer == avec >=
if args.verbosity >= 2:
print("le carré de {} est égal à {}".format(args.carré , reponse))
elif args.verbosity >= 1:
print("{}² = {}".format(args.carré , reponse))
else:
print(reponse)
Il suffit de changer le test «==» par «>=».
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse13.py 4 -vvv
le carré de 4 est égal à 16
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse13.py 4 -vvvv
le carré de 4 est égal à 16
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse13.py 4
Traceback (most recent call last):
File "argparse13.py", line 12, in <module>
if args.verbosity >= 2:
TypeError: '>=' not supported between instances of 'NoneType' and 'int'
Les premières exécutions du programme sont correctes, et le bogue que nous avons eu précédemment est corrigé.
La troisième sortie du programme est un autre bogue introduit par la modification.
Nous voulons que pour n’importe quelle valeur >= 2 le programme soit verbeux tout en calculant le carré sans ce paramètre.
Fichier argparse14.py :
Comment corriger le nouveau bogue du code de l’exemple précédent pour avoir la sortie du carré ?
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("carré", type=int, help="affiche le carré du nombre passé en argument")
parser.add_argument("-v", "--verbosity", action="count", default=0, help="augmente la verbosité de sortie")
args = parser.parse_args()
reponse = args.carré**2
# corection: remplacer == avec >=
if args.verbosity >= 2:
print("le carré de {} est égal à {}".format(args.carré , reponse))
elif args.verbosity >= 1:
print("{}² = {}".format(args.carré , reponse))
else:
print(reponse)
Nous introduisons une nouvelle option default= dans la méthode add_argument(). Nous la définisons à l’entier 0 pour la rendre compatible avec les autres valeurs entières de l’option count=. Rappelez-vous que par défaut, si un argument optionnel n’est pas spécifié, il sera définit à None une valeur booléenne, et ne pourra donc pas être comparé à une valeur de type entier. Une erreur TypeError sera alors levée.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse14.py 4
16
Fichier argparse15.py :
Qu’en est-il si nous souhaitons étendre notre mini programme pour le rendre capable de calculer d’autres puissances, et pas seulement des carrés?
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("x", type=int, help="la base")
parser.add_argument("y", type=int, help="l’exposant")
parser.add_argument("-v", "--verbosity", action="count", default=0)
args = parser.parse_args()
reponse = args.x**args.y
if args.verbosity >= 2:
print("{} à la puissance {} est égal à {}".format(args.x, args.y, reponse))
elif args.verbosity >= 1:
print("{}^{} = {}".format(args.x, args.y, reponse))
else:
print(reponse)
Nous modifions les arguments de saisies et l’opération de calcul.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse15.py
usage: argparse15.py [-h] [-v] x y
argparse15.py: error: the following arguments are required: x, y
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse15.py -h
usage: argparse15.py [-h] [-v] x y
positional arguments:
x la base
y l’exposant
optional arguments:
-h, --help show this help message and exit
-v, --verbosity
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse15.py 4 2 -v
4^2 = 16
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse15.py 4 2 -vv
4 à la puissance 2 est égal à 16
Il est à noter que jusqu’à présent nous avons utilisé le niveau de verbosité pour changer le texte qui est affiché.
Fichier argparse16.py :
Comment utiliser le principe du niveau de verbosité pour changer de sens de texte ?
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("x", type=int, help="la base")
parser.add_argument("y", type=int, help="l’exposant")
parser.add_argument("-v", "--verbosity", action="count", default=0)
args = parser.parse_args()
reponse = args.x**args.y
if args.verbosity >= 2:
print("Exécution de '{}'".format(__file__))
if args.verbosity >= 1:
print("{}^{} = ".format(args.x, args.y), end="")
print(reponse)
Modifions le texte affiché par les options args.verbosity pour afficher la commande exécutée.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse16.py 4 2
16
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse16.py 4 2 -v
4^2 = 16
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7\_Modules$ ./argparse16.py 4 2 -vv
Exécution de './argparse16.py'
4^2 = 16
Jusque là, nous avons travaillé avec deux méthodes parse_args() et add_argument() d’une instance de argparse.ArgumentParser.
Voyons maintenant l’utilisation de la méthode add_mutually_exclusive_group(). Cette méthode nous permet de spécifier des paramètres qui sont en conflit entre eux.
Fichier argparse17.py :
Comment utiliser add_mutually_exclusive_group() ?
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import argparse
parser = argparse.ArgumentParser()
group = parser.add_mutually_exclusive_group()
group.add_argument("-v", "--verbose", action="store_true")
group.add_argument("-q", "--quiet", action="store_true")
parser.add_argument("x", type=int, help="la base")
parser.add_argument("y", type=int, help="l’exposant")
args = parser.parse_args()
reponse = args.x**args.y
if args.quiet:
print(reponse)
elif args.verbose:
print("{} à la puissance {} est égal à {}".format(args.x, args.y, reponse))
else:
print("{}^{} = {}".format(args.x, args.y, reponse))
Changeons aussi le reste du programme de telle sorte que la nouvelle fonctionnalité fasse sens. Nous allons introduire l’option --quiet, qui va avoir l’effet opposé de l’option --verbose :
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse17.py 4 2
4^2 == 16
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse17.py 4 2 -q
16
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse17.py 4 2 -v
4 à la puissance 2 est égal à 16
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse17.py 4 2 -vq
usage: argparse17.py [-h] [-v | -q] x y
argparse17.py: error: argument -q/--quiet: not allowed with argument -v/--verbose
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse17.py 4 2 -v --quiet
usage: argparse17.py [-h] [-v | -q] x y
test.py: error: argument -q/--quiet: not allowed with argument -v/--verbose
Avant d’en finir, vous voudrez certainement dire à vos utilisateurs de votre outil de ligne de commande quel est le but principal du programme. Juste dans le cas ou ils ne le sauraient pas :-)
Fichier argparse18.py :
Comment modifier l’aide d’un programme en ligne de commande avec un titre général ?
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import argparse
parser = argparse.ArgumentParser(description="calcule X à la puissance Y")
group = parser.add_mutually_exclusive_group()
group.add_argument("-v", "--verbose", action="store_true")
group.add_argument("-q", "--quiet", action="store_true")
parser.add_argument("x", type=int, help="la base")
parser.add_argument("y", type=int, help="l’exposant")
args = parser.parse_args()
reponse = args.x**args.y
if args.quiet:
print(reponse)
elif args.verbose:
print("{} à la puissance {} est égal à {}".format(args.x, args.y, reponse))
else:
print("{}^{} = {}".format(args.x, args.y, reponse))
On ajoute l’option description= lors de la création de l’objet argparse.ArgumentParser()
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse18.py --help
usage: argparse18.py [-h] [-v \| -q] x y
calcule X à la puissance Y
positional arguments:
x la base
y l’exposant
optional arguments:
-h, --help show this help message and exit
-v, --verbose
-q, --quiet
C’est bien jolie tout cela mais on mélange de l’anglais avec du Français.
Fichier argparse19.py :
Comment faire pour traduire les messages d’aide en Français ?
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import gettext
__TRANSLATIONS = {
'ambiguous option: %(option)s could match %(matches)s': 'option ambiguë: %(option)s parmi %(matches)s', 'argument "-" with mode %r': 'argument "-" en mode %r', 'cannot merge actions - two groups are named %r': 'cannot merge actions - two groups are named %r', "can't open '%(filename)s': %(error)s": "can't open '%(filename)s': %(error)s", 'dest= is required for options like %r': 'dest= is required for options like %r', 'expected at least one argument': 'au moins un argument est attendu', 'expected at most one argument': 'au plus un argument est attendu', 'expected one argument': 'un argument est nécessaire', 'ignored explicit argument %r': 'ignored explicit argument %r', 'invalid choice: %(value)r (choose from %(choices)s)': 'choix invalide: %(value)r (parmi %(choices)s)', 'invalid conflict_resolution value: %r': 'invalid conflict_resolution value: %r', 'invalid option string %(option)r: must start with a character %(prefix_chars)r': 'invalid option string %(option)r: must start with a character %(prefix_chars)r', 'invalid %(type)s value: %(value)r': 'valeur invalide de type %(type)s: %(value)r', 'mutually exclusive arguments must be optional': 'mutually exclusive arguments must be optional', 'not allowed with argument %s': "pas permis avec l'argument %s", 'one of the arguments %s is required': 'au moins un argument requis parmi %s', 'optional arguments': 'arguments optionnels', 'positional arguments': 'arguments positionnels', "'required' is an invalid argument for positionals": "'required' is an invalid argument for positionals", 'show this help message and exit': 'afficher ce message d\’aide', 'unrecognized arguments: %s': 'argument non reconnu: %s', 'unknown parser %(parser_name)r (choices: %(choices)s)': 'unknown parser %(parser_name)r (choices: %(choices)s)', 'usage: ': 'utilisation: ', '%(prog)s: error: %(message)s\n': '%(prog)s: erreur: %(message)s\n', '%r is not callable': '%r is not callable', }
gettext.gettext = lambda text: __TRANSLATIONS[text] or text
import argparse
parser = argparse.ArgumentParser(description="calcule X à la puissance Y")
group = parser.add_mutually_exclusive_group()
group.add_argument("-v", "--verbose", action="store_true")
group.add_argument("-q", "--quiet", action="store_true")
parser.add_argument("x", type=int, help="la base")
parser.add_argument("y", type=int, help="l’exposant")
args = parser.parse_args()
reponse = args.x**args.y
if args.quiet:
print(reponse)
elif args.verbose:
print("{} à la puissance {} est égal à {}".format(args.x, args.y, reponse))
else:
print("{}^{} = {}".format(args.x, args.y, reponse))
La traduction se fait avec gettext.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ ./argparse19.py --help
utilisation: argparse19.py [-h] [-v | -q] x y
calcule X à la puissance Y
arguments positionnels:
x la base
y l’exposant
arguments optionnels:
-h, --help affiche ce message d’aide
-v, --verbose
-q, --quiet
utilisateur@MachineUbuntu:~/repertoire_de_developpement/7_Modules$ cd ..
Gestion des dates et du temps#
Date et heure#
Datetime est un module qui permet de manipuler des dates et des durées sous forme d’objets. L’idée est simple: vous manipulez l’objet pour faire tous vos calculs, et quand vous avez besoin de l’afficher, vous formatez l’objet en chaîne de caractères.
On peut créer artificiellement un objet datetime , ses paramètres sont:
datetime (année, mois, jour, heure, minute, seconde, microseconde, fuseau horaire)
Mais seuls «année», «mois» et «jour» sont obligatoires.
>>> from datetime import datetime
>>> datetime(2000, 1, 1)
datetime.datetime(2000, 1, 1, 0, 0)
Nous sommes ici le premier janvier 2000, à la seconde et la minute zéro, de l’heure zéro.
On peut bien entendu récupérer l’heure et la date du jour:
>>> actuellement = datetime.now()
>>> actuellement
datetime.datetime(2021, 7, 9, 10, 13, 1, 25073)
>>> actuellement.year
2021
>>> actuellement.month
7
>>> actuellement.day
9
>>> actuellement.hour
10
>>> actuellement.minute
13
>>> actuellement.second
1
>>> actuellement.microsecond
25073
>>> actuellement.isocalendar() # année, semaine, jour
datetime.IsoCalendarDate(year=2021, week=27, weekday=5)
>>> maintenant = datetime.now # obtenir l’heure avec une variable
>>> print(maintenant())
2021-07-09 10:14:51.359460
>>> print(maintenant())
2021-07-09 10:15:0.918195
Enfin, si vous souhaitez uniquement vous occuper de la date ou de l’heure:
>>> print(maintenant().strftime('%Hh %Mmin %Ss %d/%m/%Y')) # change une date en chaîne.
10h 16min 22s 09/07/2021
>>> from datetime import date, time, datetime
>>> maDate = datetime.strptime('2021-06-05 12:30:00', '%Y-%m-%d %H:%M:%S') # change une chaîne en date.
>>> print(maDate)
2021-06-05 12:30:00
>>> maDate
datetime.datetime(2021, 6, 5, 12, 30)
Durée#
En plus de pouvoir récupérer la date du jour, on peut calculer la différence entre deux dates. Par exemple, combien de temps y a-t-il entre aujourd’hui et le premier jour de l’an 2000 ?
>>> duree = maintenant() - datetime(2000, 1, 1)
>>> duree
datetime.timedelta(days=7860, seconds=39227, microseconds=140524)
Et vous découvrez ici un autre objet, le timedelta. Cet objet représente une durée en jours, secondes et microsecondes.
>>> duree.days
7860
>>> duree.seconds
39227
>>> duree.microseconds
140524
>>> duree.total_seconds
<built-in method total_seconds of datetime.timedelta object at 0x7efc4f7655d0>
>>> duree.total_seconds()
679144227.140524
On peut créer son propre timedelta :
>>> from datetime import timedelta
>>> print(timedelta(days=3, seconds=100))
3 days, 0:01:40
Cela permet de répondre à la question : «Quelle date serons-nous dans 2 jours, 4 heures, 3 minutes, et 12 secondes ?»:
>>> print(maintenant() + timedelta(days=2, hours=4, minutes=3, seconds=12))
2021-07-11 15:12:00.371922
Les objets datetime et timedelta sont immutables. Ainsi si vous voulez utiliser une version légèrement différente d’un objet datetime , il faudra toujours en créer un nouveau. Par exemple:
>>> actuellement.replace(year=1995) # on créer un nouvel objet
datetime.datetime(1995, 7, 9, 10, 13, 1, 25073)
Vous noterez que je ne parles pas de fuseau horaire. Et bien c’est parce que l’implémentation Python est particulièrement ratée : l’API est compliquée et les données ne sont pas à jour. Il faut dire que la mesure du temps, contrairement à ce qu’on pourrait penser, n’est pas vraiment le truc le plus stable du monde, et des pays changent régulièrement leur manière de faire.
Calendrier#
Le module calendar.
Il permet de manipuler un calendrier comme un objet, et de déterminer les jours d’un mois, les semaines, vérifier les caractéristiques d’un jour en particulier, etc. :
>>> import calendar
>>> calendar.mdays # combien de jour par mois ?
[0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31]
>>> calendar.isleap(2000) # est-ce une année bissextile ?
True
>>> calendar.weekday(2000, 1, 1) # quel jour était cette date ?
5
>>> calendar.MONDAY, calendar.TUESDAY, calendar.WEDNESDAY, calendar.THURSDAY, calendar.FRIDAY
(0, 1, 2, 3, 4)
On peut instancier un calendrier et itérer dessus:
>>> cal = calendar.Calendar()
>>> cal.getfirstweekday()
0
>>> list(cal.iterweekdays())
[0, 1, 2, 3, 4, 5, 6]
>>> list(cal.itermonthdays(2000, 1))
[0, 0, 0, 0, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 0, 0, 0, 0, 0, 0]
>>> list(cal.itermonthdates(2000, 1))
[datetime.date(1999, 12, 27), datetime.date(1999, 12, 28), datetime.date(1999, 12, 29), datetime.date(1999, 12, 30), datetime.date(1999, 12, 31), datetime.date(2000, 1, 1), datetime.date(2000, 1, 2), datetime.date(2000, 1, 3), datetime.date(2000, 1, 4), datetime.date(2000, 1, 5), datetime.date(2000, 1, 6), datetime.date(2000, 1, 7), datetime.date(2000, 1, 8), datetime.date(2000, 1, 9), datetime.date(2000, 1, 10), datetime.date(2000, 1, 16), datetime.date(2000, 1, 17), datetime.date(2000, 1, 18), datetime.date(2000, 1, 19), datetime.date(2000, 1, 20), datetime.date(2000, 1, 21), datetime.date(2000, 1, 22), datetime.date(2000, 1, 23), datetime.date(2000, 1, 24), datetime.date(2000, 1, 25), datetime.date(2000, 1, 26), datetime.date(2000, 1, 27), datetime.date(2000, 1, 28), datetime.date(2000, 1, 29), datetime.date(2000, 1, 30), datetime.date(2000, 1, 31), datetime.date(2000, 2, 1), datetime.date(2000, 2, 2), datetime.date(2000, 2, 3), datetime.date(2000, 2, 4), datetime.date(2000, 2, 5), datetime.date(2000, 2, 6)]
>>> cal.monthdayscalendar(2000, 1)
[[0, 0, 0, 0, 0, 1, 2], [3, 4, 5, 6, 7, 8, 9], [10, 11, 12, 13, 14, 15, 16], [17, 18, 19, 20, 21, 22, 23], [24, 25, 26, 27, 28, 29, 30], [31, 0, 0, 0, 0, 0, 0]]
Comme souvent Python vient aussi avec de très bons modules tierces pour manipuler les dates :
dateutils est un datetime boosté aux hormones qui permet notamment de donner des durées floues comme “+ 1 mois” et de gérer des événements qui se répètent.
babel n’est pas spécialisé dans les dates mais dans la localisation. Le module possède des outils pour formater des dates selon le format de chaque pays, et aussi avec des formats naturels comme “il y a une minute”.
pytz est une implémentation saine de gestion des fuseaux horaires en Python.
Module Windows#
pip install pywin32
Vous pouvez écrire des logs dans le gestionnaire d’évènements windows. Pour cela vous devez utiliser le module win32evlog
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import win32evtlog
import pprint
import sys
# S'abonne aux événements de l'application et les enregistre.
# Pour déclencher manuellement un nouvel événement, ouvrez une console d'administration et tapez: (remplacez 125 par tout autre ID qui vous convient)
# eventcreate.exe /L "application" /t warning /id 125 /d "Ceci est un avertissement de test"
#
# event_context peut être `None` si ce n'est pas obligatoire, c'est juste pour montrer comment cela fonctionne
event_context = {"info": "cet objet est toujours passé à votre retour"}
# Event log source to listen to
event_source = 'application'
def new_logs_event_handler(raison, contexte, evnmt):
"""
Appelé lorsque de nouveaux événements sont enregistrés.
raison - raison pour laquelle l'événement a été enregistré?
contexte- contexte dans lequel le gestionnaire d'événements a été enregistré
evnmt - événement capturé
"""
# Imprimez simplement quelques informations sur l'événement
print('raison', raison, 'contexte', contexte, 'événement capturé', evnmt)
# Rendre l'événement en XML, il y a peut-être un moyen d'obtenir un objet mais je ne l'ai pas trouvé
print('Événement rendu :', win32evtlog.EvtRender(evt, win32evtlog.EvtRenderEventXml))
# ligne vide pour séparer les journaux
print(' - ')
# Assurez-vous que tout le texte imprimé est réellement imprimé sur la console maintenant
sys.stdout.flush()
return 0
# Abonnez-vous aux futurs événements
subscription = win32evtlog.EvtSubscribe(event_source, win32evtlog.EvtSubscribeToFutureEvents, None, Callback=new_logs_event_handler, Context=event_context, Query=None)
Exemple plus complet
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import win32evtlog
import win32api
import win32con
import win32security # Pour traduire NT Sids en noms de compte.
import win32evtlogutil
def ReadLog(computer, logType="Application", dumpEachRecord = 0):
# Lit l'intégralité du journal.
h=win32evtlog.OpenEventLog(computer, logType)
numRecords = win32evtlog.GetNumberOfEventLogRecords(h)
print("Il y a% enregistrements" % numRecords)
num=0
while 1:
objects = win32evtlog.ReadEventLog(h, win32evtlog.EVENTLOG_BACKWARDS_READ|win32evtlog.EVENTLOG_SEQUENTIAL_READ, 0)
if not objects:
break
for object in objects:
# À des fins de test, mais ne l'imprime pas.
msg = win32evtlogutil.SafeFormatMessage(object, logType)
if object.Sid is not None:
try:
domain, user, typ = win32security.LookupAccountSid(computer, object.Sid)
sidDesc = "%s/%s" % (domain, user)
except win32security.error:
sidDesc = str(object.Sid)
user_desc = "Événement associé à l'utilisateur %s" % (sidDesc,)
else:
user_desc = None
if dumpEachRecord:
print("Enregistrement d'événement de %r généré à %s"\ % (object.SourceName, object.TimeGenerated.Format()))
if user_desc:
print user_desc
try:
print msg
except UnicodeError:
print("(message d'impression d'erreur unicode: repr() suit…)")
print(repr(msg))
num = num + len(objects)
if numRecords == num:
print("Succès de la lecture complète", numRecords, "enregistrements")
else:
print("Impossible d'obtenir tous les enregistrements - signalé %d, mais trouvé %d" % (numRecords, num))
print ("(Notez d'autres applications peuvent avoir écrit des enregistrements pendant l'exécution!)")
win32evtlog.CloseEventLog(h)
def usage():
print("Écrit un événement dans le journal des événements.")
print("-w : N'écrire aucun enregistrement de test.")
print("-r : Ne pas lire le journal des événements")
print("-c : nomOrdinateur : Traiter le journal sur l'ordinateur spécifié")
print("-v : Verbeux")
print("-t : LogType - Utiliser le journal spécifié - défaut = 'Application'")
def test():
# vérifier s'il fonctionne sous Windows NT, sinon, afficher un avis et terminer
if win32api.GetVersion() & 0x80000000:
print("Cet exemple ne fonctionne que sur NT")
return
import sys, getopt
opts, args = getopt.getopt(sys.argv[1:], "rwh?c:t:v")
computer = None
do_read = do_write = 1
logType = "Application"
verbose = 0
if len(args)>0:
print("Arguments non valides")
usage()
return 1
for opt, val in opts:
if opt == '-t':
logType = val
if opt == '-c':
computer = val
if opt in ['-h', '-?']:
usage()
return
if opt == '-r':
do_read = 0
if opt == '-w':
do_write = 0
if opt == '-v':
verbose = verbose + 1
if do_write:
ph = win32api.GetCurrentProcess()
th = win32security.OpenProcessToken(ph,win32con.TOKEN_READ)
my_sid = win32security.GetTokenInformation(th,win32security.TokenUser)[0]
win32evtlogutil.ReportEvent(logType, 2,
strings=["Le texte du message pour l'événement 2", "Un autre insert"],
data="Raw\0Data".encode("ascii"), sid=my_sid)
win32evtlogutil.ReportEvent(logType, 1, eventType=win32evtlog.EVENTLOG_WARNING_TYPE,
strings=["Un avertissement", "Un avertissement encore plus grave"],
data="Raw\0Data".encode("ascii"), sid=my_sid)
win32evtlogutil.ReportEvent(logType, 1, eventType=win32evtlog.EVENTLOG_INFORMATION_TYPE,
strings=["Une info", "Trop d'informations"],
data="Raw\0Data".encode("ascii"), sid=my_sid)
print("Écriture réussie de 3 enregistrements dans le journal")
if do_read:
ReadLog(computer, logType, verbose > 0)
if __name__ == '__main__':
test()
L’organisation du code#
Structures de contrôles#
Structures alternatives#
If, else, elif#
Les instructions if, else, elif sont sans doute les plus connues.
Par exemple :
>>> import os
>>> x = int(input("SVP entrez un entier: "))
SVP entrez un entier: 42
>>> if x < 0:
... x = 0
... print('Nombre négatif remplacé par zéro')
... elif x == 0:
... print('Zéro')
... elif x == 1:
... print('Unité')
... else:
... print('Plus grand')
...
Plus grand
Il peut y avoir un nombre quelconque de parties elif et la partie else est facultative. Le mot clé elif est un raccourci pour else if, mais permet de gagner un niveau d’indentation. Une séquence if ... elif ... elif ... est par ailleurs équivalente aux instructions «switch» ou «case» disponibles dans d’autres langages.
Structures itératives#
For in#
Les instructions for in que propose Python sont un peu différente de celle que l’on peut trouver en C ou en Pascal.
Au lieu de toujours itérer sur une suite arithmétique de nombres (comme en Pascal), ou de donner à l’utilisateur la possibilité de définir le pas d’itération et la condition de fin (comme en C), l’instruction for en Python itère sur les éléments d’une séquence (qui peut être une liste, une chaîne de caractères…), dans l’ordre dans lequel ils apparaissent dans la séquence.
Par exemple :
>>> # Mesure quelques chaînes de caractères
>>> mots = ['fenêtre', 'chat', 'quantique']
>>> for l in mots:
... print(l, len(l))
...
fenêtre 7
chat 4
quantique 9
Le code qui modifie une collection tout en itérant sur cette même collection peut être délicat à mettre en place.
>>> # Strategie: Itérer sur une copie
>>> utilisateurs = {'Vador': 'inactif', 'Luc': 'actif', 'Padawan': 'actif'}
>>> for utilisateur, statut in utilisateurs.copy().items():
... if statut == 'inactif':
... del utilisateurs[utilisateur]
...
...
>>> utilisateurs
{'Luc': 'actif', 'Padawan': 'actif'}
Au lieu de cela, il est généralement plus simple de boucler sur une copie de la collection ou de créer une nouvelle collection :
>>> # Strategie: Créer une nouvelle collection utilisateurs
>>> utilisateurs = {'Vador': 'inactif', 'Luc': 'actif', 'Padawan': 'actif'}
>>> utilisateurs_actifs = utilisateurs.copy()
>>> utilisateurs_vivants = []
>>> for utilisateur, statut in utilisateurs.items():
... if statut == 'inactif':
... del utilisateurs_actifs[utilisateur]
... else:
... utilisateurs_vivants.append(utilisateur)
...
>>> utilisateurs_actifs
{'Luc': 'actif', 'Padawan': 'actif'}
>>> utilisateurs_vivants
['Luc', 'Padawan']
>>> utilisateurs
{'Vador': 'inactif', 'Luc': 'actif', 'padawan': 'actif'}
Pour itérer sur les indices d’une séquence, on peut combiner les fonctions range() et len() :
>>> phrase = ['Luc', 'a', 'un', 'petit', 'laser']
>>> for mot in range(len(phrase)):
... print(mot, phrase[mot])
...
0 Luc
1 a
2 un
3 petit
4 laser
Cependant, dans la plupart des cas, il est plus pratique d’utiliser la fonction enumerate().
>>> for mot in enumerate(phrase):
... print(mot[0], mot[1])
...
0 Luc
1 a
2 un
3 petit
4 laser
While#
L’instruction while permet de faire des boucle suivant une condition.
break, continue#
L’instruction break, comme en C, interrompt la boucle for ou while.
Les boucles peuvent également disposer d’une instruction else. Celle-ci est exécutée lorsqu’une boucle se termine alors que tous ses éléments ont été traités (dans le cas d’un for) ou que la condition devient fausse (dans le cas d’un while), mais pas lorsque la boucle est interrompue par une instruction break.
L’exemple suivant, qui effectue une recherche de nombres premiers, en est une démonstration :
>>> for n in range(2, 10):
... for x in range(2, n):
... if n % x == 0:
... print(n, 'égal', x, '*', n//x)
... break
... else:
... # la boucle s’est terminée sans trouver de facteur
... print(n, 'est un nombre premier')
...
...
2 est un nombre premier
3 est un nombre premier
4 égal 2 * 2
5 est un nombre premier
6 égal 2 * 3
7 est un nombre premier
8 égal 2 * 4
9 égal 3 * 3
Oui, ce code est correct. Regardez attentivement : l’instruction else est rattachée à la boucle for, et non à l’instruction if.
Lorsqu’elle est utilisée dans une boucle, la clause else est donc plus proche de celle associée à une instruction try que de celle associée à une instruction if: la clause else d’une instruction try s’exécute lorsqu’aucune exception n’est déclenchée, et celle d’une boucle lorsqu’aucun break n’intervient. Nous verrons plus ultérieurement dans ce cours l’instruction try et le traitement des exceptions.
L’instruction continue, également empruntée au C, fait passer la boucle à son itération suivante :
>>> for num in range(2, 10):
... if num % 2 == 0:
... print("Un nombre pair a été trouvé : ", num)
... continue
... print("Un nombre impair a été trouvé : ", num)
...
Un nombre pair a été trouvé : 2
Un nombre impair a été trouvé : 3
Un nombre pair a été trouvé : 4
Un nombre impair a été trouvé : 5
Un nombre pair a été trouvé : 6
Un nombre impair a été trouvé : 7
Un nombre pair a été trouvé : 8
Un nombre impair a été trouvé : 9
pass#
L’instruction pass ne fait rien. Elle peut être utilisée lorsqu’une instruction est nécessaire pour fournir une syntaxe correcte, mais qu’aucune action ne doit être effectuée.
Par exemple :
>>> while True:
... pass # Attente occupée pour l'interruption du clavier (Ctrl + C)
...
^CTraceback (most recent call last):
File "<stdin>", line 2, in <module>
KeyboardInterrupt
On utilise couramment cette instruction pour créer des classes minimales d’objets :
>>> class MaClasseVide:
... pass
...
>>>
Un autre cas d’utilisation du pass est de réserver un espace en phase de développement pour une fonction ou un traitement conditionnel, vous permettant ainsi de construire votre code à un niveau plus abstrait.
L’instruction pass est alors ignorée silencieusement :
>>> def initlog(*args):
... pass # N'oubliez pas de mettre en œuvre cela!
...
alternative do while#
>>> while True:
... #… code
... if cond :
... break
Techniques de boucles des dictionnaires#
Lorsque vous faites une boucle sur un dictionnaire, les clés et leurs valeurs peuvent être récupérées en même temps en utilisant la méthode items() :
>>> chevaliers_jedi = {'Luc': 'le padawan', 'Yoda': 'le grand maître', 'Obi-Wan Kenobi': 'le guerrier'}
>>> for k, v in chevaliers_jedi.items(): print(k, v)
...
Luc le padawan
Yoda le grand maître
Obi-Wan Kenobi le guerrier
Lorsque vous faites une boucle sur une séquence, la position et la valeur correspondante peuvent être récupérées en même temps en utilisant la fonction enumerate() :
>>> for i, v in enumerate(['tic', 'tac', 'toe']): print(i, v)
...
0 tic
1 tac
2 toe
Pour faire une boucle sur deux séquences, ou plus en même temps, les éléments peuvent être associés en utilisant la fonction zip() :
>>> questions = ['nom', 'côté de la force', 'couleur du sabre']
>>> réponses = ['luc', 'la lumière', 'le vert']
>>> for q, r in zip(questions, réponses):
... print('Quel est votre {0} ? C\’est {1}.'.format(q, r))
...
Quel est votre nom ? C’est luc.
Quel est votre côté de la force ? C’est la lumière.
Quel est votre couleur du sabre ? C’est le vert.
Pour faire une boucle en sens inverse sur une séquence, commencez par spécifier la séquence dans son ordre normal, puis appliquez la fonction reversed() :
>>> for n in reversed(range(1, 10, 2)): print(n)
...
9
7
5
3
1
Pour faire une boucle sur une séquence de manière ordonnée, utilisez la fonction sorted() qui renvoie une nouvelle liste ordonnée sans altérer la source :
>>> panier = ['pomme', 'orange', 'pomme', 'poire', 'orange', 'banane']
>>> for f in sorted(panier): print(f)
...
banane
orange
orange
poire
pomme
pomme
L’utilisation de la fonction set() sur une séquence élimine les doublons. L’utilisation de la fonction sorted() en combinaison avec set() sur une séquence est une façon idiomatique de boucler sur les éléments uniques d’une séquence dans l’ordre :
>>> for f in sorted(set(panier)): print(f)
...
banane
orange
poire
pomme
Il est parfois tentant de modifier une liste pendant son itération. Cependant, c’est souvent plus simple et plus sûr de créer une nouvelle liste à la place. :
>>> import math
>>> données_brutes = [56.2, float('NaN'), 51.7, 55.3, 52.5, float('NaN'), 47.8]
>>> données_filtrées = []
>>> for valeur in données_brutes:
... if not math.isnan(valeur):
... données_filtrées.append(valeur)
...
...
>>> données_filtrées
[56.2, 51.7, 55.3, 52.5, 47.8]
La génération de la documentation du programme#
Voir https://www.codeflow.site/fr/article/documenting-python-code
Sphinx est un outil très complet permettant de générer des documentations riches et bien structurées. Il a originellement été créé pour la documentation du langage Python, et a très vite été utilisé pour documenter de nombreux autres projets.
Pour ce qui est de la documentation de code, il est évidemment bien adapté au Python, mais peut aussi être utilisé avec d’autres langages.
Parmi les fonctionnalités que Sphinx propose :
la génération automatique de la documentation à partir du code (avec le support de nombreux langages),
la possibilité de faire des références entre les pages,
le support de plusieurs formats de sortie (HTML, PDF, LaTeX, EPUB, pages de manuel, …),
la gestion d’extensions permettant de l’adapter à toutes les situations et langages.
Configurer Sphinx pour Python#
Le répertoire racine Sphinx d’une collection de textes bruts permettant de générer la documentation est appelé le répertoire source. C’est le répertoire que nous avons nommé lors de l’installation «sources-documents».
Ce répertoire contient également le fichier de configuration Sphinx conf.py, où vous pouvez configurer tous les aspects de la façon dont Sphinx lit vos sources et construit votre documentation.
Pour paramétrer tous ces aspects, il faut éditer le fichier conf.py qui se trouve dans le dossier ~/repertoire_de_developpement/docs/sources-documents.
Configurations de base de sphinx#
Renseigner la racine des fichiers de CODE#
# -*- coding: utf-8 -*-
# == Configuration chemins =====================================
Indiquez où se trouve vos fichiers de code python pour générer votre documentation :
import os
import sys
sys.path.insert(0, os.path.abspath('../..'))
sys.setrecursionlimit(1500)
Informations sur le projet de documentation#
# == Informations du projet =====================================
Titres, logos, copyright et auteur :
project_title = "Documentation sur l’initiation à la programmation Python pour l’administrateur systèmes"
project_short_title = "Initiation Python 3 pour Administrateur"
project_description = "Formation d'initiation à la programmation Python pour l'administrateur systèmes."
project_logo = "images/logo.png"
project_favicon = "images/favicon.png"
copyright = '2021, Prénom NOM'
author = 'Prénom NOM'
Versions du document :
from Documentation.mon_module import __version__, __release_life_cycle__
# version 'X.Y' ou X est la version majeure incompatible avec la précédente, et Y est un ajout de fonctionnalités à la version.
version = __version__ # utilisation restructuredtext |version|.
# 'Pre-alpha' = faisabilité, 'Alpha' = développement, 'Beta' = tests et révisions, 'Release candidate' = qualification, 'Stable release' = prêt à déployer, 'Feature complete' = production, 'End of life' = obsolète.
release = __release_life_cycle__ # utilisation restructuredtext |release|.
Paramètres de documentation#
# == Configurations générales =====================================
Langue :
langage = 'fr'
# L’internationalisation de la documentation
locale_dirs = ['locales/']
gettext_compact = False
Le fichier d’entrée de la documentation et la coloration syntaxique :
# Le document maître toctree.
master_doc = 'index'
# Le thème de la coloration syntaxique
pygments_style = 'sphinx'
Extensions des fichiers de la documentation :
source_suffix = {
'.rst': 'restructuredtext',
'.txt': 'restructuredtext',
'.md': 'markdown',
}
# ou de la forme
# source_suffix = ['.rst', '.md']
# source_suffix = '.rst'
Autres paramètres :
# Liste des modèles, relatifs au répertoire source, qui correspondent aux
# fichiers et répertoires à ignorer lors de la recherche de fichiers source.
# Ce modèle affecte également html_static_path et html_extra_path.
exclude_patterns = ['.env']
# Une liste de chemins contenant des modèles supplémentaires
# (ou des modèles qui remplacent les modèles intégrés/spécifiques au thème).
# Les chemins relatifs sont considérés comme relatifs au répertoire de
# configuration.
templates_path = ['_templates']
L’apparence des documents#
Le thème HTML par défaut, Alabaster, est très minimaliste.
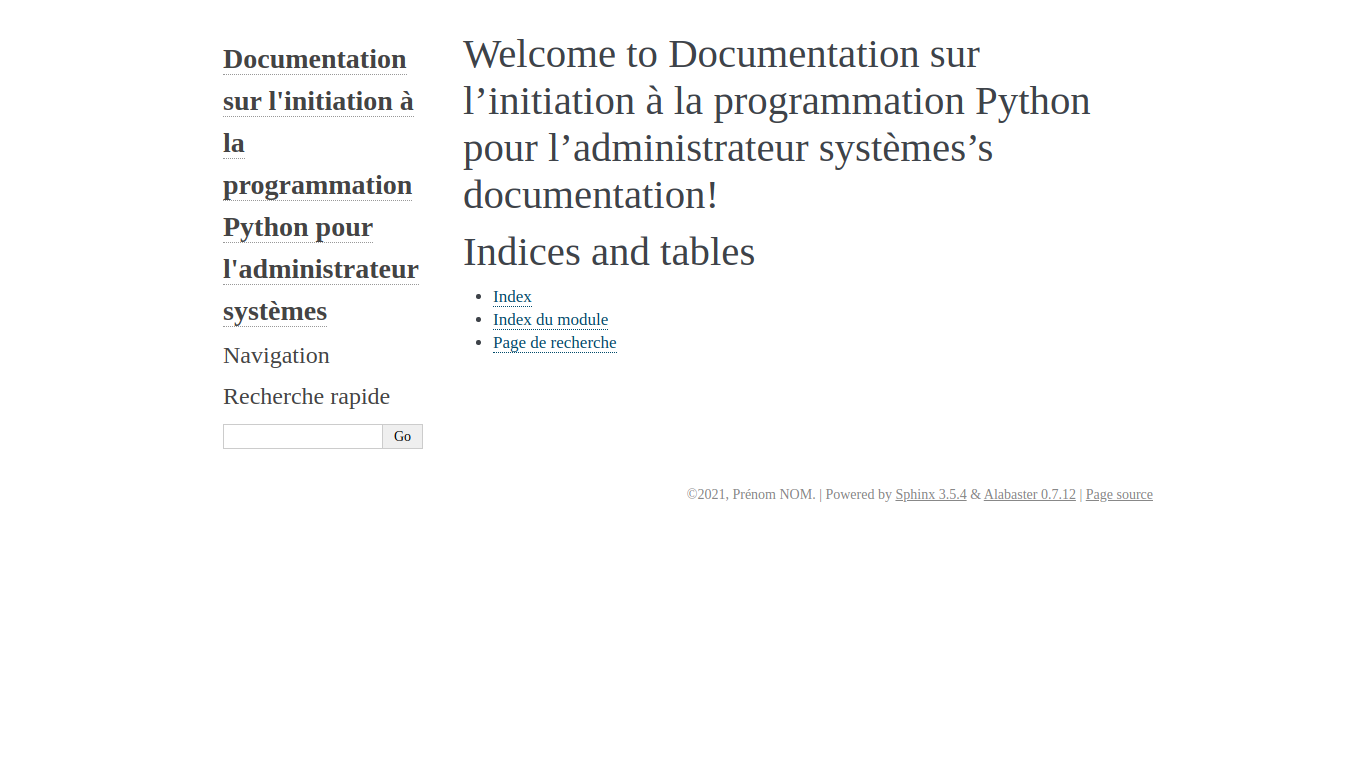
Pour avoir une documentation plus sexy, il est parfois préférable de changer le thème par défaut.
Changer le thème HTML de votre documentation#
Il existe un certain nombre de thèmes HTML intégrés à Sphinx, et de nombreux autres sont disponibles. Vous pouvez consulter les thèmes disponibles sur le site https://sphinx-themes.org/ .
On va donc voir comment installer le nouveau thème sphinx-book-theme (mais libre à vous d’en choisir un autre, le principe reste le même).
Le thème sphinx book#
Pour utiliser le thème «Sphinx book», il faut commencer par l’installer, ce qui peut être fait à l’aide de la commande suivante :
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ cd docs ; sudo pip install sphinx-book-theme
Collecting sphinx-book-theme
Downloading sphinx_book_theme-0.1.0-py3-none-any.whl (87 kB)
|████████████████████████████████| 87 kB 813 kB/s
Requirement already satisfied: sphinx<4,>=2 in /usr/local/lib/python3.9/dist-packages (from sphinx-book-theme) (3.5.4)
Requirement already satisfied: click in /usr/lib/python3/dist-packages (from sphinx-book-theme) (7.1.2)
Requirement already satisfied: docutils>=0.15 in /usr/local/lib/python3.9/dist-packages (from sphinx-book-theme) (0.16)
Collecting pydata-sphinx-theme~=0.6.0
Downloading pydata_sphinx_theme-0.6.3-py3-none-any.whl (1.4 MB)
|████████████████████████████████| 1.4 MB 3.9 MB/s
Collecting beautifulsoup4<5,>=4.6.1
Downloading beautifulsoup4-4.9.3-py3-none-any.whl (115 kB)
|████████████████████████████████| 115 kB 4.4 MB/s
Requirement already satisfied: pyyaml in /usr/lib/python3/dist-packages (from sphinx-book-theme) (5.3.1)
Collecting soupsieve>1.2
Downloading soupsieve-2.2.1-py3-none-any.whl (33 kB)
Requirement already satisfied: packaging in /usr/local/lib/python3.9/dist-packages (from sphinx<4,>=2->sphinx-book-theme) (20.9)
Requirement already satisfied: babel>=1.3 in /usr/local/lib/python3.9/dist-packages (from sphinx<4,>=2->sphinx-book-theme) (2.9.0)
Requirement already satisfied: imagesize in /usr/local/lib/python3.9/dist-packages (from sphinx<4,>=2->sphinx-book-theme) (1.2.0)
Requirement already satisfied: sphinxcontrib-qthelp in /usr/local/lib/python3.9/dist-packages (from sphinx<4,>=2->sphinx-book-theme) (1.0.3)
Requirement already satisfied: Pygments>=2.0 in /usr/local/lib/python3.9/dist-packages (from sphinx<4,>=2->sphinx-book-theme) (2.8.1)
Requirement already satisfied: requests>=2.5.0 in /usr/lib/python3/dist-packages (from sphinx<4,>=2->sphinx-book-theme) (2.25.1)
Requirement already satisfied: setuptools in /usr/lib/python3/dist-packages (from sphinx<4,>=2->sphinx-book-theme) (52.0.0)
Requirement already satisfied: sphinxcontrib-devhelp in /usr/local/lib/python3.9/dist-packages (from sphinx<4,>=2->sphinx-book-theme) (1.0.2)
Requirement already satisfied: alabaster<0.8,>=0.7 in /usr/local/lib/python3.9/dist-packages (from sphinx<4,>=2->sphinx-book-theme) (0.7.12)
Requirement already satisfied: snowballstemmer>=1.1 in /usr/local/lib/python3.9/dist-packages (from sphinx<4,>=2->sphinx-book-theme) (2.1.0)
Requirement already satisfied: sphinxcontrib-serializinghtml in /usr/local/lib/python3.9/dist-packages (from sphinx<4,>=2->sphinx-book-theme) (1.1.4)
Requirement already satisfied: sphinxcontrib-htmlhelp in /usr/local/lib/python3.9/dist-packages (from sphinx<4,>=2->sphinx-book-theme) (1.0.3)
Requirement already satisfied: sphinxcontrib-jsmath in /usr/local/lib/python3.9/dist-packages (from sphinx<4,>=2->sphinx-book-theme) (1.0.1)
Requirement already satisfied: Jinja2>=2.3 in /usr/local/lib/python3.9/dist-packages (from sphinx<4,>=2->sphinx-book-theme) (2.11.3)
Requirement already satisfied: sphinxcontrib-applehelp in /usr/local/lib/python3.9/dist-packages (from sphinx<4,>=2->sphinx-book-theme) (1.0.2)
Requirement already satisfied: pytz>=2015.7 in /usr/local/lib/python3.9/dist-packages (from babel>=1.3->sphinx<4,>=2->sphinx-book-theme) (2021.1)
Requirement already satisfied: MarkupSafe>=0.23 in /usr/local/lib/python3.9/dist-packages (from Jinja2>=2.3->sphinx<4,>=2->sphinx-book-theme) (1.1.1)
Requirement already satisfied: pyparsing>=2.0.2 in /usr/local/lib/python3.9/dist-packages (from packaging->sphinx<4,>=2->sphinx-book-theme) (2.4.7)
Installing collected packages: soupsieve, beautifulsoup4, pydata-sphinx-theme, sphinx-book-theme
Successfully installed beautifulsoup4-4.9.3 pydata-sphinx-theme-0.6.3 soupsieve-2.2.1 sphinx-book-theme-0.1.0
Ensuite, il faut indiquer à Sphinx d’utiliser ce thème.
Configuration des documents générés en sortie#
Le HTML#
Il faudra remplacer la variable «html_theme» dans «conf.py» et modifier dans la section HTML les paramètres pour ce thème :
# -- Options pour sortie HTML -------------------------------------------------
html_theme = 'sphinx_book_theme'
html_title = project_title
html_short_title = project_short_title
html_logo = project_logo
html_favicon = project_favicon
# -- Options du thème
html_theme_options = {
# Ajout du renvoie vers Gitlab
'repository_url': "http://gitlab.domaine-perso.fr/utilisateur/initiation_developpement_python_pour_administrateur",
'use_repository_button': True,
# Ajout de la possibilité de laisser des retours de dysfonctionnements
'use_issues_button': True,
# Ajout de la possibilité de laisser des propositions de corrections à la documentation
'use_edit_page_button': True,
# Ajout de la possibilité de travailler sur une branche définie
#'repository_branch': 'master',
# Ajout du chemin relatif vers les sources de la doc
'path_to_docs': "docs/sources-documents",
# Ajout d'un téléchargement Rest ou PDF de la page actuelle
'use_download_button': True,
# Ajout d'un bouton lecture plein écran
'use_fullscreen_button': True,
# Ajout de la table des matières dans le panneau latéral gauche
'home_page_in_toc': False,
# Titre du panneau latéral droite qui sera notre table des matières
'toc_title': "Contenu",
# Ajout au pied de page du panneau latéral gauche
'extra_navbar': "<p>Version " + version + " " + release + "</p>",
}
#html_sidebars = {
# "**": ["sbt-sidebar-nav.html", "sbt-sidebar-footer.html"]
#}
# Une liste de chemins contenant des fichiers statiques personnalisés
# (tels que des feuilles de style ou des fichiers de script).
# Les chemins relatifs sont considérés comme relatifs au répertoire de
# configuration.
# Ils sont copiés dans le répertoire \_static de la sortie après les fichiers
# statiques du thème.
# Par conséquent, un fichier nommé default.css écrasera le fichier default.css
# du thème.
html_static_path = ['_static']
LaTeX#
# -- Options pour LaTeX -------------------------------------------------------
latex_engine = 'xelatex'
latex_elements = {
# Le format du papier('letterpaper' ou 'a4paper').
'papersize': 'a4paper',
#
# La taille de la police ('10pt', '11pt' or '12pt').
'pointsize': '12pt',
#
# Trucs supplémentaires pour le préambule LaTeX.
'preamble': '',
#
# Alignement de la figure en LaTeX (flotteur)
'figure_align': 'htbp',
}
# latex_show_urls = 'footnote'
# latex_docclass = {
# 'howto': 'votreclassededocumentshowto', # Défaut 'article'
# 'manual': 'votreclassededocumentsmanual', # Défaut 'report'
# }
# Regroupement de l'arborescence de documents en fichiers LaTeX. Liste des tuples
# (fichier source, nom du fichier cible, titre, auteur, documentclass [howto, manuel ou votre classe]).
latex_documents = [
(master_doc, 'InitiationProgrammationPythonPourAdministrateurSystèmes.tex', project_title, author, 'manual'),
]
Pages de manuel#
# -- Options pour les pages de manuel ----------------------------------------
# Une entrée par page de manuel. Liste des tuples
# (fichier source, nom, description, auteurs, section du manuel).
man_pages = [
(master_doc, 'InitiationProgrammationPythonPourAdministrateurSystèmes', project_description, [author], 1),
]
Texinfo#
# -- Options pour Texinfo ---------------------------------------------------
# Regroupement de l'arborescence des documents dans des fichiers Texinfo.
# Liste des tuples (fichier source, nom de la cible, titre, auteur, répertoire, description, catégorie)
texinfo_documents = [
(master_doc, 'InitiationProgrammationPythonPourAdministrateurSystèmes', project_title, author, 'InitiationProgrammationPythonPourAdministrateurSystèmes', project_description, 'Miscellaneous'),
]
Epub#
# -- Options pour les Epub ---------------------------------------------------
# Informations bibliographiques Dublin Core.
epub_title = project_title
# L'identifiant unique du texte. Cela peut être un numéro ISBN
# ou la page d'accueil du projet.
# epub_identifier = ''
# Une identification unique pour le texte.
# epub_uid = ''
# A list of files that should not be packed into the epub file.
epub_exclude_files = ['search.html']
Inclure les extensions de documentation utiles pour Python#
Installation des extensions non incluses de base :
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ sudo apt install sphinx-intl texinfo xindy graphviz latexmk texlive-lang-french texlive-xetex fonts-freefont-otf ; sudo pip install sphinxcontrib-inlinesyntaxhighlight sphinx-copybutton sphinx-markdown-builder sphinx-tabs pbr
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ sudo pip install --upgrade sphinx wget https://github.com/mans0954/odfbuilder/releases/download/0.0.1/sphinxcontrib-odfbuilder-0.0.1.tar.gz
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ sudo pip install sphinxcontrib-odfbuilder
Il existe de nombreuses extensions intégrés à Sphinx, je vous présente ici celles qui me paraissent les plus utiles :
sphinx.ext.intersphinx : générer des liens automatiques dans la documentation suivant des mots clés.
sphinx.ext.extlinks : Fournit des alias aux URL de base de votre documentation, de sorte que vous n’avez qu’à donner le nom d’alias pour la création du lien dans votre documentation.
sphinx.ext.autodoc : Insère automatiquement les docstrings des fonctions, des classes ou des modules Python dans votre documentation. Permet de construire directement de la documentation à partir de votre code Python.
sphinxcontrib.inlinesyntaxhighlight : Insère du code d’un langage de programmation dans une ligne de texte.
sphinxcontrib-bibtex : Insère des références bibliographiques.
sphinx.ext.todo : Insère des taches, ou liste de taches à faire dans votre documentation.
sphinx.ext.githubpages : Cette extension créée un fichier .nojekyll dans le répertoire HTML généré pour publier le document sur les pages GitHub.
sphinx.ext.imgmath : Insère des formules mathématiques dans votre documentation.
sphinx.ext.graphviz : Cette extension vous permet d’intégrer des graphiques Graphviz dans vos documents.
sphinxcontrib-svg2pdfconverter : Pour gérer les images SVG en LaTeX pour le PDF.
sphinx.ext.inheritance_diagram : Cette extension vous permet d’inclure des diagrammes d’héritage, rendus via l’extension Graphviz.
sphinx_copybutton : insère dans votre documentation une icône pour copier dans le presse-papiers le contenu de la directive.
hieroglyph : Permet de générer des slides de présentations.
sphinx.ext.ifconfig : Inclure le contenu de la directive uniquement si l’expression Python donnée en argument est
True.sphinx.ext.doctest : Cette extension vous permet de tester un code Python dans la documentation. Le constructeur doctest collectera le résultat et pourra agir suivant les retours d’exécutions obtenus.
sphinx_markdown_builder : Pour construire de la documentation au format markdown pour gitlab et créer les formats .odt ou .docx.
Ajout des extensions utiles pour Python et Sphinx#
# -- Configuration des extensions ---------------------------------------------
extensions = [
'sphinx.ext.intersphinx',
'sphinx.ext.extlinks',
'sphinx.ext.autodoc',
'sphinxcontrib.inlinesyntaxhighlight',
'sphinx.ext.githubpages',
'sphinx.ext.graphviz',
'sphinxcontrib.cairosvgconverter',
'sphinx.ext.inheritance_diagram',
'sphinx_copybutton',
'sphinx.ext.tabs',
'sphinx.ext.todo',
'sphinx.ext.ifconfig',
'sphinx.ext.doctest',
'sphinx_markdown_builder',
'sphinxcontrib-odfbuilder',
]
Configuration des extensions#
Intersphinx#
# -- Options pour intersphinx -------------------------------------------------
# Alias du lien de la documentation de Python 3
intersphinx_mapping = {'python': ('https://docs.python.org/fr/3/', None)}
# Utilisation restructuredtext:
# index de page WEB
# :ref:`python:reference-index`
# :ref:`Référence langage Python <python:reference-index>`
# lien WEB
# :doc:`python:library/enum`
# :doc:`Énumérations <python:library/enum>`
Extlinks#
# -- Options pour extlinks ----------------------------------------------------
# Liens vers la documentation de Python 3
extlinks = {
'docpython3': ('https://docs.python.org/fr/3/%s', 'Python'),
'manpython3': ('https://docs.python.org/fr/3/library/%s.html', 'Manuel Python de '),
}
# utilisation restructuredtext :docpython3:`tutorial` ou :manpython3:`enum`
Autodoc#
# -- Options pour autodoc -----------------------------------------------------
# Simule l'existence du module classes de python pour ne pas être bloqué
autodoc_mock_imports = ['classes']
Inline Syntax highlight#
# -- Options pour inline syntax highlight --------------------------------------
# Langage défini par la directive de surbrillance si aucun langage n'est défini par le rôle
inline_highlight_respect_highlight = False
# Langage défini par la directive de surbrillance si aucun rôle n'est défini
inline_highlight_literals = False
Graphviz#
# -- Options pour Graphviz ----------------------------------------------------
graphviz_output_format = 'svg'
# utilisation restructuredtext :
# .. graphviz::
#
# digraph frameworks web python {
# python [label="python", href="https://www.python.org/", target="_top"];
# flask [label="Flask", href="https://flask.palletsprojects.com/en/1.1.x/", target="_top"];
# django [label="Bjango", href="https://www.djangoproject.com/", target="_top"];
# bottle [label="Bottle", href="https://bottlepy.org/", target="_top"];
# turbogears [label="TurboGears", href="https://turbogears.org/", target="_top"];
# web2py [label="web2py", href="http://www.web2py.com/", target="_top"];
# cherrypy [label="CherryPy", href="https://cherrypy.org/", target="_top"];
# quixote [label="Quixote", href="http://quixote.ca/", target="_top"];
# python -> {flask; django; bottle; turbogears; web2py; cherrypy; quixote;};
# }
Tabs#
# -- Options pour tabs ----------------------------------------------------
# utilisation restructuredtext :
# .. tabs::
# .. tab:: Python
# Ma documentation sur Python
# .. tabs::
# .. code-tab:: py
# Fichier Python main.py
# .. code-tab:: java
# Fichier java
# .. tabs::
# .. code-tab:: py
# def main():
# return
# .. code-tab:: java
# class Main {
# public static void main(String[] args) {
# }
# }
# .. tab:: Frameworks Python
# .. tabs::
# .. group-tab:: Flask
# Ma documentation sur Flask
# .. group-tab:: Django
# Ma documentation sur Django
# .. tabs::
# .. group-tab:: Flask
# Le code d'exemple pour Flask
# .. group-tab:: Django
# Le code d'exemple pour Django*
Ifconfig#
# -- Options pour ifconfig ----------------------------------------------------
def setup(app):
app.add_config_value('niveau_developpement', 'Alpha', True)
# utilisation restructuredtext :
# .. ifconfig:: niveau_developpement not in ('Pre-alpha', 'Alpha', 'Beta', 'Release candidate', 'Stable release')
# En production
# .. ifconfig:: 'Alpha' == niveau_developpement
# En developpement
# .. ifconfig:: 'Beta' == niveau_developpement
# En test
# .. ifconfig:: 'Release candidate' == niveau_developpement
# En qualification
# .. ifconfig:: ''End of life'' == niveau_developpement
# Obsolète
Générer la documentation#
Attention des accents dans les noms de fichiers .rst font planter LaTeX.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ make html
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ make latex
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ make latexpdf
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ make epub
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ make text
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ make markdown
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ make xml
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ make man
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ make texinfo
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ make info
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ make odt
Générer les formats odt ou docx#
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ sudo apt install pandoc
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ cd documentation/html ; pandoc ./index.html -o ../../InitiationProgrammationPythonPourAdministrateurSystèmes.odt
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs/documentation/html$ pandoc ./index.html -o ../../InitiationProgrammationPythonPourAdministrateurSystèmes.docx
Générer l’internationalisation#
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ make gettext
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ sphinx-intl update -p documentation/gettext -l fr -l en
Traduire les fichiers dans ./locales/<lang>/LC_MESSAGES/
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ make -e SPHINXOPTS="-Dlanguage='en'" html
Rédiger la documentation#
Le fichier d’entrée de votre documentation index.rst (toctree) se trouve dans ~/repertoire_de_developpement/docs/sources-documents.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ sudo apt install retext
Éditer le fichier index.rst et le modifier ainsi :
.. Documentation sur l'initiation à la programmation Python pour l'administrateur systèmes. Document maître créé par sphinx-quickstart le Mercredi 24 Avril 2021 à 17h 27min 50s.
Vous pouvez adapter ce fichier complètement à votre goût.
Il contient la racine `toctree` de votre documentation.
.. toctree::
:caption: Contenu :
:maxdepth: 2
Initiation à la programmation Python pour l'administrateur systèmes
===================================================================
Index
=====
* :ref:`genindex`
Index des modules
=================
* :ref:`modindex`
.. * :ref:`search\`
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ make html

Parties, chapitres, sections, paragraphes#
Par convention pour Python :
«#» : Parties
«*» : Chapitres
«=» : Sections
«-» : Sous-sections
«^» : Sous-sous-section
«"» : Paragraphes
.. Documentation sur l'initiation à la programmation Python pour l'administrateur systèmes. Document maître créé par sphinx-quickstart le Mercredi 24 Avril 2021 à 17h 27min 50s.
Vous pouvez adapter ce fichier complètement à votre goût.
Il contient la racine `toctree` de votre documentation.
.. sectionauthor:: Prénom NOM <prenom.nom@fai.fr>
.. codeauthor:: Geek DEVELOPPEUR <geek.developpeur@fai.fr>
.. toctree::
:caption: Contenu :
:maxdepth: 5
Programmation Python 3
######################
Un texte d’introduction sur la partie Python 3.
Initiation à la programmation Python pour l'administrateur systèmes
*******************************************************************
Un texte d’introduction pour mon chapitre.
Section 1
=========
Un texte pour la section 1.
Sous-section 1
--------------
Du texte pour la sous-section 1
Du texte pour une sous-partie de la sous-section 1
Du texte pour une sous sous partie de la sous-section 1
Sous-section 2
--------------
Du texte pour la sous-section 2
Exemple de titrages
###################
Chapitre 1
**********
Section 1
=========
Sous-section 1
--------------
Sous-sous-section 1
^^^^^^^^^^^^^^^^^^^
Paragraphe 1
""""""""""""
Sous-paragraphe 1
+++++++++++++++++
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ make html
Mettre en forme du texte#
.. Documentation sur l'initiation à la programmation Python pour l'administrateur systèmes. Document maître créé par sphinx-quickstart le Mercredi 24 Avril 2021 à 17h 27min 50s.
Vous pouvez adapter ce fichier complètement à votre goût.
Il contient la racine `toctree` de votre documentation.
.. toctree::
:caption: Contenu :
:maxdepth: 2
Initiation à la programmation Python pour l'administrateur systèmes
###################################################################
**Tout en gras.**
Du texte \ **en gras**\ pour ma documentation.
*Tout en italique.*
Du texte \ *en italique*\ pour ma documentation.
.. only:: html
.. raw:: html
Une phrase avec un <font color="Red">mot</font> en rouge.
.. only:: latex
.. raw:: latex
Une phrase avec un \textcolor{red}{mot} en rouge.
.. only:: odt
Une phrase avec un mot non en rouge.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ make html
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ make latexpdf
Insertion de texte d’échappement#
.. Documentation sur l'initiation à la programmation Python pour l'administrateur systèmes. Document maître créé par sphinx-quickstart le Mercredi 24 Avril 2021 à 17h 27min 50s.
Vous pouvez adapter ce fichier complètement à votre goût.
Il contient la racine `toctree` de votre documentation.
.. toctree::
:caption: Contenu :
:maxdepth: 2
Initiation à la programmation Python pour l'administrateur systèmes
###################################################################
Le caractère \\
Du texte \
sur une seule ligne.
Du texte sans qu’il soit interprété ``\n, \r, \t, \\``.
``**Une phrase non en gras**``
``*Une phrase non en italique*``
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ make html

Les listes#
.. Documentation sur l'initiation à la programmation Python pour l'administrateur systèmes. Document maître créé par sphinx-quickstart le Mercredi 24 Avril 2021 à 17h 27min 50s.
Vous pouvez adapter ce fichier complètement à votre goût.
Il contient la racine `toctree` de votre documentation.
.. toctree::
:caption: Contenu :
:maxdepth: 2
Initiation à la programmation Python pour l'administrateur systèmes
###################################################################
Liste à puces
* élément 1
* élément 2
* élément 3
La liste numérotée
1. élément 1
2. élément 2
3. élément 3
La liste numérotée automatiquement
#. élément 1
#. élément 2
#. élément 3
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ make html

Les tableaux#
.. Documentation sur l'initiation à la programmation Python pour l'administrateur systèmes. Document maître créé par sphinx-quickstart le Mercredi 24 Avril 2021 à 17h 27min 50s.
Vous pouvez adapter ce fichier complètement à votre goût.
Il contient la racine `toctree` de votre documentation.
.. toctree::
:caption: Contenu :
:maxdepth: 2
Initiation à la programmation Python pour l'administrateur systèmes
###################################################################
+-----+-----------+
| A | B |
+=====+=====+=====+
| 1 | 2 | 3 |
+-----+-----+-----+
==== ==== ====
A B
--------- ----
A0 A1 B0
==== ==== ====
01 02 03
04 05 06
==== ==== ====
.. csv-table:: Personnel
:header: "Prénom", "Nom"
:widths: 40, 40
"Franc", "GEEK"
"Emmanuel", "DICTATOR"
.. list-table:: Lettres
:widths: 10 10 20
:header-rows: 1
:stub-columns: 1
* - Lettre
- A
- B
* - Nombre
- 25
- 5
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ make html
Insertion de blocs, code, image, graphviz, liens, mathématiques, notes, citations#
.. Documentation sur l'initiation à la programmation Python pour l'administrateur systèmes. Document maître créé par sphinx-quickstart le Mercredi 24 Avril 2021 à 17h 27min 50s.
Vous pouvez adapter ce fichier complètement à votre goût.
Il contient la racine `toctree` de votre documentation.
.. role:: python(code)
:language: python
.. toctree::
:caption: Contenu :
:maxdepth: 2
Initiation à la programmation Python pour l'administrateur systèmes
###################################################################
Pour afficher un texte en Python on utilise la fonction :python:`print("Mon texte")`.
.. literalinclude:: ../../1_Mode_interprété/mon_1er_programme.py
.. code-block:: python
print("Bonjour les zouzous")
.. image:: ../../../Images/tux.svg
:alt: Sphinx c’est cool
:align: center
:width: 120px
.. graphviz::
digraph "frameworks web python" {
python [label="Python", href="https://www.python.org/", target="_top"];
flask [label="Flask", href="https://flask.palletsprojects.com/en/1.1.x/", target="_top"];
django [label="Django", href="https://www.djangoproject.com/", target="_top"];
bottle [label="Bottle", href="https://bottlepy.org/", target="_top"];
turbogears [label="TurboGears", href="https://turbogears.org/", target="_top"];
web2py [label="web2py", href="http://www.web2py.com/", target="_top"];
cherrypy [label="CherryPy", href="https://cherrypy.org/", target="_top"];
quixote [label="Quixote", href="http://quixote.ca/", target="_top"];
python -> {flask; django; bottle; turbogears; web2py; cherrypy; quixote;};
}
`Python <https://www.python.org>`_
- :ref:`python:reference-index`
- :ref:`Référence langage Python <python:reference-index>`
- :doc:`python:library/enum`
- :doc:`Énumérasions <python:library/enum>`
- :docpython3:`tutorial`
- :manpython3:`enum`
:download: `Téléchargement <http://gitlab.domaine-perso.fr/utilisateur/initiation_developpement_python_pour_administrateur/-/raw/master/README.md?inline=false>`_
.. math::
:nowrap:
\begin{gather*}
(a + b)² = a² + 2ab + b² \\
\sqrt{\frac{n}{n-\sqrt[3]{2}} S} \\
\int_a^b x \, \mathrm dx = [x^2]_a^b = [(b)^2 – (a)²] = b² – a² \\
\mathrm{2~H_{2(g)}+O_{2(g)}=2~H_2O_{(1)}}
\end{gather*}
L'équation d'Euler :eq:`euler` est utile en mathématiques.
Référence à la citation du formateur [citation]_.
Première note [#n1]_, deuxième note [#n2]_
Et encore une troisième note [#n3]_
.. [citation] «Python que oui, ou Python que non…».
.. math:: e^{i\pi} + 1 = 0
:label: euler
.. rubric:: Notes de bas de page
.. [#n1] Note 1
.. [#n2] Note 2
.. [#n3] Note 3
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ make html
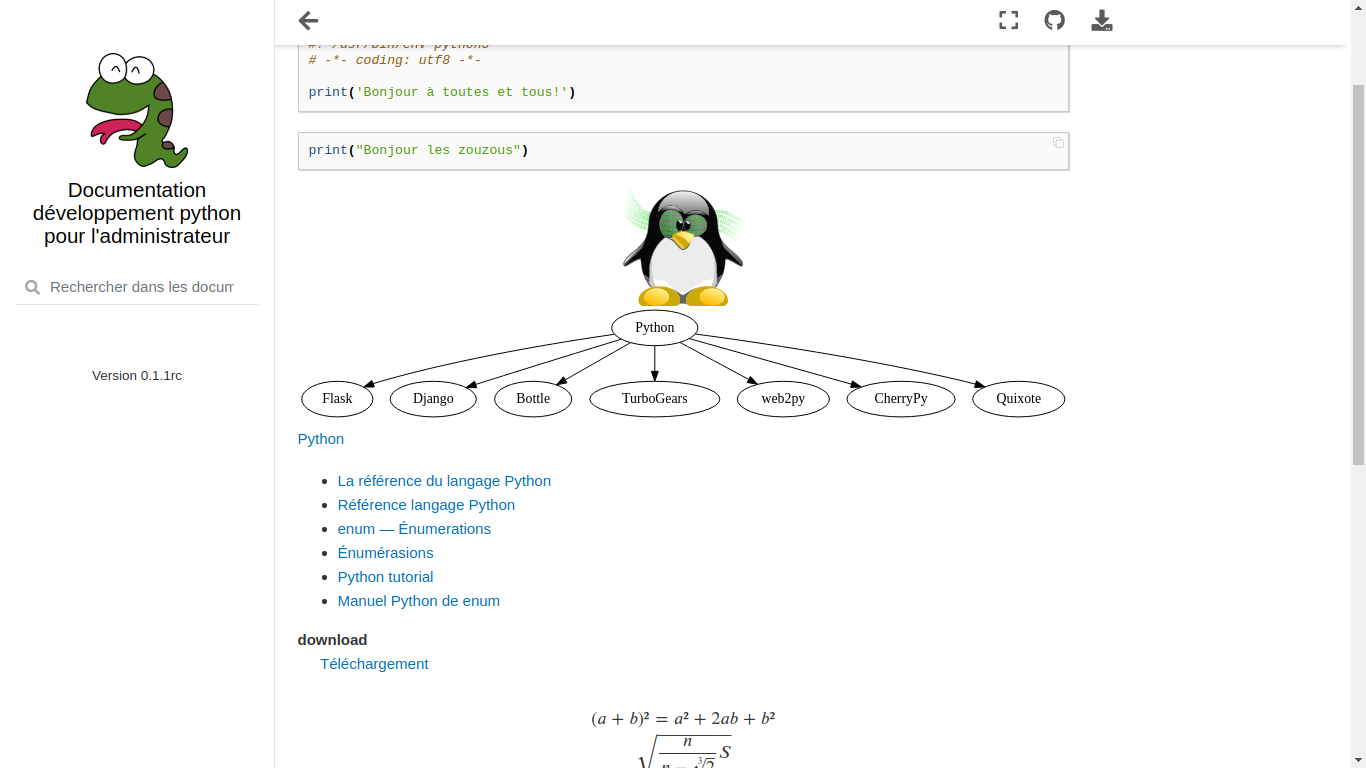
Boites et conditions d’affichages#
Il faut d’abord modifier l’extension «sphinx.ext.todo» au fichier conf.py.
[extensions]
todo_include_todos = True
Puis modifier index.rst comme suit :
.. Documentation sur l'initiation à la programmation Python pour l'administrateur systèmes. Document maître créé par sphinx-quickstart le Mercredi 24 Avril 2021 à 17h 27min 50s.
Vous pouvez adapter ce fichier complètement à votre goût.
Il contient la racine `toctree` de votre documentation.
.. toctree::
:maxdepth: 2
:caption: Contenu :
Initiation à la programmation Python pour l'administrateur systèmes
###################################################################
.. ifconfig:: niveau_developpement == 'alpha'
.. only :: format_html and not builder_epub
.. raw:: html
<font color="Red">Liste des TODOs à faire</font>
.. only :: latex
.. raw:: latex
\textcolor{red}{Liste des TODOs à faire}
.. todolist::
.. ifconfig:: niveau_developpement not in ( 'pre-alpha', 'alpha', 'beta', 'rc')
En production
.. ifconfig:: niveau_developpement == 'pre-alpha'
En faisabilité
.. ifconfig:: niveau_developpement == 'alpha'
En développement
.. ifconfig:: niveau_developpement == 'beta'
En test
.. ifconfig:: niveau_developpement == 'rc'
En qualification
Les boîtes :
.. ifconfig:: niveau_developpement == 'alpha'
.. todo:: Compléter la boîte voir aussi
.. seealso:: Ceci est une boîte
.. ifconfig:: niveau_developpement == 'alpha'
.. todo:: Compléter la boîte note
.. note:: Ceci est une boîte
.. sidebar:: Ceci est une boîte
Contenu de la barre de côté
.. warning:: Ceci est une boîte
.. important:: Ceci est une boîte
.. ifconfig:: niveau_developpement == 'alpha'
.. todo:: Compléter la boîte Remarque
.. topic:: **Remarque**
Ceci est le contenu du sujet
.. only:: format_html and not builder_epub
Les onglets à n'utiliser que pour une documentation purement html
.. tabs::
.. tab:: Code
Ma documentation sur le code
.. tabs::
.. code-tab:: py
python AfficheArguments.py Bonjour à tous
.. code-tab:: java
java AfficheArguments Bonjour à tous
.. tabs::
.. code-tab:: py
import sys
for arg in sys.argv:
print(arg)
.. code-tab:: java
public class AfficheArguments {
public static void main(String[] args) {
int i;
for (String s : args) System.out.println(s);
}
}
.. tab:: Group
Ma documentation sur le code
.. tabs::
.. group-tab:: Python
Exécuter le programme :
.. code-block:: shell
python AfficheArguments.py Bonjour à tous
.. group-tab:: Java
Exécuter le programme :
.. code-block:: shell
java AfficheArguments Bonjour à tous
.. tabs::
.. group-tab:: Python
Le code Python :
.. code-block:: python
import sys
for arg in sys.argv:
print(arg)
.. group-tab:: Java
Le code java :
.. code-block:: java
public class AfficheArguments {
public static void main(String[] args) {
int i;
for (String s : args) System.out.println(s);
}
}
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ make html
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ make epub
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ make latexpdf
Documenter le code Python#
Modifier le fichier «index.rst» :
.. Documentation sur l'initiation à la programmation Python pour l'administrateur systèmes. Document maître créé par sphinx-quickstart le Mercredi 24 Avril 2021 à 17h 27min 50s.
Vous pouvez adapter ce fichier complètement à votre goût.
Il contient la racine `toctree` de votre documentation.
.. toctree::
:maxdepth: 2
:caption: Contenu :
Initiation à la programmation Python pour l'administrateur systèmes
###################################################################
Approche manuelle :
.. py:module:: module
:platform: Linux
:synopsis: Un court résumé du périmètre d’utilisation du module
.. py:function:: fonction(paramètres)
.. py:class:: Classe(paramètres)
.. py:method:: méthode(paramètres)
.. py:attribute:: attribut
.. py:decorator:: décorateur(paramètres)
.. py:exception:: exception
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ make html
Pour l’approche automatique, dont nous verrons l’utilisation un peu plus loin, il faut utiliser :
.. Documentation sur l'initiation à la programmation Python pour l'administrateur systèmes. Document maître créé par sphinx-quickstart le Mercredi 24 Avril 2021 à 17h 27min 50s.
Vous pouvez adapter ce fichier complètement à votre goût.
Il contient la racine `toctree` de votre documentation.
.. toctree::
:maxdepth: 2
:caption: Contenu :
Initiation à la programmation Python pour l'administrateur systèmes
###################################################################
Approche automatique :
.. automodule:: Documentation.mon_module
:members:
Rôle des membres de automodule dans nos fichiers «.rst» :
:members: affiche les éléments publics (qui ne débute pas par «_»).
:special-members: Affiche aussi les constructeurs des éléments publics.
:undoc-members: Affiche aussi les éléments sans docstring.
:private-members: Affiche aussi les éléments privés (qui commencent par «_»).
:inherited-members: Affiche les éléments non hérités.
:show-inheritance: Affiche les classes mères dont hérite les classes Python.
Ces définitions vont se trouver dans la structure de la documentation «.rst».
Pour l’écriture de la documentation directement dans notre code il faudra renseigner nos docstring. Sphinx ajoute de nombreuses nouvelles directives et rôles de texte interprétés au balisage reST standard.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ cd .. ; mkdir Documentation ; cd Documentation ; touch mon_module.py
Balise de méta-information#
Balisages spécifiques au module#
Lorque vous commencez l’écriture d’un module Python (fichier «mon_module.py»), la première des informations à fournir aux autres développeurs est sur le module lui même. Le balisage décrit dans cette section est utilisé pour fournir ces informations sur le module pour la documentation. Chaque module doit être documenté dans son propre fichier. Normalement, ce balisage apparaît après le titre du module dans le fichier ; un fichier typique peut commencer comme ceci :
# -*- coding: utf-8 -*-
"""
.. sectionauthor:: Stagiaire ADMINISTRATEUR <stagiaire.administrateur@fai.fr>
:mod:`mon_module` -- Module d'exemple
#####################################
.. module:: mon_paquet.mon_module
:synopsis:: Ce module illustre comment écrire une docstring de module avec Python
:platform: Linux
"""
Note
Il est important de donner un titre de module puisque cela sera inséré dans l’arborescence de la table des matières pour la documentation.
module#
La directive .. module:: nom_du_module marque le début de la description d’un module, d’un package ou d’un sous-module. Le nom doit être entièrement qualifié (c’est-à-dire incluant le nom du package pour les sous-modules). Il est paramétrable avec :
L’option
:synopsis: Résumé rapidequi doit consister en une phrase décrivant l’objectif du module. Elle n’est actuellement utilisée que dans l’index global des modules.L’option
:platform: Unix, Mac, Windows, si elle est présente, qui indique les plateformes compatibles avec le code Python. C’est une liste séparée par des virgules des plates-formes. Si le code est disponible pour toutes les plates-formes, l’option doit être omise. Les clés sont des identifiants courts ; les exemples utilisés incluent «Linux», «Unix», «Mac» et «Windows». Il est important d’utiliser une clé qui a déjà été utilisée le cas échéant.L’option
:deprecated:(sans valeur) peut être donnée pour marquer un module comme obsolète ; il sera alors désigné comme tel à divers endroits.
Pour le code, nos fonctions et nos classes#
«:var/ivar/cvar nom_variable: description» : Pour nos variables.
«:param/parameter/arg/argument/key/keywords nom_paramètre: description» : Pour décrire un paramètre d’une fonction ou d’un objet.
«:type element: type» : Pour décrite le type d’une variable ou d’un paramètre (Callable, int, float, long, str, tuple, list, dict, None, True, False, boolean).
«:returns/return: description» : Décrit ce qui est retourné par une fonction ou un objet.
«:rtype: type» : Pour décrite le type de ce qui est retourné par une fonction ou un objet (Callable, int, float, long, str, tuple, list, dict, None, True, False, boolean).
«:raises/raise/except/exception nom_exception: description» : Décrit une exception dans votre code.
Tout ceci nous permet d’écrire un code de documentation minimal final (avec des variables Python et Sphinx utiles) :
# -*- coding: utf-8 -*-
"""
.. sectionauthor:: Stagiaire ADMINISTRATEUR <stagiaire.administrateur@fai.fr>
:mod:`mon_module` -- Module d'exemple
#####################################
.. module:: mon_module
:platform: Unix, Windows
:synopsis: Ce module illustre comment écrire votre docstring dans Python.
.. moduleauthor:: Formateur PYTHON <formateur.python@fai.fr>
.. moduleauthor:: Stagiaire ADMINISTRATEUR <stagiaire.administrateur@fai.fr>
"""
__title__ = "Module illustration écriture docstring Python"
__author__ = "Formateur PYTHON"
__version__ = '0.7.3'
__release_life_cycle__ = 'alpha'
# pre-alpha = faisabilité, alpha = développement, beta = test, rc = qualification, prod = production
__docformat__ = 'reStructuredText'
Fichier mon_module.py avec une classe Python d’exemple :
# -*- coding: utf-8 -*-
"""
.. sectionauthor:: Stagiaire ADMINISTRATEUR <stagiaire.administrateur@fai.fr>
:mod:`mon_module` -- Module d'exemple
#####################################
.. module:: mon_module
:platform: Unix, Windows
:synopsis: Ce module illustre comment écrire votre docstring dans Python.
.. moduleauthor:: Formateur PYTHON <formateur.python@fai.fr>
.. moduleauthor:: Stagiaire ADMINISTRATEUR <stagiaire.administrateur@fai.fr>
"""
__title__ = "Module illustration écriture docstring Python"
__author__ = "Formateur PYTHON"
__version__ = '0.7.3'
__release_life_cycle__ = 'alpha'
# pre-alpha = faisabilité, alpha = développement, beta = test, rc = qualification, prod = production
__docformat__ = 'reStructuredText'
class ClasseExemple():
"""Cette classe docstring montre comment utiliser sphinx et la syntaxe rst.
La première ligne est une brève explication de la classe avec ses paramètres et ce que renvoi
l’objet.
Cela doit être complété par une description plus précise des méthodes et des attributs dans
le code de la classe dans le code.
La seule méthode ici est :func:`mafonction`.
- **paramètres**, **types**, **retour** et **type de retours**::
:param arg1: description
:param arg2: description
:type arg1: type arg1
:type arg2: type arg2
:return: description du retour
:rtype: type du retour
- Documentez des sections **:Exemples:** en utilisant la syntaxe des doubles points ``:``
.. code-block:: rest
:Exemple:
suivi d'une ligne vierge!
qui apparaît comme suit :
:Exemple:
suivi d'une ligne vierge!
- Des sections spéciales telles que **Voir aussi**, **Avertissements**, **Notes** avec la
syntaxe sphinx (*directives de paragraphe*)::
.. seealso:: blabla
.. warnings:: blabla
.. note:: blabla
.. todo:: blabla
.. warning::
Il existe de nombreux autres champs Info mais ils peuvent être redondants:
* param, parameter, arg, argument, key, keyword: Description d'un paramètre.
* type: Type de paramètre.
* raises, raise, except, exception: Quand une exception spécifique est levée.
* var, ivar, cvar: Description d'une variable.
* returns, return: Description de la valeur de retour.
* rtype: Type de retour.
.. note::
Il existe de nombreuses autres directives telles que :
versionadded, versionchanged, rubric, centered, …
Voir la documentation sphinx pour plus de détails.
Voici ci-dessous les résultats pour :func:`mafonction` docstring.
"""
def maméthode(self, arg1, arg2, arg3):
"""Retourne (arg1 / arg2) + arg3
Ceci est une explication plus précise, qui peut inclure des mathématiques avec la syntaxe
latex :math:`\\alpha`.
Ensuite, vous devez fournir une sous-section facultative (juste pour être cohérent et avoir
une documentation uniforme. Rien ne vous empêche de changer l'ordre):
- paramètres utilisés ``:param <nom>: <description>``
- type des paramètres ``:type <nom>: <description>``
- retours de la méthode ``:returns: <description>``
- exemples (doctest)
- utilisation de voir aussi ``.. seealso:: texte``
- utilisation des notes ``.. note:: texte``
- utilisation des alertes ``.. warning:: texte``
- liste des restes à faire ``.. todo:: texte``
**Avantages**:
- Utilise les balises sphinx.
- Belle sortie HTML avec les directives Seealso, Note, Warning.
**Désavantages**:
- En regardant simplement la docstring, les sections de paramètres, de types et de retours
n'apparaissent pas bien dans le code.
:param arg1: la première valeur
:param arg2: la première valeur
:param arg3: la première valeur
:type arg1: int, float,...
:type arg2: int, float,...
:type arg3: int, float,...
:returns: arg1/arg2 +arg3
:rtype: int, float
:Example:
.. code-block:: pycon
>>> import template
>>> a = template.ClasseExemple()
>>> a.mafonction(1,1,1)
2
.. note:: il peut être utile de souligner une caractéristique importante
.. seealso:: :class:`AutreClasseExemple`
.. warning:: arg2 doit être différent de zéro.
.. todo:: vérifier que arg2 est non nul.
"""
return arg1 / arg2 + arg3
Générer la documentation pour voir le rendu :
utilisateur@MachineUbuntu:~/repertoire_de_developpement/Documentation$ cd ../docs
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ make html
utilisateur@MachineUbuntu:~/repertoire_de_developpement/docs$ cd ..
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git add .
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git status
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git commit -m "Configuration de la documentation du projet"
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git push
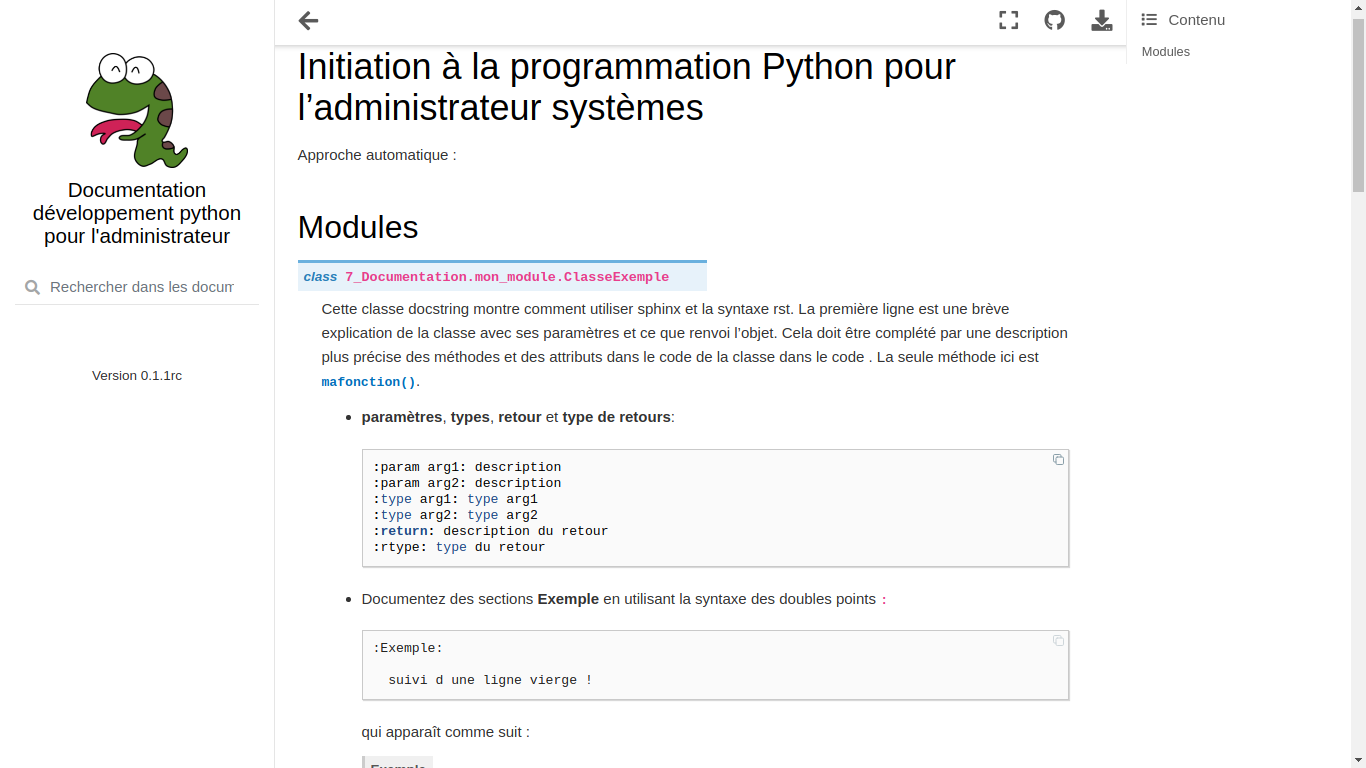
Mise en œuvre de la documentation avec Gitlab#
Définition de la structure du document#
Supposons que vous ayez exécuté sphinx-quickstart. Il a créé un répertoire source avec conf.py et un document maître, index.rst.
La fonction principale du document maître (ou toctree) est de servir de page d’accueil et de contenir la racine de «l’arborescence de la documentation du projet». C’est l’une des principales choses que Sphinx ajoute à reStructuredText, un moyen de connecter plusieurs fichiers à une seule hiérarchie de documents.
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ makedir docs/sources-documents/classes docs/sources-documents/cours
Modifiez index.rst :
.. |date| date::
:Date: |date|
:Revision: 1.0
:Author: Prénom NOM <prénom.nom@fai.fr>
:Description: Documentation sur l'initiation à la programmation Python pour l'administrateur systèmes
:Info: Voir <http://gitlab.domaine-perso.fr/utilisateur/initiation_developpement_python_pour_administrateur> pour la mise à jour de ce cours.
.. toctree::
:maxdepth: 2
:caption: Contenu
.. include:: cours/InitiationProgrammationPythonPourAdministrateurSystemes.rst
Modules
*******
.. automodule:: Documentation.mon_module
:members:
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ touch docs/sources-documents/cours/InitiationProgrammationPythonPourAdministrateurSystemes.rst
Modifiez InitiationProgrammationPythonPourAdministrateurSystemes.rst :
.. Cours Initiation à la programmation Python pour l'administrateur systèmes.
Initiation à la programmation Python pour l'administrateur systèmes
###################################################################
Générer la documentation avec un script#
Créer un fichier makedocs pour générer la documentation, et makediagrammes pour générer ultérieurement les diagrammes de Classes Python.
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ touch makedocs makediagrammes
Modifier makedocs avec le contenu ci-dessous :
#!/bin/bash
titre=$(tput bold ; tput setaf 1 ; tput setab 53)
section=$(tput bold ; tput setaf 3 ; tput setab 240)
soussection=$(tput bold ; tput setaf 4 ; tput setab 0)
ordinaire=$(tput sgr0)
echo -e "$titre""Création de la documentation du projet""$ordinaire"
echo -e "$section""Création des diagrammes de classes""$ordinaire"
( exec "./makediagrammes" )
cd docs
echo -e "$section""Création des fichiers de documentations""$ordinaire"
echo -e "$soussection""Format html""$ordinaire"
make html
echo -e "$soussection""Format LaTeX""$ordinaire"
make latex >/dev/null
echo -e "$soussection""Format epub""$ordinaire"
make epub
echo -e "$soussection""Format pdf""$ordinaire"
make latexpdf >/dev/null
echo -e "$soussection""Format texte""$ordinaire"
make text
echo -e "$soussection""Format xml""$ordinaire"
make xml
echo -e "$soussection""Format markdown""$ordinaire"
make markdown
echo -e "$soussection""Création des pages de manuel""$ordinaire"
make man
echo -e "$soussection""Création des pages texinfo""$ordinaire"
make texinfo
echo -e "$soussection""Création des pages info""$ordinaire"
make info
echo -e "$soussection""Format ODT""$ordinaire"
make odt
pandoc ./documentation/html/index.html -o InitiationProgrammationPythonPourAdministrateurSystèmes.odt
echo -e "$soussection""Format DOCX""$ordinaire"
pandoc ./documentation/html/index.html -o InitiationProgrammationPythonPourAdministrateurSystèmes.docx
echo -e "$section""Création du README.md du projet""$ordinaire"
cp ./documentation/markdown/index.md ../README.md
echo -e "$section""Changement du chemin des images dans README.md""$ordinaire"
cd..
sed -i 's/classes\//docs\/sources-documents\/classes\//g'\ README.md
sed -i 's/images\//docs\/sources-documents\/images\//g'\ README.md
Modifier makediagrammes avec le contenu ci-dessous :
#!/bin/bash
Rendre exécutable.
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ chmod u+x makedocs makediagrammes
Créez les documents de la documentation :
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ ./makedocs
Sauvegarder les documents dans le dépôt git et dans Gitlab :
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git add .
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git status
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git commit -m "Génération par un script de la documentation du projet"
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git push
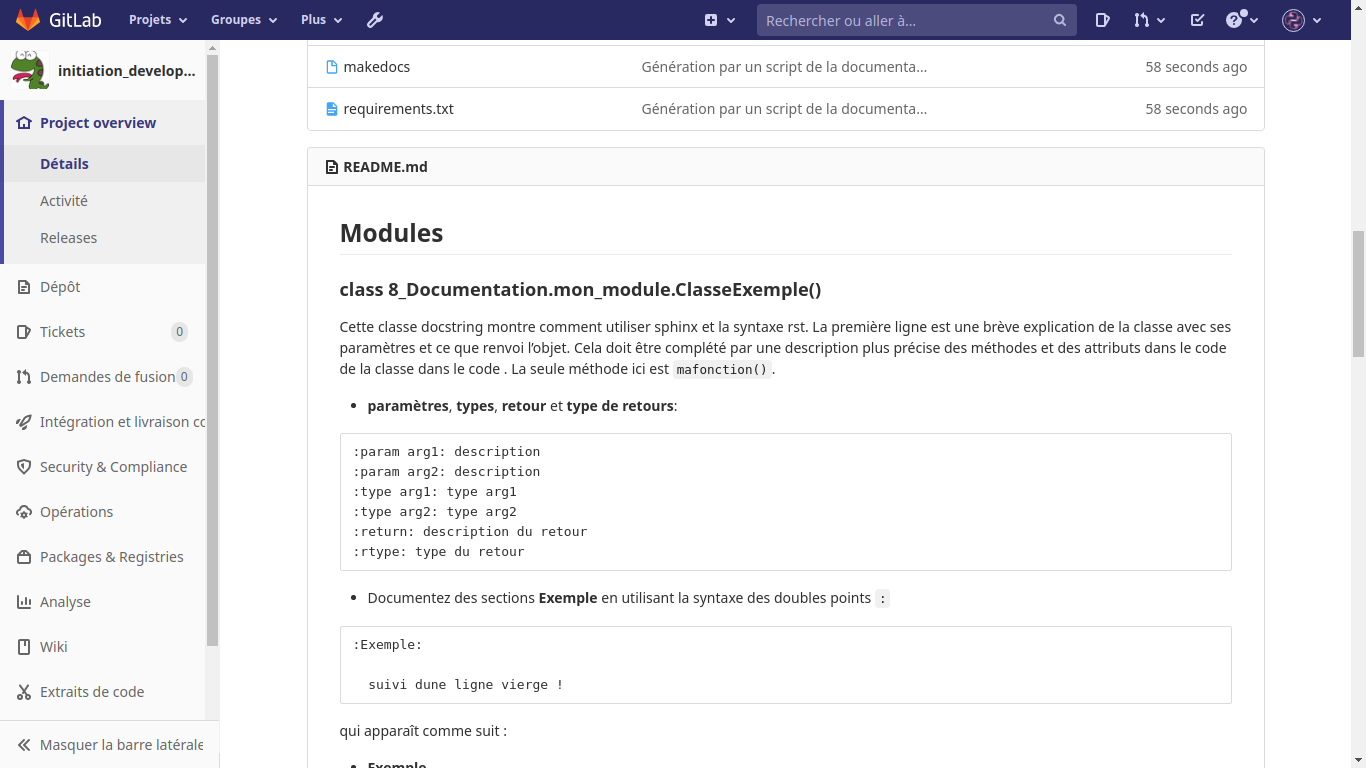
Générer la documentation avec Gitlab#
Créer un fichier vide requirements.txt pour préparer à l’installation des modules Python et packages.txt pour installer les applications utiles dans l’environnement de test Python. Créer aussi des fichiers vides docs-requirements.txt et docs-packages.txt pour la construction de la documentation.
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ touch requirements.txt packages.txt docs-requirements.txt docs-packages.txt
Génération de la documentation dans Gitlab#
Modifier .gitlab-ci.yml :
Remarque : il faut impérativement saisir «pages» comme section
image: python:latest
stages:
- deploy
pages:
stage: deploy
script:
- echo "$GITLAB_USER_LOGIN déploiement de la documentation"
- echo "** Mises à jour et installation des applications supplémentaires **"
- echo "Mises à jour système"
- apt -y update
- apt -y upgrade
- echo "Installation des applications supplémentaires"
- cat docs-packages.txt | xargs apt -y install
- echo "Mise à jour de PIP"
- pip install --upgrade pip
- echo "Installation des dépendances de modules python"
- pip install -U -r docs-requirements.txt
- echo "** Génération des diagrammes de classes **"
- ./makediagrammes
- echo "** Génération de la documentation HTML **"
- sphinx-build -b html ./docs/sources-document public
artifacts:
paths:
- public
only:
- master
Modifier docs-packages.txt:
dnsutils
sphinx-intl
graphviz
cairosvg
Modifier docs-requirements.txt:
sphinx
sphinx-intl
sphinxcontrib-inlinesyntaxhighlight
sphinx-copybutton
sphinx-tabs
sphinx-markdown-builder
sphinx-book-theme
sphinxcontrib-svg2pdfconverter
sphinxcontrib-svg2pdfconverter[CairoSVG]
pygments-ldif
Modifier conf.py pour supprimer les extensions de sortie inutiles:
extensions = [
'sphinx.ext.intersphinx',
'sphinx.ext.extlinks',
'sphinx.ext.autodoc',
'sphinx.ext.githubpages',
'sphinx.ext.graphviz',
'sphinxcontrib.cairosvgconverter',
'sphinx.ext.inheritance_diagram',
'sphinx_copybutton',
'sphinx.ext.tabs',
'sphinx.ext.todo',
'sphinx.ext.ifconfig',
'sphinx.ext.doctest',
'sphinx_markdown_builder',
'sphinxcontrib-odfbuilder',
]
Modifiez cours/InitiationProgrammationPythonPourAdministrateurSystemes.rst :
.. Cours Initiation à la programmation Python pour l'administrateur systèmes.
`Initiation à la programmation Python pour l'administrateur systèmes <http://utilisateur.documentation.domaine-perso.fr/initiation_developpement_python_pour_administrateur/>`_
###############################################################################################################################################################################

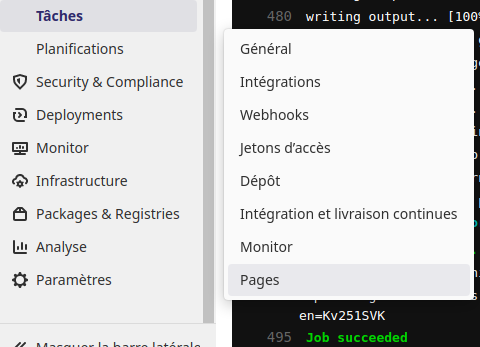
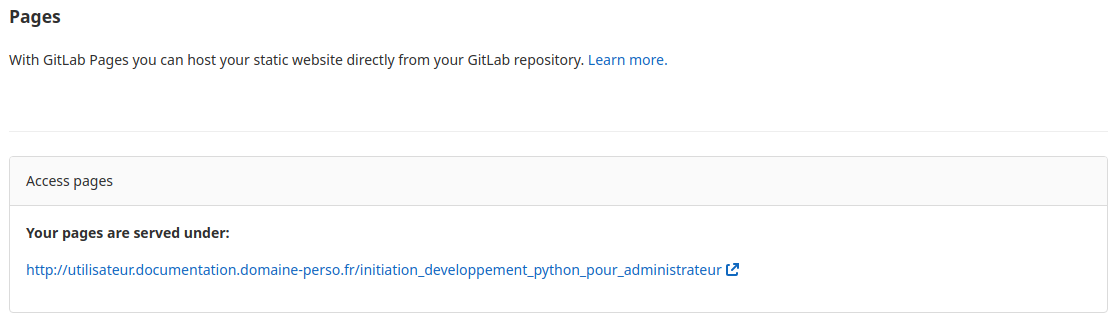
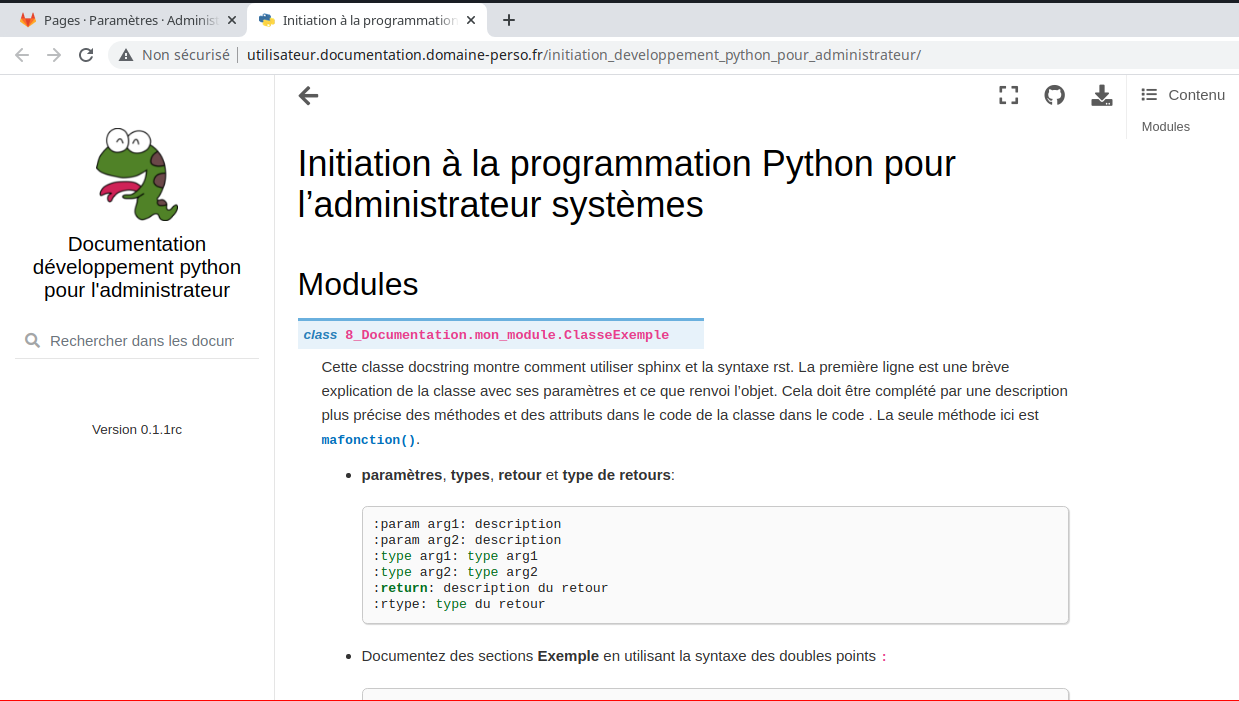
La qualité du code#
Vous avez écrit votre code de votre projet, mais avez vous :
utilisé des modules odsolètes ?
respecté les standards d’écriture Python définis dans les spécifications de la PEP 8 ?
Pour cela, en plus de la commande python3 -Wd pour vérifier l’obsolescence du code, nous avons plusieurs outils Pylint, pyflakes, pychecker, pep8 ou flake8, qui permettent de vérifier la conformité de votre code avec la PEP 8.
Dans ce cours nous allons utiliser Pylint.
Voyons comment fonctionne cet outil ?
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo apt install pylint
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ pylint 1_Mode_interprété/mon_1er_programme.py
************ Module mon_1er_programme
1_Mode_interprété/mon_1er_programme.py:1:0: C0114: Missing module docstring (missing-module-docstring)
-----------------------------------
Your code has been rated at 0.00/10
Comment éviter un message d’erreur de documentation lorsque l’on ne veut pas de documentation dans son code ?
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ pylint --disable=missing-module-docstring
1_Mode_interprété/mon_1er_programme.py
---------------------
Your code has been rated at 10.00/10 (previous run: 0.00/10, +10.00)
Comment éviter des fichiers, ou répertoires, que l’on ne veut pas tester avec pylint ?
Nous allons d’abord tester dans un terminal la bonne remontée des fichiers à tester pour pylint avec un script shell.
Créer un fichier choix-fichiers-a-tester.
#! /usr/bin/env bash
find -type f -name "*.py" ! -path "*1_Mode_interprété*" ! -path "*2_Debug*" ! -path "*3_Interpreteur_alerts*" ! -path "*4_Passage_paramètres*" ! -path "*5_Niveau_journalisation*" ! -path "*6_Chaines_split_join*" ! -path "*7_Modules*" ! -path "*/.env/*" ! -path "*docs*"
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ chmod u+x choix-fichiers-a-tester ; ./choix-fichiers-a-tester
./Documentation/mon_module.py
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ pylint $(find -type f -name "*.py" ! -path "*1_Mode_interprété*" ! -path "*2_Debug*" ! -path "*3_Interpreteur_alerts*" ! -path "*4_Passage_paramètres*" ! -path "*5_Niveau_journalisation*" ! -path "*6_Chaines_split_join*" ! -path "*7_Modules*" ! -path "*/.env/*" ! -path "*docs*")
************ Module mon_module
Documentation/mon_module.py:72:59: C0303: Trailing whitespace (trailing-whitespace)
Documentation/mon_module.py:127:31: C0303: Trailing whitespace (trailing-whitespace)
Documentation/mon_module.py:19:0: R0205: Class 'ClasseExemple' inherits from object, can be safely removed from bases in python3 (useless-object-inheritance)
Documentation/mon_module.py:79:4: R0201: Method could be a function (no-self-use)
Documentation/mon_module.py:19:0: R0903: Too few public methods (1/2) (too-few-public-methods)
------------------------------------------------------------------
Your code has been rated at 5.00/10
Nous allons maintenant voir comment mettre ces tests d’obsolescence et de qualité du code dans GitLab.
Test de l’environnement Python dans Gitlab#
Ici nous allons tester le déploiement de l’environnement Python 3 pour notre code, avec le déploiement d’une page de documentation.
Modifier .gitlab-ci.yml :
image: python:latest
stages:
- build
- deploy
construction-environnement:
stage: build
script:
- echo "Bonjour $GITLAB_USER_LOGIN !"
- echo "** Mises à jour et installation des applications supplémentaires **"
- echo "Mises à jour système"
- apt -y update
- apt -y upgrade
- echo "Installation des applications supplémentaires"
- cat packages.txt | xargs apt -y install
- echo "Mise à jour de PIP"
- pip install --upgrade pip
- echo "Installation des dépendances de modules python"
- pip install -U -r requirements.txt
only:
- master
pages:
stage: deploy
script:
- echo "$GITLAB_USER_LOGIN déploiement de la documentation"
- echo "** Mises à jour et installation des applications supplémentaires **"
- echo "Mises à jour système"
- apt -y update
- apt -y upgrade
- echo "Installation des applications supplémentaires"
- cat docs-packages.txt | xargs apt -y install
- echo "Mise à jour de PIP"
- pip install --upgrade pip
- echo "Installation des dépendances de modules python"
- pip install -U -r docs-requirements.txt
- echo "** Génération des diagrammes de classes **"
- ./makediagrammes
- echo "** Génération de la documentation HTML **"
- sphinx-build -b html ./docs/sources-document public
artifacts:
paths:
- public
only:
- master
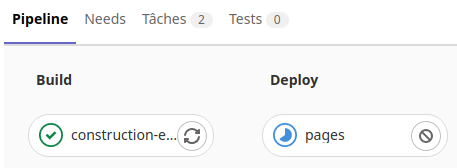
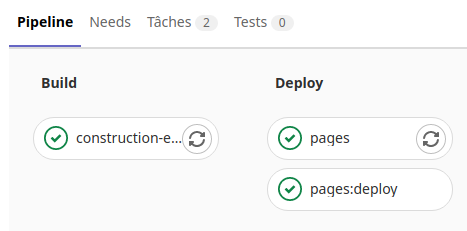
Test de l’obsolescence du code Python dans Gitlab#
Ici nous allons utiliser la commande python3 -Wd pour générer une image d’obsolescence du code. Nous allons le tester avec le fichier «3_Interpreteur_alerts/monscript.py».
Modifier le fichier .gitlab-ci.yml. Voici à quoi ressemble le fichier .gitlab-ci.yml pour ce projet :
image: python:latest
stages:
- build
- Static Analysis
- deploy
construction-environnement:
stage: build
script:
- echo "Bonjour $GITLAB_USER_LOGIN !"
- echo "** Mises à jour et installation des applications supplémentaires **"
- echo "Mises à jour système"
- apt -y update
- apt -y upgrade
- echo "Installation des applications supplémentaires"
- cat packages.txt | xargs apt -y install
- echo "Mise à jour de PIP"
- pip install --upgrade pip
- echo "Installation des dépendances de modules python"
- pip install -U -r requirements.txt
only:
- master
obsolescence-code:
stage: Static Analysis
allow_failure: true
script:
- echo "$GITLAB_USER_LOGIN test de l'obsolescence du code"
- python3 -Wd Documentation/mon_module.py &2> /tmp/output.txt
- sed -n '/DeprecationWarning:/p' /tmp/output.txt > /tmp/obsolescence.txt
- \[ -s /tmp/obsolescence.txt \] && cat /tmp/obsolescence.txt || echo "Pas d'obsolescences"
pages:
stage: deploy
before_script:
- echo "** Mises à jour et installation des applications supplémentaires **"
- echo "Mises à jour système"
- apt -y update
- apt -y upgrade
- echo "Installation des applications supplémentaires"
- cat docs-packages.txt | xargs apt -y install
- echo "Mise à jour de PIP"
- pip install --upgrade pip
- echo "Installation des dépendances de modules python"
- pip install -U -r docs-requirements.txt
- echo "Création de l’infrastructure pour l'obsolescence du code"
- mkdir -p public/obsolescence public/badges
- echo undefined > public/obsolescence/obsolescence.score
script:
- echo "** $GITLAB_USER_LOGIN déploiement de la documentation **"
- python3 -Wd Documentation/mon_module.py &2> /tmp/output.txt
- sed -n '/DeprecationWarning:/p' /tmp/output.txt > /tmp/obsolescence.txt
- \[ -s /tmp/obsolescence.txt \] && cat /tmp/obsolescence.txt || echo "Pas d'obsolescences"
- \[ -s /tmp/obsolescence.txt \] && echo oui > public/obsolescence/obsolescence.score || echo non > public/obsolescence/obsolescence.score
- echo "Obsolescence $(cat public/obsolescence/obsolescence.score)"
- echo "Génération des diagrammes de classes"
- ./makediagrammes
- echo "Création du logo SVG d'obsolescence de code"
- anybadge --overwrite --label "Obsolescence du code" --value=$(cat public/obsolescence/obsolescence.score) --file=public/badges/obsolescence.svg oui=red non=green
- echo "Génération de la documentation HTML"
- sphinx-build -b html ./docs/sources-document public
artifacts:
paths:
- public
only:
- master
Modifier le fichier repertoire_de_developpement/docs-requirements.txt.
Et ajouter à la fin du fichier :
anybadge
Modifier le fichier repertoire_de_developpement/docs/sources-documents/index.rst.
.. |date| date::
:Date: |date|
:Revision: 1.0
:Author: Prénom NOM <prénom.nom@fai.fr>
:Description: Documentation sur l'initiation à la programmation Python pour l'administrateur systèmes
:Info: Voir <http://gitlab.domaine-perso.fr/utilisateur/initiation_developpement_python_pour_administrateur> pour la mise à jour de ce cours.
.. toctree::
:maxdepth: 2
:caption: Contenu
.. include:: cours/InitiationProgrammationPythonPourAdministrateurSystemes.rst
.. only:: html
.. image:: ./badges/obsolescence.svg
:alt: Obsolescence du code Python
:align: left
:width: 200px
Modules
*******
.. automodule:: Documentation.mon_module
:members:
Déployez les fichiers dans gitlab.
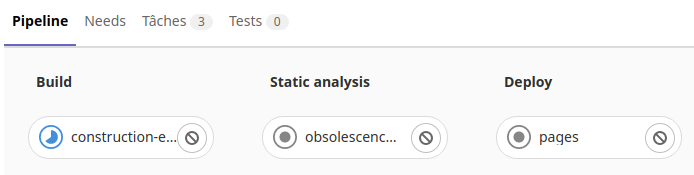
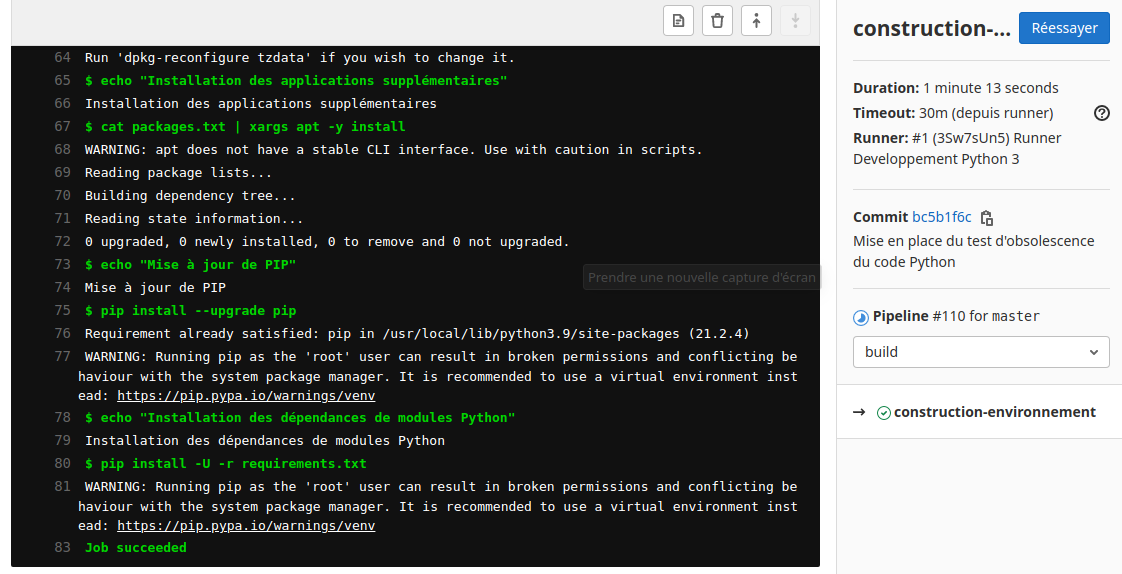
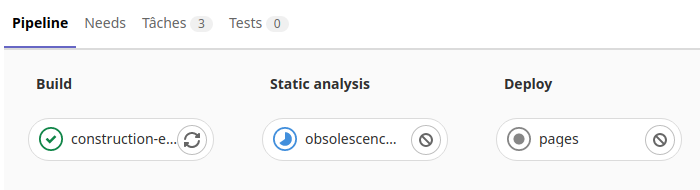
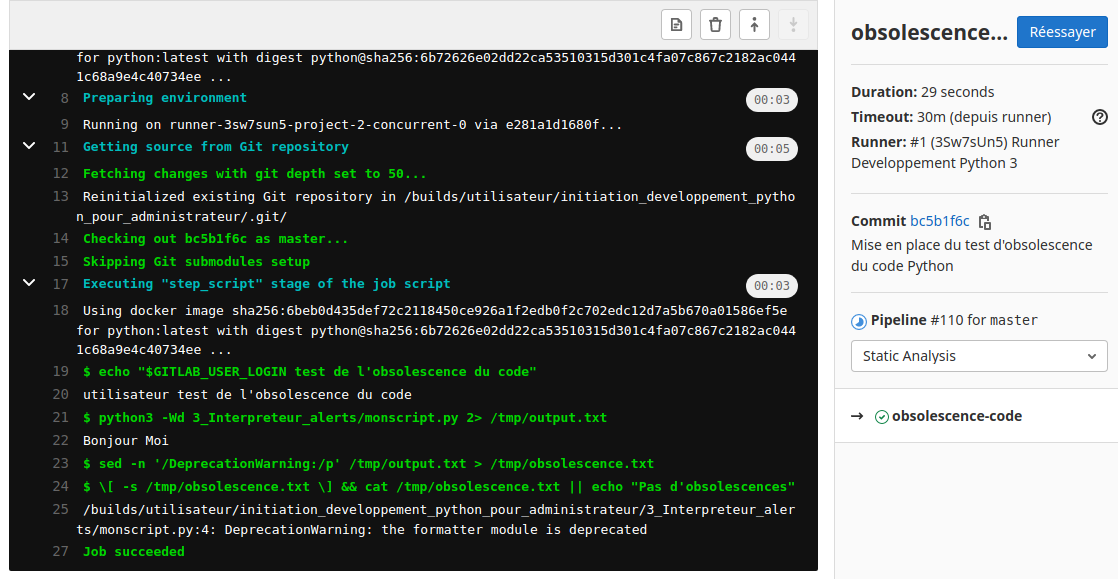
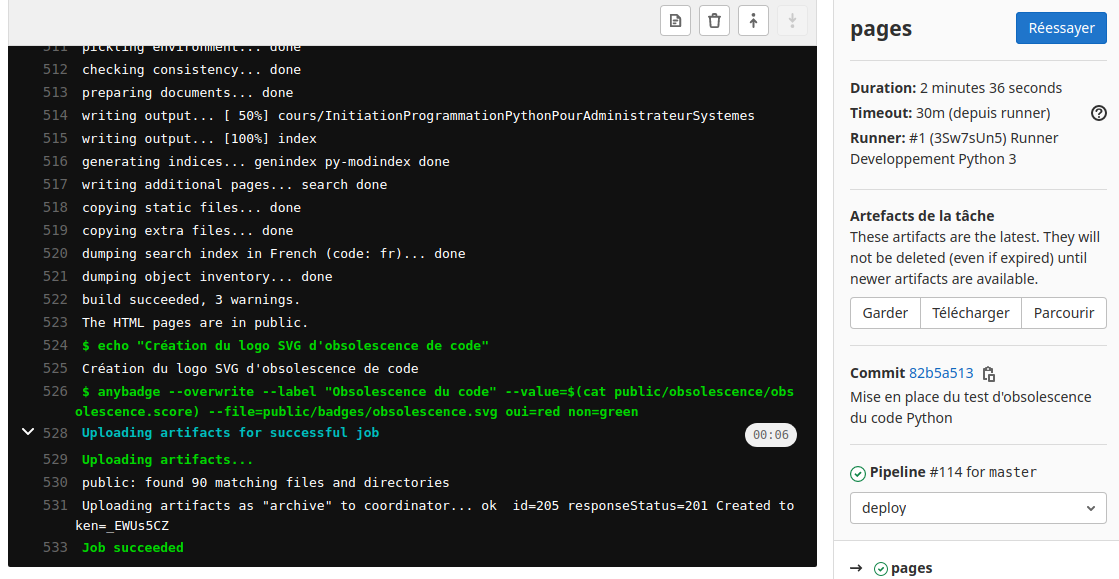
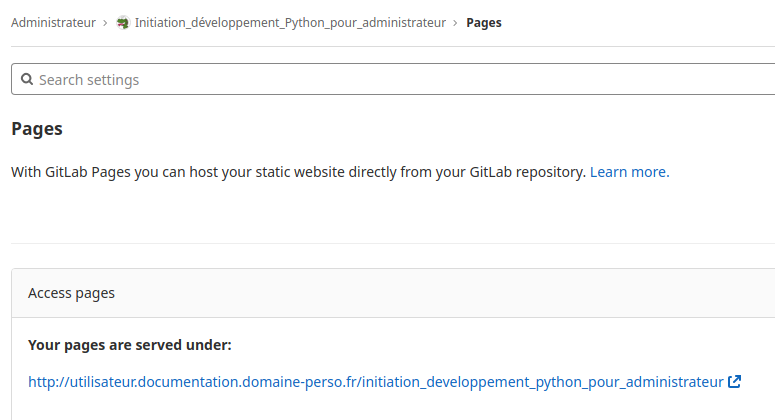
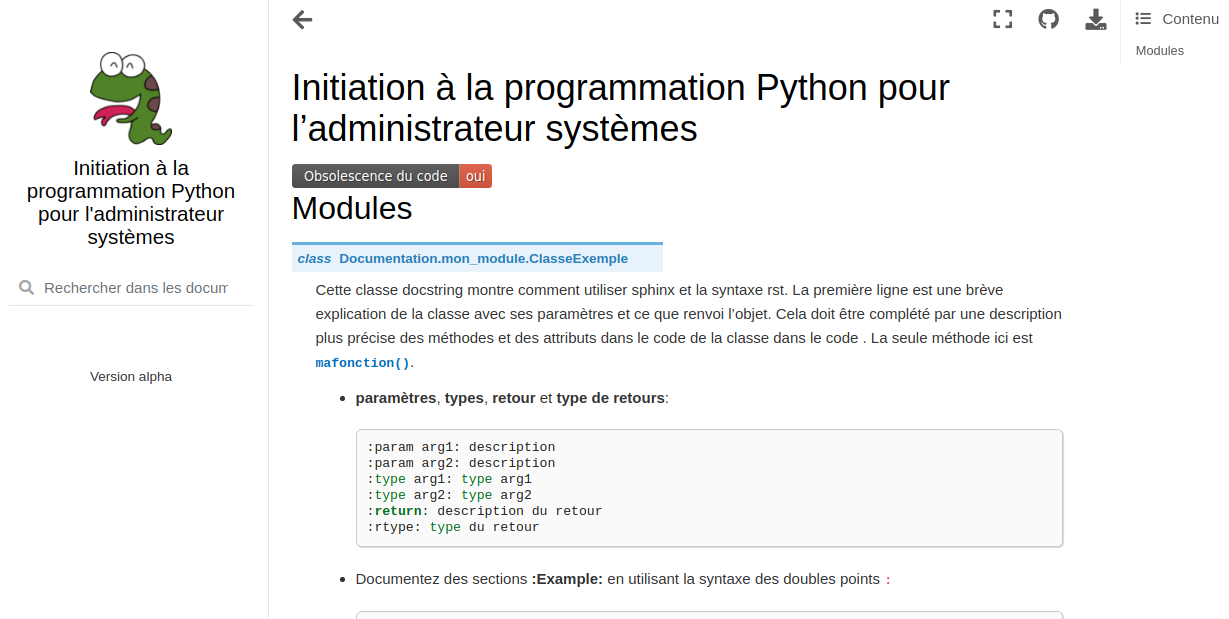
Test de qualité du code dans Gitlab#
Ici nous allons tester avec pylint la conformance du code de votre projet avec le standard PEP 8.
Voici à quoi ressemble le fichier .gitlab-ci.yml pour ce projet :
image: python:latest
stages:
- build
- Static Analysis
- deploy
construction-environnement:
stage: build
script:
- echo "Bonjour $GITLAB_USER_LOGIN !"
- echo "** Mises à jour et installation des applications supplémentaires **"
- echo "Mises à jour système"
- apt -y update
- apt -y upgrade
- echo "Installation des applications supplémentaires"
- cat packages.txt | xargs apt -y install
- echo "Mise à jour de PIP"
- pip install --upgrade pip
- echo "Installation des dépendances de modules python"
- pip install -U -r requirements.txt
only:
- master
obsolescence-code:
stage: Static Analysis
allow_failure: true
script:
- echo "$GITLAB_USER_LOGIN test de l'obsolescence du code"
- python3 -Wd Documentation/mon_module.py &2> /tmp/output.txt
- sed -n '/DeprecationWarning:/p' /tmp/output.txt > /tmp/obsolescence.txt
- \[ -s /tmp/obsolescence.txt \] && cat /tmp/obsolescence.txt || echo "Pas d'obsolescences"
qualité-du-code:
stage: Static Analysis
allow_failure: true
before_script:
- echo "Installation de Pylint"
- pip install -U pylint-gitlab
script:
- echo "$GITLAB_USER_LOGIN test de la qualité du code"
- pylint --output-format=text $(bash choix-fichiers-a-tester) | tee /tmp/pylint.txt
after_script:
- sed -n 's/^Your code has been rated at \([-0-9.]*\)\/.*/\1/p' /tmp/pylint.txt > pylint.score
- echo "Votre score de qualité de code Pylint est de $(cat pylint.score)"
pages:
stage: deploy
before_script:
- echo "** Mises à jour et installation des applications supplémentaires **"
- echo "Mises à jour système"
- apt -y update
- apt -y upgrade
- echo "Installation des applications supplémentaires"
- cat docs-packages.txt | xargs apt -y install
- echo "Mise à jour de PIP"
- pip install --upgrade pip
- echo "Installation des dépendances de modules python"
- pip install -U -r docs-requirements.txt
- echo "Création de l’infrastructure pour l'obsolescence et la qualité de code"
- mkdir -p public/obsolescence public/quality public/badges public/pylint
- echo undefined > public/obsolescence/obsolescence.score
- echo undefined > public/quality/pylint.score
- pip install -U pylint-gitlab
script:
- echo "** $GITLAB_USER_LOGIN déploiement de la documentation **"
- python3 -Wd Documentation/mon_module.py &2> /tmp/output.txt
- sed -n '/DeprecationWarning:/p' /tmp/output.txt > /tmp/obsolescence.txt
- \[ -s /tmp/obsolescence.txt \] && cat /tmp/obsolescence.txt || echo "Pas d'obsolescences"
- \[ -s /tmp/obsolescence.txt \] && echo oui > public/obsolescence/obsolescence.score || echo non > public/obsolescence/obsolescence.score
- echo "Obsolescence $(cat public/obsolescence/obsolescence.score)"
- pylint --exit-zero --output-format=text $(bash choix-fichiers-a-tester) | tee /tmp/pylint.txt
- sed -n 's/^Your code has been rated at \([-0-9.]*\)\/.*/\1/p' /tmp/pylint.txt > public/quality/pylint.score
- echo "Votre score de qualité de code Pylint est de $(cat public/quality/pylint.score)"
- echo "Création du rapport HTML de qualité de code"
- pylint --exit-zero --output-format=pylint_gitlab.GitlabPagesHtmlReporter $(bash choix-fichiers-a-tester) > public/pylint/index.html
- echo "Génération des diagrammes de classes"
- ./makediagrammes
- echo "Création du logo SVG d'obsolescence de code"
- anybadge --overwrite --label "Obsolescence du code" --value=$(cat public/obsolescence/obsolescence.score) --file=public/badges/obsolescence.svg oui=red non=green
- echo "Création du logo SVG de qualité de code"
- anybadge --overwrite --label "Qualité du code avec Pylint" --value=$(cat public/quality/pylint.score) --file=public/badges/pylint.svg 4=red 6=orange 8=yellow 10=green
- echo "Génération de la documentation HTML"
- sphinx-build -b html ./docs/sources-document public
artifacts:
paths:
- public
only:
- master
Modifier le fichier repertoire_de_developpement/docs/sources-documents/index.rst.
.. |date| date::
:Date: |date|
:Revision: 1.0
:Author: Prénom NOM <prénom.nom@fai.fr>
:Description: Documentation sur l'initiation à la programmation Python pour l'administrateur systèmes
:Info: Voir <http://gitlab.domaine-perso.fr/utilisateur/initiation_developpement_python_pour_administrateur> pour la mise à jour de ce cours.
.. toctree::
:maxdepth: 2
:caption: Contenu
.. include:: cours/InitiationProgrammationPythonPourAdministrateurSystemes.rst
.. only:: html
.. image:: ./badges/obsolescence.svg
:alt: Obsolescence du code Python
:align: left
:width: 200px
.. image:: ./badges/pylint.svg
:alt: Cliquez pour voir le rapport
:align: left
:width: 200px
:target: ./pylint/index.html
----
Modules
*******
.. automodule:: Documentation.mon_module
:members:
Déployez les fichiers dans gitlab.
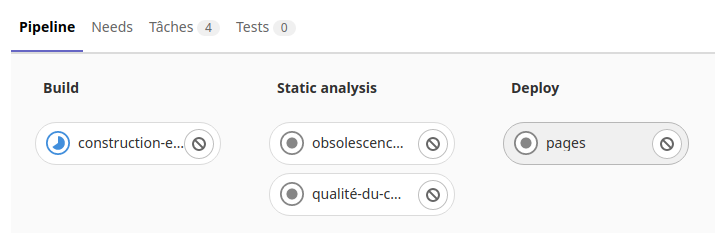
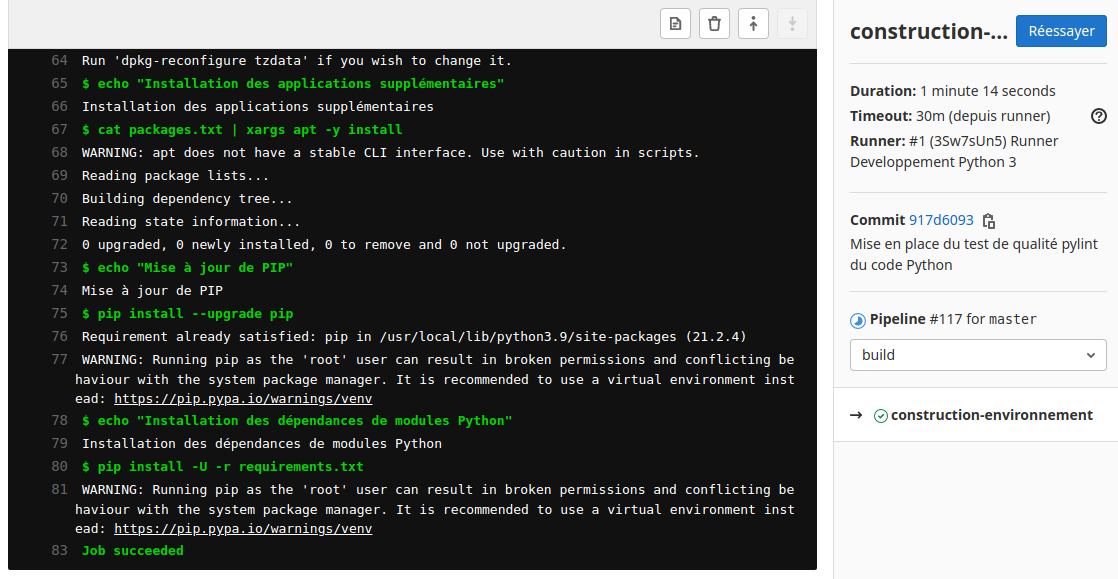
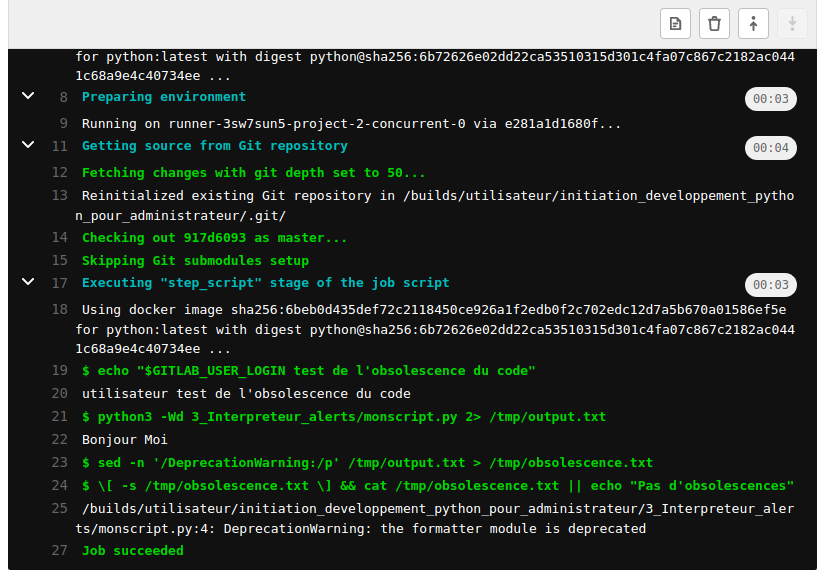
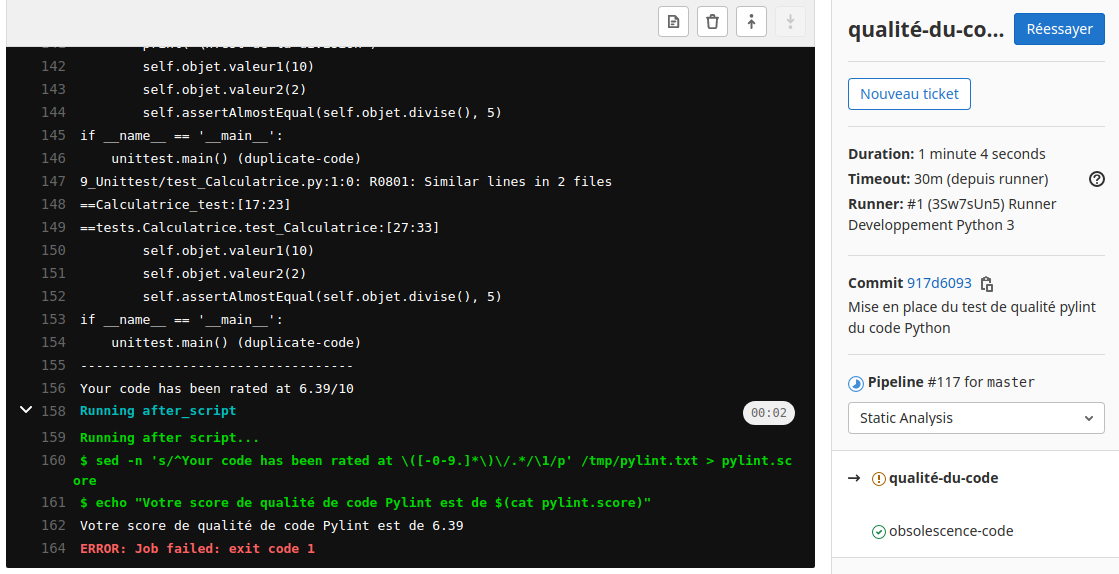
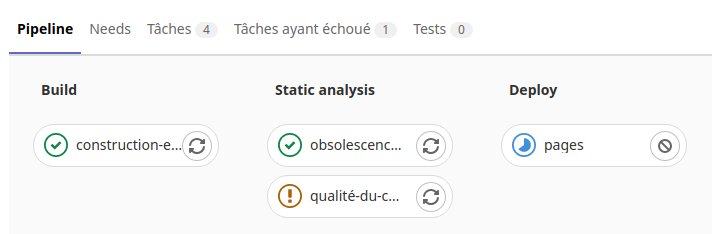
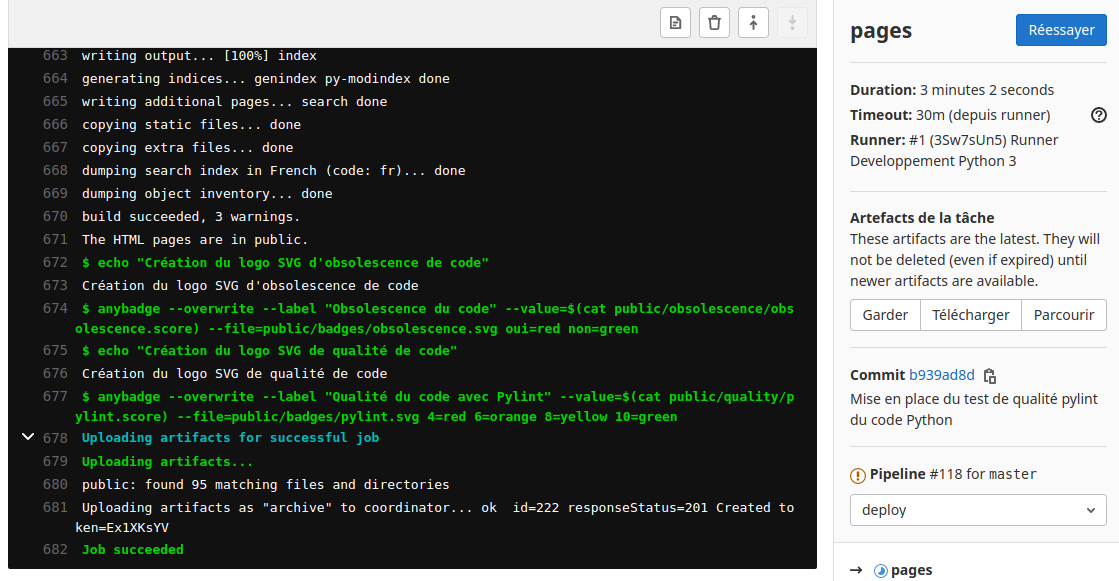
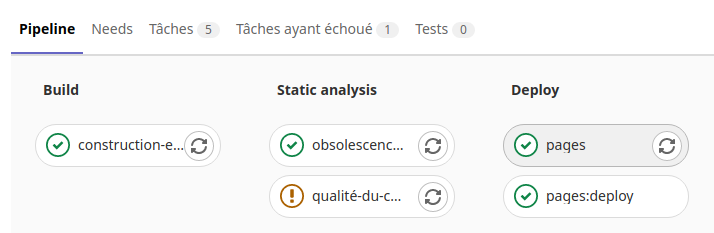
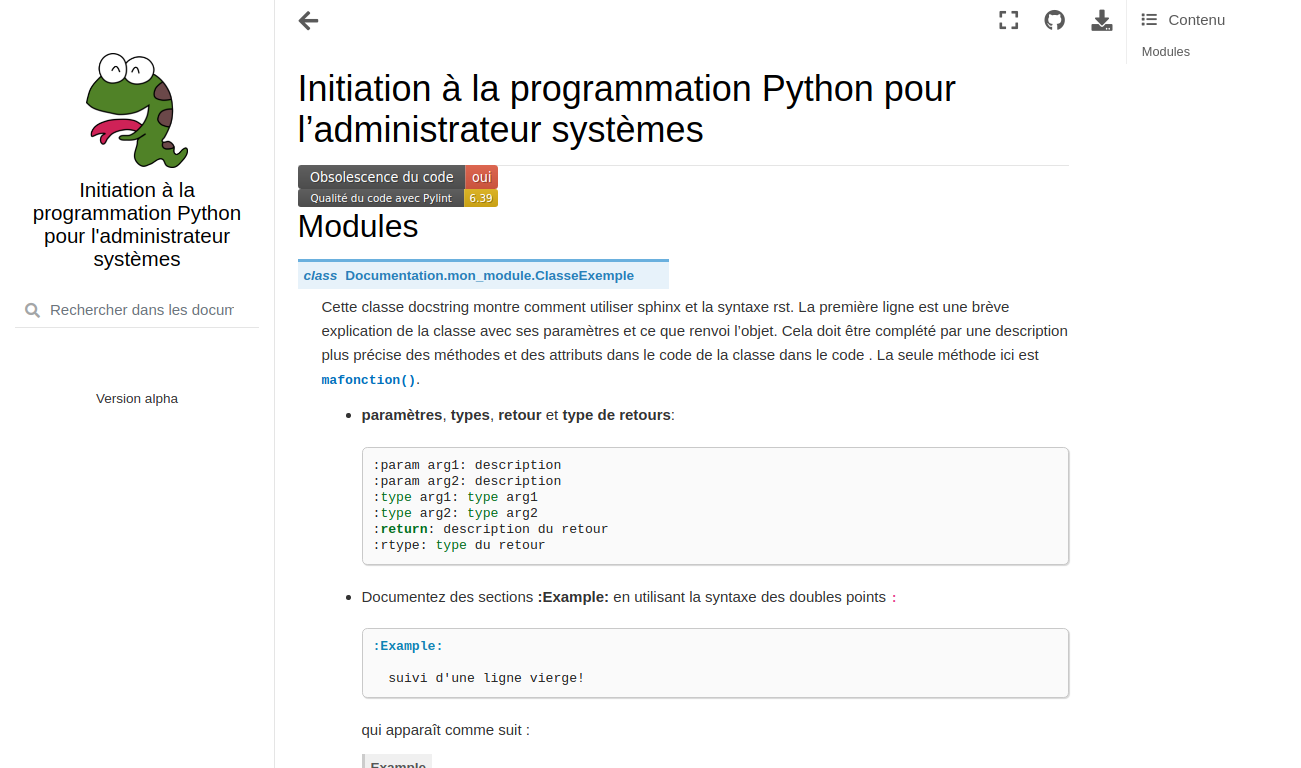
Tests unitaire Python#
Après avoir testé la qualité de rédaction du code Python suivant les standards, nous allons maintenant tester le comportement du programme tel qu’attendu par le programmeur.
Le module Unittest#
Les tests unitaires permettent de vérifier le comportement logiciel des éléments spécifiques d’un programme.
Par exemple ils permettent de vérifier le fonctionnement de méthodes, d’objets, de fonctions. La mise en place des tests unitaires est aussi utile pour s’assurer que la correction de dysfonctionnements logiciels n’entraînera pas de régressions dans la code ailleurs.
Unittest est disponible nativement dans Python, et il est basé sur le modèle de framework Xunit imaginé par Kent Beck et Erich Gamma.
Créer le répertoire «repertoire_de_developpement/Unittest».
Puis dans ce répertoire créer le fichier «Calculatrice.py» :
class Calculatrice:
""" Fait des opérations entre deux valeurs """
def __init__(self):
""" Initialisation de la classe """
self.efface()
def valeur1(self, première_valeur):
""" Affecte la première valeur """
self.__a = première_valeur
def valeur2(self, deuxième_valeur):
""" Affecte la deuxième valeur """
self.__b = deuxième_valeur
def efface(self):
"""\ Efface les valeurs\ """
self.__a = None
self.__b = None
def ajoute(self):
"""\ Ajoute les valeurs\ """
return self.__a + self.__b
def divise(self):
"""\ Divise les valeurs\ """
return self.__a / self.__b
if __name__ == '__main__':
calcule = Calculatrice()
calcule.valeur1(4)
calcule.valeur2(2)
print("Valeur des opérandes : 4 et 2")
print("Addition : ", calcule.ajoute())
print('Division : ', calcule.divise())
utilisateur@MachineUbuntu:~/repertoire_de_developpement/Unittest$ python3 Calculatrice.py
Valeur des opérandes : 4 et 2
Addition : 6
Division : 2.0
Exemple de test unitaires :
Créer le fichier Calculatrice_test.py :
# -*- coding: utf-8 -*-
import unittest
from Calculatrice import Calculatrice
class Calculatricetest(unittest.TestCase):
""" Tests de la classe Calculatrice """
def test_simple_ajoute(self):
""" Tests sur la somme """
print("\n Début du test de la somme")
self.objet = Calculatrice()
self.objet.valeur1(2)
self.objet.valeur2(3)
self.assertAlmostEqual(self.objet.ajoute(), 5)
def test_simple_divise(self):
""" Tests sur la division """
print("\n Début du test de la division")
self.objet = Calculatrice()
self.objet.valeur1(10)
self.objet.valeur2(2)
self.assertAlmostEqual(self.objet.divise(), 5)
if __name__ == '__main__':
unittest.main()
utilisateur@MachineUbuntu:~/repertoire_de_developpement//Unittest$ python3 Calculatrice_test.py
Début du test de la somme
.
Début du test de la division
.
----------------------------------------------------------------------
Ran 2 tests in 0.000s
OK
Les valeurs de retour des tests#
Il y a trois valeurs de retour pour un test :
OK : le test s’est déroulé correctement.
F : (Fail) le test a échoué.
E : (Error) une erreur est présente dans le code.
Tests réussits#
utilisateur@MachineUbuntu:~/repertoire_de_developpement/Unittest$ python3 Calculatrice_test.py
Début du test de la somme
.
Début du test de la division
.
----------------------------------------------------------------------
Ran 2 tests in 0.000s
OK
Modification engendrant un échec#
Modifiez dans Calculatrice.py
def ajoute(self):
""" Ajoute les valeurs """
return self.__a + self.__b + 1
utilisateur@MachineUbuntu:~/repertoire_de_developpement/Unittest$ python3 Calculatrice_test.py
Début du test de la somme
F
Début du test de la division
.
======================================================================
FAIL: test_simple_ajoute (__main__.Calculatricetest)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/home/utilisateur/Calculatrice_test.py", line 7, in test_simple_ajoute
self.assertAlmostEqual(self.objet.ajoute(), 5)
AssertionError: 6 != 5 within 7 places (1 difference)
----------------------------------------------------------------------
Ran 2 tests in 0.000s
FAILED (failures=1)
Modification engendrant une erreur#
Modifiez dans Calculatrice_test.py
class Calculatricetest(unittest.TestCase):
""" Tests de la classe Calculatrice """
def test_simple_ajoute(self):
""" Tests sur la somme """
self.objet = Calculatrice(2, 3)
self.objet.valeur1(2)
self.objet.valeur2(3)
self.assertAlmostEqual(self.objet.ajoute(), 5)
utilisateur@MachineUbuntu:~/repertoire_de_developpement/Unittest$ python3 Calculatrice_test.py
Début du test de la somme
E
Début du test de la division
.
======================================================================
ERROR: test_simple_ajoute (__main__.Calculatricetest)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/home/utilisateur/Calculatrice_test.py", line 8, in test_simple_ajoute
self.objet = Calculatrice(2, 3)
TypeError: \__init__() takes 1 positional argument but 3 were given
----------------------------------------------------------------------
Ran 2 tests in 0.000s
FAILED (errors=1)
Exécution de l’ensemble de tests#
Pour les programmes de nos projets nous pouvons avoir un nombre conséquent de fichiers de tests. On va donc tenter d’appeler ces tests à la façon d’un batch. C’est à dire de les exécuter automatiquement lorsqu’ils sont découverts (Test Discovery) dans le répertoire courant du projet ou dans ses sous-répertoires.
Testons avec le code actuel ce mode :
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ python3 -m unittest
----------------------------------------------------------------------
Ran 0 tests in 0.000s
OK
Cela ne fonctionne pas !
Pour que ce mode fonctionne il faut impérativement nommer les fichiers de test en commençant par le mot «test».
Il faut donc renommer notre fichier Calculatrice_test.py en test_Calculatrice.py.
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ python3 -m unittest
Début du test de la somme
.
Début du test de la division
.
----------------------------------------------------------------------
Ran 2 tests in 0.000s
OK
Présentation et architecture des tests#
Pour un gros projet, ou pour une instance possédant les mêmes valeurs, il peut-être intéressant de factoriser le code de tests des méthodes. Les tests peuvent être nombreux, et la mise en place du code des méthodes peut être répétitif dans la classe de tests.
Heureusement, nous pouvons le prendre en compte dans le code de configuration en implémentant une méthode appelée setUp(). Le framework de test l’appellera automatiquement pour chaque méthode de tests que nous exécutons. Si la méthode setUp() lève une exception pendant l’exécution d’une méthode de tests de la classe, le framework considérera l’exécution de la méthode comme ayant subi une erreur. La méthode de tests ne sera alors pas exécutée.
De même, nous pouvons fournir une méthode tearDown() qui s’exécutera à la fin de la méthode de test appelée :
Résumé des méthodes :
La méthode
setUp(). Elle est appelée pour réaliser la mise en place du test des méthodes. Elle est exécutée immédiatement avant l’appel d’une méthode de la classe de tests.La méthode
tearDown(). Elle est appelée immédiatement après l’appel d’une méthode de test et de l’enregistrement de son résultat. Elle est appelée même si la méthode de test a levé une exception. De fait, l’implémentation d’un sous-classes doit être fait avec précaution si vous vérifiez l’état interne de la classe. Cette méthode est appelée uniquement si l’exécution desetUp()est réussie quel que soit le résultat de la méthode de test. L’implémentation par défaut ne fait rien.
Factorisons l’initialisation de l’objet Calculatrice dans nos méthodes de tests.
Modifier le fichier «test_Calculatrice.py» :
# -*- coding: utf-8 -*-*
import unittest
from Calculatrice import Calculatrice
class Calculatricetest(unittest.TestCase):
""" Tests de la classe Calculatrice """
def setUp (self):
""" Traitements de début d’exécution """
print('\nClasse Calculatrice')
self.objet = Calculatrice()
def tearDown(self):
""" Traitements de fin d’exécution """
self.objet.efface()
print('\nFin du test')
def test_simple_ajoute(self):
""" Tests sur la somme """
print('\nTest de la somme')
self.objet.valeur1(2)
self.objet.valeur2(3)
self.assertAlmostEqual(self.objet.ajoute(), 5)
def test_simple_divise(self):
""" Tests sur la division """
print('\nTest de la division')
self.objet.valeur1(10)
self.objet.valeur2(2)
self.assertAlmostEqual(self.objet.divise(), 5)
if __name__ == '__main__':
unittest.main()
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ python3 -m unittest
Classe Calculatrice
Test de la somme
Fin du test
.
Classe Calculatrice
Test de la division
Fin du test
.
----------------------------------------------------------------------
Ran 2 tests in 0.000s
OK
Il est plus maintenable de séparer les tests du code source, pour cela nous pouvons placer les fichiers de tests dans un répertoire tests.
Pour que celui-ci soit accessible pour la découverte des tests, n’oubliez pas d’y ajouter un fichier vide __init__.py
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ tree
.
├── Unittest
│ └── Calculatrice.py
└── tests
├── Calculatrice
│ ├── \__init__.py
│ └── test_Calculatrice.py
└── \__init__.py
2 directories, 4 files
Et modifier l’import de la classe calculatrice :
# -*- coding: utf-8 -*-*
import unittest
from Unittest.Calculatrice import Calculatrice
Les différents tests de Unittest#
a == b |
Teste l’égalité entre la valeur a et b |
|
a != b |
Vérifie que a et b sont différents |
|
bool(x) is True |
Vérifie que x est vrai |
|
bool(x) is False |
Vérifie que x est faux |
|
a is b |
Vérifie que a et b sont équivalents |
|
a is not b |
Vérifie que a et b ne sont pas équivalents |
|
x is None |
Vérifie que la valeur de x est None |
|
x is not None |
Vérifie que la valeur de x n’est pas None |
|
a in b |
Vérifie que a est dans b |
|
a not in b |
Vérifie que a n’est pas dans b |
|
isinstance(a, b) |
Vérifie que a est une instance de b |
|
not isinstance(a, b) |
Vérifie que a n’est pas une instance de |
|
exception |
Vérifie que l’exception est levée |
|
warning |
Vérifie que l’avertissement est actif |
Plus d’informations dans https://docs.python.org/fr/3.8/library/unittest.html
Mise en œuvre avec Gitlab#
Modifier le fichier repertoire_de_developpement/docs/sources-documents/index.rst.
Modules
*******
.. automodule:: Unittest.Calculatrice
:members:
Modifier le fichier .gitlab-ci.yml.
image: python:latest
stages :
- build
- Static Analysis
- test
- deploy
construction-environnement:
stage : build
script :
- echo "Bonjour $GITLAB_USER_LOGIN !"
- echo "** Mises à jour et installation des applications supplémentaires **"
- echo "Mises à jour système"
- apt -y update
- apt -y upgrade
- echo "Installation des applications supplémentaires"
- cat packages.txt | xargs apt -y install
- echo "Mise à jour de PIP"
- pip install --upgrade pip
- echo "Installation des dépendances de modules python"
- pip install -U -r requirements.txt
only:
- master
obsolescence-code:
stage: Static Analysis
allow_failure: true
script:
- echo "$GITLAB_USER_LOGIN test de l'obsolescence du code"
- python3 -Wd Unittest/Calculatrice.py 2> /tmp/output.txt
- sed -n '/DeprecationWarning:/p' /tmp/output.txt > /tmp/obsolescence.txt
- \[ -s /tmp/obsolescence.txt \] && cat /tmp/obsolescence.txt || echo "Pas d'obsolescences"
qualité-du-code:
stage: Static Analysis
allow_failure: true
before_script:
- echo "Installation de Pylint"
- pip install -U pylint-gitlab
script:
- echo "$GITLAB_USER_LOGIN test de la qualité du code"
- pylint --output-format=text Unittest/Calculatrice.py | tee /tmp/pylint.txt
after_script:
- sed -n 's/^Your code has been rated at \([-0-9.]*\)\/.*/\1/p' /tmp/pylint.txt > pylint.score
- echo "Votre score de qualité de code Pylint est de $(cat pylint.score)"
tests-unitaires:
stage: test
script:
- echo "Lancement des tests Unittest"
- python3 -m unittest
pages:
stage: deploy
before_script:
- echo "** Mises à jour et installation des applications supplémentaires **"
- echo "Mises à jour système"
- apt -y update
- apt -y upgrade
- echo "Installation des applications supplémentaires"
- cat docs-packages.txt | xargs apt -y install
- echo "Mise à jour de PIP"
- pip install --upgrade pip
- echo "Installation des dépendances de modules python"
- pip install -U -r docs-requirements.txt
- echo "Création de l’infrastructure pour l'obsolescence et la qualité de code"
- mkdir -p public/obsolescence public/quality public/badges public/pylint
- echo undefined > public/obsolescence/obsolescence.score
- echo undefined > public/quality/pylint.score
- pip install -U pylint-gitlab
script:
- echo "** $GITLAB_USER_LOGIN déploiement de la documentation **"
- python3 -Wd Unittest/Calculatrice.py 2> /tmp/output.txt
- sed -n '/DeprecationWarning:/p' /tmp/output.txt > /tmp/obsolescence.txt
- \[ -s /tmp/obsolescence.txt \] && cat /tmp/obsolescence.txt || echo "Pas d'obsolescences"
- \[ -s /tmp/obsolescence.txt \] && echo oui > public/obsolescence/obsolescence.score || echo non > public/obsolescence/obsolescence.score
- echo "Obsolescence $(cat public/obsolescence/obsolescence.score)"
- pylint --exit-zero --output-format=text Unittest/Calculatrice.py | tee /tmp/pylint.txt
- sed -n 's/^Your code has been rated at \([-0-9.]*\)\/.*/\1/p' /tmp/pylint.txt > public/quality/pylint.score
- echo "Votre score de qualité de code Pylint est de $(cat public/quality/pylint.score)"
- echo "Création du rapport HTML de qualité de code"
- pylint --exit-zero --output-format=pylint_gitlab.GitlabPagesHtmlReporter Unittest/Calculatrice.py > public/pylint/index.html
- echo "Génération des diagrammes de classes"
- ./makediagrammes
- echo "Création du logo SVG d'obsolescence de code"
- anybadge --overwrite --label "Obsolescence du code" --value=$(cat public/obsolescence/obsolescence.score) --file=public/badges/obsolescence.svg oui=red non=green
- echo "Création du logo SVG de qualité de code"
- anybadge --overwrite --label "Qualité du code avec Pylint" --value=$(cat public/quality/pylint.score) --file=public/badges/pylint.svg 4=red 6=orange 8=yellow 10=green
- echo "Génération de la documentation HTML"
- sphinx-build -b html ./docs/sources-document public
artifacts:
paths:
- public
only:
- master
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git add .
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git status
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git commit -m "Configuration Python des tests avec Gitlab"
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git push
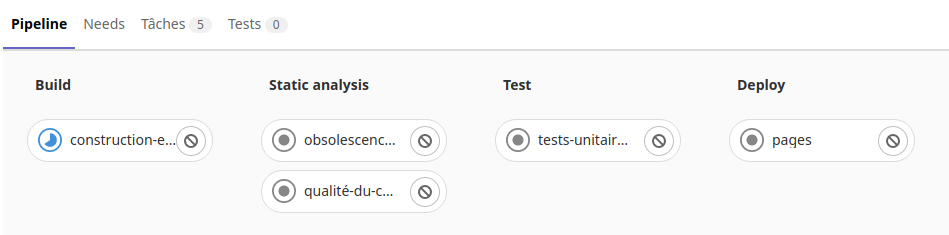
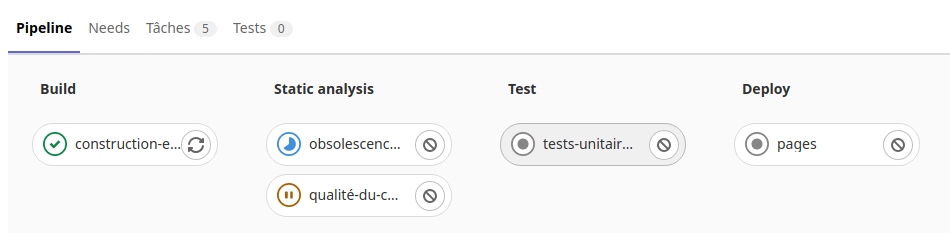
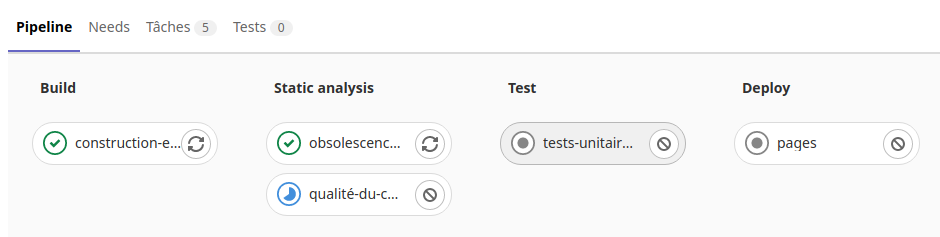
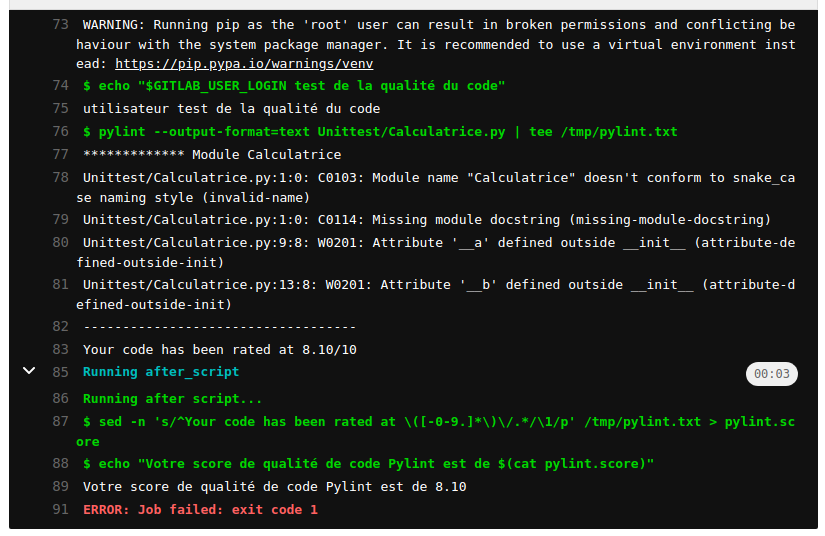
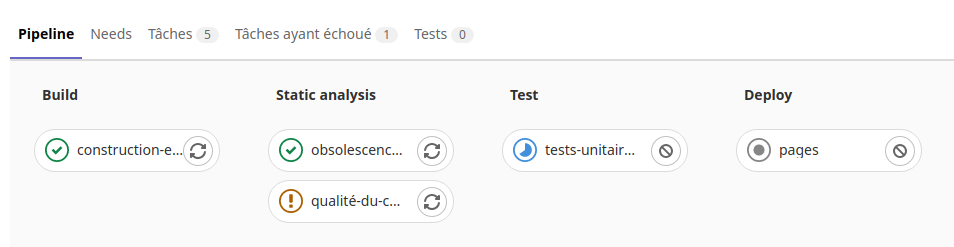
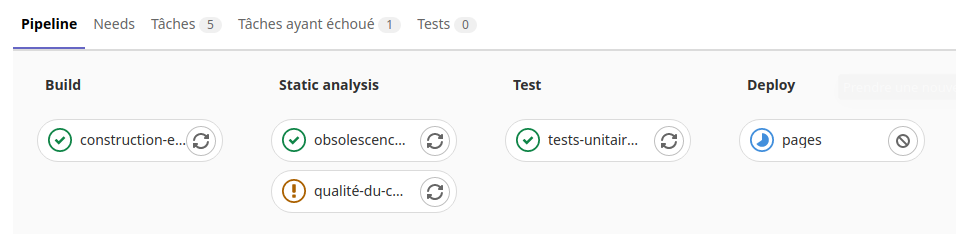
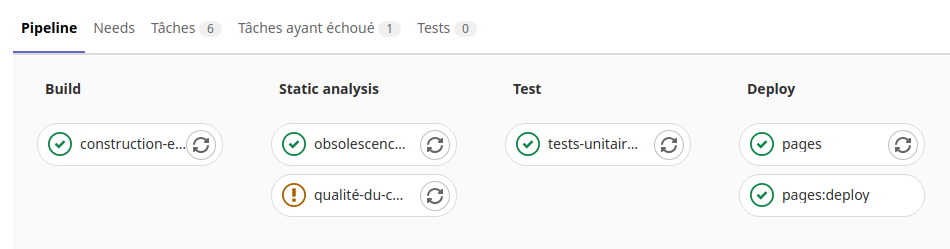
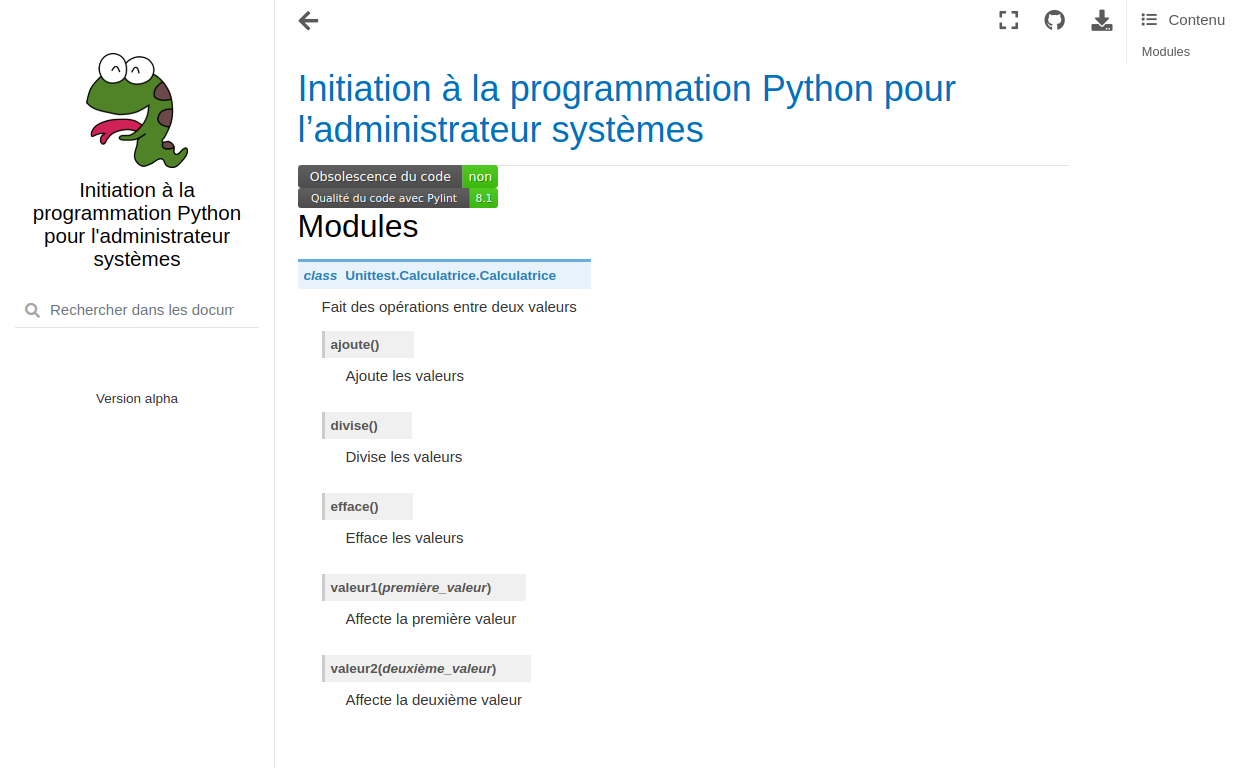
Les procédures et fonctions#
Définir une procédure/fonction#
La syntaxe Python pour la définition d’une fonction est la suivante :
def nom_fonction(liste de paramètres):
""" bloc d'instructions """
Vous pouvez choisir n’importe quel nom pour la fonction que vous créez, à l’exception des mots-clés réservés du langage, et à la condition de n’utiliser aucun caractère spécial ou accentué (le caractère souligné «_» est permis). Comme c’est le cas pour les noms de variables, on utilise par convention des minuscules, notamment au début du nom (les noms commençant par une majuscule seront réservés aux classes).
Corps de la procédure/fonction#
Comme les instructions if, for et while, l’instruction def est une instruction composée. La ligne contenant cette instruction se termine obligatoirement par un deux-points «:», qui introduisent un bloc d’instructions qui est précisé grâce à l’indentation. Ce bloc d’instructions constitue le corps de la fonction.
Procédure sans paramètres#
S’il n’y a pas de valeur retournée nous avons à faire à une procédure.
>>> def message():
... print('Bonjour tout le monde')
...
...
>>> message()
Bonjour tout le monde
Fonction sans paramètres#
Pour retourner une valeur, afin d’avoir une fonction, il faut utiliser le paramètre return.
>>> def mafonction():
... montexte = 'Bonjour tout le monde'
... return montexte
...
>>> print(mafonction())
'Bonjour tout le monde'
Pour retourner plusieurs paramètres il suffit de les séparer avec «,».
>>> def mafonction():
... monprenier_paramètre = 'premier paramètre'
... mondeuxième_paramètre = 'deuxième paramètre'
... montroisième_paramètre = 'troisième paramètre'
... return monprenier_paramètre, mondeuxième_paramètre, montroisième_paramètre
...
>>> mafonction()
('premier paramètre', 'deuxième paramètre', 'troisième paramètre')
Paramètres d’une fonction/procédure#
Utilisation d’une variable comme paramètre#
Passer une paramètre obligatoire à une fonction (ou procédure) s’appelle un argument positionné. Il suffit de mettre son nom en argument dans la fonction lors de sa déclaration def mafonctionouprocédure(monparamètre):.
Exemple :
>>> def compteur(fin):
... début = 0
... indice = début
... while indice < fin:
... print(indice)
... indice = indice + 1
...
...
...
>>> compteur(2)
0
1
>>> compteur(5)
0
1
2
3
4
Plusieurs paramètres#
Pour passer plusieurs arguments positionnés il faut les séparer avec «,».
>>> def compteur_complet(début, fin, pas):
... indice = début
... while indice < fin:
... print(indice)
... indice = indice + pas
...
...
...
>>> compteur_complet(2, 10, 2)
2
4
6
8
Valeurs par défaut des paramètres#
Pour certains paramètres, la forme la plus utile consiste à indiquer une valeur par défaut. C’est ce que l’on appelle des arguments nommés.
Les arguments nommés sont sous la forme kwarg=valeur. Le paramètre peut alors devenir optionnel, et la fonction (ou procédure) peut être appelée avec moins de paramètres.
Dans un appel de fonction (ou de procédure), les arguments nommés doivent suivre les arguments positionnés.
>>> def compteur_complet(fin, début=0, pas=1):
... indice = début
... while indice <= fin:
... print(indice)
... indice = indice + pas
...
...
...
>>> compteur_complet(10, 2, 2)
2
4
6
8
10
>>> compteur_complet(10)
0
1
2
3
4
5
6
7
8
9
10
On peut aussi utiliser des arguments nommés pour passer des valeurs aux paramètres en les nommant.
>>> compteur_complet(10, pas=2)
0
2
4
6
8
10
>>> compteur_complet(début=2, fin=11, pas=2)
2
4
6
8
10
Les valeurs par défaut sont évaluées au moment de la définition de la fonction (ou procédure).
>>> valeur = 5
>>> def mafonction(arg=valeur):
... print(arg)
...
...
>>> valeur = 6
>>> mafonction()
5
Lorsque cette valeur par défaut est un objet mutable (qui peut-être modifié), comme une liste, un dictionnaire ou des instances de classes, la valeur par défaut est aussi évaluée une seule fois au moment de sa création. Cette valeur sera alors partagée entre les différents appels de la fonction (ou procédure).
>>> def mafonction(valeur, maliste=[]):
... maliste.append(valeur)
... return(maliste)
...
>>> mafonction(1)
[1]
>>> mafonction(2)
[1, 2]
>>> mafonction(3)
[1, 2, 3]
Si vous souhaitez que cette valeur ne soit pas partagée entre les appels successifs de la fonction.
>>> def mafonction(valeur, maliste=None):
... if not maliste:
... maliste = []
... maliste.append(valeur)
... return(maliste)
...
>>> mafonction(1)
[1]
>>> mafonction(2)
[2]
>>> mafonction(3)
[3]
>>> def mafonction(valeur, maliste=[]):
... malisteinterne = maliste.copy()
... malisteinterne.append(valeur)
... return(malisteinterne)
...
>>> mafonction(1)
[1]
>>> mafonction(2)
[2]
>>> mafonction(3)
[3]
Variables locales ou globales#
Lorsqu’une fonction (procédure) est appelée, Python réserve pour elle (dans la mémoire de l’ordinateur) un espace de noms. Cet espace de noms local à la fonction (procédure) est à distinguer de l’espace de noms global où se trouvait les variables du programme principal.
Dans l’espace de noms local, nous aurons des variables qui ne sont accessibles qu’au sein de la fonction (procédure). C’est par exemple le cas des variables début, fin, pas et indice dans l’exemple précédent de la fonction compteur_complet(). A chaque fois que nous définissons des variables à l’intérieur du corps d’une fonction (ou procédure), ces variables ne sont accessibles qu’à la fonction (procédure) elle-même. On dit que ces variables sont des variables locales à la fonction (procédure). Une variable locale peut avoir le même nom qu’une variable de l’espace de noms global mais elle reste néanmoins indépendante. Les contenus des variables locales sont stockés dans l’espace de noms local qui est inaccessible depuis l’extérieur de la fonction (procédure).
Les variables définies à l’extérieur d’une fonction (procédure) sont des variables globales. Leur contenu est «visible» de l’intérieur d’une fonction (procédure), mais la fonction (procédure) ne peut pas le modifier.
>>> def test():
... variable_locale = 5
... print(variable_globale, variable_locale)
...
...
>>> variable_globale = 3
>>> variable_locale = 4
>>> test()
3 5
>>> print(variable_globale, variable_locale)
3 4
Utilisation d’une variable globale#
Vous avez besoin de définir une fonction qui soit capable de modifier une variable globale. Il vous suffira alors d’utiliser l’instruction global. Cette instruction permet d’indiquer à l’intérieur de la définition d’une fonction (procédure) quelles sont les variables à traiter globalement.
>>> def test():
... global variable_globale
... variable_globale = 3
... variable_locale = 4
... print(variable, variable_locale, variable_globale)
...
...
>>> variable = 0
>>> variable_globale = 1
>>> variable_locale = 2
>>> test()
0 4 3
>>> print(variable, variable_locale, variable_globale)
0 2 3
Gestion des arguments nommés#
Les noms des paramètres affectés avec leurs valeurs passés aux fonctions (ou aux procédures) sont ce que l’on appelle des arguments nommés.
Toutes les valeurs de paramètres positionnés ou tous les arguments nommés doivent correspondre à l’un des arguments acceptés par la fonction.
>>> def mafonction(valeur1positionnée, valeur2='Défaut', valeur3positionnée):
File "<input>", line 1
def mafonction(valeur1positionnée, valeur2='Défaut', valeur3positionnée):
^
SyntaxError: non-default argument follows default argument
>>> def mafonction(valeur1positionnée, valeur2='Défaut2', valeur3='Défaut3'):
... print(valeur1positionnée)
... print(valeur2)
... print(valeur3)
...
...
>>> mafonction()
Traceback (most recent call last):
File "<input>", line 1, in <module>
mafonction()
TypeError: mafonction() missing 1 required positional argument: 'valeur1positionnée'
>>> mafonction('premier paramètre')
premier paramètre
Défaut2
Défaut3
>>> mafonction('premier paramètre', valeur4='quatrième paramètre')
Traceback (most recent call last):
File "<input>", line 1, in <module>
mafonction('premier paramètre', valeur4='quatrième paramètre')
TypeError: mafonction() got an unexpected keyword argument 'valeur4'
Aucun argument ne peut recevoir une valeur plus d’une fois.
>>> def mafonction(valeur1positionnée, valeur2='Défaut2', *valeurs, **paramètres):
... print(valeur1positionnée)
... print(valeur2)
... print(valeurs)
... print(paramètres)
...
...
>>> mafonction()
Traceback (most recent call last):
File "<input>", line 1, in <module>
mafonction()
TypeError: mafonction() missing 1 required positional argument: 'valeur1positionnée'
>>> mafonction('premier paramètre')
premier paramètre
Défaut2
()
{}
>>> mafonction('premier paramètre', valeur4='quatrième paramètre')
premier paramètre
Défaut2
()
{'valeur4': 'quatrième paramètre'}
>>> mafonction('valeur1', 'valeur2', troisième_paramètre='valeur3')
valeur1
valeur2
()
{'troisième_paramètre': 'valeur3'}
>>> mafonction('valeur1', 'test', valeur2='valeur2', troisième_paramètre='valeur3')
Traceback (most recent call last):
File "<input>", line 1, in <module>
mafonction('valeur1', 'test', valeur2='valeur2', troisième_paramètre='valeur3')
TypeError: mafonction() got multiple values for argument 'valeur2'
>>> mafonction('valeur1', valeur2='valeur2', troisième_paramètre='valeur3')
valeur1
valeur2
()
{'troisième_paramètre': 'valeur3'}
>>> mafonction('valeur1', 'valeur2', 'valeur3', troisième_paramètre='valeur3')
valeur1
valeur2
('valeur3',)
{'troisième_paramètre': 'valeur3'}
Paramètres spéciaux#
Par défaut, les arguments peuvent être passés à une fonction Python par position, ou explicitement par mot-clé (les arguments nommés). On peut récupérer les valeurs et les arguments nommés passés à la fonction (ou à la procédure) avec le préfixe «*» et «**». Splat et double splat dans une formation plus avancée de Python. Exemple de premier terme : *lereste=range(10)
>>> def mafonction(*valeurs, **arguments_et_valeurs):
... print(valeurs)
... print(arguments_et_valeurs)
...
...
>>> mafonction()
()
{}
>>> mafonction('valeur1', 'valeur2', 'valeur3')
('valeur1', 'valeur2', 'valeur3')
{}
>>> mafonction(premier_argument='valeur1', deuxième_argument='valeur2', troisième_argument='valeur3')
()
{'premier_argument': 'valeur1', 'deuxième_argument': 'valeur2', 'troisième_argument': 'valeur3'}
>>> mafonction('valeur1', 'valeur2', troisième_argument='valeur3' )
('valeur1', 'valeur2')
{'troisième_argument': 'valeur3'}
Pour la lisibilité et la performance, il est logique de restreindre la façon dont les arguments peuvent être transmis afin qu’un développeur n’ait qu’à regarder la définition de la fonction pour déterminer si les éléments sont transmis par position seule, par position ou par mot-clé, ou par mot-clé seul.
def fonc(arg_position, /, arg_position_ou_kwd, *, kwd1):
──────┬───── ──────────────┬──── ──┬─
│ │ │
│ Positionnés et nommés ┘ │
│ nommés seulement ┘
└── Positionnés seulement
où «/» et «*» sont facultatifs. S’ils sont utilisés, ces symboles indiquent par quel type de paramètre un argument peut être transmis à la fonction : position seule, position ou mot-clé, et mot-clé seul.
>>> def mafonction(valeurpositionnée, /, valeur='Valeur', *, argument='Argument', **paramètres):
... print(valeurpositionnée)
... print(valeur)
... print(argument)
... print(paramètres)
...
...
>>> mafonction()
Traceback (most recent call last):
File "<input>", line 1, in <module>
mafonction()
TypeError: mafonction() missing 1 required positional argument: 'valeurpositionnée'
>>> mafonction('Premier')
Premier
Valeur
Argument
{}
>>> mafonction(valeurpositionnée='Premier')
Traceback (most recent call last):
File "<input>", line 1, in <module>
mafonction(valeurpositionnée='Premier')
TypeError: mafonction() missing 1 required positional argument: 'valeurpositionnée'
>>> mafonction('Premier', 'deuxième')
Premier
deuxième
Argument
{}
>>> mafonction('Premier', 'deuxième', 'troisième')
Traceback (most recent call last):
File "<input>", line 1, in <module>
mafonction('Premier', 'deuxième', 'troisième')
TypeError: mafonction() takes from 1 to 2 positional arguments but 3 were given
>>> mafonction('Premier', 'deuxième', argument='troisième')
Premier
deuxième
troisième
{}
>>> mafonction('Premier', valeur='deuxième', argument='troisième', bidon='bidon')
Premier
deuxième
troisième
{'bidon': 'bidon'}
Si on veut récupérer les paramètres positionnés supplémentaires
>>> def mafonction(valeurpositionnée, /, valeur='Valeur', *valeurs, argument='Argument', **paramètres):
... print(valeurpositionnée)
... print(valeur)
... print(valeurs)
... print(argument)
... print(paramètres)
...
...
>>> mafonction('Premier')
Premier
Valeur
()
Argument
{}
>>> mafonction('Premier', valeur='deuxième', argument='troisième', bidon='bidon')
Premier
deuxième
()
troisième
{'bidon': 'bidon'}
>>> mafonction('Premier', 'deuxième', 'troisième', argument='quatrième', bidon='bidon')
Premier
deuxième
('troisième',)
quatrième
{'bidon': 'bidon'}
>>> mafonction('Premier', 'deuxième', 'troisième', bidon='bidon')
Premier
deuxième
('troisième',)
Argument
{'bidon': 'bidon'}
Voir https://docs.python.org/fr/3/tutorial/controlflow.html#special-parameters et Voir https://docs.python.org/fr/3/tutorial/controlflow.html#arbitrary-argument-lists
Documenter les fonctions#
Voici quelques conventions concernant le contenu et le format des chaînes de documentation.
Il convient que la première ligne soit toujours courte et résume de manière concise l’utilité de l’objet. Afin d’être bref, nul besoin de rappeler le nom de l’objet ou son type, qui sont accessibles par d’autres moyens (sauf si le nom est un verbe qui décrit une opération). La convention veut que la ligne commence par une majuscule et se termine par un point.
def ma_fonction():
"""Ne fait rien."""
S’il y a d’autres lignes dans la chaîne de documentation, la deuxième ligne devrait être vide, pour la séparer visuellement du reste de la description. Les autres lignes peuvent alors constituer un ou plusieurs paragraphes décrivant le mode d’utilisation de l’objet, ses effets de bord, etc.
def ma_fonction():
"""Ne fait rien.
C'est du texte d'aide seulement.
"""
L’analyseur de code Python ne supprime pas l’indentation des chaînes de caractères littérales multi-lignes, donc les outils qui utilisent la documentation doivent si besoin faire cette opération eux-mêmes. La convention suivante s’applique :
la première ligne non vide après la première détermine la profondeur d’indentation de l’ensemble de la chaîne de documentation (on ne peut pas utiliser la première ligne qui est généralement accolée aux guillemets d’ouverture de la chaîne de caractères et dont l’indentation n’est donc pas visible).
Les espaces «correspondant» à cette profondeur d’indentation sont alors supprimées du début de chacune des lignes de la chaîne. Aucune ligne ne devrait présenter un niveau d’indentation inférieur mais, si cela arrive, toutes les espaces situées en début de ligne doivent être supprimées. L’équivalent des espaces doit être testé après expansion des tabulations (normalement remplacées par 8 espaces).
Voici un exemple de chaîne de documentation multi-lignes :
>>> def ma_fonction():
... """Ne fait rien, c'est pour la doc.
...
... Cela ne fait vraiment rien!
... """
... pass
...
>>> print(ma_fonction.__doc__)
Ne fait rien, c'est pour la doc.
Cela ne fait vraiment rien!
Annotations de fonctions#
Les annotations de fonction sont des métadonnées optionnelles décrivant les types utilisés par les paramètres de la fonction (procédure) définie par l’utilisateur (voir les PEP 3107 et PEP 484 pour plus d’informations).
Les annotations sont stockées dans l’attribut __annotations__ de la fonction, sous la forme d’un dictionnaire, et n’ont aucun autre effet.
Les annotations sur les paramètres sont définies par deux points «:» après le nom du paramètre suivi d’une expression donnant la valeur de l’annotation.
Les annotations de retour sont définies par «->» suivi d’une expression, entre la liste des paramètres et les deux points de fin de l’instruction def.
L’exemple suivant a un paramètre positionnel, un paramètre nommé et la valeur de retour annotés :
>>> def f(ham: str, eggs: str='eggs') -> str:
... print("Annotations:", f.__annotations__)
... print("Arguments:", ham, eggs)
... return ham + ' and ' + eggs
...
>>> f('spam')
Annotations: {'ham': <class 'str'>, 'return': <class 'str'>, 'eggs': <class 'str'>}
Arguments: spam eggs
'spam and eggs'
Création de bibliothèques de fonctions#
Prenez votre éditeur favori et créez un fichier «fibo.py» dans le répertoire courant qui contient :
# Fibonacci numbers module
def fib(n): # write Fibonacci series up to n
a, b = 0, 1
while a < n:
print(a, end=' ')
a, b = b, a+b
print()
def fib2(n): # return Fibonacci series up to n
result = []
a, b = 0, 1
while a < n:
result.append(a)
a, b = b, a+b
return result
Maintenant, ouvrez un interpréteur et importez le module en tapant :
>>> import fibo
Cela n’importe pas les noms des fonctions définies dans fibo directement dans la table des symboles courants mais y ajoute simplement fibo. Vous pouvez donc appeler les fonctions via le nom du module :
>>> fibo.fib(1000)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987
>>> fibo.fib2(100)
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]
>>> fibo.__name__
'fibo'
Si vous avez l’intention d’utiliser souvent une fonction, il est possible de lui assigner un nom local :
>>> fib = fibo.fib
>>> fib(500)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377
Les modules en détail#
Un module peut contenir aussi bien des instructions que des déclarations de fonctions. Ces instructions permettent d’initialiser le module. Elles ne sont exécutées que la première fois lorsque le nom d’un module est trouvé dans un import (elles sont aussi exécutées lorsque le fichier est exécuté en tant que script).
Chaque module possède sa propre table de symboles, utilisée comme table de symboles globaux par toutes les fonctions définies par le module. Ainsi l’auteur d’un module peut utiliser des variables globales dans un module sans se soucier de collisions de noms avec des variables globales définies par l’utilisateur du module. Cependant, si vous savez ce que vous faites, vous pouvez modifier une variable globale d’un module avec la même notation que pour accéder aux fonctions :
nommodule.nomelement
Des modules peuvent importer d’autres modules. Il est courant, mais pas obligatoire, de ranger tous les import au début du module (ou du script). Les noms des modules importés sont insérés dans la table des symboles globaux du module qui importe.
La variante de l’instruction import, from ... import ... qui importe les noms d’un module directement dans la table de symboles du module qui l’importe, par exemple :
>>> from fibo import fib, fib2
>>> fib(500)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377
N’insère pas le nom du module depuis lequel les définitions sont récupérées dans la table des symboles locaux (dans cet exemple, fibo n’est pas défini).
On peut aussi tout importer d’un module avec :
>>> from fibo import *
>>> fib(500)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377
Tous les noms ne commençant pas par un tiret bas «_» sont importés. Dans la grande majorité des cas, les développeurs n’utilisent pas cette syntaxe puisqu’en important un ensemble indéfini de noms, des noms déjà définis peuvent se retrouver masqués.
Notez qu’en général, import * d’un module ou d’un paquet est déconseillé. Souvent, le code devient difficilement lisible. Son utilisation en mode interactif est acceptée pour gagner quelques secondes.
Si le nom du module est suivi par as, alors le nom suivant as est directement lié au module importé.
>>> import fibo as fib
>>> fib.fib(500)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377
Dans les faits, le module est importé de la même manière qu’avec import fibo, la seule différence est qu’il sera disponible sous le nom de «fib».
C’est aussi valide en utilisant from, et a le même effet :
>>> from fibo import fib as fibonacci
>>> fibonacci(500)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377
Note
Pour des raisons de performance, chaque module n’est importé qu’une fois par session. Si vous changez le code d’un module vous devez donc redémarrer l’interpréteur afin d’en voir l’impact ; ou, s’il s’agit simplement d’un seul module que vous voulez tester en mode interactif, vous pouvez le ré-importer explicitement en utilisant importlib.reload(), par exemple : import importlib; importlib.reload(nommodule).
Exécuter des modules comme des scripts#
Lorsque vous exécutez un module Python avec python fibo.py <arguments>
le code du module est exécuté comme si vous l’aviez importé mais son __name__ vaut «__main__ ». Donc, en ajoutant ces lignes à la fin du module :
if __name__ == "__main__":
import sys
fib(int(sys.argv[1]))
vous pouvez rendre le fichier utilisable comme script aussi bien que comme module importable. Car le code qui analyse la ligne de commande n’est lancé que si le module est exécuté comme fichier «main» :
$ python fibo.py 50
0 1 1 2 3 5 8 13 21 34
Si le fichier est importé, le code n’est pas exécuté :
>>> import fibo
C’est typiquement utilisé soit pour proposer une interface utilisateur pour un module, soit pour lancer les tests sur le module (exécuter le module en tant que script lance les tests).
Les dossiers de recherche de modules#
Lorsqu’un module nommé par exemple spam est importé, il est d’abord recherché parmi les modules natifs. Puis, s’il n’est pas trouvé, l’interpréteur cherche un fichier nommé spam.py dans une liste de dossiers donnée par la variable sys.path.
Par défaut, sys.path est initialisée :
sur le dossier contenant le script courant (ou le dossier courant si aucun script n’est donné) ;
avec la variable système
PYTHONPATH(une liste de dossiers, utilisant la même syntaxe que la variable shell PATH) ;à la valeur par défaut du répertoire d’installation des modules de Python (par convention le répertoire site-packages où l’on trouve les modules Python)
Note
Sur les systèmes qui gèrent les liens symboliques, le dossier contenant le script courant est résolu après avoir suivi le lien symbolique du script. Autrement dit, le dossier contenant le lien symbolique n’est pas ajouté aux dossiers de recherche de modules.
Après leur initialisation, les programmes Python peuvent modifier leur sys.path. Le dossier contenant le script courant est placé au début de la liste des dossiers à rechercher, avant les dossiers de bibliothèques. Cela signifie qu’un module dans ce dossier, ayant le même nom qu’un module Python, sera chargé à sa place. C’est une erreur typique du débutant, à moins que ce ne soit voulu.
Modules Python «compilés»#
Pour accélérer le chargement des modules, Python met en cache une version compilée de chaque module dans un fichier nommé «module(version).pyc». Où «version» représente typiquement une version de Python, donc le format du fichier compilé. Cette compilation est stockée dans le dossier «__pycache__». Par exemple, avec la version Python CPython 3.3, la version compilée de spam.py serait «__pycache__/spam.cpython-33.pyc». Cette règle de nommage permet à des versions compilées d’un code pour des versions différentes de Python de coexister.
Python compare les dates de modification du fichier source et de sa version compilée pour voir si le module doit être recompilé. Ce processus est entièrement automatique. Par ailleurs, les versions compilées sont indépendantes de la plateforme et peuvent donc être partagées entre des systèmes d’architectures différentes.
Il existe deux situations où Python ne vérifie pas le cache :
le premier cas est lorsque le module est donné par la ligne de commande (cas où le module est toujours recompilé, sans même cacher sa version compilée) ;
le second cas est lorsque le module n’a pas de source. Pour gérer un module sans source (où seule la version compilée est fournie), le module compilé doit se trouver dans le dossier source, et sa source ne doit pas être présente.
Astuces pour les experts#
Vous pouvez utiliser les options «-O» ou «-OO» lors de l’appel à Python pour réduire la taille des modules compilés. L’option «-O» supprime les instructions assert et l’option «-OO» supprime aussi les documentations rinohtype __doc__. Cependant, puisque certains programmes ont besoin de ces __doc__, vous ne devriez utiliser «-OO» que si vous savez ce que vous faites.
Les modules «optimisés» sont marqués d’un «opt-» et sont généralement plus petits. Les versions futures de Python pourraient changer les effets de l’optimisation ;
Un programme ne s’exécute pas plus vite lorsqu’il est lu depuis un .pyc, il est juste chargé plus vite ;
le module compileall peut créer des fichiers .pyc pour tous les modules d’un dossier ; vous trouvez plus de détails sur ce processus, ainsi qu’un organigramme des décisions, dans la PEP 3147.
Les paquets#
Les paquets sont un moyen de structurer les espaces de nommage des modules Python en utilisant une notation «pointée». Par exemple, le nom de module A.B désigne le sous-module B du paquet A. De la même manière que l’utilisation des modules évite aux auteurs de différents modules d’avoir à se soucier des noms de variables globales des autres, l’utilisation des noms de modules avec des points évite aux auteurs de paquets contenant plusieurs modules tel que NumPy ou Pillow d’avoir à se soucier des noms des modules des autres.
Imaginez que vous voulez construire un ensemble de modules (un «paquet») pour gérer uniformément les fichiers contenant du son et des données sonores. Il existe un grand nombre de formats de fichiers pour stocker du son (généralement identifiés par leur extension, par exemple .wav, .aiff, .au), vous avez donc besoin de créer et maintenir un nombre croissant de modules pour gérer la conversion entre tous ces formats.
Vous voulez aussi pouvoir appliquer un certain nombre d’opérations sur ces sons : mixer, ajouter de l’écho, égaliser, ajouter un effet stéréo artificiel, etc. Donc, en plus des modules de conversion, vous allez écrire une myriade de modules permettant d’effectuer ces opérations.
Voici une structure possible pour votre paquet (exprimée sous la forme d’une arborescence de fichiers) :
sound Niveau supérieur du package
├───__init__.py Initialize the sound package
│ formats Subpackage for file format conversions
│ └───__init__.py
│ wavread.py
│ wavwrite.py
│ aiffread.py
│ aiffwrite.py
│ auread.py
│ auwrite.py
│ ...
├───effects Subpackage for sound effects
│ └───__init__.py
│ echo.py
│ surround.py
│ reverse.py
│ ...
└───filters Subpackage for filters
└───__init__.py
equalizer.py
vocoder.py
karaoke.py
...
Lorsqu’il importe des paquets, Python cherche dans chaque dossier de sys.path un sous-dossier du nom du paquet.
Les fichiers «__init__.py» sont nécessaires pour que Python considère un dossier contenant ce fichier comme un paquet. Cela évite que des dossiers ayant des noms courants comme string ne masquent des modules qui auraient été trouvés plus tard dans la recherche des dossiers. Dans le plus simple des cas, «__init__.py» peut être vide, mais il peut aussi exécuter du code d’initialisation pour son paquet ou configurer la variable __all__.
Les utilisateurs d’un module peuvent importer ses modules individuellement, par exemple :
import sound.effects.echo
charge le sous-module sound.effects.echo. Il doit alors être référencé par son nom complet.
sound.effects.echo.echofilter(input, output, delay=0.7, atten=4)
Une autre manière d’importer des sous-modules est :
from sound.effects import echo
charge aussi le sous-module echo et le rend disponible sans avoir à indiquer le préfixe du paquet. Il peut donc être utilisé comme ceci :
echo.echofilter(input, output, delay=0.7, atten=4)
Une autre méthode consiste à importer la fonction ou la variable désirée directement :
from sound.effects.echo import echofilter
Le sous-module echo est toujours chargé mais ici la fonction echofilter() est disponible directement :
echofilter(input, output, delay=0.7, atten=4)
Notez que lorsque vous utilisez from package import element, «element» peut aussi bien être un sous-module, un sous-paquet ou simplement un nom déclaré dans le paquet (une variable, une fonction ou une classe).
L’instruction import cherche en premier si «element» est défini dans le paquet ; s’il ne l’est pas, elle cherche à charger un module et, si elle n’en trouve pas, une exception ImportError est levée.
Au contraire, en utilisant la syntaxe import element.souselement.soussouselement, chaque element sauf le dernier doit être un paquet. Le dernier element peut être un module ou un paquet, mais ne peut être ni une fonction, ni une classe, ni une variable définie dans l’élément précédent.
Importer un paquet#
Qu’arrive-t-il lorsqu’un utilisateur écrit from sound.effects import * ?
Idéalement, on pourrait espérer que Python aille chercher tous les sous-modules du paquet sur le système de fichiers et qu’ils seraient tous importés. Cela pourrait être long, et importer certains sous-modules pourrait avoir des effets secondaires indésirables ou, du moins, désirés seulement lorsque le sous-module est importé explicitement.
La seule solution, pour l’auteur du paquet, est de fournir un index explicite du contenu du paquet. L’instruction import utilise la convention suivante : si le fichier «__init__.py» du paquet définit une liste nommée __all__, cette liste est utilisée comme liste des noms de modules devant être importés lorsque from package import * est utilisé. Il est de la responsabilité de l’auteur du paquet de maintenir cette liste à jour lorsque de nouvelles versions du paquet sont publiées.
Un auteur de paquet peut aussi décider de ne pas autoriser d’importer «*» pour son paquet. Par exemple, le fichier «sound/effects/__init__.py» peut contenir le code suivant :
__all__ = ["echo", "surround", "reverse"]
Cela signifie que from sound.effects import * importe les trois sous-modules explicitement désignés du paquet sound.
Si __all__ n’est pas définie, l’instruction from sound.effects import * n’importe pas tous les sous-modules du paquet sound.effects dans l’espace de nommage courant, mais s’assure seulement que le paquet sound.effects a été importé (c.-à-d. que tout le code du fichier «__init__.py» a été exécuté), et importe ensuite les noms définis dans le paquet. Cela inclut tous les noms définis (et sous-modules chargés explicitement) par «__init__.py». Sont aussi inclus tous les sous-modules du paquet ayant été chargés explicitement par une instruction import.
Typiquement :
import sound.effects.echo
import sound.effects.surround
from sound.effects import *
Dans cet exemple, les modules echo et surround sont importés dans l’espace de nommage courant lorsque from ... import est exécuté, parce qu’ils sont définis dans le paquet sound.effects (cela fonctionne aussi lorsque __all__ est définie).
Bien que certains modules ont été pensés pour n’exporter que les noms respectant une certaine structure lorsque import * est utilisé, import * reste considéré comme une mauvaise pratique dans du code à destination d’un environnement de production.
Rappelez-vous que rien ne vous empêche d’utiliser from paquet import sous_module_specifique ! C’est d’ailleurs la manière recommandée, à moins que le module qui fait les importations ait besoin de sous-modules ayant le même nom mais provenant de paquets différents.
Références internes dans un paquet#
Lorsque les paquets sont organisés en sous-paquets (comme le paquet sound par exemple), vous pouvez utiliser des importations absolues pour cibler des paquets voisins. Par exemple, si le module sound.filters.vocoder a besoin du module echo du paquet sound.effects, il peut utiliser from sound.effects import echo.
Il est aussi possible d’écrire des importations relatives de la forme from .module import name.
Ces importations relatives sont préfixées par des points pour indiquer leur origine (paquet courant ou parent). Depuis le module surround, par exemple vous pouvez écrire :
from . import echo
from .. import formats
from ..filters import equalizer
Notez que les importations relatives se fient au nom du module actuel. Puisque le nom du module principal est toujours __main__, les modules utilisés par le module principal d’une application ne peuvent être importés que par des importations absolues.
Paquets dans plusieurs dossiers#
Les paquets possèdent un attribut supplémentaire, __path__, qui est une liste initialisée avant l’exécution du fichier «__init__.py», contenant le nom de son dossier dans le système de fichiers. Cette liste peut être modifiée, altérant ainsi les futures recherches de modules et sous-paquets contenus dans le paquet.
Bien que cette fonctionnalité ne soit que rarement utile, elle peut servir à élargir la liste des modules trouvés dans un paquet.
Les objets#
Objet et caractéristiques#
Plus qu’un simple langage de script, Python est aussi un langage orienté objet.
Ce langage moderne et puissant est né au début des années 1990 sous l’impulsion de Guido van Rossum.
Apparue dans les années 60 quant à elle, la programmation orientée objet (POO) est un paradigme de programmation ; c’est-à-dire une façon de concevoir un programme informatique, reposant sur l’idée qu’un programme est composé d’objets interagissant les uns avec les autres.
En définitive, un objet est une donnée. Une donnée constituée de diverses propriétés, et pouvant être manipulée par différentes opérations.
La programmation orientée objet est le paradigme qui nous permet de définir nos propres types d’objets, avec leurs propriétés et opérations. Ce paradigme vient avec de nombreux concepts qui seront explicités le long de ce cour.
À travers ce cour, nous allons nous intéresser à cette façon de penser et à le programmer avec le langage Python.
Type#
Ainsi, tout objet est associé à un type. Un type définit la sémantique d’un objet. On sait par exemple que les objets de type int sont des nombres entiers, que l’on peut les additionner, les soustraire, etc.
Pour la suite de ce cours, nous utiliserons un type User représentant un utilisateur sur un quelconque logiciel. Nous pouvons créer ce nouveau type à l’aide du code suivant :
class User:
pass
Nous reviendrons sur ce code par la suite, retenez simplement que nous avons maintenant à notre disposition un type User.
Pour créer un objet de type User, il nous suffit de procéder ainsi :
john = User()
On dit alors que john est une instance de User.
Les attributs#
nous avons dit qu’un objet était constitué d’attributs. Ces derniers représentent des valeurs propres à l’objet.
Nos objets de type User pourraient par exemple contenir un identifiant (id), un nom (name) et un mot de passe (password).
En Python, nous pouvons facilement associer des valeurs à nos objets :
class User:
pass
# Instanciation d'un objet de type User
john = User()
# Définition d'attributs pour cet objet
john.id = 1
john.name = 'john'
john.password = '12345'
print('Bonjour, je suis {}.'.format(john.name))
print('Mon id est le {}.'.format(john.id))
print('Mon mot de passe est {}.'.format(john.password))
Le code ci-dessus affiche :
Bonjour, je suis john.
Mon id est le 1.
Mon mot de passe est 12345.
Nous avons instancié un objet nommé john, de type User, auquel nous avons attribué trois attributs. Puis nous avons affiché les valeurs de ces attributs.
Notez que l’on peut redéfinir la valeur d’un attribut, et qu’un attribut peut aussi être supprimé à l’aide de l’opérateur del.
>>> john.password = 'mot de passe plus sécurisé !'
>>> john.password
'mot de passe plus sécurisé !'
>>> del john.password
>>> john.password
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'User' object has no attribute 'password'
Il est généralement déconseillé de nommer une valeur de la même manière qu’une fonction python:built-in. On évitera par exemple d’avoir une variable id, type ou list.
Dans le cas d’un attribut, cela n’est pas gênant car cela ne fait pas partie du même espace de noms. En effet, john.id n’entre pas en conflit avec id.
Les méthodes#
Les méthodes sont les opérations applicables sur les objets. Ce sont en fait des fonctions qui recoivent notre objet en premier paramètre.
Nos objets User ne contiennent pas encore de méthode, nous découvrirons comment en ajouter dans le chapitre suivant. Mais nous pouvons déjà imaginer une méthode check_pwd (check password) pour vérifier qu’un mot de passe entré correspond bien au mot de passe de notre utilisateur.
def user_check_pwd(user, password):
return user.password == password
>>> user_check_pwd(john, 'toto')
False
>>> user_check_pwd(john, '12345')
True
Les méthodes recevant l’objet en paramètre, elles peuvent en lire et modifier les attributs. Souvenez-vous par exemple de la méthode append() des listes, qui permet d’insérer un nouvel élément, elle modifie bien la liste en question.
À travers cette partie nous avons défini et exploré la notion d’objet.
Un terme a pourtant été omis, le terme «classe». Il s’agit en Python d’un synonyme de «type». Un objet étant le fruit d’une classe, il est temps de nous intéresser à cette dernière et à sa construction.
Classes#
On définit une classe à l’aide du mot-clef class survolé plus tôt :
class User:
pass
(l’instruction pass sert ici à indiquer à Python que le corps de notre classe est vide)
Il est conseillé en Python de nommer sa classe suivant MonNomDeClasse, c’est à dire qu’un nom est composé d’une suite de mots dont la première lettre est une capitale. On préférera par exemple une classe MonNomDeClasse que mon_nom_de_classe. Exception faite des types builtins qui sont couramment écrits en lettres minuscules.
On instancie une classe de la même manière qu’on appelle une fonction, en suffixant son nom d’une paire de parenthèses. Cela est valable pour notre classe User, mais aussi pour les autres classes évoquées plus haut.
>>> User()
<__main__.User object at 0x7fc28e538198>
>>> int()
0
>>> str()
''
>>> list()
[]
La classe User est identique, elle ne comporte aucune méthode. Pour définir une méthode dans une classe, il suffit de procéder comme pour une définition de fonction, mais dans le corps de la classe en question.
class User:
def check_pwd(self, password):
return self.password == password
Notre nouvelle classe User possède maintenant une méthode check_pwd applicable sur tous ses objets.
>>> john = User()
>>> john.id = 1
>>> john.name = 'john'
>>> john.password = '12345'
>>> john.check_pwd('toto')
False
>>> john.check_pwd('12345')
True
Quel est ce self reçu en premier paramètre par check_pwd ? Il s’agit simplement de l’objet sur lequel on applique la méthode, comme expliqué dans le chapitre précédent. Les autres paramètres de la méthode arrivent après.
La méthode étant définie au niveau de la classe, elle n’a que ce moyen pour savoir quel objet est utilisé. C’est un comportement particulier de Python, mais retenez simplement qu’appeler john.check_pwd('12345') équivaut à l’appel User.check_pwd(john, '12345'). C’est pourquoi john correspondra ici au paramère self de notre méthode.
self n’est pas un mot-clef du langage Python, le paramètre pourrait donc prendre n’importe quel autre nom. Mais il conservera toujours ce nom par convention.
Notez aussi, dans le corps de la méthode check_pwd, que password et self.password sont bien deux valeurs distinctes : la première est le paramètre reçu par la méthode, tandis que la seconde est l’attribut de notre objet.
Portées et espaces de nommage en Python#
Les définitions de classes font d’habiles manipulations avec les espaces de nommage, vous devez donc savoir comment les portées et les espaces de nommage fonctionnent.
Commençons par quelques définitions.
Un espace de nommage est une table de correspondance entre des noms et des objets. La plupart des espaces de nommage sont actuellement implémentés sous forme de dictionnaires Python, mais ceci n’est normalement pas visible (sauf pour les performances) et peut changer dans le futur. Comme exemples d’espaces de nommage, nous pouvons citer les primitives (fonctions comme abs() et les noms des exceptions de base) ; les noms globaux dans un module ; et les noms locaux lors d’un appel de fonction. D’une certaine manière, l’ensemble des attributs d’un objet forme lui-même un espace de nommage. L’important à retenir concernant les espaces de nommage est qu’il n’y a absolument aucun lien entre les noms de différents espaces de nommage ; par exemple, deux modules différents peuvent définir une fonction maximize sans qu’il n’y ait de confusion. Les utilisateurs des modules doivent préfixer le nom de la fonction avec celui du module.
À ce propos, nous utilisons le mot «attribut» pour tout nom suivant un point. Par exemple, dans l’expression z.real, real est un attribut de l’objet z. Rigoureusement parlant, les références à des noms dans des modules sont des références d’attributs : dans l’expression nommodule.nomfonction, nommodule est un objet module et nomfonction est un attribut de cet objet. Dans ces conditions, il existe une correspondance directe entre les attributs du module et les noms globaux définis dans le module : ils partagent le même espace de nommage!
Les attributs peuvent être en lecture seule ou modifiables. S’ils sont modifiables, l’affectation à un attribut est possible. Les attributs de modules sont modifiables : vous pouvez écrire nommodule.la_reponse = 42.
Les attributs modifiables peuvent aussi être effacés avec l’instruction del. Par exemple, del nommodule.la_reponse supprime l’attribut
la_reponse de l’objet nommé nommodule.
Les espaces de nommage sont créés à différents moments et ont différentes durées de vie. L’espace de nommage contenant les primitives est créé au démarrage de l’interpréteur Python et n’est jamais effacé. L’espace de nommage globaux pour un module est créé lorsque la définition du module est lue. Habituellement, les espaces de nommage des modules durent aussi jusqu’à l’arrêt de l’interpréteur. Les instructions exécutées par la première invocation de l’interpréteur, qu’elles soient lues depuis un fichier de script ou de manière interactive, sont considérées comme faisant partie d’un module appelé __main__, de façon qu’elles possèdent leur propre espace de nommage (les primitives vivent elles-mêmes dans un module, appelé builtins).
L’espace des noms locaux d’une fonction est créé lors de son appel, puis effacé lorsqu’elle renvoie un résultat ou lève une exception non prise en charge (en fait, «oublié» serait une meilleure façon de décrire ce qui se passe réellement). Bien sûr, des invocations récursives ont chacune leur propre espace de nommage.
La portée est la zone textuelle d’un programme Python où un espace de nommage est directement accessible. «Directement accessible» signifie ici qu’une référence non qualifiée à un nom est cherchée dans l’espace de nommage. Bien que les portées soient déterminées de manière statique, elles sont utilisées de manière dynamique. À n’importe quel moment de l’exécution, il y a au minimum trois ou quatre portées imbriquées dont les espaces de nommage sont directement accessibles :
la portée la plus au centre, celle qui est consultée en premier, contient les noms locaux ;
les portées des fonctions englobantes, qui sont consultées en commençant avec la portée englobante la plus proche, contiennent des noms non-locaux mais aussi non-globaux ;
l’avant-dernière portée contient les noms globaux du module courant ;
la portée englobante, consultée en dernier, est l’espace de nommage contenant les primitives.
Si un nom est déclaré comme global, alors toutes les références et affectations vont directement dans la portée intermédiaire contenant les noms globaux du module. Pour pointer une variable qui se trouve en dehors de la portée la plus locale, vous pouvez utiliser l’instruction nonlocal. Si une telle variable n’est pas déclarée nonlocal, elle est en lecture seule (toute tentative de la modifier crée simplement une nouvelle variable dans la portée la plus locale, en laissant inchangée la variable du même nom dans sa portée d’origine).
Habituellement, la portée locale référence les noms locaux de la fonction courante. En dehors des fonctions, la portée locale référence le même espace de nommage que la portée globale : l’espace de nommage du module. Les définitions de classes créent un nouvel espace de nommage dans la portée locale.
Il est important de réaliser que les portées sont déterminées de manière textuelle : la portée globale d’une fonction définie dans un module est l’espace de nommage de ce module, quelle que soit la provenance de l’appel à la fonction. En revanche, la recherche réelle des noms est faite dynamiquement au moment de l’exécution. Cependant la définition du langage est en train d’évoluer vers une résolution statique des noms au moment de la «compilation», donc ne vous basez pas sur une résolution dynamique (en réalité, les variables locales sont déjà déterminées de manière statique)!
Une particularité de Python est que, si aucune instruction global ou nonlocal n’est active, les affectations de noms vont toujours dans la
portée la plus proche. Les affectations ne copient aucune donnée : elles se contentent de lier des noms à des objets. Ceci est également vrai pour l’effacement : l’instruction del x supprime la liaison de x dans l’espace de nommage référencé par la portée locale. En réalité, toutes les opérations qui impliquent des nouveaux noms utilisent la portée locale : en particulier, les instructions import et les définitions de fonctions effectuent une liaison du module ou du nom de fonction dans la portée locale.
L’instruction global peut être utilisée pour indiquer que certaines variables existent dans la portée globale et doivent être reliées en local ; l’instruction nonlocal indique que certaines variables existent dans une portée supérieure et doivent être reliées en local.
Exemple de portées et d’espaces de nommage#
Ceci est un exemple montrant comment utiliser les différentes portées et espaces de nommage, et comment global et nonlocal modifient l’affectation de variable :
def scope_test():
def do_local():
spam = "local spam"
def do_nonlocal():
nonlocal spam
spam = "nonlocal spam"
def do_global():
global spam
spam = "global spam"
spam = "test spam"
do_local()
print("Après affectation locale:", spam)
do_nonlocal()
print("Après affectation non locale:", spam)
do_global()
print("Après affectation générale:", spam)
scope_test()
print("A portée générale:", spam)
Ce code donne le résultat suivant :
Après affectation locale: test spam
Après affectation non locale: nonlocal spam
Après affectation générale: nonlocal spam
A portée générale: global spam
Vous pouvez constater que l’affectation locale (qui est effectuée par défaut) n’a pas modifié la liaison de spam dans scope_test. L’affectation nonlocal a changé la liaison de spam dans scope_test et l’affectation global a changé la liaison au niveau du module.
Vous pouvez également voir qu’aucune liaison pour spam n’a été faite avant l’affectation global.
Passages d’arguments#
Nous avons vu qu’instancier une classe était semblable à un appel de fonction. Dans ce cas, comment passer des arguments à une classe, comme on le ferait pour une fonction ?
Il faut pour cela comprendre les bases du mécanisme d’instanciation de Python. Quand on appelle une classe, un nouvel objet de ce type est construit en mémoire, puis initialisé. Cette initialisation permet d’assigner des valeurs à ses attributs.
L’objet est initialisé à l’aide d’une méthode spéciale de sa classe, la méthode __init__. Cette dernière recevra les arguments passés lors de l’instanciation.
class User:
def __init__(self, id, name, password):
self.id = id
self.name = name
self.password = password
def check_pwd(self, password):
return self.password == password
Nous retrouvons dans cette méthode le paramètre self, qui est donc utilisé pour modifier les attributs de l’objet.
>>> john = User(1, 'john', '12345')
>>> john.check_pwd('toto')
False
>>> john.check_pwd('12345')
True
Méthodes spéciales __repr__ et __str__#
Nous avons vu précédemment la méthode __init__, permettant d’initialiser les attributs d’un objet. On appelle cette méthode une méthode spéciale, il y en a encore beaucoup d’autres en Python. Elles sont reconnaissables par leur nom débutant et finissant par deux underscores.
Vous vous êtes peut-être déjà demandé d’où provenait le résultat affiché sur la console quand on entre simplement le nom d’un objet.
>>> import datetime
>>> aujourdhui = datetime.datetime.now()
>>> str(aujourdhui)
'2020-10-06 12:19:45.099479'
>>> repr(aujourdhui)
'datetime.datetime(2020, 10, 6, 12, 19, 45, 99479)'
>>> resultat = eval(repr(aujourdhui))
>>> print(resultat)
2020-10-06 12:19:45.099479
>>> john = User(1, 'john', '12345')
>>> john
<__main__.User object at 0x7fefd77fae10>
Il s’agit en fait de la représentation d’un objet, calculée à partir de sa méthode spéciale __repr__.
>>> john.__repr__()
'<__main__.User object at 0x7fefd77fae10>'
À noter qu’une méthode spéciale n’est presque jamais directement appelée en Python, on lui préférera dans le cas présent la fonction builtin repr.
>>> repr(john)
'<__main__.User object at 0x7fefd77fae10>'
Il nous suffit alors de redéfinir cette méthode __repr__ pour bénéficier de notre propre représentation.
>>> class User:
... def __repr__(self):
... return '<User: {}, {}>'.format(self.id, self.name)
>>> User(1, 'john', '12345')
<User: 1, john>
Une autre opération courante est la conversion de notre objet en chaîne de caractères afin d’être affiché via print par exemple. Par défaut, la conversion en chaîne correspond à la représentation de l’objet, mais elle peut être surchargée par la méthode __str__.
>>> class User:
...
... def __repr__(self):
... return '<User: {}, {}>'.format(self.id, self.name)
...
... def __str__(self):
... return '{}-{}'.format(self.id, self.name)
>>> john = User(1, 'john', 12345)
>>> john
<User: 1, john>
>>> repr(john)
'<User: 1, john>'
>>> str(john)
'1-john'
>>> print(john)
1-john
Exemple :
>>> class Fraction:
... def __init__(self, num, den):
... self.__num = num
... self.__den = den
...
... def resultat(self):
... return 1/2
...
... def __str__(self):
... return str(self.resultat())
...
... def __repr__(self):
... return str(self.__num) + '/' + str(self.__den)
>>> f = Fraction(1,2)
>>> f.resultat()
0.5
>>> print(f)
>>> print('Valeur numérique de ma fraction : ' + str(f))
Valeur numérique de ma fraction : 0.5
>>> print('Représentation de ma fraction : ', repr(f))
Représentation de ma fraction : 1/2
Exercice :
>>> from math import *
>>> class Racine:
... def __init__(self, valeur):
... self.__valeur = valeur
...
... def resultat(self):
... return sqrt(self.__valeur)
...
... def __str__(self):
... return str(self.resultat())
...
... def __repr__(self):
... return '√' + str(self.__valeur)
...
>>> nombre = Racine(2)
>>> nombre.resultat()
1.4142135623730951
>>> print(nombre)
1.4142135623730951
>>> repr(nombre)
'√2'
Variables privées, l’encapsulation#
Au commencement étaient les invariants
Les différents attributs de notre objet forment un état de cet objet, normalement stable. Ils sont en effet liés les uns aux autres, la modification d’un attribut pouvant avoir des conséquences sur un autre. Les invariants correspondent aux relations qui lient ces différents attributs.
Imaginons que nos objets User soient dotés d’un attribut contenant une évaluation du mot de passe (savoir si ce mot de passe est assez sécurisé ou non), il doit alors être mis à jour chaque fois que nous modifions l’attribut password d’un objet User.
Dans le cas contraire, le mot de passe et l’évaluation ne seraient plus corrélés, et notre objet User ne serait alors plus dans un état stable. Il est donc important de veiller à ces invariants pour assurer la stabilité de nos objets.
Protège-moi
Au sein d’un objet, les attributs peuvent avoir des sémantiques différentes. Certains attributs vont représenter des propriétés de l’objet et faire partie de son interface (tels que le prénom et le nom de nos objets User). Ils pourront alors être lus et modifiés depuis l’extérieur de l’objet, on parle dans ce cas d’attributs publics.
D’autres vont contenir des données internes à l’objet, n’ayant pas vocation à être accessibles depuis l’extérieur. Nous allons sécuriser notre stockage du mot de passe en ajoutant une méthode pour le hasher (à l’aide du module crypt), afin de ne pas stocker d’informations sensibles dans l’objet. Ce condensat du mot de passe ne devrait pas être accessible de l’extérieur, et encore moins modifié (ce qui en altérerait la sécurité).
De la même manière que pour les attributs, certaines méthodes vont avoir une portée publique et d’autres privée (on peut imaginer une méthode interne de la classe pour générer notre identifiant unique). On nomme encapsulation cette notion de protection des attributs et méthodes d’un objet, dans le respect de ses invariants.
Certains langages implémentent dans leur syntaxe des outils pour gérer la visibilité des attributs et méthodes, mais il n’y a rien de tel en Python. Il existe à la place des conventions, qui indiquent aux développeurs quels attributs/méthodes sont publics ou privés. Quand vous voyez un nom d’attribut ou méthode débuter par un «_» au sein d’un objet, il indique quelque chose d’interne à l’objet (privé), dont la modification peut avoir des conséquences graves sur la stabilité.
>>> import crypt
>>> class User:
... def __init__(self, id, name, password):
... self.id = id
... self.name = name
... self._salt = crypt.mksalt() # sel utilisé pour le hash du mot de passe
... self._password = self._crypt_pwd(password)
...
... def _crypt_pwd(self, password):
... return crypt.crypt(password, self._salt)
...
... def check_pwd(self, password):
... return self._password == self._crypt_pwd(password)
...
>>> john = User(1, 'john', '12345')
>>> john.check_pwd('12345')
True
On note toutefois qu’il ne s’agit que d’une convention, l’attribut _password étant parfaitement visible depuis l’extérieur.
>>> john._password
'$6$DwdvE5H8sT71Huf/$9a.H/VIK4fdwIFdLJYL34yml/QC3KZ7'
Il reste possible de masquer un peu plus l’attribut à l’aide du préfixe __. Ce préfixe a pour effet de renommer l’attribut en y insérant le nom de la classe courante.
>>> class User:
... def __init__(self, id, name, password):
... self.id = id
... self.name = name
... self.__salt = crypt.mksalt()
... self.__password = self.__crypt_pwd(password)
...
... def __crypt_pwd(self, password):
... return crypt.crypt(password, self.__salt)
...
... def check_pwd(self, password):
... return self.__password == self.__crypt_pwd(password)
>>> john = User(1, 'john', '12345')
>>> john.__password
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'User' object has no attribute '__password'
>>> john._User__password
'$6$kjwoqPPHRQAamRHT$591frrNfNNb3.RdLXYiB/bgdCC4Z0p.B'
Ce comportement pourra surtout être utile pour éviter des conflits de noms entre attributs internes de plusieurs classes sur un même objet, que nous verrons lors de l’héritage.
Le hashage d’un mot de passe correspond à une opération non-réversible qui permet de calculer un condensat (hash) du mot de passe. Ce condensat peut-être utilisé pour vérifier la validité d’un mot de passe, mais ne permet pas de retrouver le mot de passe d’origine.
C++, Java, Ruby, etc.
Duck-typing#
Un objet en Python est défini par sa structure (les attributs qu’il contient et les méthodes qui lui sont applicables) plutôt que par son type.
Ainsi, pour faire simple, un fichier sera un objet possédant des méthodes read, write et close. Tout objet respectant cette définition sera considéré par Python comme un fichier.
class FakeFile:
def read(self, size=0):
return ''
def write(self, s):
return 0
def close(self):
pass
f = FakeFile()
print('foo', file=f)
Python est entièrement construit autour de cette idée, appelée duck-typing : «Si je vois un animal qui vole comme un canard, cancane comme un canard, et nage comme un canard, alors j’appelle cet oiseau un canard» (James Whitcomb Riley)
Exercice :
Pour ce premier exercice, nous allons nous intéresser aux classes d’un forum. Forts de notre type User pour représenter un utilisateur, nous souhaitons ajouter une classe Post, correspondant à un quelconque message.
Cette classe sera inititalisée avec un auteur (un objet User) et un contenu textuel (le corps du message). Une date sera de plus générée lors de la création.
Un Post possèdera une méthode format pour retourner le message formaté, correspondant au HTML suivant :
<div>
<span>Par NOM_DE_L_AUTEUR le DATE_AU_FORMAT_JJ_MM_YYYY à HEURE_AU_FORMAT_HH_MM_SS</span>
<p>
CORPS_DU_MESSAGE
</p>
</div>
De plus, nous ajouterons une méthode post à notre classe User, recevant un corps de message en paramètre et retournant un nouvel objet Post.
import crypt
import datetime
class User:
def __init__(self, id, name, password):
self.id = id
self.name = name
self._salt = crypt.mksalt()
self._password = self._crypt_pwd(password)
def _crypt_pwd(self, password):
return crypt.crypt(password, self._salt)
def check_pwd(self, password):
return self._password == self._crypt_pwd(password)
def post(self, message):
return Post(self, message)
class Post:
def __init__(self, author, message):
self.author = author
self.message = message
self.date = datetime.datetime.now()
def format(self):
date = self.date.strftime('le %d/%m/%Y à %H:%M:%S')
return '<div><span>Par {} {}</span><p>{}</p></div>'.format(self.author.name, date, self.message)
if __name__ == '__main__':
user = User(1, 'john', '12345')
p = user.post('Salut à tous')
print(p.format())
Nous savons maintenant définir une classe et ses méthodes, initialiser nos objets, et protéger les noms d’attributs/méthodes.
Mais jusqu’ici, quand nous voulons étendre le comportement d’une classe, nous la redéfinissons entièrement en ajoutant de nouveaux attributs/méthodes. Le chapitre suivant présente l’héritage, un concept qui permet d’étendre une ou plusieurs classes sans toucher au code initial.
Documenter les classes d’objets#
Maintenant qu’on sait documenter une fonction, documentons une classe d’objets.
Exemple de documentation d’une classe MaClasse dans un module mon_module d’un paquet mon_paquet :
# -*- coding: utf-8 -*-
"""
.. sectionauthor:: Stagiaire ADMINISTRATEUR <stagiaire.administrateur@fai.fr>
:mod:`mon_module` -- Module d'exemple de documentation d'une classe
###################################################################
.. module:: mon_paquet.mon_module
:platform: Linux
:synopsis: Ce module illustre comment écrire votre docstring pour une classe dans Python.
.. moduleauthor:: Formateur PYTHON <formateur.python@fai.fr>
.. moduleauthor:: Stagiaire ADMINISTRATEUR <stagiaire.administrateur@fai.fr>
"""
__title__ = "Module illustration écriture docstring d'une classe Python"
__author__ = "Formateur PYTHON"
__version__ = '0.7.3'
__release_life_cycle__ = 'alpha'
# pre-alpha = faisabilité, alpha = développement, beta = test, rc = qualification, prod = production
__docformat__ = 'reStructuredText'
class MaClasse():
"""
Exemple de classe de mon_paquet.mon_module
:param arg: argument du constructeur MaClasse
:type arg: int
"""
def __init__(self, arg):
"""
Constructeur de MaClasse
Les propriétés de la classe sont :
:param param: p1
:type param: int
"""
self.p1 = None
def bonjour(self, nom):
"""
Permet d'afficher le message « Bonjour à toi <nom> »
:param nom: Nom de la personne
:type nom: str
:return: Message de bonjour
:rtype: str:
"""
print("Bonjour " + nom)
return "Bonjour à toi " + nom
if __name__ == "__main__":
mon_objet = MaClasse()
print mon_objet.bonjour("padawan")
Finalement, il n’y a rien de bien nouveau. On a documenté les méthodes de la classe MaClasse comme on l’a fait avec les fonctions.
La seule différence c’est avec la méthode constructeur __init__ de la classe MaClasse où la docstring des paramètres de classe est directement dans la déclaration de la classe (:param arg: argument du constructeur MaClasse et :type arg: int).
C’est le fonctionnement par défaut avec autodoc.
Cette disposition permet de séparer la déclaration des propriétés de la classe, qui sont définies dans la méthode __init__, avec les paramètres de création d’objets de la classe MaClasse qui sont définis dans la déclaration des paramètres de la méthode __init__.
Ce comportement est réglable via une option autoclass_content = 'configuration' dans le fichier «conf.py».
Si vous préférez documenter avec le constructeur __init__ les paramètres de création d’objet avec les propriétés de la classe, ce paramètre vous permet de définir comment seront insérés les paramètres de la classe avec «autoclass». Exemple pour que cela soit avec la déclaration de propriétés dans __init__ :
autoclass_content = 'init'
Les valeurs possibles sont :
« class » : Seule la docstring de la classe est insérée. C’est la valeur par défaut. Vous pouvez toujours documenter
__init__en tant que méthode distincte en utilisant «automethod» ou l’option «members» pour générer automatique la documentation de vos classes.« both » : La docstring de la classe et de la méthode
__init__sont concaténées et insérées.« init » : Seule la docstring de la méthode
__init__est insérée.
Avertissement
Si la classe n’a pas de méthode __init__, ou si la docstring de la méthode __init__ est vide, et que la classe a une docstring avec la méthode __new__ celle-ci sera utilisée à la place.
Nous avons maintenant abordé l’essentiel pour commencer une rédaction complète de sa documentation du code Python. Vous pouvez encore approfondir avec plein de directives Sphinx utiles avec ce lien.
Notions avancées en objet#
Extension de classes#
Nous allons nous intéresser à l’extension de classes.
Imaginons que nous voulions définir une classe Admin, pour gérer des administrateurs, qui réutiliserait le même code que la classe User. Tout ce que nous savons faire actuellement c’est copier/coller le code de la classe User en changeant son nom pour Admin.
Nous allons maintenant voir comment faire ça de manière plus élégante, grâce à l’héritage. Nous étudierons de plus les relations entre classes ansi créées.
Nous utiliserons donc la classe User suivante pour la suite de ce chapitre.
class User:
""" Défini des propriétés d'un utilisateur """
def __init__(self, id, name, password):
""" Initialisation de l'utilisateur """
self.id = id
self.name = name
self._salt = crypt.mksalt()
self._password = self._crypt_pwd(password)
def _crypt_pwd(self, password):
""" Calcule un mot de passe crypté """
return crypt.crypt(password, self._salt)
def check_pwd(self, password):
""" Vérifie le mot de passe """
return self._password == self._crypt_pwd(password)
Hériter#
L’héritage simple est le mécanisme permettant d’étendre une unique classe. Il consiste à créer une nouvelle classe (fille) qui bénéficiera des mêmes méthodes et attributs que sa classe mère. Il sera aisé d’en définir de nouveaux dans la classe fille, et cela n’altèrera pas le fonctionnement de la mère.
Par exemple, nous voudrions étendre notre classe User pour ajouter la possibilité d’avoir des administrateurs. Les administrateurs (Admin) possèderaient une nouvelle méthode, manage, pour administrer le système.
class Admin(User):
""" Défini des propriétés d'un administrateur """
def manage(self):
""" Ajoute des fonctions d'administrateur """
print('Je suis un Jedi!')
En plus des méthodes de la classe User (__init__, _crypt_pwd et check_pwd), Admin possède aussi une méthode manage.
>>> root = Admin(1, 'root', 'toor')
>>> root.check_password('toor')
True
>>> root.manage()
Je suis un Jedi!
>>> john = User(2, 'john', '12345')
>>> john.manage()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'User' object has no attribute 'manage'
Nous pouvons avoir deux classes différentes héritant d’une même mère
class Guest(User):
pass
Admin et Guest sont alors deux classes filles de User.
L’héritage simple permet aussi d’hériter d’une classe qui hérite elle-même d’une autre classe.
class SuperAdmin(Admin):
pass
SuperAdmin est alors la fille de Admin, elle-même la fille de User. On dit alors que User est une ancêtre de SuperAdmin.
On peut constater quels sont les parents d’une classe à l’aide de l’attribut spécial __bases__ des classes :
>>> Admin.__bases__
(<class '__main__.User'>,)
>>> Guest.__bases__
(<class '__main__.User'>,)
>>> SuperAdmin.__bases__
(<class '__main__.Admin'>,)
Que vaudrait alors User.__bases__, sachant que la classe User est définie sans héritage ?
>>> User.__bases__
(<class 'object'>,)
On remarque que, sans que nous n’ayons rien demandé, User hérite de object. En fait, object est l’ancêtre de toute classe Python. Ainsi, quand aucune classe parente n’est définie, c’est object qui est choisi.
Sous-typage#
Nous avons vu que l’héritage permettait d’étendre le comportement d’une classe, mais ce n’est pas tout. L’héritage a aussi du sens au niveau des types, en créant un nouveau type compatible avec le parent.
En Python, la fonction isinstance permet de tester si un objet est l’instance d’une certaine classe.
>>> isinstance(root, Admin)
True
>>> isinstance(root, User)
True
>>> isinstance(root, Guest)
False
>>> isinstance(root, object)
True
Mais gardez toujours à l’esprit qu’en Python, on préfère se référer à la structure d’un objet qu’à son type (duck-typing), les tests à base de isinstance sont donc à utiliser pour des cas particuliers uniquement, où il serait difficile de procéder autrement.
Redéfinition de méthodes, la surcharge#
Nous savons hériter d’une classe pour y insérer de nouvelles méthodes, mais nous ne savons pas étendre les méthodes déjà présentes dans la classe mère. La redéfinition est un concept qui permet de remplacer une méthode du parent.
Nous voudrions que la classe Guest ne possède plus aucun mot de passe. Celle-ci devra modifier la méthode check_pwd pour accepter tout mot de passe, et simplifier la méthode __init__.
On ne peut pas à proprement parler étendre le contenu d’une méthode, mais on peut la redéfinir :
class Guest(User):
def __init__(self, id, name):
self.id = id
self.name = name
self._salt = ''
self._password = ''
def check_pwd(self, password):
return True
Cela fonctionne comme souhaité, mais vient avec un petit problème, le code de la méthode __init__ est répété. En l’occurrence il ne s’agit que de 2 lignes de code, mais lorsque nous voudrons apporter des modifications à la méthode de la classe User, il faudra les répercuter sur Guest, ce qui donne vite quelque chose de difficile à maintenir.
Heureusement, Python nous offre un moyen de remédier à ce mécanisme, super! Oui, super, littéralement, une fonction un peu spéciale en Python, qui nous permet d’utiliser la classe parente (superclass).
super est une fonction qui prend initialement en paramètre une classe et une instance de cette classe. Elle retourne un objet proxy (Un proxy est un intermédiaire transparent entre deux entités) qui s’utilise comme une instance de la classe parente.
>>> guest = Guest(3, 'Guest')
>>> guest.check_pwd('password')
True
>>> super(Guest, guest).check_pwd('password')
False
Au sein de la classe en question, les arguments de super peuvent être omis (ils correspondront à la classe et à l’instance courantes), ce qui nous permet de simplifier notre méthode __init__ et d’éviter les répétitions.
class Guest(User):
def __init__(self, id, name):
super().__init__(id, name, '')
def check_pwd(self, password):
return True
On notera tout de même que contrairement aux versions précédentes, l’initialisateur de User est appelé en plus de celui de Guest, et donc qu’un self et un hash du mot de passe sont générés alors qu’ils ne serviront pas.
Ça n’est pas très grave dans le cas présent, mais pensez-y dans vos développements futurs, afin de ne pas exécuter d’opérations coûteuses inutilement.
Héritage Conditionnel#
Il nous arrive souvent en Python d’être bloqué, lors de la création d’une classe, parce que l’héritage est conditionné à une variable passée en paramètre de la classe.
Se présente alors deux cas :
Le premier est un comportement de classe complètement différent avec ses méthodes et propriétés, c’est un proxy (filtre) de classes qu’il nous faudra utiliser.
Le deuxième est un ajout de propriétés et de méthodes à la classe avec un vrai héritage conditionnel.
Nous allons voir comment résoudre cela avec la déclaration de classe def __new__()
Proxy de classes#
Dans cet exercice, nous allons créer deux classes distinctes (A et B) qui suivant un paramètre passé à une métaclasse Proxy va retourner la bonne classe.
class A:
def __init__(self, mon_paramètreA):
self.ma_propriétéA = mon_paramètreA
def maMéthodeA(self):
pass
class B:
def __init__(self, mon_paramètreB):
self.ma_propriétéB = mon_paramètreB
def maMéthodeB(self):
pass
class Proxy:
def __new__(cls, mon_paramètre):
if mon_paramètre == 'valeur1':
return A(mon_paramètre)
if mon_paramètre == 'valeur2':
return B(mon_paramètre)
Nous voyons ici que la déclaration def __new__() nous permet de récupérer les paramètres passés à la classe Proxy, ce qui nous permet avec un test de renvoyer un objet créé avec la bonne classe. C’est pour cela que l’on parle de Proxy de classe. Le paramètre cls représente la classe qui a besoin d’être instanciée.
On peut bien sur changer les conditions de filtrage suivant le type de test que l’on veut, ou augmenter le nombre de classes en option. Mais ici dans cette section nous parlons d’héritage de classe, nous allons voir avec ce procédé comment créer un héritage conditionnel.
Héritage conditionnel#
Nous introduisons ici un nouveau concept pour les héritages, l’héritage conditionnel de classes ClasseAHeriter if mon_paramètre == 'Valeur' else object. La difficulté de la solution vient du fait que la variable passée à la classe ne peut être récupérée avant l’héritage de classe, mon_paramètre doit donc être global pour que la condition d’héritage fonctionne. Avec le proxy nous outrepassons cette limite de façon élégante…
Ici dans cet exercice, nous allons créer un héritage conditionnel de la classe A dans la classe B suivant un paramètre passé au travers de la classe proxy ProxyHeritage.
class A:
def __init__(self, mon_paramètreA):
self.ma_propriétéA = mon_paramètreA
def maMéthodeA(self):
pass
class ProxyHeritage:
def __new__(cls, mon_paramètre):
class B(A if mon_paramètre == 'Valeur' else object):
def __init__(self, mon_paramètreB):
self.ma_propriétéB = mon_paramètreB
def maMéthodeB(self):
pass
return B(mon_paramètre)
Cette solution n’est pas satisfaisante. En effet si on veut hériter la classe ProxyHeritage le comportement de gestion des héritages de classes normal de Python n’est plus possible. Nous verrons plus loin dans ce cour comment faire.
Tout ceci nous permet maintenant d’introduire la section suivante.
Héritages Multiples#
Avec l’héritage simple, nous pouvions étendre le comportement d’une classe. L’héritage multiple va nous permettre de le faire pour plusieurs classes à la fois. Il nous suffit de préciser plusieurs classes séparées par des virgules lors de la création de notre classe fille.
class A:
def foo(self):
return '!'
class B:
def bar(self):
return '?'
class C(A, B):
pass
Notre classe C a donc deux mères : A et B. Cela veut aussi dire que les objets de type C possèdent à la fois les méthodes foo et bar.
>>> c = C()
>>> c.foo()
'!'
>>> c.bar()
'?'
Ordre d’héritage#
L’ordre dans lequel on hérite des parents est important, il détermine dans quel ordre les méthodes seront recherchées dans les classes mères. Ainsi, dans le cas où la méthode existe dans plusieurs parents, celle de la première classe sera conservée.
class A:
def foo(self):
return '!'
class B:
def foo(self):
return '?'
class C(A, B):
pass
class D(B, A):
pass
>>> C().foo()
'!'
>>> D().foo()
'?'
Cet ordre dans lequel les classes parentes sont explorées pour la recherche des méthodes est appelé Method Resolution Order (MRO). On peut le connaître à l’aide de la méthode mro des classes.
>>> A.mro()
[<class '__main__.A'>, <class 'object'>]
>>> B.mro()
[<class '__main__.B'>, <class 'object'>]
>>> C.mro()
[<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>, <class 'object'>]
>>> D.mro()
[<class '__main__.D'>, <class '__main__.B'>, <class '__main__.A'>, <class 'object'>]
C’est aussi ce MRO qui est utilisé par super pour trouver à quelle classe faire appel. super se charge d’explorer le MRO de la classe de l’instance qui lui est donnée en second paramètre, et de retourner un proxy sur la classe juste à droite de celle donnée en premier paramètre.
Ainsi, avec c une instance de C, :python`super(C, c)` retournera un objet se comportant comme une instance de A, super(A, c) comme une instance de B, et super(B, c) comme une instance de object.
>>> c = C()
>>> c.foo() # C.foo == A.foo
'!'
>>> super(C, c).foo() # A.foo
'!'
>>> super(A, c).foo() # B.foo
'?'
>>> super(B, c).foo() # object.foo -> méthode introuvable
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'super' object has no attribute 'foo'
Les classes parentes n’ont alors pas besoin de se connaître les unes les autres pour se référencer.
class A:
def __init__(self):
print("Début initialisation d'un objet de type A")
super().__init__()
print("Fin initialisation d'un objet de type A")
class B:
def __init__(self):
print("Début initialisation d'un objet de type B")
super().__init__()
print("Fin initialisation d'un objet de type B")
class C(A, B):
def __init__(self):
print("Début initialisation d'un objet de type C")
super().__init__()
print("Fin initialisation d'un objet de type C")
class D(B, A):
def __init__(self):
print("Début initialisation d'un objet de type D")
super().__init__()
print("Fin initialisation d'un objet de type D")
>>> C()
Début initialisation d'un objet de type C
Début initialisation d'un objet de type A
Début initialisation d'un objet de type B
Fin initialisation d'un objet de type B
Fin initialisation d'un objet de type A
Fin initialisation d'un objet de type C
<__main__.C object at 0x7f0ccaa970b8>
>>> D()
Début initialisation d'un objet de type D
Début initialisation d'un objet de type B
Début initialisation d'un objet de type A
Fin initialisation d'un objet de type A
Fin initialisation d'un objet de type B
Fin initialisation d'un objet de type D
<__main__.D object at 0x7f0ccaa971d0>
La méthode __init__ des classes parentes n’est pas appelée automatiquement, et l’appel doit donc être réalisé explicitement.
C’est ainsi le super().__init__() présent dans la classe C qui appelle l’initialiseur de la classe A, qui appelle lui-même celui de la classe B. Inversement, pour la classe D, super().__init__() appelle l’initialiseur de B qui appelle celui de A.
On notera que les exemple donnés n’utilisent jamais plus de deux classes mères, mais il est possible d’en avoir autant que vous le souhaitez.
class A:
pass
class B:
pass
class C:
pass
class D:
pass
class E(A, B, C, D):
pass
Mixins#
Les mixins sont des classes dédiées à une fonctionnalité particulière, utilisable en héritant d’une classe de base et de ce mixin.
Par exemple, plusieurs types que l’on connaît sont appelés séquences (str, list, tuple). Ils ont en commun le fait d’implémenter l’opérateur [] et de gérer le slicing. On peut ainsi obtenir l’objet en ordre inverse à l’aide de obj[::-1].
Un mixin qui pourrait nous être utile serait une classe avec une méthode reverse pour nous retourner l’objet inversé.
class Reversable:
def reverse(self):
return self[::-1]
class ReversableStr(Reversable, str):
pass
class ReversableTuple(Reversable, tuple):
pass
>>> s = ReversableStr('abc')
>>> s
'abc'
>>> s.reverse()
'cba'
>>> ReversableTuple((1, 2, 3)).reverse()
(3, 2, 1)
Ou encore nous pourrions vouloir ajouter la gestion d’une photo de profil à nos classes User et dérivées.
class ProfilePicture:
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.picture = '{}-{}.png'.format(self.id, self.name)
class UserPicture(ProfilePicture, User):
pass
class AdminPicture(ProfilePicture, Admin):
pass
class GuestPicture(ProfilePicture, Guest):
pass
>>> john = UserPicture(1, 'john', '12345')
>>> john.picture
'1-john.png'
Exercice : Fils de discussion
Vous vous souvenez de la classe Post pour représenter un message ? Nous aimerions maintenant pouvoir instancier des fils de discussion (Thread) sur notre forum.
Qu’est-ce qu’un fil de discussion ?
Un message associé à un auteur et à une date ;
Mais qui comporte aussi un titre ;
Et une liste de posts (les réponses).
Le premier point indique clairement que nous allons réutiliser le code de la classe Post, donc en hériter.
Notre nouvelle classe sera initialisée avec un titre, un auteur et un message. Thread sera dotée d’une méthode answer recevant un auteur et un texte, et s’occupant de créer le post correspondant et de l’ajouter au fil. Nous changerons aussi la méthode format du Thread afin qu’elle concatène au fil l’ensemble de ses réponses.
La classe Post restera inchangée. Enfin, nous supprimerons la méthode post de la classe User, pour lui en ajouter deux nouvelles :
new_thread(title, message)pour créer un nouveau fil de discussion associé à cet utilisateur ;answer_thread(thread, message)pour répondre à un fil existant.
import crypt
import datetime
class User:
def __init__(self, id, name, password):
self.id = id
self.name = name
self._salt = crypt.mksalt()
self._password = self._crypt_pwd(password)
def _crypt_pwd(self, password):
return crypt.crypt(password, self._salt)
def check_pwd(self, password):
return self._password == self._crypt_pwd(password)
def new_thread(self, title, message):
return Thread(title, self, message)
def answer_thread(self, thread, message):
thread.answer(self, message)
class Post:
def __init__(self, author, message):
self.author = author
self.message = message
self.date = datetime.datetime.now()
def format(self):
date = self.date.strftime('le %d/%m/%Y à %H:%M:%S')
return '<div><span>Par {} {}</span><p>{}</p></div>'.format(self.author.name, date, self.message)
class Thread(Post):
def __init__(self, title, author, message):
super().__init__(author, message)
self.title = title
self.posts = []
def answer(self, author, message):
self.posts.append(Post(author, message))
def format(self):
posts = [super().format()]
posts += [p.format() for p in self.posts]
return '\n'.join(posts)
if __name__ == '__main__':
john = User(1, 'john', '12345')
peter = User(2, 'peter', 'toto')
thread = john.new_thread('Bienvenue', 'Bienvenue à tous')
peter.answer_thread(thread, 'Merci')
print(thread.format())
L’héritage conditionnel#
Nous revenons ici sur le traitement des héritages conditionnels déjà abordés.
Avec init()#
Pour optimiser notre code, et la réutilisation de classes, nous voulons pouvoir avoir un héritage conditionnel lors de l’initialisation de nos objets. Nous voulons donc utiliser la méthode __init__ pour le faire. Nous allons aussi avoir la possibilité de supprimer une méthode héritée avec des paramètres passés à la classe.
Voici un exemple de comment le faire avec le fichier «heritageconditionnel.py» :
class Pere():
def __init__(self, **kwargs):
self.mapropriété_père = 'mapropriété_père'
if 'paramètrePère' in kwargs and kwargs['paramètrePère']:
self.mapropriété_conditionnellepère = 'mapropriété_conditionnellepère'
def ma_Methode_Conditionnelle_Père():
return self.mapropriété_conditionnellepère
self.ma_Methode_Conditionnelle_Père = ma_Methode_Conditionnelle_Père
def ma_Methode_Père(self):
return self.mapropriété_père
class Enfant(Pere):
def __init__(self, **kwargs):
Pere.__init__(Pere, **kwargs)
if 'paramètreEnfant' in kwargs and kwargs['paramètreEnfant']:
self.mapropriété_conditionnelleenfant = 'mapropriété_conditionnelleenfant'
def ma_Methode_Conditionnelle_Enfant():
return self.mapropriété_conditionnelleenfant
self.ma_Methode_Conditionnelle_Enfant = ma_Methode_Conditionnelle_Enfant
class new_parent(Pere.__base__):
pass
parent_list = dir(Pere)
new_parent_list = dir(new_parent)
if 'paramètrePère' in kwargs and kwargs['paramètrePère']:
methodes = set(parent_list) - set(new_parent_list)
else:
methodes = set(parent_list) - set(new_parent_list) - {'mapropriété_conditionnellepère', 'ma_Methode_Conditionnelle_Père'}
if 'banieméthodes' in kwargs and kwargs['banieméthodes'] != []:
for methode in methodes:
if methode not in kwargs['banieméthodes']:
setattr(new_parent, methode, Pere.__getattribute__(Pere, methode))
else:
for methode in methodes:
setattr(new_parent, methode, Pere.__getattribute__(Pere, methode))
Enfant.__bases__ = (new_parent, )
self.mapropriété_enfant = 'mapropriété_enfant'
def ma_Methode_Enfant(self):
return self.mapropriété_enfant
class PetitEnfant(Enfant):
def __init__(self, paramètrePetitEnfant=False, paramètreEnfant=False, options=[], paramètrePère=False):
super().__init__(paramètreEnfant=paramètreEnfant, banieméthodes=options, paramètrePère=paramètrePère)
self.mapropriétépetitenfant = 'mapropriétépetitenfant'
if paramètrePetitEnfant:
self.mapropriété_conditionnellepetitenfant = 'mapropriété_conditionnellepetitenfant'
def ma_Methode_Conditionnelle_PetitEnfant():
return self.mapropriété_conditionnellepetitenfant
self.ma_Methode_Conditionnelle_PetitEnfant = ma_Methode_Conditionnelle_PetitEnfant
def ma_Methode_PetitEnfant(self):
return self.mapropriétépetitenfant
if __name__ == '__main__':
class Vide():
pass
vide = Vide()
vide_list = set(dir(vide))
print('Pere()')
a = Pere()
a_list = set(dir(a))
print(str(a_list - vide_list))
print('Pere(paramètrePère=True)')
a = Pere(paramètrePère=True)
a_list = set(dir(a))
print(str(a_list - vide_list))
print('Enfant()')
b = Enfant()
b_list = set(dir(b))
print(str(b_list - vide_list))
print('Enfant(paramètrePère=True)')
b = Enfant(paramètrePère=True)
b_list = set(dir(b))
print(str(b_list - vide_list))
print('Enfant(banieméthodes=[\'ma_Methode_Père\'])')
b = Enfant(banieméthodes=['ma_Methode_Père'])
b_list = set(dir(b))
print(str(b_list - vide_list))
print('Enfant(paramètreEnfant=True)')
b = Enfant(paramètreEnfant=True)
b_list = set(dir(b))
print(str(b_list - vide_list))
print('Enfant(paramètreEnfant=True, paramètrePère=True)')
b = Enfant(paramètreEnfant=True, paramètrePère=True)
b_list = set(dir(b))
print(str(b_list - vide_list))
print('Enfant(paramètreEnfant=True, paramètrePère=True, banieméthodes=[\'ma_Methode_Père\'])')
b = Enfant(paramètreEnfant=True, paramètrePère=True, banieméthodes=['ma_Methode_Père'])
b_list = set(dir(b))
print(str(b_list - vide_list))
print('PetitEnfant()')
c = PetitEnfant()
c_list = set(dir(c))
print(str(c_list - vide_list))
print('PetitEnfant(paramètrePère=True)')
c = PetitEnfant(paramètrePère=True)
c_list = set(dir(c))
print(str(c_list - vide_list))
print('PetitEnfant(options=[\'ma_Methode_Père\']')
c = PetitEnfant(options=['ma_Methode_Père'])
c_list = set(dir(c))
print(str(c_list - vide_list))
print('PetitEnfant(paramètreEnfant=True)')
c = Enfant(paramètreEnfant=True)
c_list = set(dir(c))
print(str(c_list - vide_list))
print('PetitEnfant(paramètrePetitEnfant=True)')
c = PetitEnfant(paramètrePetitEnfant=True)
c_list = set(dir(c))
print(str(c_list - vide_list))
Ce qui nous donne en sortie d’exécution
utilisateur@MachineUbuntu:~/repertoire_de_developpement/9_objets$ python3 ./heritageconditionnel.py
Pere()
{'ma_Methode_Père', 'mapropriété_père'}
Pere(paramètrePère=True)
{'mapropriété_conditionnellepère', 'ma_Methode_Père', 'mapropriété_père', 'ma_Methode_Conditionnelle_Père'}
Enfant()
{'ma_Methode_Enfant', 'ma_Methode_Père', 'mapropriété_enfant', 'mapropriété_père'}
Enfant(paramètrePère=True)
{'ma_Methode_Enfant', 'ma_Methode_Père', 'mapropriété_père', 'ma_Methode_Conditionnelle_Père', 'mapropriété_conditionnellepère', 'mapropriété_enfant'}
Enfant(banieméthodes=['ma_Methode_Père'])
{'ma_Methode_Enfant', 'mapropriété_enfant', 'mapropriété_père'}
Enfant(paramètreEnfant=True)
{'ma_Methode_Enfant', 'ma_Methode_Père', 'mapropriété_père', 'mapropriété_conditionnelleenfant', 'mapropriété_enfant', 'ma_Methode_Conditionnelle_Enfant'}
Enfant(paramètreEnfant=True, paramètrePère=True)
{'ma_Methode_Enfant', 'ma_Methode_Père', 'mapropriété_père', 'ma_Methode_Conditionnelle_Père', 'mapropriété_conditionnelleenfant', 'mapropriété_conditionnellepère', 'mapropriété_enfant', 'ma_Methode_Conditionnelle_Enfant'}
Enfant(paramètreEnfant=True, paramètrePère=True, banieméthodes=['ma_Methode_Père'])
{'ma_Methode_Enfant', 'mapropriété_père', 'ma_Methode_Conditionnelle_Père', 'mapropriété_conditionnelleenfant', 'mapropriété_conditionnellepère', 'mapropriété_enfant', 'ma_Methode_Conditionnelle_Enfant'}
PetitEnfant()
{'ma_Methode_Enfant', 'ma_Methode_Père', 'mapropriété_père', 'mapropriétépetitenfant', 'mapropriété_enfant', 'ma_Methode_PetitEnfant'}
PetitEnfant(paramètrePère=True)
{'ma_Methode_Enfant', 'ma_Methode_Père', 'mapropriété_père', 'ma_Methode_Conditionnelle_Père', 'mapropriété_conditionnellepère', 'mapropriétépetitenfant', 'mapropriété_enfant', 'ma_Methode_PetitEnfant'}
PetitEnfant(options=['ma_Methode_Père']
{'ma_Methode_Enfant', 'mapropriété_père', 'mapropriétépetitenfant', 'mapropriété_enfant', 'ma_Methode_PetitEnfant'}
PetitEnfant(paramètreEnfant=True)
{'ma_Methode_Enfant', 'ma_Methode_Père', 'mapropriété_père', 'mapropriété_conditionnelleenfant', 'mapropriété_enfant', 'ma_Methode_Conditionnelle_Enfant'}
PetitEnfant(paramètrePetitEnfant=True)
{'ma_Methode_Enfant', 'ma_Methode_Père', 'mapropriété_conditionnellepetitenfant', 'mapropriété_père', 'mapropriétépetitenfant', 'mapropriété_enfant', 'ma_Methode_Conditionnelle_PetitEnfant', 'ma_Methode_PetitEnfant'}
Avec new()#
Chaque fois qu’une classe est instanciée, les méthodes __new__ et __init__ sont appelées.
On sait déjà que la méthode __init__ sera appelée pour initialiser l’objet. La méthode __new__ sera elle appelée lors de la création d’un objet, son instanciation.
Dans l’objet de classe de base, la méthode __new__ est définie comme une méthode statique qui nécessite de passer un paramètre cls. cls représente la classe qui doit être instanciée et le compilateur fournit automatiquement ce paramètre au moment de l’instanciation.
Nous pouvons alors modifier directement la classe cls, mais les modifications seront prises en compte par tous les objets actifs l’utilisant. Pour éviter cela nous travaillerons donc directement avec l’instance de la classe que l’on obtiendra avec super(MaClasse, cls).__new__(cls, *args, **kwargs).
Nous allons donc filtrer l’héritage de nos classes sur l’instance de l’objet avec la méthode __new__. Comme précédemment nous allons aussi supprimer une méthode héritée.
Voici un exemple de comment le faire avec le fichier «heritageconditionnelnew.py» :
class Pere():
def __new__(cls, *args, **kwargs):
newclass = super(Pere, cls).__new__(cls)
if 'paramètrePère' in kwargs.keys():
if kwargs['paramètrePère']:
setattr(newclass, 'mapropriété_conditionnellepère', None)
def ma_Methode_Conditionnelle_Père():
return newclass.mapropriété_conditionnellepère
setattr(newclass, ma_Methode_Conditionnelle_Père.__name__, ma_Methode_Conditionnelle_Père)
del kwargs['paramètrePère']
if 'banieméthodes' in kwargs and 'ma_Methode_Père' in kwargs['banieméthodes']:
setattr(newclass, 'mapropriété_père', 'mapropriété_père')
else:
setattr(newclass, 'mapropriété_père', 'mapropriété_père')
def ma_Methode_Père(self):
return newclass.mapropriété_père
setattr(newclass, ma_Methode_Père.__name__, ma_Methode_Père)
return newclass
def __init__(self, *args, **kwargs):
pass
class Enfant(Pere):
def __new__(cls, *args, **kwargs):
newclass = super(Enfant, cls).__new__(cls, *args, **kwargs)
if 'paramètreEnfant' in kwargs.keys():
if kwargs['paramètreEnfant']:
setattr(newclass, 'mapropriété_conditionnelleenfant', None)
def ma_Methode_Conditionnelle_Enfant():
return newclass.mapropriété_conditionnelleenfant
setattr(newclass, ma_Methode_Conditionnelle_Enfant.__name__, ma_Methode_Conditionnelle_Enfant)
del kwargs['paramètreEnfant']
return newclass
def __init__(self, *args, **kwargs):
super().__init__(**kwargs)
self.mapropriété_enfant = None
def ma_Methode_Enfant(self):
pass
class PetitEnfant(Enfant):
def __new__(cls, *args, **kwargs):
newclass = super(PetitEnfant, cls).__new__(cls, *args, **kwargs)
if 'paramètrePetitEnfant' in kwargs.keys():
if kwargs['paramètrePetitEnfant']:
setattr(newclass, 'mapropriété_conditionnellepetitenfant', None)
def ma_Methode_Conditionnelle_PetitEnfant():
return newclass.mapropriété_conditionnellepetitenfant
setattr(newclass, ma_Methode_Conditionnelle_PetitEnfant.__name__, ma_Methode_Conditionnelle_PetitEnfant)
del kwargs['paramètrePetitEnfant']
return newclass
def __init__(self, **kwargs):
self.mapropriétépetitenfant = None
super().__init__()
def ma_Methode_PetitEnfant(self):
pass
if __name__ == '__main__':
class Vide():
pass
vide = Vide()
vide_list = set(dir(vide))
print('Pere()')
a = Pere()
a_list = set(dir(a))
print(str(a_list - vide_list))
print('Pere(paramètrePère=True)')
a = Pere(paramètrePère=True)
a_list = set(dir(a))
print(str(a_list - vide_list))
print('Enfant()')
b = Enfant()
b_list = set(dir(b))
print(str(b_list - vide_list))
print('Enfant(paramètrePère=True)')
b = Enfant(paramètrePère=True)
b_list = set(dir(b))
print(str(b_list - vide_list))
print('Enfant(banieméthodes=[\'ma_Methode_Père\'])')
b = Enfant(banieméthodes=['ma_Methode_Père'])
b_list = set(dir(b))
print(str(b_list - vide_list))
print('Enfant(paramètreEnfant=True)')
b = Enfant(paramètreEnfant=True)
b_list = set(dir(b))
print(str(b_list - vide_list))
print('Enfant(paramètreEnfant=True, paramètrePère=True)')
b = Enfant(paramètreEnfant=True, paramètrePère=True)
b_list = set(dir(b))
print(str(b_list - vide_list))
print('Enfant(paramètreEnfant=True, paramètrePère=True, banieméthodes=[\'ma_Methode_Père\'])')
b = Enfant(paramètreEnfant=True, paramètrePère=True, banieméthodes=['ma_Methode_Père'])
b_list = set(dir(b))
print(str(b_list - vide_list))
print('PetitEnfant()')
c = PetitEnfant()
c_list = set(dir(c))
print(str(c_list - vide_list))
print('PetitEnfant(paramètrePère=True)')
c = PetitEnfant(paramètrePère=True)
c_list = set(dir(c))
print(str(c_list - vide_list))
print('PetitEnfant(banieméthodes=[\'ma_Methode_Père\']')
c = PetitEnfant(banieméthodes=['ma_Methode_Père'])
c_list = set(dir(c))
print(str(c_list - vide_list))
print('PetitEnfant(paramètreEnfant=True)')
c = Enfant(paramètreEnfant=True)
c_list = set(dir(c))
print(str(c_list - vide_list))
print('PetitEnfant(paramètrePetitEnfant=True)')
c = PetitEnfant(paramètrePetitEnfant=True)
c_list = set(dir(c))
print(str(c_list - vide_list))
Ce qui nous donne en sortie d’exécution
utilisateur@MachineUbuntu:~/repertoire_de_developpement/9_objets$ python3 ./heritageconditionnelnew.py
Pere()
{'mapropriété_père', 'ma_Methode_Père'}
Pere(paramètrePère=True)
{'mapropriété_père', 'mapropriété_conditionnellepère', 'ma_Methode_Conditionnelle_Père', 'ma_Methode_Père'}
Enfant()
{'mapropriété_enfant', 'ma_Methode_Enfant', 'mapropriété_père', 'ma_Methode_Père'}
Enfant(paramètrePère=True)
{'mapropriété_enfant', 'ma_Methode_Enfant', 'mapropriété_conditionnellepère', 'ma_Methode_Conditionnelle_Père', 'mapropriété_père', 'ma_Methode_Père'}
Enfant(banieméthodes=['ma_Methode_Père'])
{'mapropriété_enfant', 'ma_Methode_Enfant', 'mapropriété_père'}
Enfant(paramètreEnfant=True)
{'mapropriété_enfant', 'ma_Methode_Enfant', 'ma_Methode_Conditionnelle_Enfant', 'mapropriété_père', 'ma_Methode_Père', 'mapropriété_conditionnelleenfant'}
Enfant(paramètreEnfant=True, paramètrePère=True)
{'mapropriété_enfant', 'ma_Methode_Enfant', 'ma_Methode_Conditionnelle_Enfant', 'mapropriété_conditionnellepère', 'ma_Methode_Conditionnelle_Père', 'mapropriété_père', 'ma_Methode_Père', 'mapropriété_conditionnelleenfant'}
Enfant(paramètreEnfant=True, paramètrePère=True, banieméthodes=['ma_Methode_Père'])
{'mapropriété_enfant', 'ma_Methode_Enfant', 'ma_Methode_Conditionnelle_Enfant', 'mapropriété_conditionnellepère', 'ma_Methode_Conditionnelle_Père', 'mapropriété_père', 'mapropriété_conditionnelleenfant'}
PetitEnfant()
{'mapropriété_enfant', 'ma_Methode_Enfant', 'ma_Methode_PetitEnfant', 'mapropriété_père', 'ma_Methode_Père', 'mapropriétépetitenfant'}
PetitEnfant(paramètrePère=True)
{'mapropriété_enfant', 'ma_Methode_Enfant', 'mapropriété_conditionnellepère', 'ma_Methode_Conditionnelle_Père', 'ma_Methode_PetitEnfant', 'mapropriété_père', 'ma_Methode_Père', 'mapropriétépetitenfant'}
PetitEnfant(banieméthodes=['ma_Methode_Père']
{'mapropriété_enfant', 'ma_Methode_Enfant', 'ma_Methode_PetitEnfant', 'mapropriété_père', 'mapropriétépetitenfant'}
PetitEnfant(paramètreEnfant=True)
{'mapropriété_enfant', 'ma_Methode_Enfant', 'ma_Methode_Conditionnelle_Enfant', 'mapropriété_père', 'ma_Methode_Père', 'mapropriété_conditionnelleenfant'}
PetitEnfant(paramètrePetitEnfant=True)
{'mapropriété_enfant', 'ma_Methode_Enfant', 'ma_Methode_Conditionnelle_PetitEnfant', 'ma_Methode_PetitEnfant', 'mapropriété_père', 'ma_Methode_Père', 'mapropriétépetitenfant', 'mapropriété_conditionnellepetitenfant'}
Avec une metaclass#
En Python 3 tout est objet et tous les objets ont un type (comme int, str, float, list, dict, etc.). Pour obtenir ce type on utilise la commande type(). Les classes sont aussi des objets, par conséquent une classe doit avoir un type. Quel est le type d’une classe ?
>>> class MaClasse():
... pass
...
>>> type(MaClasse)
<class 'type'>
Il est alors exact de faire référence au lien entre le type d’un objet et sa classe. Une métaclasse est la classe d’une classe. Une classe définit le comportement d’une instance de la classe, c’est-à-dire un objet, tandis qu’une métaclasse définit le comportement d’une classe, c’est donc le type de l’objet. Une classe est une instance d’une métaclasse, son type.
Une métaclasse est donc un objet type. Et pour construire sa métaclasse il faut hériter de cet objet, comme nos classes d’objet héritent de l’objet object.
Dans notre exemple l’utilisation d’une métaclasse c’est lorsque l’on veut que le filtrage et l’héritage des classes s’effectuent au niveau de l’écriture de la classe. C’est au niveau de la classe elle même que s’appliquera le filtrage (plus au niveau des paramètres d’instanciation de l’objet avec la classe”).
#! /usr/bin/env python3
# -*- coding: utf8 -*-
class MetaTest(type):
""" Classe Meta de test """
def __new__(cls, name, bases, namespace, **kwargs):
""" Set class MetaTest """
print('new cls: %s' % cls)
print('new name: %s' % name)
if bases:
print('new bases: %s' % bases)
print('new namespace: %s' % namespace)
print('new kwargs: %s' % kwargs)
setattribute = False
setmethod = False
if 'settest' in kwargs.keys():
if kwargs['settest']:
setattribute = True
setmethod = True
del kwargs['settest']
if 'setattribute' in kwargs.keys():
if kwargs['setattribute']:
setattribute = True
del kwargs['setattribute']
if 'setmethod' in kwargs.keys():
if kwargs['setmethod']:
setmethod = True
del kwargs['setmethod']
newclass = super(MetaTest, cls).__new__(cls, name, bases, namespace, **kwargs)
if setattribute:
setattr(newclass, 'my_property', None)
if setmethod:
def info(self):
return 'My method info'
setattr(newclass, info.__name__, info)
if setmethod and setattribute:
setattr(newclass, 'my_method', None)
def set_method(self, value):
self.my_method = value
def get_method(self):
return self.my_method
setattr(newclass, set_method.__name__, set_method)
setattr(newclass, get_method.__name__, get_method)
return newclass
def __init__(cls, name, bases, namespace, **kwargs):
""" Initialize metaclass MetaTest """
super().__init__(name, bases, namespace)
print('init cls: %s' % cls)
print('init name: %s' % name)
if bases:
print('init bases: %s' % bases)
print('init namespace: %s' % namespace)
print('init kwargs: %s' % kwargs)
class A(metaclass=MetaTest):
pass
class B(metaclass=MetaTest, settest=False):
pass
class C(metaclass=MetaTest, settest=True):
pass
class D(metaclass=MetaTest, setattribute=False):
pass
class E(metaclass=MetaTest, setattribute=True):
pass
class F(metaclass=MetaTest, setmethod=False):
pass
class G(metaclass=MetaTest, setmethod=True):
pass
print('A: %s' % dir(A))
print('B: %s' % dir(B))
print('C: %s' % dir(C))
print('D: %s' % dir(D))
print('E: %s' % dir(E))
print('F: %s' % dir(F))
print('G: %s' % dir(G))
a = A()
b = B()
c = C()
d = D()
e = E()
f = F()
g = G()
print('a: %s' % dir(a))
print('b: %s' % dir(b))
print('c: %s' % dir(c))
print('c.my_property: %s' % c.my_property)
c.my_property = 'Property value'
print('c.my_property: %s' % c.my_property)
print('c.get_method(): %s' % c.get_method())
c.set_method('Method value')
print('c.get_method(): %s' % c.get_method())
print('d: %s' % dir(d))
print('e: %s' % dir(e))
print('e.my_property: %s' % e.my_property)
e.my_property = 'Property value'
print('e.my_property: %s' % e.my_property)
print('f: %s' % dir(f))
print('g: %s' % dir(g))
print('g.info(): %s' % g.info())
Opérateurs#
Il est maintenant temps de nous intéresser aux opérateurs du langage Python (+, -, *, etc.). En effet, un code respectant la philosophie du langage se doit de les utiliser à bon escient.
Ils sont une manière claire de représenter des opérations élémentaires (addition, concaténation, …) entre deux objets. a + b est en effet plus lisible qu’un add(a, b) ou encore a.add(b).
Ce chapitre a pour but de vous présenter les mécanismes mis en jeu par ces différents opérateurs, et la manière de les implémenter. Les opérateurs sont un autre type de méthodes spéciales que nous découvrirons dans cette section.
En effet, les opérateurs ne sont rien d’autres en Python que des fonctions, qui s’appliquent sur leurs opérandes. On peut s’en rendre compte à l’aide du module operator, qui répertorie les fonctions associées à chaque opérateur.
>>> import operator
>>> operator.add(5, 6)
11
>>> operator.mul(2, 3)
6
Ainsi, chacun des opérateurs correspondra à une méthode de l’opérande de gauche, qui recevra en paramètre l’opérande de droite.
Opérateurs arithmétiques#
L’addition, par exemple, est définie par la méthode __add__.
>>> class A:
... def \__add__(self, other):
... return other # on considère self comme 0
...
>>> A() + 5
5
Assez simple, n’est-il pas ? Mais nous n’avons pas tout à fait terminé. Si la méthode est appelée sur l’opérande de gauche, que se passe-t-il quand notre objet se trouve à droite ?
>>> 5 + A()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported operand type(s) for +: 'int' and 'A'
Nous ne supportons pas cette opération. En effet, l’expression fait appel à la méthode int.__add__ qui ne connaît pas les objets de type A.
Heureusement, ce cas a été prévu et il existe une fonction inverse, __radd__, appelée si la première opération n’était pas supportée.
>>> class A:
... def __add__(self, other):
... return other
... def __radd__(self, other):
... return other
...
>>> A() + 5
5
>>> 5 + A()
5
Il faut bien noter que A.__radd__ ne sera appelée que si int.__add__ a échoué.
Les autres opérateurs arithmétques binaires auront un comportement similaire, voici une liste des méthodes à implémenter pour chacun d’eux :
Addition/Concaténation (a + b) —
__add__,__radd__Soustraction/Différence (a - b) —
__sub__,__rsub__Multiplication (a * b) —
__mul__,__rmul__Division (a / b) —
__truediv__,__rtruediv__Division entière (a // b) —
__floordiv__,__rfloordiv__Modulo/Formattage (a % b) —
__mod__,__rmod__Exponentiation (a ** b) —
__pow__,__rpow__
On remarque aussi que chacun de ces opérateurs arithmétiques possède une version simplifiée pour l’assignation (a += b) qui correspond à la méthode __iadd__. Par défaut, les méthodes __add__ __radd__ sont appelées, mais définir __iadd__ permet d’avoir un comportement différent dans le cas d’un opérateur d’assignation, par exemple sur les listes :
>>> l = [1, 2, 3]
>>> l2 = l
>>> l2 = l2 + [4]
>>> l2
[1, 2, 3, 4]
>>> l
[1, 2, 3]
>>> l2 = l
>>> l2 += [4]
>>> l2
[1, 2, 3, 4]
>>> l
[1, 2, 3, 4]
Opérateurs arithmétiques unaires#
Voyons maintenant les opérateurs unaires, qui ne prennent donc pas d’autre paramètre que self.
Opposé (-a) —
__neg__Positif (+a) -
__pos__Valeur abosule (abs(a)) —
__abs__
Opérateurs de comparaison#
De la même manière que pour les opérateurs arithmétiques et unaires, nous avons une méthode spéciale par opérateur de comparaison. Ces opérateurs s’appliqueront sur l’opérande gauche en recevant le droite en paramètre. Ils devront retourner un booléen.
Contrairement aux opérateurs arithmétiques, il n’est pas nécessaire d’avoir deux versions pour chaque opérateur puisque Python saura directement quelle opération inverse tester si la première a échoué (a == b est équivalent à b == a, a < b à b > a, etc.).
Égalité (a == b) —
__eq__Différence (a != b) —
__neq__Stricte infériorité (a < b) —
__lt__Infériorité (a <= b) —
__le__Stricte supériorité (a > b) —
__gt__Supériorité (a >= b) —
__ge__
On notera aussi que beaucoup de ces opérateurs peuvent s’inférer les uns les autres. Par exemple, il suffit de savoir calculer a == b et a < b pour définir toutes les autres opérations. Ainsi, Python dispose d’un décorateur, total_ordering du module functools, pour automatiquement générer les opérations manquantes.
>>> from functools import total_ordering
>>> @total_ordering
... class Inferior:
... def __eq__(self, other):
... return False
... def __lt__(self, other):
... return True
...
>>> i = Inferior()
>>> i == 5
False
>>> i > 5
False
>>> i < 5
True
>>> i <= 5
True
>>> i != 5
True
Autres opérateurs#
Nous avons ici étudié les principaux opérateurs du langage. Ces listes ne sont pas exhaustives et présentent juste la méthodologie à suivre.
Pour une liste complète, je vous invite à consulter la documentation du module operator : https://docs.python.org/3/library/operator.html.
Exercice Arithmétique simple#
Oublions temporairement nos utilisateurs et notre forum, et intéressons-nous à l’évaluation mathématique.
Imaginons que nous voulions représenter une expression mathématique, qui pourrait contenir des termes variables (par exemple, 2 * (-x + 1)).
Il va nous falloir utiliser un type pour représenter cette variable x, appelé Var, et un second pour l’expression non évaluée, Expr. Les Var étant un type particulier d’expressions.
Nous aurons deux autres types d’expressions : les opérations arithmétiques unaires (+, -) et binaires (+, -, *, /, //, %, **). Vous pouvez vous appuyer un même type pour ces deux types d’opérations.
L’expression précédente s’évaluerait par exemple à :
BinOp(operator.mul, 2, BinOp(operator.add, UnOp(operator.neg, Var('x')), 1))
Nous ajouterons à notre type Expr une méthode compute(**values), qui permettra de calculer l’expression suivant une valeur donnée, de façon à ce que Var('x').compute(x=5) retourne 5.
Enfin, nous pourrons ajouter une méthode __repr__ pour obtenir une représentation lisible de notre expression.
import operator
def compute(expr, **values):
if not isinstance(expr, Expr):
return expr
return expr.compute(**values)
class Expr:
def compute(self, **values):
raise NotImplementedError
def __pos__(self):
return UnOp(operator.pos, self, '+')
def __neg__(self):
return UnOp(operator.neg, self, '-')
def __add__(self, rhs):
return BinOp(operator.add, self, rhs, '+')
def __radd__(self, lhs):
return BinOp(operator.add, lhs, self, '+')
def __sub__(self, rhs):
return BinOp(operator.sub, self, rhs, '-')
def __rsub__(self, lhs):
return BinOp(operator.sub, lhs, self, '-')
def __mul__(self, rhs):
return BinOp(operator.mul, self, rhs, '*')
def __rmul__(self, lhs):
return BinOp(operator.mul, lhs, self, '*')
def __truediv__(self, rhs):
return BinOp(operator.truediv, self, rhs, '/')
def __rtruediv__(self, lhs):
return BinOp(operator.truediv, lhs, self, '/')
def __floordiv__(self, rhs):
return BinOp(operator.floordiv, self, rhs, '//')
def __rfloordiv__(self, lhs):
return BinOp(operator.floordiv, lhs, self, '//')
def __mod__(self, rhs):
return BinOp(operator.mod, self, rhs, '*')
def __rmod__(self, lhs):
return BinOp(operator.mod, lhs, self, '*')
class Var(Expr):
def __init__(self, name):
self.name = name
def compute(self, **values):
if self.name in values:
return values[self.name]
return self
def __repr__(self):
return self.name
class Op(Expr):
def __init__(self, op, *args):
self.op = op
self.args = args
def compute(self, **values):
args = [compute(arg, **values) for arg in self.args]
return self.op(*args)
class UnOp(Op):
def __init__(self, op, expr, symbol=None):
super().__init__(op, expr)
self.symbol = symbol
def __repr__(self):
if self.symbol is None:
return super().__repr__()
return '{}{!r}'.format(self.symbol, self.args[0])
class BinOp(Op):
def __init__(self, op, expr1, expr2, symbol=None):
super().__init__(op, expr1, expr2)
self.symbol = symbol
def __repr__(self):
if self.symbol is None:
return super().__repr__()
return '({!r} {} {!r})'.format(self.args[0], self.symbol, self.args[1])
if __name__ == '__main__':
x = Var('x')
expr = 2 * (-x + 1)
print(expr)
print(compute(expr, x=1))
y = Var('y')
expr += y
print(compute(expr, x=0, y=10))
Les opérateurs sont une notion importante en Python, mais ils sont loin d’être la seule. Le chapitre suivant vous présentera d’autres concepts avancés du Python, qu’il est important de connaître, pour être en mesure de les utiliser quand cela s’avère nécessaire.
Les attributs de classe#
Nous avons déjà rencontré un attribut de classe, quand nous nous intéressions aux parents d’une classe. Souvenez-vous de __bases__, nous ne l’utilisions pas sur des instances mais sur notre classe directement.
En Python, les classes sont des objets comme les autres, et peuvent donc posséder leurs propres attributs.
>>> class User:
... pass
...
>>> User.type = 'simple_user'
>>> User.type
'simple_user'
Les attributs de classe peuvent aussi se définir dans le corps de la classe, de la même manière que les méthodes.
class User:
type = 'simple_user'
On notera à l’inverse qu’il est aussi possible de définir une méthode de la classe depuis l’extérieur :
>>> def User_repr(self):
... return '<User>'
...
>>> User.__repr_\_ = User_repr
>>> User()
<User>
L’avantage des attributs de classe, c’est qu’ils sont aussi disponibles pour les instances de cette classe. Ils sont partagés par toutes les instances.
>>> john = User()
>>> john.type
'simple_user'
>>> User.type = 'admin'
>>> john.type
'admin'
C’est le fonctionnement du MRO de Python, il cherche d’abord si l’attribut existe dans l’objet, puis si ce n’est pas le cas, le cherche dans les classes parentes.
Attention donc, quand l’attribut est redéfini dans l’objet, il sera trouvé en premier, et n’affectera pas la classe.
>>> john = User()
>>> john.type
'admin'
>>> john.type = 'superadmin'
>>> john.type
'superadmin'
>>> User.type
'admin'
>>> joe = User()
>>> joe.type
'admin'
Attention aussi, quand l’attribut de classe est un objet mutable { Un objet mutable est un objet que l’on peut modifier (liste, dictionnaire) par opposition à un objet immutable (nombre, chaîne de caractères, tuple) }, il peut être modifié par n’importe quelle instance de la classe.
>>> class User:
... users = []
...
>>> john, joe = User(), User()
>>> john.users.append(john)
>>> joe.users.append(joe)
>>> john.users
[<__main__.User object at 0x7f3b7acf8b70>, <__main__.User object at 0x7f3b7acf8ba8>]
L’attribut de classe est aussi conservé lors de l’héritage, et partagé avec les classes filles (sauf lorsque les classes filles redéfinissent l’attribut, de la même manière que pour les instances).
>>> class Guest(User):
... pass
...
>>> Guest.users
[<__main__.User object at 0x7f3b7acf8b70>, <__main__.User object at 0x7f3b7acf8ba8>]
>>> class Admin(User):
... users = []
...
>>> Admin.users
[]
Méthodes de Classes#
Comme pour les attributs, des méthodes peuvent être définies au niveau de la classe. C’est par exemple le cas de la méthode mro.
int.mro()
Les méthodes de classe constituent des opérations relatives à la classe mais à aucune instance. Elles recevront la classe courante en premier paramètre (nommé cls, correspondant au self des méthodes d’instance), et auront donc accès aux autres attributs et méthodes de classe.
Reprenons notre classe User, à laquelle nous voudrions ajouter le stockage de tous les utilisateurs, et la génération automatique de l’id.
Il nous suffirait d’une même méthode de classe pour stocker l’utilisateur dans un attribut de classe users, et qui lui attribuerait un id en fonction du nombre d’utilisateurs déjà enregistrés.
>>> root = Admin('root', 'toor')
>>> root
<User: 1, root>
>>> User('john', '12345')
<User: 2, john>
>>> guest = Guest('guest')
<User: 3, guest>
Les méthodes de classe se définissent comme les méthodes habituelles, à la différence près qu’elles sont précédées du décorateur classmethod.
import crypt
class User:
users = []
def __init__(self, name, password):
self.name = name
self._salt = crypt.mksalt()
self._password = self._crypt_pwd(password)
self.register(self)
@classmethod
def register(cls, user):
cls.users.append(user)
user.id = len(cls.users)
def _crypt_pwd(self, password):
return crypt.crypt(password, self._salt)
def check_pwd(self, password):
return self._password == self._crypt_pwd(password)
def __repr__(self):
return '<User: {}, {}>'.format(self.id, self.name)
class Guest(User):
def __init__(self, name):
super().__init__(name, '')
def check_pwd(self, password):
return True
class Admin(User):
def manage(self):
print('Je suis un Jedi!')
Vous pouvez constater le résultat en réessayant le code donné plus haut.
Méthodes statiques#
Les méthodes statiques sont très proches des méthodes de classe, mais sont plus à considérer comme des fonctions au sein d’une classe.
Contrairement aux méthodes de classe, elles ne recevront pas le paramètre cls, et n’auront donc pas accès aux attributs de classe,
méthodes de classe ou méthodes statiques.
Les méthodes statiques sont plutôt dédiées à des comportements annexes en rapport avec la classe, par exemple on pourrait remplacer notre attribut id par un uuid aléatoire, dont la génération ne dépendrait de rien d’autre dans la classe.
Elles se définissent avec le décorateur staticmethod.
import uuid
class User:
def __init__(self, name, password):
self.id = self._gen_uuid()
self.name = name
self._salt = crypt.mksalt()
self._password = self._crypt_pwd(password)
@staticmethod
def _gen_uuid():
return str(uuid.uuid4())
def _crypt_pwd(self, password):
return crypt.crypt(password, self._salt)
def check_pwd(self, password):
return self._password == self._crypt_pwd(password)
>>> john = User('john', '12345')
>>> john.id
'69ef1327-3d96-42a9-94e6-622619fbf666'
Recherche d’attributs#
Nous savons récupérer et assigner un attribut dont le nom est fixé, cela se fait facilement à l’aide des instructions obj.foo et obj.foo = value.
Mais nous est-il possible d’accéder à des attributs dont le nom est variable ?
Prenons une instance john de notre classe User, et le nom d’un attribut que nous voudrions extraire :
>>> john = User('john', '12345')
>>> attr = 'name'
La fonction getattr nous permet alors de récupérer cet attribut.
>>> getattr(john, attr)
'john'
Ainsi, getattr(obj, 'foo') est équivalent à obj.foo.
On trouve aussi une fonction hasattr pour tester la présence d’un attribut dans un objet. Elle est construite comme getattr mais retourne un booléen pour savoir si l’attribut est présent ou non.
>>> hasattr(john, 'name')
True
>>> hasattr(john, 'last_name')
False
>>> hasattr(john, 'id')
True
De la même manière, les fonctions setattr et delattr servent respectivement à modifier et supprimer un attribut.
>>> setattr(john, 'name', 'peter') # équivalent à `john.name = 'peter'`
>>> john.name
'peter'
>>> delattr(john, 'name') # équivalent à \`del john.name\`
>>> john.name
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'User' object has no attribute 'name'
Les propriétés#
Les propriétés sont une manière en Python de «dynamiser» les attributs d’un objet. Ils permettent de générer des attributs à la volée à partir de méthodes de l’objet.
Un exemple vaut mieux qu’un long discours :
class ProfilePicture:
@property
def picture(self):
return '{}-{}.png'.format(self.id, self.name)
class UserPicture(ProfilePicture, User):
pass
On définit donc une propriété picture avec @property, qui s’utilise comme un attribut. Chaque fois qu’on appelle picture, la méthode correspondante est appelée et le résultat est calculé.
>>> john = UserPicture('john', '12345')
>>> john.picture
'1-john.png'
>>> john.name = 'John'
>>> john.picture
'1-John.png'
Il s’agit là d’une propriété en lecture seule, il nous est en effet impossible de modifier la valeur de l’attribut picture.
>>> john.picture = 'toto.png'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: can't set attribute
Pour le rendre modifiable, il faut ajouter à notre classe la méthode permettant de gérer la modification, à l’aide du décorateur @picture.setter (le décorateur setter de notre propriété picture, donc).
On utilisera ici un attribut _picture, qui pourra contenir l’adresse de l’image si elle a été définie, et None le cas échéant.
class ProfilePicture:
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self._picture = None
@property
def picture(self):
if self._picture is not None:
return self._picture
return '{}-{}.png'.format(self.id, self.name)
@picture.setter
def picture(self, value):
self._picture = value
class UserPicture(ProfilePicture, User):
pass
>>> john = UserPicture('john', '12345')
>>> john.picture
'1-john.png'
>>> john.picture = 'toto.png'
>>> john.picture
'toto.png'
Enfin, on peut aussi coder la suppression de l’attribut à l’aide de @picture.deleter, ce qui revient à réaffecter None à l’attribut _picture.
class ProfilePicture:
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self._picture = None
@property
def picture(self):
if self._picture is not None:
return self._picture
return '{}-{}.png'.format(self.id, self.name)
@picture.setter
def picture(self, value):
self._picture = value
@picture.deleter
def picture(self):
self._picture = None
class UserPicture(ProfilePicture, User):
pass
>>> john = UserPicture('john', '12345')
>>> john.picture
'1-john.png'
>>> john.picture = 'toto.png'
>>> john.picture
'toto.png'
>>> del john.picture
>>> john.picture
'1-john.png'
Classes abstraites#
La notion de classes abstraites est utilisée lors de l’héritage pour forcer les classes filles à implémenter certaines méthodes (dites méthodes abstraites) et donc respecter une interface.
Les classes abstraites ne font pas partie du cœur même de Python, mais sont disponibles via un module de la bibliothèque standard, abc (Abstract Pere Classes). Ce module contient notamment la classe ABC et le décorateur @abstractmethod, pour définir respectivement une classe abstraite et une méthode abstraite de cette classe.
Une classe abstraite doit donc hériter d’ABC, et utiliser le décorateur cité pour définir ses méthodes abstraites.
import abc
class MyABC(abc.ABC):
@abc.abstractmethod
def foo(self):
pass
Il nous est impossible d’instancier des objets de type MyABC, puisqu’une méthode abstraite n’est pas implémentée :
>>> MyABC()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: Can't instantiate abstract class MyABC with abstract methods foo
Il en est de même pour une classe héritant de MyABC sans redéfinir la méthode.
>>> class A(MyABC):
... pass
...
>>> A()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: Can't instantiate abstract class A with abstract methods foo
Aucun problème par contre avec une autre classe qui redéfinit bien la méthode.
>>> class B(MyABC):
... def foo(self):
... return 7
...
>>> B()
<__main__.B object at 0x7f33065316a0>
>>> B().foo()
7
Exercice : Base de données#
nous aborderons les méthodes de classe et les propriétés.
Reprenons notre forum, auquel nous souhaiterions ajouter la gestion d’une base de données.
Notre base de données sera une classe avec deux méthodes, insert et select. Son implémentation est libre, elle doit juste respecter l’interface suivante :
>>> class A: pass
...
>>> class B: pass
...
>>>
>>> db = Database()
>>> obj = A()
>>> obj.value = 42
>>> db.insert(obj)
>>> obj = A()
>>> obj.value = 5
>>> db.insert(obj)
>>> obj = B()
>>> obj.value = 42
>>> obj.name = 'foo'
>>> db.insert(obj)
>>>
>>> db.select(A)
<__main__.A object at 0x7f033697f358>
>>> db.select(A, value=5)
<__main__.A object at 0x7f033697f3c8>
>>> db.select(B, value=42)
<__main__.B object at 0x7f033697f438>
>>> db.select(B, value=42, name='foo')
<__main__.B object at 0x7f033697f438>
>>> db.select(B, value=5)
ValueError: item not found
Nous ajouterons ensuite une classe Model, qui se chargera de stocker dans la base toutes les instances créées. Model comprendra une méthode de classe get(**kwargs) chargée de réaliser une requête select sur la base de données et de retourner l’objet correspondant. Les objets de type Model disposeront aussi d’une propriété id, retournant un identifiant unique de l’objet.
On pourra alors faire hériter nos classes User et Post de Model, afin que les utilisateurs et messages soient stockés en base de données. Dans un second temps, on pourra faire de Model une classe abstraite, par exemple en rendant abstraite la méthode __init__.
import abc
import datetime
class Database:
data = []
def insert(self, obj):
self.data.append(obj)
def select(self, cls, **kwargs):
items = (item for item in self.data
if isinstance(item, cls)
and all(hasattr(item, k) and getattr(item, k) == v
for (k, v) in kwargs.items()))
try:
return next(items)
except StopIteration:
raise ValueError('item not found')
class Model(abc.ABC):
db = Database()
@abc.abstractmethod
def __init__(self):
self.db.insert(self)
@classmethod
def get(cls, \**kwargs):
return cls.db.select(cls, \**kwargs)
@property
def id(self):
return id(self)
class User(Model):
def __init__(self, name):
super().__init__()
self.name = name
class Post(Model):
def __init__(self, author, message):
super().__init__()
self.author = author
self.message = message
self.date = datetime.datetime.now()
def format(self):
date = self.date.strftime('le %d/%m/%Y à %H:%M:%S')
return '<div><span>Par {} {}</span><p>{}</p></div>'.format(self.author.name, date, self.message)
if __name__ == '__main__':
john = User('john')
peter = User('peter')
Post(john, 'salut')
Post(peter, 'coucou')
print(Post.get(author=User.get(name='peter')).format())
print(Post.get(author=User.get(id=john.id)).format())
Ces dernières notions ont dû compléter vos connaissances du modèle objet de Python, et vous devriez maintenant être prêts à vous lancer dans un projet exploitant ces concepts.
La visualisation de l’architecture objets#
Le programme pylint, que nous avons installé pour tester le code Python, est livré avec un outil de ligne de commande fort pratique pyreverse. Celui-ci permet d’imager les classes Python et de créer des diagrammes UML des classes Python.
Pyreverse#
Pyreverse permet de générer des diagrammes avec :
des attributs de classes et si possible avec leurs types,
des méthodes de classes avec leurs paramètres,
la représentation des exceptions,
les liens d’héritages de classes,
et les liens d’association de classes.
Les options de la ligne de commande#
Option courte |
Option verbeuse |
Description |
|---|---|---|
|
|
Nom du fichier en sortie |
|
|
Format de sortie de fichier (svg, svgz, png, jpeg/jpg/jpe, gif, ps/ps2/eps, pdf, pic, pcl, hpgl, gd/gd2, fig, dia, dot/xdot, plain/plain-ext, vrml/vml/vmlz, tk, wbmp, xlib, etc.) |
|
|
Afficher la classe passée en paramètre |
|
|
Afficher seulement les noms des classes |
|
|
Inclure le nom des modules pour la représentation des classes. |
|
|
Afficher les classes des objets natifs Python |
|
|
Aficher le niveaux d’héritage passé en paramètre |
|
|
Afficher tout l’arbre d’héritage |
|
|
Liens des imports suivant le niveau d’imports |
|
|
Toutes les liaisons d’imports |
|
|
Filtre ce qu’il faut faire apparaître (par défaut PUB_ONLY) :
|
Utilisation en ligne de commande#
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ cd 9_objets
utilisateur@MachineUbuntu:~/repertoire_de_developpement/9_objets$ pyreverse -p test -o png scene.py
L’option -p test ajoute le suffixe test au nom du fichier (qui par défaut est «classes.ext»).
L’option -o png choisit le format de sortie du diagramme, ici une image PNG.
Cela génère donc le fichier «classes_test.png».
Qui nous donne comme image :
Le diagramme UML contient le nom de la classe Decor (cellule du haut) avec sa propriété fabriqueBatiments (cellule du milieu) affectée à l’objet FabriqueBatiments. Ceci nous permet de comprendre que cela est en fait un objet puisque c’est le type de la propriété. La case vide est celle des méthodes.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/9_objets$ pyreverse -c Decor -o png scene.py
L’option -c Decor choisit la classe à générer comme diagramme UML, et va produire une sortie de nom de fichier avec le nom de la classe «Decor.png».
Ce qui va nous donner un diagramme plus intéressant :
Là nous voyons avec les flêches l’héritage des classes Vegetation, Urbanisation, Hydrotopologie, Geomorphologie et Atmosphere qui elle même hérite de Nuages.
Nous voyon aussi les propriétés et les méthodes (dernière cellule) de FabriqueBatiments. Classe qui est bien affectée (en vert) à la propriété fabriqueBatiments de la classe Decor
utilisateur@MachineUbuntu:~/repertoire_de_developpement/9_objets$ pyreverse -k -c Decor -o png scene.py
L’option -k permet de n’afficher que le nom des classes :
utilisateur@MachineUbuntu:~/repertoire_de_developpement/9_objets$ pyreverse -f ALL -S -c Decor -o png scene.py
L’option -f ALL permet d’afficher les propriétés et les méthodes cachées :
utilisateur@MachineUbuntu:~/repertoire_de_developpement/9_objets$ pyreverse -a 1 -c Decor -o png scene.py
L’option -a 1 permet de limiter le niveau de liens en héritage par rapport à la classe :
En limitant au premier niveau -a 1 la classe Nuages n’est plus affichée.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/9_objets$ pyreverse -b -c Decor -o png scene.py
L’option -b permet d’afficher l’héritage des classes natives Python :
On voit alors bien apparaître la classe object comme on l’attendait, mais aussi les classes builtin.list et builtin.str.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/9_objets$ pyreverse -mn -c Decor -o png scene.py
L’option -mn permet de supprimer le chemin d’importation des classes dans les intitulés de classes :
utilisateur@MachineUbuntu:~/repertoire_de_developpement/9_objets$ pyreverse -s 0 -c Decor -o png scene.py
L’option -s 0 permet de ne visualiser que les classes importées directement :
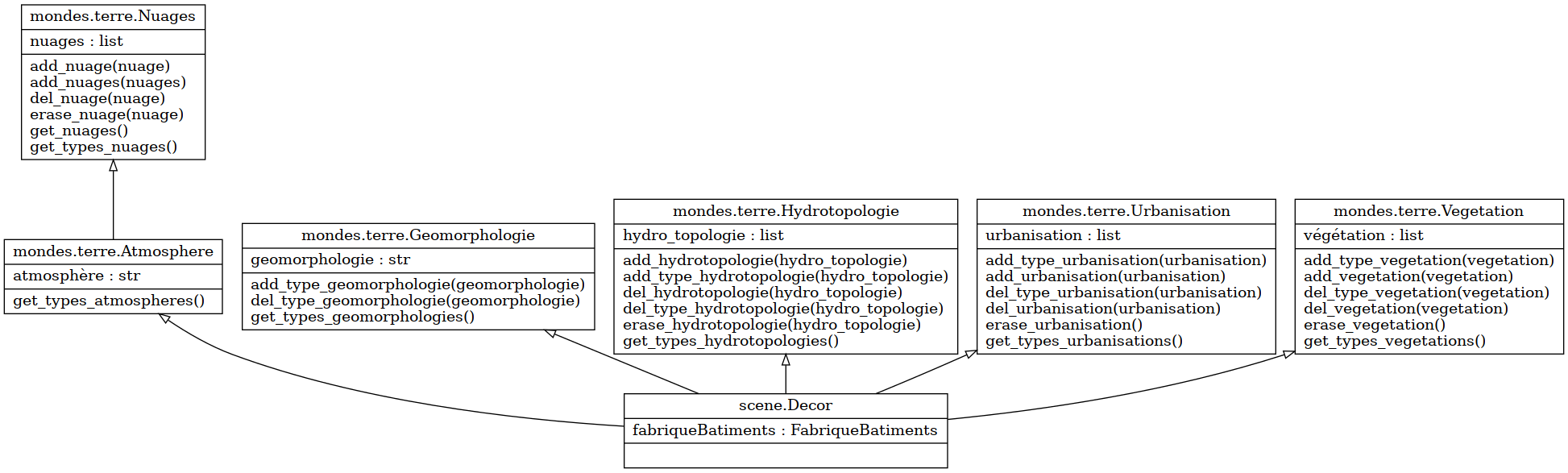
On voit bien que la classe FabriqueBatiments ne s’affiche plus avec un niveau supplémentaire d’importation.
Vous pouvez maintenant générer tous les diagrammes de classes Python que vous voulez pour agrémenter les documentations de vos programmes.
Mise en œuvre dans GitLab#
Avec un script#
Nous allons maintenant générer les diagrammes UML pour «Unittest.Calculatrice.py».
Modifier le fichier «makediagrammes».
#!/bin/bash
echo -e "___________ Génère les Classes ___________"
echo -e "=========== Supprime les anciens diagrammes de Classes ==========="
rm -f docs/sources-documents/classes/*
echo -e "+++++++++++ Génère les diagrammes UML des Classes +++++++++++"
echo -e "Classes"
pyreverse -mn -A -S -k -f PUB_ONLY -o png Unittest/Calculatrice.py
echo -e "Génère le diagramme de Calculatrice"
pyreverse -mn -A -S -f PUB_ONLY -o png -c Calculatrice Unittest/Calculatrice.py
echo -e "+++++++++++ End Generate UML Classes +++++++++++"
echo -e "=========== Move Classes to correct folder ==========="
mv *.png docs/sources-documents/classes
echo -e "___________ Classes Generated ___________"
Tester le script :
___________ Génère les Classes ___________
=========== Supprime les anciens diagrammes de Classes ===========
+++++++++++ Génère les diagrammes UML des Classes +++++++++++
Classes
parsing Calculatrice.py...
Génère le diagramme de Calculatrice
parsing Calculatrice.py...
+++++++++++ End Generate UML Classes +++++++++++
=========== Move Classes to correct folder ===========
___________ Classes Generated ___________
Et nous retrouvons nos digrammes UML dans «repertoire_de_developpement/docs/sources-documents/classes» avec les noms de fichiers «classes.png»

et «Calculatrice.png»

Modifier alors dans «repertoire_de_developpement/docs/sources-documents» le fichier «index.rst»
.. |date| date::
:Date: |date|
:Revision: 1.0
:Author: Prénom NOM <prénom.nom@fai.fr>
:Description: Documentation sur l'initiation à la programmation Python pour l'administrateur systèmes
:Info: Voir <http://gitlab.domaine-perso.fr/utilisateur/initiation_developpement_python_pour_administrateur> pour la mise à jour de ce cours.
.. toctree::
:maxdepth: 2
:caption: Contenu
.. include:: cours/InitiationProgrammationPythonPourAdministrateurSystemes.rst
.. only:: html
.. image:: ./badges/obsolescence.svg
:alt: Obsolescence du code Python
:align: left
:width: 200px
.. image:: ./badges/pylint.svg
:alt: Cliquez pour voir le rapport
:align: left
:width: 200px
:target: ./pylint/index.html
.. image:: classes/classes.png
:alt: UML des classes de calculatrice.py
:align: left
:width: 200px
.. image:: classes/Calculatrice.png
:alt: UML de Calculatrice
:align: left
:width: 200px
----
Modules
*******
.. automodule:: Unittest.Calculatrice
:members:
Générer la documentation.
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ ./makedocs
Mettre le résultat dans le dépot GitLab.
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git add .
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git commit -m "Ajout diagrammes UML à la documentation"
[master 2aac2d0] Ajout diagrammes UML à la documentation
45 files changed, 1043 insertions(+), 2083 deletions(-)
rewrite README.md (92%)
rewrite docs/documentation/doctrees/environment.pickle (74%)
rewrite docs/documentation/doctrees/index.doctree (90%)
create mode 100644 docs/documentation/epub/_images/Calculatrice.png
create mode 100644 docs/documentation/epub/_images/classes.png
rewrite docs/documentation/epub/index.xhtml (85%)
create mode 100644 docs/documentation/html/_images/Calculatrice.png
create mode 100644 docs/documentation/html/_images/classes.png
rewrite docs/documentation/html/searchindex.js (97%)
create mode 100644 docs/documentation/latex/Calculatrice.png
rewrite "docs/documentation/latex/InitiationProgrammationPythonPourAdministrateurSyst\303\250mes.idx" (100%)
rewrite "docs/documentation/latex/InitiationProgrammationPythonPourAdministrateurSyst\303\250mes.pdf" (94%)
rewrite "docs/documentation/latex/InitiationProgrammationPythonPourAdministrateurSyst\303\250mes.tex" (75%)
create mode 100644 docs/documentation/latex/classes.png
rewrite "docs/documentation/man/InitiationProgrammationPythonPourAdministrateurSyst\303\250mes.1" (77%)
rewrite docs/documentation/markdown/index.md (92%)
create mode 100644 "docs/documentation/texinfo/InitiationProgrammationPythonPourAdministrateurSyst\303\250mes-figures/Calculatrice.png"
create mode 100644 "docs/documentation/texinfo/InitiationProgrammationPythonPourAdministrateurSyst\303\250mes-figures/classes.png"
rewrite "docs/documentation/texinfo/InitiationProgrammationPythonPourAdministrateurSyst\303\250mes.info" (73%)
rewrite "docs/documentation/texinfo/InitiationProgrammationPythonPourAdministrateurSyst\303\250mes.texi" (72%)
rewrite docs/documentation/text/index.txt (93%)
rewrite docs/documentation/xml/index.xml (89%)
create mode 100644 docs/sources-documents/classes/Calculatrice.png
create mode 100644 docs/sources-documents/classes/classes.png
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ git push
Énumération des objets: 106, fait.
Décompte des objets: 100% (105/105), fait.
Compression par delta en utilisant jusqu'à 4 fils d'exécution
Compression des objets: 100% (54/54), fait.
Écriture des objets: 100% (55/55), 310.98 Kio | 2.96 Mio/s, fait.
Total 55 (delta 40), réutilisés 0 (delta 0), réutilisés du pack 0
To http://gitlab.domaine-perso.fr/utilisateur/initiation_developpement_python_pour_administrateur.git
42c3a24..2aac2d0 master -> master
Ce qui nous donne après traitement par GitLab pour le fichier «README.md»
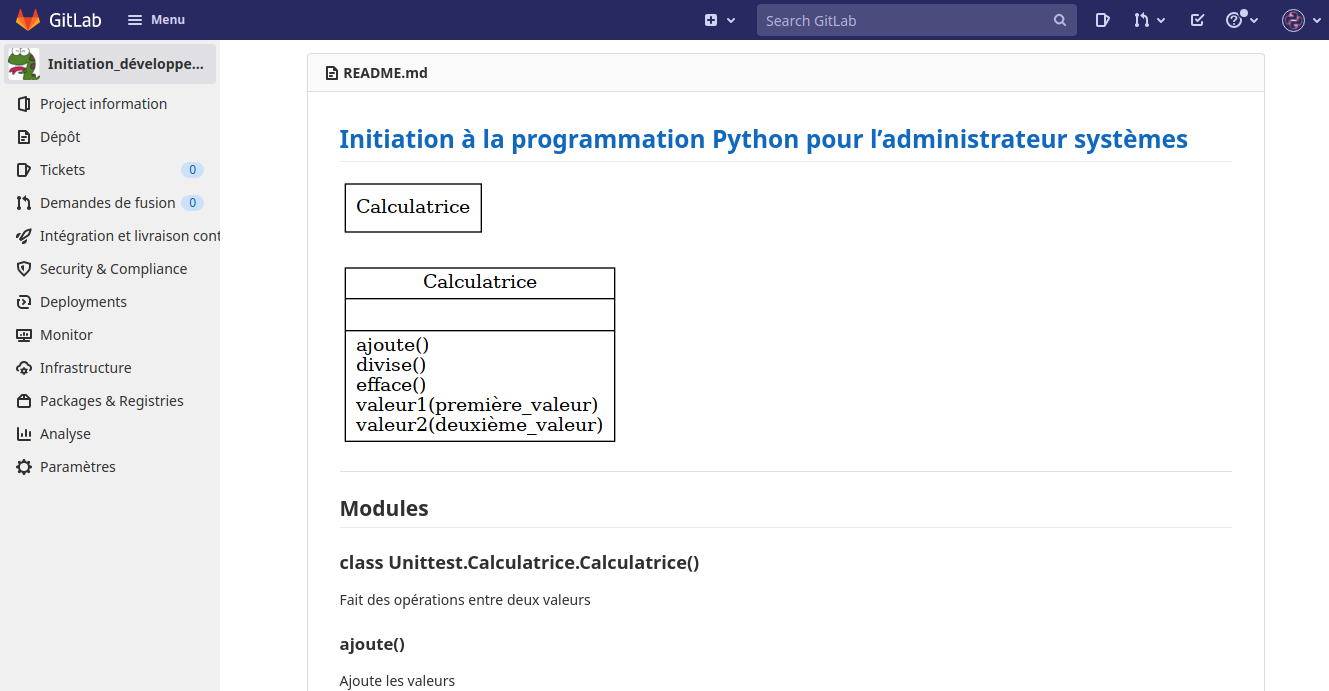
Et pour la page générée en HTML par GitLab «http://utilisateur.documentation.domaine-perso.fr/initiation_developpement_python_pour_administrateur/»
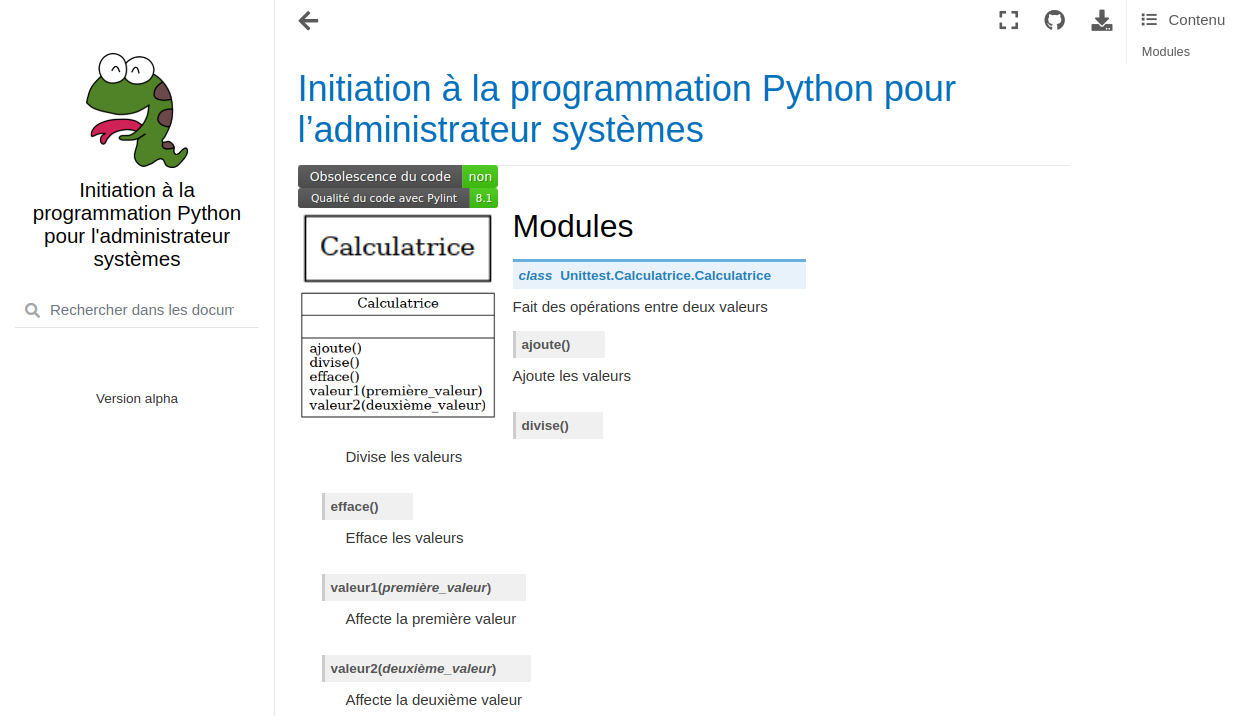
Générer des diagrammes UML avec GitLab#
Éditons le fichier «.gitlab-ci.yml», et modifions la section «pages».
image: python:latest
stages:
- build
- Static Analysis
- test
- deploy
construction-environnement:
stage: build
script:
- echo "Bonjour $GITLAB_USER_LOGIN !"
- echo "** Mises à jour et installation des applications supplémentaires **"
- echo "Mises à jour système"
- apt -y update
- apt -y upgrade
- echo "Installation des applications supplémentaires"
- cat packages.txt | xargs apt -y install
- echo "Mise à jour de PIP"
- pip install --upgrade pip
- echo "Installation des dépendances de modules Python"
- pip install -U -r requirements.txt
only:
- master
obsolescence-code:
stage: Static Analysis
allow_failure: true
script:
- echo "$GITLAB_USER_LOGIN test de l'obsolescence du code"
- python3 -Wd Unittest.Calculatrice.py 2> /tmp/output.txt
- sed -n '/DeprecationWarning:/p' /tmp/output.txt > /tmp/obsolescence.txt
- \[ -s /tmp/obsolescence.txt \] && cat /tmp/obsolescence.txt || echo "Pas d'obsolescences"
qualité-du-code:
stage: Static Analysis
allow_failure: true
before_script:
- echo "Installation de Pylint"
- pip install -U pylint-gitlab
script:
- echo "$GITLAB_USER_LOGIN test de la qualité du code"
- pylint --output-format=text Unittest.Calculatrice.py | tee /tmp/pylint.txt
after_script:
- sed -n 's/^Your code has been rated at \([-0-9.]*\)\/.*/\1/p' /tmp/pylint.txt > pylint.score
- echo "Votre score de qualité de code Pylint est de $(cat pylint.score)"
tests-unitaires:
stage: test
script:
- echo "Lancement des tests Unittest"
- python3 -m unittest
pages:
stage: deploy
before_script:
- echo "** Mises à jour et installation des applications supplémentaires **"
- echo "Mises à jour système"
- apt -y update
- apt -y upgrade
- echo "Installation des applications supplémentaires"
- cat docs-packages.txt | xargs apt -y install
- echo "Mise à jour de PIP"
- pip install --upgrade pip
- echo "Installation des dépendances de modules Python"
- pip install -U -r docs-requirements.txt
- echo "Création de l’infrastructure pour l'obsolescence et la qualité de code"
- mkdir -p public/obsolescence public/quality public/badges public/pylint public/classes
- echo undefined > public/obsolescence/obsolescence.score
- echo undefined > public/quality/pylint.score
- pip install -U pylint-gitlab
script:
- echo "** $GITLAB_USER_LOGIN déploiement de la documentation **"
- python3 -Wd Unittest.Calculatrice.py 2> /tmp/output.txt
- sed -n '/DeprecationWarning:/p' /tmp/output.txt > /tmp/obsolescence.txt
- \[ -s /tmp/obsolescence.txt \] && cat /tmp/obsolescence.txt || echo "Pas d'obsolescences"
- \[ -s /tmp/obsolescence.txt \] && echo oui > public/obsolescence/obsolescence.score || echo non > public/obsolescence/obsolescence.score
- echo "Obsolescence $(cat public/obsolescence/obsolescence.score)"
- pylint --exit-zero --output-format=text Unittest.Calculatrice.py | tee /tmp/pylint.txt
- sed -n 's/^Your code has been rated at \([-0-9.]*\)\/.*/\1/p' /tmp/pylint.txt > public/quality/pylint.score
- echo "Votre score de qualité de code Pylint est de $(cat public/quality/pylint.score)"
- echo "Création du rapport HTML de qualité de code"
- pylint --exit-zero --output-format=pylint_gitlab.GitlabPagesHtmlReporter Unittest.Calculatrice.py > public/pylint/index.html
- echo "Génération des diagrammes de classes"
- cd Unittest public/classes
- pyreverse -mn -A -S -k -f PUB_ONLY -o png ../../Calculatrice.py
- pyreverse -mn -A -S -f PUB_ONLY -o png -c Calculatrice ../../Unittest/Calculatrice.py
- cd ../..
- echo "Création du logo SVG d'obsolescence de code"
- anybadge --overwrite --label "Obsolescence du code" --value=$(cat public/obsolescence/obsolescence.score) --file=public/badges/obsolescence.svg oui=red non=green
- echo "Création du logo SVG de qualité de code"
- anybadge --overwrite --label "Qualité du code avec Pylint" --value=$(cat public/quality/pylint.score) --file=public/badges/pylint.svg 4=red 6=orange 8=yellow 10=green
- echo "Génération de la documentation html"
- sphinx-build -b html ./docs/sources-documents public
artifacts:
paths:
- public
only:
- master
Et après déploiement du fichier dans GitLab et génération de la page de documentation.
Une fois fini, aller dans la tâche «pages».
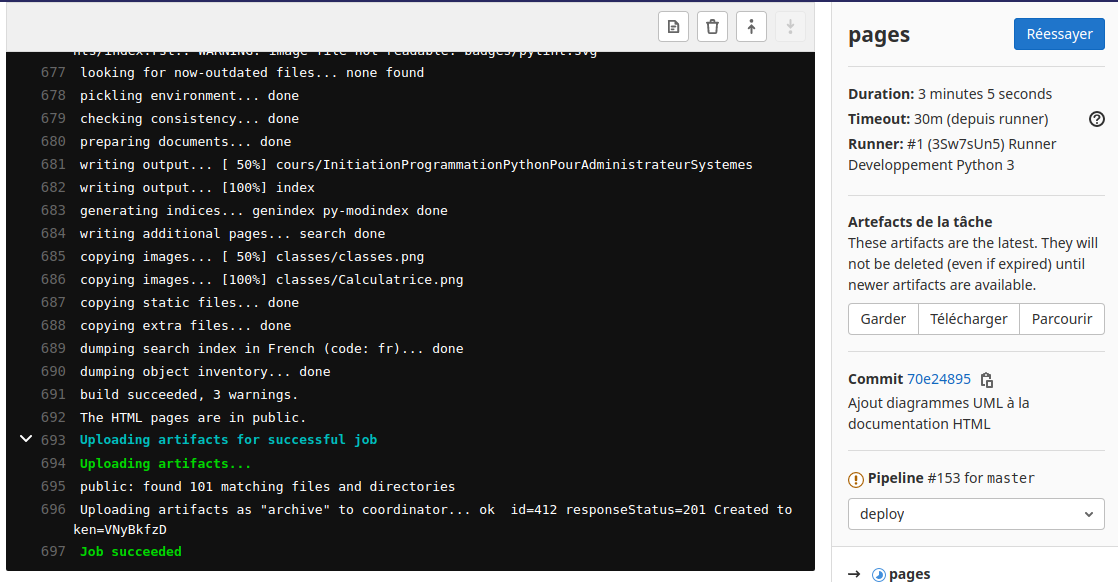
«Artefacts de la tâche»
Cliquer sur le bouton «Parcourir»
naviguer dans l’arborescence «public/classes»
La gestion des erreurs#
Les erreurs de syntaxe#
Jusqu’ici, les messages d’erreurs ont seulement été mentionnés. Mais si vous avez essayé les exemples vous avez certainement vu plus que cela. En fait, il y a au moins deux types d’erreurs à distinguer : les erreurs de syntaxe et les exceptions.
Les erreurs de syntaxe, qui sont des erreurs d’analyse du code, sont peut-être celles que vous rencontrez le plus souvent lorsque vous êtes encore en phase d’apprentissage de Python :
>>> while True print('Hello world')
File "<stdin>", line 1
while True print('Hello world')
^
SyntaxError: invalid syntax
L’analyseur indique la ligne incriminée et affiche une petite «flèche» pointant vers le premier endroit de la ligne où l’erreur a été détectée.
L’erreur est causée (ou, au moins, a été détectée comme telle) par le symbole placé avant la flèche. Dans cet exemple la flèche est sur la fonction print() car il manque deux points (”:”) juste avant. Le nom du fichier et le numéro de ligne sont affichés pour vous permettre de localiser facilement l’erreur lorsque le code provient d’un script.
Exceptions#
Même si une instruction ou une expression est syntaxiquement correcte, elle peut générer une erreur lors de son exécution. Les erreurs détectées durant l’exécution sont appelées des exceptions et ne sont pas toujours fatales : nous apprendrons bientôt comment les traiter dans vos programmes. La plupart des exceptions toutefois ne sont pas prises en charge par les programmes, ce qui génère des messages d’erreurs comme celui-ci :
>>> 10 * (1 / 0)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ZeroDivisionError: division by zero
>>> 4 + spam * 3
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'spam' is not defined
>>> '2' + 2
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: Can't convert 'int' object to str implicitly
La dernière ligne du message d’erreur indique ce qui s’est passé. Les exceptions peuvent être de différents types et ce type est indiqué dans le message : les types indiqués dans l’exemple sont ZeroDivisionError, NameError et TypeError. Le texte affiché comme type de l’exception est le nom de l’exception native qui a été déclenchée. Ceci est vrai pour toutes les exceptions natives mais n’est pas une obligation pour les exceptions définies par l’utilisateur (même si c’est une convention bien pratique). Les noms des exceptions standards sont des identifiants natifs (pas des mots-clef réservés).
Le reste de la ligne fournit plus de détails en fonction du type de l’exception et de ce qui l’a causée.
La partie précédente du message d’erreur indique le contexte dans lequel s’est produite l’exception, sous la forme d’une trace de pile d’exécution. En général, celle-ci contient les lignes du code source ; toutefois, les lignes lues à partir de l’entrée standard ne sont pas affichées.
Vous trouvez la liste des exceptions natives et leur signification dans Exceptions natives.
Gestion des exceptions#
Il est possible d’écrire des programmes qui prennent en charge certaines exceptions. Regardez l’exemple suivant, qui demande une saisie à l’utilisateur jusqu’à ce qu’un entier valide ait été entré, mais permet à l’utilisateur d’interrompre le programme (en utilisant Control-C ou un autre raccourci que le système accepte) ; notez qu’une interruption générée par l’utilisateur est signalée en levant l’exception KeyboardInterrupt.
>>> while True:
... try:
... x = int(input("Please enter a number: "))
... break
... except ValueError:
... print("Oops! That was no valid number. Try again...")
L’instruction try fonctionne comme ceci :
premièrement, la clause try (instruction(s) placée(s) entre les mots-clés try et except) est exécutée.
si aucune exception n’intervient, la clause except est sautée et l’exécution de l’instruction try est terminée.
si une exception intervient pendant l’exécution de la clause try, le reste de cette clause est sauté. Si le type d’exception levée correspond
à un nom indiqué après le mot-clé except, la clause except correspondante est exécutée, puis l’exécution continue après l’instruction try.
si une exception intervient et ne correspond à aucune exception mentionnée dans la clause except, elle est transmise à l’instruction try de niveau supérieur ; si aucun gestionnaire d’exception n’est trouvé, il s’agit d’une exception non gérée et l’exécution s’arrête avec un message comme indiqué ci-dessus.
Une instruction try peut comporter plusieurs clauses except pour permettre la prise en charge de différentes exceptions. Mais un seul gestionnaire, au plus, sera exécuté. Les gestionnaires ne prennent en charge que les exceptions qui interviennent dans la clause ! try correspondante, pas dans d’autres gestionnaires de la même instruction try. Mais une même clause except peut citer plusieurs exceptions sous la forme d’un tuple entre parenthèses, comme dans cet exemple :
... except (RuntimeError, TypeError, NameError):
... pass
Une classe dans une clause except est compatible avec une exception si elle est de la même classe ou d’une de ses classes dérivées. Mais l’inverse n’est pas vrai, une clause except spécifiant une classe dérivée n’est pas compatible avec une classe de base. Par exemple, le code suivant affiche B, C et D dans cet ordre :
class B(Exception):
pass
class C(B):
pass
class D(C):
pass
for cls in [B, C, D]:
try:
raise cls()
except D:
print("D")
except C:
print("C")
except B:
print("B")
Notez que si les clauses except avaient été inversées (avec except B: en premier), il aurait affiché B, B, B — la première clause except qui correspond est déclenchée.
La dernière clause except peut omettre le(s) nom(s) d’exception(s) et joue alors le rôle de joker. C’est toutefois à utiliser avec beaucoup de précautions car il est facile de masquer une vraie erreur de programmation par ce biais. Elle peut aussi être utilisée pour afficher un message d’erreur avant de propager l’exception (en permettant à un appelant de gérer également l’exception) :
import sys
try:
f = open('myfile.txt')
s = f.readline()
i = int(s.strip())
except OSError as err:
print("OS error: {0}".format(err))
except ValueError:
print("Could not convert data to an integer.")
except:
print("Unexpected error:", sys.exc_info()[0])
raise
L’instruction try … except accepte également une clause else optionnelle qui, lorsqu’elle est présente, doit se placer après toutes les clauses except. Elle est utile pour du code qui doit être exécuté lorsqu’aucune exception n’a été levée par la clause try. Par exemple :
for arg in sys.argv[1:]:
try:
f = open(arg, 'r')
except OSError:
print('cannot open', arg)
else:
print(arg, 'has', len(f.readlines()), 'lines')
f.close()
Il vaut mieux utiliser la clause else plutôt que d’ajouter du code à la clause try car cela évite de capturer accidentellement une exception qui n’a pas été levée par le code initialement protégé par l’instruction try … except.
Quand une exception intervient, une valeur peut lui être associée, que l’on appelle l’argument de l’exception. La présence de cet argument et son type dépendent du type de l’exception.
La clause except peut spécifier un nom de variable après le nom de l’exception. Cette variable est liée à une instance d’exception avec les arguments stockés dans instance.args. Pour plus de commodité, l’instance de l’exception définit la méthode __str__() afin que les arguments puissent être affichés directement sans avoir à référencer .args. Il est possible de construire une exception, y ajouter ses attributs, puis la lever plus tard.
>>> try:
... raise Exception('spam', 'eggs')
... except Exception as inst:
... print(type(inst)) # the exception instance
... print(inst.args) # arguments stored in .args
... print(inst) # __str__ allows args to be printed directly,
... # but may be overridden in exception subclasses
... x, y = inst.args # unpack args
... print('x =', x)
... print('y =', y)
...
<class 'Exception'>
('spam', 'eggs')
('spam', 'eggs')
x = spam
y = eggs
Si une exception a un argument, il est affiché dans la dernière partie du message des exceptions non gérées.
Les gestionnaires d’exceptions n’interceptent pas que les exceptions qui sont levées immédiatement dans leur clause try, mais aussi celles qui sont levées au sein de fonctions appelées (parfois indirectement) dans la clause try. Par exemple :
>>> def this_fails():
... x = 1 / 0
...
>>> try:
... this_fails()
... except ZeroDivisionError as err:
... print('Handling run-time error:', err)
... Handling run-time error: division by zero
Déclencher des exceptions#
L’instruction raise permet au programmeur de déclencher une exception spécifique. Par exemple :
>>> raise NameError('HiThere')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: HiThere
Le seul argument à raise indique l’exception à déclencher. Cela peut être soit une instance d’exception, soit une classe d’exception (une classe dérivée de Exception). Si une classe est donnée, elle est implicitement instanciée via l’appel de son constructeur, sans argument :
raise ValueError # shorthand for 'raise ValueError()'
Si vous avez besoin de savoir si une exception a été levée mais que vous n’avez pas intention de la gérer, une forme plus simple de l’instruction raise permet de propager l’exception :
>>> try:
... raise NameError('HiThere')
... except NameError:
... print('An exception flew by!')
... raise
...
An exception flew by!
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
NameError: HiThere
Chaînage d’exceptions#
L’instruction raise autorise un from optionnel qui permets de chaîner les exceptions en définissant l’attribut __cause__ de l’exception levée. Par exemple :
raise RuntimeError from OSError
Cela peut être utile lorsque vous transformez des exceptions. Par exemple :
>>> def func():
... raise IOError
...
>>> try:
... func()
... except IOError as exc:
... raise RuntimeError('Failed to open database') from exc
...
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
File "<stdin>", line 2, in func
OSError
L’exception ci-dessus était la cause directe de l’exception suivante :
Traceback (most recent call last):
File "<stdin>", line 4, in <module>
RuntimeError
L’expression suivant le from doit être soit une exception soit None. Le chaînage d’exceptions se produit automatiquement lorsqu’une exception est levée dans un gestionnaire d’exception ou dans une section finally.
Le chaînage d’exceptions peut être désactivé en utilisant l’idiome from None :
>>> try:
... open('database.sqlite')
... except IOError:
... raise RuntimeError from None
Traceback (most recent call last):
File "<stdin>", line 4, in <module>
RuntimeError
Exceptions définies par l’utilisateur#
Les programmes peuvent nommer leurs propres exceptions en créant une nouvelle classe d’exception. Les exceptions sont typiquement dérivées de la classe Exception, directement ou non.
Les classes d’exceptions peuvent être définies pour faire tout ce qu’une autre classe peut faire. Elles sont le plus souvent gardées assez simples, n’offrant que les attributs permettant aux gestionnaires de ces exceptions d’extraire les informations relatives à l’erreur qui s’est produite. Lorsque l’on crée un module qui peut déclencher plusieurs types d’erreurs distincts, une pratique courante est de créer une classe de base pour l’ensemble des exceptions définies dans ce module et de créer des sous-classes spécifiques d’exceptions pour les différentes conditions d’erreurs :
class Error(Exception):
"""Base class for exceptions in this module."""
pass
class InputError(Error):
"""Exception raised for errors in the input.
Attributes:
expression -- input expression in which the error occurred
message -- explanation of the error
"""
def __init__(self, expression, message):
self.expression = expression
self.message = message
class TransitionError(Error):
"""Raised when an operation attempts a state transition that's not allowed.
Attributes:
previous -- state at beginning of transition
next -- attempted new state
message -- explanation of why the specific transition is not allowed
"""
def __init__(self, previous, next, message):
self.previous = previous
self.next = next
self.message = message
La plupart des exceptions sont définies avec des noms qui se terminent par «Error», comme les exceptions standards.
Beaucoup de modules standards définissent leurs propres exceptions pour signaler les erreurs possibles dans les fonctions qu’ils définissent.
Définition d’actions de nettoyage#
L’instruction try a une autre clause optionnelle qui est destinée à définir des actions de nettoyage devant être exécutées dans certaines circonstances. Par exemple :
>>> try:
... raise KeyboardInterrupt
... finally:
... print('Goodbye, world!')
...
Goodbye, world!
KeyboardInterrupt
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
Si la clause finally est présente, la clause finally est la dernière tâche exécutée avant la fin du bloc try. La clause finally se lance même si le bloc try ne produit pas une exception.
Si une exception se produit durant l’exécution de la clause try, elle peut être récupérée par une clause except. Si l'exception n'est pas récupérée par une clause :python:`except, l’exception est levée à nouveau après que la clause finally a été exécutée.
Une exception peut se produire durant l’exécution d’une clause except ou else. Encore une fois, l’exception est reprise après que la clause que finally ait été exécuté.
Si dans l’exécution d’un bloc try, on atteint une instruction break, continue ou return, alors la clause finally s’exécute juste avant l’exécution de break, continue ou return.
Si la clause finally contient une instruction return, la valeur retournée sera celle du return de la clause finally, et non la valeur du return de la clause try.
Par exemple :
>>> def bool_return():
... try:
... return True
... finally:
... return False
...
>>> bool_return()
False
Un exemple plus compliqué :
>>> def divide(x, y):
... try:
... result = x / y
... except ZeroDivisionError:
... print("division by zero!")
... else:
... print("result is", result)
... finally:
... print("executing finally clause")
...
>>> divide(2, 1)
result is 2.0
executing finally clause
>>> divide(2, 0)
division by zero!
executing finally clause
>>> divide("2", "1")
executing finally clause
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 3, in divide
TypeError: unsupported operand type(s) for /: 'str' and 'str'
Comme vous pouvez le voir, la clause finally est exécutée dans tous les cas. L’exception de type TypeError, déclenchée en divisant deux chaînes de caractères, n’est pas prise en charge par la clause except et est donc propagée après que la clause finally a été exécutée.
Dans les vraies applications, la clause finally est notamment utile pour libérer des ressources externes (telles que des fichiers ou des connexions réseau), quelle qu’ait été l’utilisation de ces ressources.
Actions de nettoyage prédéfinies#
Certains objets définissent des actions de nettoyage standards qui doivent être exécutées lorsque l’objet n’est plus nécessaire, indépendamment du fait que l’opération ayant utilisé l’objet ait réussi ou non. Regardez l’exemple suivant, qui tente d’ouvrir un fichier et d’afficher son contenu à l’écran :
for line in open("myfile.txt"):
print(line, end="")
Le problème avec ce code est qu’il laisse le fichier ouvert pendant une durée indéterminée après que le code a fini de s’exécuter. Ce n’est pas un problème avec des scripts simples, mais peut l’être au sein d’applications plus conséquentes. L’instruction with permet d’utiliser certains objets comme des fichiers d’une façon qui assure qu’ils seront toujours nettoyés rapidement et correctement.
with open("myfile.txt") as f:
for line in f:
print(line, end="")
Après l’exécution du bloc, le fichier f est toujours fermé, même si un problème est survenu pendant l’exécution de ces lignes. D’autres objets qui, comme pour les fichiers, fournissent des actions de nettoyage prédéfinies l’indiquent dans leur documentation.
Les expressions régulières#
C’est un outil très puissant qui permet de vérifier un contenu suivant une forme attendue. Par exemple si on récupère un numéro de téléphone, une adresse postale, une adresse courriel, une adresse ip, une adresse mac, etc. on s’attend à ce que le contenu soit formaté d’une certaine façon. Les expressions régulières permettent non seulement de vous avertir d’une mauvaise syntaxe, mais également de supprimer/modifier cette syntaxe.
On utilise des symboles qui ont une action:
. ^ $ * + ? { } [ ] \ | ( )
Symbole |
Description de l’action |
|---|---|
^ |
Indique un commencement de segment, signifie aussi « contraire de ». |
$ |
Fin de segment. |
. |
Le point correspond à n’importe quel caractère. |
\ |
Est un caractère d’échappement |
\s |
Un espace, ce qui équivaut à [ \t\n\r\f\v]. |
\S |
Pas d’espace, ce qui équivaut à [^ \t\n\r\f\v]. |
\d |
le segment est composé uniquement de chiffre, ce qui équivaut à [0-9]. |
\D |
le segment n’est pas composé de chiffre, ce qui équivaut à [^0-9]. |
\w |
Présence alphanumérique, ce qui équivaut à [a-zA-Z0-9_]. |
\W |
Pas de présence alphanumérique [^a-zA-Z0-9_]. |
[xy] |
Une liste de segment possibble. Exemple [abc] équivaut à : a, b ou c. |
(x|y) |
Indique un choix multiple type (ps|top) équivaut à « ps » OU « top ». |
a{2} |
s’attend à ce que la lettre «a» se répète 2 fois consécutives. |
ba{1,9} |
s’attend à ce que le segment «ba» se répète de 1 à 9 fois consécutives. |
abc{,10} |
s’attend à ce que le segment «abc» ne soit pas présent du tout ou présent jusqu’à 10 fois consécutives. |
ab{1,} |
s’attend à ce que le segment «ba» soit présent au mois une fois. |
Symbole |
Nb Caractères attendus |
Exemple |
Cas possibles |
|---|---|---|---|
? |
0 ou 1 |
(.)?NIX |
NIX, U NIX etc. |
+ |
1 ou plus |
(.)+NIX |
U NIX, PHORO NIX, etc. |
* |
0, 1 ou plus |
(.)*NIX |
NIX, U NIX , PHORO NIX, etc. |
La bibliothèque re#
Créer un objet pour la recherche#
Si vous êtes amenés à utiliser plusieurs fois la même expression, vous pouvez la compiler pour gagner en performence. re.compile() permet de créer un objet expression régulière.
Lancez votre interpréteur python et importez la bibliothèque re.
>>> import re
>>> recherche = re.compile(r"(.)?NIX")
On affecte l’objet avec une expression régulière re.compile(), initialisé avec l’expression régulière r"(.)?NIX", à la variable Python recherche.
Recherches#
Recherches sur des mots#
match() est une méthode de l’objet re.compile() qui permet d’appliquer cette expression régulière sur une chaîne de caractères.
Testons avec une chaîne de caractères :
>>> recherche.match("UNIX")
<re.Match object; span=(0, 4), match='UNIX'>
La méthode match() recherche suivant l’expression régulière r"(.)?NIX" s’il y a une occurrence dans la chaîne "UNIX".
Si la réponse est …, match='UNIX' c’est que la chaîne a été trouvée.
>>> for mot in ["NIX", "UNIX", "LINUX", "PHORONIX", "WINDOWS", "MAC"]:
... recherche.match(mot)
...
<re.Match object; span=(0, 3), match='NIX'>
<re.Match object; span=(0, 4), match='UNIX'>
>>> recherche = re.compile(r"(.)+NIX")
>>> for mot in ["NIX", "UNIX", "LINUX", "PHORONIX", "WINDOWS", "MAC"]:
... recherche.match(mot)
...
<re.Match object; span=(0, 4), match='UNIX'>
<re.Match object; span=(0, 8), match='PHORONIX'>
>>> recherche = re.compile(r"(.)*NIX")
>>> for mot in ["NIX", "UNIX", "LINUX", "PHORONIX", "WINDOWS", "MAC"]:
... recherche.match(mot)
...
<re.Match object; span=(0, 3), match='NIX'>
<re.Match object; span=(0, 4), match='UNIX'>
<re.Match object; span=(0, 8), match='PHORONIX'>
Le but c’est d’anticiper si une expression est Vraie ou Fausse pour repérer le fonctionnement des expressions régulières.
>>> recherche = re.compile(r"L(.)?NUX")
>>> bool(recherche.match("LINUX"))
True
EXPRESSION |
CHAÎNE |
SOLUTION |
|---|---|---|
L(.)?NUX |
LINUX |
Vrai |
L(.)?NUX |
LNUX |
Vrai |
LI(.)?NUX |
LINUX |
Vrai |
LIN(.)? |
LINUX |
Vrai |
L(.)?UX |
LINUX |
Faux |
L(I)?N(U)?X |
LNX |
Vrai |
L(.)+X |
LINUX |
Vrai |
L(.)+(U)+X |
LINUX |
Vrai |
L(.)+([a-z])+X |
LINUX |
Faux |
L(.)+([A-Z])+X |
LINUX |
Vrai |
^! |
LINUX! |
Faux |
!$ |
LINUX! |
Faux |
^([A-Z])+$ |
LINUX! |
Faux |
^([A-Z!])+$ |
!LINUX! |
Vrai |
^!L(.)+!$ |
!LINUX! |
Vrai |
([0-9 ]) |
01 23 45 67 89 |
Vrai |
^0[0-9]([ .-/]?[0-9]{2}){4} |
01 23 45 67 89 |
Vrai |
^0[0-9]([ .-/]?[0-9]{2}){4} |
01-23-45-67-89 |
Faux |
^0[0-9]([ .-/]?[0-9]{2}){4} |
01-23-45-67-89 |
Vrai |
^0[0-9]([ .-/]?[0-9]{2}){4} |
01 23.45-67/89 |
Vrai |
Recherches dans une phrase#
Le recherche.match() est très intéressant pour valider l’intégrité d’un mot ou de numéros. Il est également possible de chercher des expressions spécifiques dans une chaîne de caractères.
>>> recherche.match("UNIX et mon LINUX sont dans les articles de PHORONIX.")
<re.Match object; span=(0, 52), match='UNIX et mon LINUX sont dans les articles de PHORO>
>>> recherche.match("UNIX et mon LINUX sont dans les articles de PHORONIX.").string
'UNIX et mon LINUX sont dans les articles de PHORONIX.'
>>> recherche = re.compile(r"(.)?NIX")
>>> recherche.match("UNIX et mon LINUX sont dans les articles de PHORONIX.")
<re.Match object; span=(0, 52), match='UNIX'>
>>> recherche.match("Mon UNIX et mon LINUX sont dans les articles de PHORONIX.")
La recherche commence dès le début de la chaîne de caractères et ne trouve donc aucune occurrence dans notre dernier exemple.
Pour rechercher l’occurrence dans une chaîne de caractères il faut utiliser recherche.search().
>>> recherche = re.compile(r"(.)?NIX")
>>> recherche.search("Mon UNIX et mon LINUX sont dans les articles de PHORONIX.")
<re.Match object; span=(4, 8), match='UNIX'>
Pour rechercher toutes les occurrences c’est recherche.findall().
>>> recherche = re.compile(r"\b[A-Z]+NIX\b")
>>> recherche.findall("Mon UNIX et mon LINUX sont dans les articles de PHORONIX.")
['UNIX', 'PHORONIX']
Il est également possible de chercher par groupe:
>>> recherche = re.search("Mon (?P<système1>\w+) et mon (?P<système2>\w+) sont dans les articles de (?P<revue>\w+).", "Mon UNIX et mon LINUX sont dans les articles de PHORONIX.")
>>> if recherche:
... print(recherche.group('système1'))
... print(recherche.group('système2'))
... print(recherche.group('revue'))
...
UNIX
LINUX
PHORONIX
Remplacer une expression#
Pour remplacer une expression on utilise la méthode re.sub().
>>> re.sub(r"Mon (?P<système1>\w+) et mon (?P<système2>\w+) sont dans les articles de (?P<revue>\w+).", r"\g<système1> et \g<système2> ont des articles dans \g<revue>","Mon UNIX et mon LINUX sont dans les articles de PHORONIX.")
'UNIX et LINUX ont des articles dans PHORONIX'
Le remplacement d’expressions se fait sur toutes les occurrences possibles:
>>> données = """
... Prénom1 Nom1 Age1;
... Prénom2 Nom2 Age2;
... Prénom2 Nom2 Age3;
... """
>>> print(re.sub(r"(?P<prenom>\w+) (?P<nom>\w+) (?P<age>\w+);", r"\g<nom> \g<prenom> a \g<age>", données))
Nom1 Prénom1 a Age1
Nom2 Prénom2 a Age2
Nom2 Prénom2 a Age3
Exercice de mise en pratique des expressions régulières#
Créer une expression qui reconnaît une adresse courriel
Lorsque vous commencez à rédiger une expression régulière, il ne faut pas être très ambitieux.
Toujours commencer petit, et coder étape par étape.
#! /usr/bin/env python3
# -*- coding: utf8 -*-
import re
mot = "TEST"
expressionreg = r"(TEST)"
if re.match(expressionreg, mot):
print("Vrai")
print(re.match(expressionreg, mot))
else:
print("Faux")
Si vous exécutez ce script, Vrai et <re.Match object; span=(0, 4), match='TEST'> seront affichés.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/11_ExpReg$ ./exemple1.py
Vrai
<re.Match object; span=(0, 4), match='TEST'>
Une adresse mail en gros ressemble à ça nom.prénom@fai.fr.
Commençons par le début, recherchons nom.prénom@, cela peut se traduire par ^[a-z0-9._-]+@.
#! /usr/bin/env python3
# -*- coding: utf8 -*-
import re
courriel = "nom.prénom@fai.fr"
expressionreg = r"^[a-z0-9._\-]+@"
if re.match(expressionreg, courriel):
print("Vrai")
print(re.match(expressionreg, courriel))
else:
print("Faux")
utilisateur@MachineUbuntu:~/repertoire_de_developpement/11_ExpReg$ ./exemple2.py
Faux
Le test est bon car la RFC 822 précise que les lettres accentuées ne sont pas autorisées pour les adresses courriel.
Modifier courriel = "nom.prenom@fai.fr"
Si vous exécutez à nouveau ce script, Vrai et <re.Match object; span=(0, 11), match='nom.prenom@'> seront affichés. Nous avons donc en retour d’occurrence nom.prenom@.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/11_ExpReg$ ./exemple2.py
Vrai
<re.Match object; span=(0, 11), match='nom.prenom@'>
Continuons en ajoutant [a-z0-9._-]+.
courriel = "nom.prenom@fai.fr"
expressionreg = r"^[a-z0-9._\-]+@[a-z0-9._\-]+"
utilisateur@MachineUbuntu:~/repertoire_de_developpement/11_ExpReg$ ./exemple3.py
Vrai
<re.Match object; span=(0, 17), match='nom.prenom@fai.fr'>
Continuons en ajoutant . pour ne pas avoir l’extension fr.
expressionreg = r"^[a-z0-9._\-]+@[a-z0-9._\-]+\."
utilisateur@MachineUbuntu:~/repertoire_de_developpement/11_ExpReg$ ./exemple4.py
Vrai
<re.Match object; span=(0, 15), match='nom.prenom@fai.'>
Testons ce code avec courriel = "nom.prenom@fai.service.fr".
courriel = "nom.prenom@fai.service.fr"
utilisateur@MachineUbuntu:~/repertoire_de_developpement/11_ExpReg$ ./exemple4.py
Vrai
<re.Match object; span=(0, 23), match='nom.prenom@fai.service.'>
Et enfin ajoutons un choix d’extensions avec (fr|org|net|com).
expressionreg = r"^[a-z0-9._\-]+@[a-z0-9._\-]+\.(fr|org|net|com)"
utilisateur@MachineUbuntu:~/repertoire_de_developpement/11_ExpReg$ ./exemple5.py
Vrai
<re.Match object; span=(0, 25), match='nom.prenom@fai.service.fr'>
Et voila, le résultat devrait être bon.
Stocker des données#
Lire et Écrire des fichiers#
Lecture et écriture de fichiers#
La fonction open() renvoie un objet fichier et est le plus souvent utilisée avec deux arguments : open(nomfichier, mode).
fichier = open(fichier, [code], [encoding=None])
Le premier argument est une chaîne contenant le nom du fichier (recherche le fichier dans le répertoire d’exécution de Python) ou le chemin avec le nom de fichier.
Le deuxième argument est une autre chaîne contenant quelques caractères décrivant la façon dont le fichier est utilisé :
Option |
Signification |
|---|---|
|
Le fichier n’est accédé qu’en lecture (par défaut). |
|
Ouvre le fichier en création exclusive (échoue si le fichier existe déjà). |
|
Ouvre le fichier en création (un fichier existant portant le même nom sera alors écrasé). |
|
Ouvre le fichier en mode ajout (toute donnée écrite dans le fichier est automatiquement ajoutée à la fin). |
Complément d’option |
Signification |
|---|---|
|
Ouvre le fichier en mode lecture/écriture. |
|
Mode texte (par défaut), les données sont lues et écrites sous formes de caractères. |
|
Mode binaire, les données sont lues et écrites sous formes d’octets (type bytes). |
L’argument mode est optionnel, sa valeur par défaut est 'r'.
'b' collé à la fin du mode est à utiliser pour les fichiers contenant autre chose que du texte.
fichier = open('mon_fichier.bin', 'rb')
L’argument encoding définit en mode texte l’encodage des données. Si aucun encodage n’est spécifié, l’encodage par défaut dépend de la plateforme (voir open()). Pour connaître cet encodage utilisez la méthode Python locale.getpreferredencoding(False).
En mode texte à la lecture, le comportement par défaut est de convertir les fins de lignes (\n sur Unix) avec celles spécifiques à la plateforme. Donc tous les \n sont convertis dans leur équivalent de la plateforme courante.
Ces modifications effectuées automatiquement sont normales pour du texte, mais détérioreraient les données binaires contenues dans un fichier de type JPEG ou EXE. Soyez particulièrement attentifs à ouvrir ces fichiers binaires en mode binaire.
Console Python ouvrir un fichier existant avec python.
>>> fichier = open('mon_fichier.ext')
Bien ouvrir ses fichiers#
C’est une bonne pratique d’utiliser le mot-clé with lorsque vous traitez des fichiers. Vous fermez ainsi toujours correctement le fichier, même si une exception est levée. Utiliser with est aussi beaucoup plus court que d’utiliser l’équivalent avec des blocs try … finally.
>>> with open('fichier.ext') as fichier:
... lecture_données = fichier.read()
...
>>> # Nous pouvons vérifier que le dossier a été automatiquement fermé.
>>> fichier.closed
True
Si vous n’utilisez pas le mot clef with, vous devez appeler fichier.close() pour fermer le fichier et immédiatement libérer les ressources système qu’il utilise. Si vous ne fermez pas explicitement le fichier, le ramasse-miette de Python finira par détruire l’objet et fermer le
fichier pour vous. Mais le fichier peut rester ouvert pendant un moment. Un autre risque est que les différentes implémentations de Python fassent ce nettoyage à des moments différents.
Après la fermeture du fichier, que ce soit via une instruction with ou en appelant fichier.close(), toute tentative d’utilisation de l’objet fichier échoue systématiquement.
>>> fichier.close()
>>> fichier.read()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: I/O operation on closed file.
Méthodes des objets fichiers#
Pour lire le contenu d’un fichier partiellement, vous pouvez appeler la méthode read comme cela fichier.read(taille). Cette dernière lit une certaine quantité de données et la renvoie sous forme de chaîne (en mode texte) ou d’objet bytes (en mode binaire). taille est un argument numérique facultatif.
Lorsque taille est omis ou négatif, la totalité du contenu du fichier sera lue et retournée. C’est votre problème de développeur si le fichier est deux fois plus grand que la mémoire de votre machine.
La méthode ne peut lire ou renvoyer au maximum que la taille de caractères (en mode texte) ou la taille d’octets (en mode binaire).
Lorsque la fin du fichier est atteinte, fichier.read() renvoie une chaîne vide ''.
>>> fichier.read()
'Ceci est le fichier entier.\n'
>>> fichier.read()
''
fichier.readline() lit une seule ligne du fichier.
Un caractère de fin de ligne \n est laissé à la fin de la chaîne. Si le fichier ne se termine pas par un caractère de fin de ligne, ce caractère n’est omis par fichier.readline() que pour la dernière ligne du fichier. Ceci permet de rendre la valeur de retour non ambigüe.
Si fichier.readline() renvoie une chaîne vide, c’est que la fin du fichier a été atteinte.
>>> fichier.readline()
'Ceci est la première ligne du fichier.\n'
>>> fichier.readline()
'Deuxième ligne du fichier\n'
>>> fichier.readline()
''
Pour lire ligne à ligne, vous pouvez aussi boucler sur l’objet fichier. C’est plus efficace en terme de gestion mémoire, plus rapide et donne un code plus simple :
>>> for ligne in fichier:
... print(ligne, end='')
...
Ceci est la première ligne du fichier.
Deuxième ligne du fichier
Pour construire une liste avec toutes les lignes d’un fichier, il est aussi possible d’utiliser list(fichier) ou fichier.readlines().
fichier.write(chaine) écrit le contenu d’une chaîne dans le fichier et renvoie le nombre de caractères écrits.
>>> fichier.write('Ceci est un test\n')
17
Les autres types de données Python doivent être convertis. Soit en une chaîne (en mode texte) str(), soit en objet bytes (en mode binaire) bytes() avant de les écrire :
>>> valeur = ('la réponse', 42)
>>> untuple = str(valeur) # convertir le tuple en chaîne
>>> fichier.write(untuple)
18
ficher.tell() renvoie un entier indiquant la position actuelle dans le fichier, mesurée en octets à partir du début du fichier lorsque le fichier est ouvert en mode binaire, ou en nombre de caractères pour le mode texte.
Pour modifier la position dans le fichier, utilisez fichier.seek(décalage, origine). La position est calculée en ajoutant décalage à un point de référence. Ce point de référence est déterminé par l’argument origine.
Valeur |
Signification |
|---|---|
|
Pour le début du fichier. |
1 |
Pour la position actuelle. |
2 |
Pour la fin du fichier. |
origine peut être omis et sa valeur par défaut est 0 (Python utilise le début du fichier comme point de référence).
>>> fichier = open('fichier.bin', 'rb+')
>>> fichier.write(b'0123456789abcdef')
16
>>> fichier.seek(5) # Va au 6ème octet du fichier
5
>>> fichier.read(1)
b'5'
>>> fichier.seek(-3, 2) # Va au 3ème octet avant la fin
13
>>> fichier.read(1)
b'd'
Sur un fichier en mode texte (ceux ouverts sans 'b' dans le mode), seuls les changements de positions relatifs au début du fichier sont autorisés (sauf après une exception où Python se rend alors à la fin du fichier avec seek(0, 2)), et les seules valeurs possibles pour le paramètre décalage sont les valeurs renvoyées par fichier.tell(), ou zéro. Toute autre valeur pour le paramètre décalage produit un comportement indéfini.
L’objet fichier dispose de méthodes supplémentaires, telles que isatty() et truncate() qui sont moins souvent utilisées. Consultez la Référence de la Bibliothèque Standard pour avoir un guide complet des objets fichiers.
Stocker des objets#
pickle#
le module pickle permet de sauvegarder dans un fichier, au format binaire, n’importe quel objet Python.
En clair, si pour une raison quelconque, dans un script Python, vous avez besoin de sauvegarder, temporairement ou même de façon plus pérenne, le contenu d’un objet Python (une liste, un dictionnaire, un tuple etc.) au lieu d’utiliser une base de données ou un simple fichier texte, le module pickle est fait pour ça.
Il permet de stocker et de restaurer un objet Python, tel quel, sans aucune manipulation supplémentaire.
>>> import pickle
>>> import string
>>> ma_liste = list(string.ascii_letters)
>>> ma_liste
['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z']
>>> with open('monfichierpickle', 'wb') as fichier:
... pickle.dump(ma_liste, fichier)
...
>>> with open('monfichierpickle', 'rb') as fichier:
... fichier.read()
...
b'\x80\x04\x95\xd5\x00\x00\x00\x00\x00\x00\x00]\x94(\x8c\x01a\x94\x8c\x01b\x94\x8c\x01c\x94\x8c\x01d\x94\x8c\x01e\x94\x8c\x01f\x94\x8c\x01g\x94\x8c\x01h\x94\x8c\x01i\x94\x8c\x01j\x94\x8c\x01k\x94\x8c\x01l\x94\x8c\x01m\x94\x8c\x01n\x94\x8c\x01o\x94\x8c\x01p\x94\x8c\x01q\x94\x8c\x01r\x94\x8c\x01s\x94\x8c\x01t\x94\x8c\x01u\x94\x8c\x01v\x94\x8c\x01w\x94\x8c\x01x\x94\x8c\x01y\x94\x8c\x01z\x94\x8c\x01A\x94\x8c\x01B\x94\x8c\x01C\x94\x8c\x01D\x94\x8c\x01E\x94\x8c\x01F\x94\x8c\x01G\x94\x8c\x01H\x94\x8c\x01I\x94\x8c\x01J\x94\x8c\x01K\x94\x8c\x01L\x94\x8c\x01M\x94\x8c\x01N\x94\x8c\x01O\x94\x8c\x01P\x94\x8c\x01Q\x94\x8c\x01R\x94\x8c\x01S\x94\x8c\x01T\x94\x8c\x01U\x94\x8c\x01V\x94\x8c\x01W\x94\x8c\x01X\x94\x8c\x01Y\x94\x8c\x01Z\x94e.'
>>> autre_liste = None
>>> print(autre_liste)
None
>>> with open('monfichierpickle', 'rb') as fichier:
... autre_liste = pickle.load(fichier)
>>> type(autre_liste)
<class 'list'>
>>> autre_liste
['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z']
>>> ma_liste == autre_liste
True
On peut faire la même chose avec un tuple :
mon_tuple = tuple(string.ascii_letters)
Avec un dictionnaire ou même ses propres objets… Dans ce cas la classe de l’objet stocké doit être disponible pour pouvoir être utilisée via load du module pickle, sinon une erreur AttributeError est alors levée.
Stocker des données de façon persistante#
Archivage (zip)#
Avec python on peut compresser des fichiers au format zip avec le module zipfile. On peut aussi utiliser shutil qui est de plus haut niveau mais moins souple.
Il nous faut utiliser l’objet ZipFile du module zipfile pour créer, modifier ou ouvrir un fichier zip à l’image du traitement des fichiers sous Python.
import zipfile
with zipfile.ZipFile(fichier_destination, 'w') as donnees_zip:
# …
Compression de fichiers individuels#
La méthode write() de l’objet ZipFile permet d’envoyer le fichier à compresser.
import zipfile
fichier_destination = 'mon_fichier.zip'
fichier_a_compresser = 'mon_fichier.pdf'
with zipfile.ZipFile(fichier_destination, 'w') as donnees_zip:
donnees_zip.write(fichier_a_compresser, compress_type = zipfile.ZIP_DEFLATED)
Il faut indiquer l’option zipfile.ZIP_DEFLATED, sinon l’archive n’est pas compressée par défaut.
Compression de plusieurs fichiers#
import os
import zipfile
fichier_destination = 'mon_fichier.zip'
dossier_fichier_a_compresser = 'mon_dossier'
with zipfile.ZipFile(fichier_destination, 'w') as donnees_zip:
for dossier_parent, sous-dossier, fichier in os.walk(dossier_fichiers_a_compresse):
if '.pdf' in fichier[0]: # pour les fichiers pdf
donnees_zip.write (os.path.join(sous-dossier, fichier), os.path.relpath (os.path.join (sous-dossier, fichier) , dossier_fichiers_a_compresser), compress_type = zipfile.ZIP_DEFLATED)
Pour compresser les fichiers sans le répertoire il faut modifier :
donnees_zip.write (os.path.join (dossier, fichier), fichier, compress_type = zipfile.ZIP_DEFLATED)
Extraire les fichiers#
import zipfile
fichier_zip = 'mon_fichier.zip'
dossier_destination = 'mon_dossier'
with zipfile.ZipFile(fichier_zip) as donnees_zip:
donnees_zip.extractall(dossier_destination)
Extraire des fichiers individuels#
import zipfile
fichier_zip = 'mon_fichier.zip'
dossier_destination = 'mon_dossier'
fichiers_a_extraires = ['mon_fichier1.pdf', 'mon_fichier2.pdf']
with zipfile.ZipFile(fichier_zip) as donnees_zip:
for fichier in fichiers_a_extraires:
donnees_zip.extract (fichier, dossier_destination)
Mais là nous n’avons aucune garantie que le fichier soit présent dans le zip.
Lecture de fichiers Zip#
import zipfile
fichier_zip = 'mon_fichier.zip'
dossier_destination = 'mon_dossier'
fichiers_a_extraires = ['mon_fichier1.pdf', 'mon_fichier2.pdf']
with zipfile.ZipFile(fichier_zip) as donnees_zip:
for fichier in fichiers_a_extraires:
# pour un fichier dans le zip
for fichier in donnees_zip.namelist():
donnees_zip.extract(fichier, dossier_destination)
Commande |
Signification |
|---|---|
|
Pour ouvrir le fichier zip au début. |
|
Pour indiquer le mot de passe si le zip est crypté (qui doit être converti en bytes, d’où |
|
Donne la liste des fichiers contenus dans l’archive (avec leur chemin). |
|
Récupère un objet d’information |
|
On peut aussi directement avoir tous les objets info_zip de l’archive. |
|
Extrait tous les fichiers dans le répertoire courant (en respectant l’arborescence du zip). |
|
Extrait tous les fichiers dans le répertoire cible donné (en respectant l’arborescence du zip). |
|
extrait seulement le fichier indiqué (présent dans le zip) dans le répertoire indiqué. |
Propriété |
Signification |
|---|---|
|
Taille originale du fichier. |
|
Taille compressée. |
|
Nom du fichier. |
|
Date du fichier |
Commande |
Signification |
|---|---|
|
Création d’une nouvelle archive chemin/mon_fichier.zip (il faut indiquer ZIP_DEFLATED, sinon, elle n’est pas compressée par défaut). |
|
Ajoute un fichier avec son chemin réel et dans l’archive. |
|
Fermeture le fichier de l’archive. |
|
On peut décider du chemin exact du fichier dans l’archive quelque soit l’endroit où se trouve le fichier. Le fichier est physiquement dans mon_chemin1, mais dans l’archive, il sera dans chemin2. |
Pour approfondir voir Travailler avec des archives ZIP.
CSV#
Nous utilisons souvent des tableurs dans notre bureautique numérique. Le format couramment utilisé pour échanger des données est le CSV (Comma Separated Values). Comme son nom anglo-saxon l’indique, c’est un format texte de données séparées avec des virgules ,. Mais ces données peuvent-être représentées avec des virgules. Il est donc préférable d’utiliser des tabulations ou encore des points virgules comme séparateur de vos données.
Créer le fichier «exemple.csv»
identifiant;nom;prénom
PreNM;NOM,Prénom
UtBD;BIDON;Utilisateur
MaPER;PERSONNE;Ma;Pas;Bon;
Pour lire ce genre de fichier avec Python, on utilise le module csv avec la méthode reader().
>>> import csv
>>> with open('exemple.csv') as fichiercsv:
... lecture = csv.reader(fichiercsv, delimiter=';', quotechar='\'')
... for données in lecture:
... print(données)
...
['identifiant', 'nom', 'prénom']
['PreNM', 'NOM,Prénom']
['UtBD', 'BIDON', 'Utilisateur']
['MaPER', 'PERSONNE', 'Ma', 'Pas', 'Bon', '']
Pour écrire dans ce fichier avec Python, on utilise l’objet writer et sa méthode writerow().
>>> import csv
>>> with open('exemple.csv', 'a') as fichiercsv:
... écriture = csv.writer(fichiercsv, delimiter=';', quotechar='\'', quoting=csv.QUOTE_MINIMAL)
... écriture.writerow(['identifiant', 'MonNOM', 'MonPrénom'])
...
30
Le fichier «exemple.csv» est devenu
identifiant;nom;prénom
PreNM;NOM,Prénom
UtBD;BIDON;Utilisateur
MaPER;PERSONNE;Ma;Pas;Bon;
identifiant;MonNOM;MonPrénom
Pour plus d’informations voir la documentation Lecture et écriture de fichiers CSV.
JSON#
Les chaînes de caractères peuvent facilement être écrites dans un fichier et relues. Les nombres nécessitent un peu plus d’effort, car la méthode read() ne renvoie que des chaînes. Elles doivent donc être passées à une fonction comme int(), qui prend une chaîne comme '123' en entrée et renvoie sa valeur numérique 123. Mais dès que vous voulez enregistrer des types de données plus complexes comme des listes, des dictionnaires ou des instances de classes, le traitement lecture/écriture avec le code devient vite compliqué.
Plutôt que de passer son temps à écrire et déboguer du code permettant de sauvegarder des types de données compliqués, Python permet d’utiliser JSON (JavaScript Object Notation), un format répandu de représentation et d’échange de données.
Le module standard json peut transformer des données de Python en une représentation sous forme de chaîne de caractères.
Ce processus est nommé sérialiser. Reconstruire les données à partir de leur représentation sous forme de chaîne est appelé déserialiser. Entre sa sérialisation et sa désérialisation, la chaîne représentant les données peut avoir été stockée ou transmise à une autre machine.
Note
Le format JSON est couramment utilisé dans les applications modernes pour échanger des données. Beaucoup de développeurs le maîtrise, ce qui en fait un format de prédilection pour l’interopérabilité.
Si vous avez un objet quelconque, vous pouvez voir sa représentation JSON en tapant simplement :
>>> import json
>>> json.dumps([1, 'simple', 'list'])
'[1, "simple", "list"]'
Une variante de la fonction dumps(), nommée dump(), sérialise simplement l’objet donné vers un fichier texte. Donc si fichier est un fichier texte ouvert en écriture, il est possible de faire :
json.dump(x, fichier)
Pour reconstruire l’objet, si fichier est cette fois un fichier texte ouvert en lecture :
x = json.load(fichier)
Cette méthode de sérialisation peut sérialiser des listes et des dictionnaires, mais aussi sérialiser d’autres types de données. Cela requiert un peu plus de travail et la documentation du module json explique comment faire.
XML#
Maintenant passons à la dimension supérieure du traitement de ces données. On veut maintenant échanger des données, comme avec JSON, mais avec la possibilité de définir ses propres standards de données (au delà des types de Python). Pour cela il existe un façon standard de le faire c’est le XML (eXtensible Markup Language).
Le XML permet de définir sa propre représentation des données dans un fichier «.xml», tout en spécifiant sa syntaxe DTD (Document Type Definition) dans un fichier «.dtd» qui va préciser la grammaire, et un schéma qui va préciser les propriétés de son vocabulaire.
La Validation#
Nous allons devoir définir suivant la norme DSDL (Document Schema Definition Language) la syntaxe et ses propriétés du code XML.
Schéma DTD#
Pour tester sous Python la validité de la grammaire XML de notre code avec une DTD, il nous faut installer le module lxml.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/12_Données$ sudo pip install lxml
Testons maintenant la conformité XML.
Cette syntaxe est :
utilisateurs : Une liste d’utilisateurs.
utilisateur : un utilisateur avec une option d’identifiant obligatoire.
nom : le nom de l’utilisateur (chaîne de caractères alpha).
prenom : le prénom de l’utilisateur (chaîne de caractères alpha).
sexe : le sexe de l’utilisateur défini avec une option biologique obligatoire, dont les valeurs possibles sont H = Homme, F = Femme, S = Sans, 2 = Hermaphrodite. Et une option social avec les valeurs possibles H = Homme, F = Femme, B = 2 sexes, S = pas de sexualité, Faux = pas de particularité sexuelle sociale.
age : l’age de l’utilisateur (nombre entier limité à 150 ans).
adresse : l’adresse de l’utilisateur (chaîne alphanumérique).
codepostal : Un nombre de 5 chiffres numériques.
ville : la ville de l’utilisateur (chaîne alphanumérique de maximum 163 caractères).
Testons la validation de balises (ELEMENT) pour cela nous allons utiliser l’objet etree.DTD() pour saisir nos règles de syntaxe, l’objet etree.XML() pour saisir notre code XML, et enfin la méthode validate() de l’objet DTD pour tester la bonne conformité de la grammaire.
>>> from io import StringIO
>>> from lxml import etree
>>> texte_dtd = StringIO("<!ELEMENT utilisateur EMPTY>")
>>> dtd = etree.DTD(texte_dtd)
>>> xml = etree.XML("<utilisateur/>")
>>> dtd.validate(xml)
True
>>> xml = etree.XML("<utilisateur>Du blabla</utilisateur>")
>>> dtd.validate(xml)
False
>>> dtd.error_log
<string>:1:0:ERROR:VALID:DTD_NOT_EMPTY: Element utilisateur was declared EMPTY this one has content
Nous avons introduit à la fin dtd.error_log qui permet de visualiser les problèmes de syntaxe dans le code XML.
Testons et saisissons maintenant la grammaire de tous les tags XML.
>>> texte_dtd = StringIO("<!ELEMENT utilisateur (#PCDATA)>")
>>> dtd = etree.DTD(texte_dtd)
>>> dtd.validate(xml)
>>> texte_dtd = StringIO("<!ELEMENT utilisateurs (utilisateur+)><!ELEMENT utilisateur (#PCDATA)>")
>>> dtd = etree.DTD(texte_dtd)
>>> xml = etree.XML("<utilisateurs><utilisateur>Premier</utilisateur></utilisateurs>")
>>> dtd.validate(xml)
True
>>> xml = etree.XML("<utilisateurs><utilisateur>Premier</utilisateur><utilisateur>Deuxième</utilisateur></utilisateurs>")
>>> dtd.validate(xml)
True
>>> texte_dtd = StringIO("<!ELEMENT utilisateurs (utilisateur+)><!ELEMENT utilisateur (nom, prenom, sexe, age, adresse, codepostal, ville)><!ELEMENT nom (#PCDATA)><!ELEMENT prenom (#PCDATA)><!ELEMENT sexe EMPTY><!ELEMENT age (#PCDATA)><!ELEMENT adresse (#PCDATA)><!ELEMENT codepostal (#PCDATA)><!ELEMENT ville (#PCDATA)>")
>>> dtd = etree.DTD(texte_dtd)
>>> xml = etree.XML("<utilisateurs><utilisateur><nom>NOM</nom><prenom>Prénom</prenom><sexe/><age>70</age><adresse>Lieu de vie</adresse><codepostal>34110</codepostal><ville>FRONTIGNAN</ville></utilisateur></utilisateurs>")
>>> dtd.validate(xml)
True
Abordons maintenant les options des tags XML (ATTLIST).
>>> texte_dtd = StringIO("<!ELEMENT utilisateurs (utilisateur+)><!ELEMENT utilisateur (nom, prenom, sexe, age, adresse, codepostal, ville)><!ATTLIST utilisateur identifiant CDATA #REQUIRED><!ELEMENT nom (#PCDATA)><!ELEMENT prenom (#PCDATA)><!ELEMENT sexe (#PCDATA)><!ATTLIST sexe biologique (H|F|2|S) #REQUIRED><!ATTLIST sexe social (H|F|B|S|False) 'False'><!ELEMENT age (#PCDATA)><!ELEMENT adresse (#PCDATA)><!ELEMENT codepostal (#PCDATA)><!ELEMENT ville (#PCDATA)>")
>>> dtd = etree.DTD(texte_dtd)
>>> dtd.validate(xml)
False
>>> dtd.error_log
<string>:1:0:ERROR:VALID:DTD_MISSING_ATTRIBUTE: Element utilisateur does not carry attribute identifiant
<string>:1:0:ERROR:VALID:DTD_MISSING_ATTRIBUTE: Element sexe does not carry attribute biologique
>>> xml = etree.XML("<utilisateurs><utilisateur identifiant='1'><nom>NOM</nom><prenom>Prénom</prenom><sexe biologique='H'/><age>70</age><adresse>Lieu de vie</adresse><codepostal>34110</codepostal><ville>FRONTIGNAN</ville></utilisateur></utilisateurs>")
>>> dtd.validate(xml)
True
>>> xml = etree.XML("<utilisateurs><utilisateur identifiant='1'><nom>NOM</nom><prenom>Prénom</prenom><sexe biologique='H' social='F'/><age>70</age><adresse>Lieu de vie</adresse><codepostal>34110</codepostal><ville>FRONTIGNAN</ville></utilisateur></utilisateurs>")
>>> dtd.validate(xml)
True
>>> xml = etree.XML("<utilisateurs><utilisateur identifiant='1'><nom>NOM</nom><prenom>Prénom</prenom><sexe biologique='H' social=''/><age>70</age><adresse>Lieu de vie</adresse><codepostal>34110</codepostal><ville>FRONTIGNAN</ville></utilisateur></utilisateurs>")
>>> dtd.validate(xml)
False
>>> dtd.error_log
<string>:1:0:ERROR:VALID:DTD_ATTRIBUTE_VALUE: Syntax of value for attribute social of sexe is not valid
<string>:1:0:ERROR:VALID:DTD_ATTRIBUTE_VALUE: Value "" for attribute social of sexe is not among the enumerated set
Exemple xml avec le fichier «personnes.xml».
<?xml version="1.0" encoding="utf-8"?>
<utilisateurs identifiant="1">
<utilisateur>
<nom>NOM</nom>
<prenom>Prénom</prenom>
<sexe biologique='H'/>
<age>70</age>
<adresse>Lieu de vie</adresse>
<codepostal>34110</codepostal>
<ville>FRONTIGNAN</ville>
</utilisateur>
<utilisateur identifiant="2">
<nom>MONNOM</nom>
<prenom>MonPrénom</prenom>
<sexe biologique='F'/>
<age>40</age>
<adresse>Mon lieu de vie</adresse>
<codepostal>34000</codepostal>
<ville>MONTPELLIER</ville>
</utilisateur>
<utilisateur identifiant="3">
<nom>PERSONNE</nom>
<prenom>Jesuis</prenom>
<sexe biologique='H' indetermine='F'/>
<age>25</age>
<adresse>Sans lieu de vie</adresse>
<codepostal>34200</codepostal>
<ville>SÈTE</ville>
</utilisateur>
<utilisateur identifiant="4">
<nom>UNIVERSEL</nom>
<prenom>Divain</prenom>
<sexe biologique='2'/>
<age>15</age>
<adresse>Lieu sain</adresse>
<codepostal>34130</codepostal>
<ville>SAINT-AUNÈS</ville>
</utilisateur>
<utilisateur identifiant="5">
<nom>DIFFÉRENT</nom>
<prenom>Être</prenom>
<sexe biologique='S'/>
<age>33</age>
<adresse>Lieu de vie normal</adresse>
<codepostal>34260</codepostal>
<ville>LE BOUSQUET-D'ORB</ville>
</utilisateur>
</utilisateurs>
Créons le fichiers «personnes.dtd».
<!ELEMENT utilisateurs (utilisateur+)>
<!ELEMENT utilisateur (nom, prenom, sexe, age, adresse, codepostal, ville)>
<!ATTLIST utilisateur identifiant CDATA #REQUIRED>
<!ELEMENT nom (#PCDATA)>
<!ELEMENT prenom (#PCDATA)>
<!ELEMENT sexe EMPTY>
<!ATTLIST sexe biologique (H|F|2|S) #REQUIRED>
<!ATTLIST sexe social (H|F|B|S|False) 'False'>
<!ELEMENT age (#PCDATA)>
<!ELEMENT adresse (#PCDATA)>
<!ELEMENT codepostal (#PCDATA)>
<!ELEMENT ville (#PCDATA)>
Testons avec ces deux fichiers la DTD et le code Python. Abordons l’objet etree.parse() qui nous permet de charger directement un fichier XML.
>>> from lxml import etree
>>> dtd = etree.DTD('personnes.dtd')
>>> xml = etree.XML("<utilisateurs>\n<utilisateur identifiant='1'>\n<nom>NOM</nom>\n<prenom>Prénom</prenom>\n<sexe biologique='H' social='F'/>\n<age>70</age>\n<adresse>Lieu de vie</adresse>\n<codepostal>34110</codepostal>\n<ville>FRONTIGNAN</ville>\n</utilisateur>\n</utilisateurs>")
>>> dtd.validate(xml)
True
>>> with open('personnes.xml', 'r') as filexml:
... xml = filexml.read()
... xml = etree.XML(xml)
... dtd.validate(xml)
...
True
>>> xml = etree.parse('personnes.xml')
>>> dtd.validate(xml)
True
Schéma XML XSD#
Maintenant validons notre code XML avec le format XSD.
>>> xsd = StringIO('''\
... <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
... <xs:complexType name="TypeUtilisateur">
... <xs:sequence>
... <xs:element name="nom" type="xs:string"/>
... <xs:element name="prenom" type="xs:string"/>
... <xs:element name="sexe" type="xs:string"/>
... <xs:element name="age" type="xs:integer"/>
... <xs:element name="adresse" type="xs:string"/>
... <xs:element name="codepostal" type="xs:integer"/>
... <xs:element name="ville" type="xs:string"/>
... </xs:sequence>
... </xs:complexType>
... <xs:element name="utilisateur" type="TypeUtilisateur"/>
... </xs:schema>
... ''')
>>> parsexmlxsd = etree.parse(xsd)
>>> xmlxsd = etree.XMLSchema(parsexmlxsd)
>>> xml = StringIO("<utilisateur><nom>NOM</nom><prenom>Prénom</prenom><sexe/><age>70</age><adresse>Lieu de vie</adresse><codepostal>34110</codepostal><ville>FRONTIGNAN</ville></utilisateur>")
>>> codexml = etree.parse(xml)
>>> xmlxsd.validate(codexml)
True
Ajoutons l’imbrication dans le tag utilisateurs.
xsd = StringIO('''<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="utilisateurs">
<xs:complexType>
<xs:sequence>
<xs:element name="utilisateur" type="UtilisateurType" minOccurs="1" maxOccurs="unbounded"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:complexType name="UtilisateurType">
<xs:sequence>
<xs:element name="nom" type="xs:string"/>
<xs:element name="prenom" type="xs:string"/>
<xs:element name="sexe" type="xs:string"/>
<xs:element name="age" type="xs:integer"/>
<xs:element name="adresse" type="xs:string"/>
<xs:element name="codepostal" type="xs:integer"/>
<xs:element name="ville" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:schema>
''')
parsexmlxsd = etree.parse(xsd)
xmlxsd = etree.XMLSchema(parsexmlxsd)
>>> xml = StringIO("<utilisateurs><utilisateur><nom>NOM</nom><prenom>Prénom</prenom><sexe/><age>70</age><adresse>Lieu de vie</adresse><codepostal>34110</codepostal><ville>FRONTIGNAN</ville></utilisateur></utilisateurs>")
>>> codexml = etree.parse(xml)
>>> xmlxsd.validate(codexml)
True
Ajoutons un attribut.
>>> xsd = StringIO('''<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
... <xs:element name="utilisateurs">
... <xs:complexType>
... <xs:sequence>
... <xs:element name="utilisateur" type="UtilisateurType" minOccurs="1" maxOccurs="unbounded"/>
... </xs:sequence>
... </xs:complexType>
... </xs:element>
...
... <xs:complexType name="UtilisateurType">
... <xs:sequence>
... <xs:element name="nom" type="xs:string"/>
... <xs:element name="prenom" type="xs:string"/>
... <xs:element name="sexe" type="xs:string"/>
... <xs:element name="age" type="xs:integer"/>
... <xs:element name="adresse" type="xs:string"/>
... <xs:element name="codepostal" type="xs:integer"/>
... <xs:element name="ville" type="xs:string"/>
... </xs:sequence>
... <xs:attribute name="identifiant" use="required" type="xs:positiveInteger"/>
... </xs:complexType>
... </xs:schema>
... ''')
>>> parsexmlxsd = etree.parse(xsd)
>>> xmlxsd = etree.XMLSchema(parsexmlxsd)
>>> codexml = etree.parse(xml)
>>> xmlxsd.validate(codexml)
False
>>> xml = StringIO("<utilisateurs><utilisateur identifiant='1'><nom>NOM</nom><prenom>Prénom</prenom><sexe/><age>70</age><adresse>Lieu de vie</adresse><codepostal>34110</codepostal><ville>FRONTIGNAN</ville></utilisateur></utilisateurs>")
>>> codexml = etree.parse(xml)
>>> xmlxsd.validate(codexml)
True
Pour la suite je vous laisse à l’apprentissage du XSD dans une formation XML.
La lecture#
Maintenant que nous avons validé la syntaxe du XML, nous allons parcourir avec Python les éléments dans un fichier XML. Pour cela nous allons utiliser la bibliothèque native xml.
>>> import xml.etree.ElementTree as ArbreXML
>>> structurexml = ArbreXML.parse('personnes.xml')
>>> racinexml = structurexml.getroot()
>>> racinexml.tag
'utilisateurs'
>>> racinexml.attrib
{}
>>> for enfant in racinexml:
... print(enfant.tag, enfant.attrib)
...
utilisateur {'identifiant': '1'}
utilisateur {'identifiant': '2'}
utilisateur {'identifiant': '3'}
utilisateur {'identifiant': '4'}
utilisateur {'identifiant': '5'}
>>> racinexml[0][1].text
'Prénom'
>>> racinexml[0][0].text
'NOM'
>>> for nom in structurexml.iter('nom'):
... print(nom.text)
...
NOM
MONNOM
PERSONNE
UNIVERSEL
DIFFÉRENT
>>> for utilisateur in structurexml.findall('utilisateur'):
... identifiant = utilisateur.get('identifiant')
... prénom = utilisateur.find('prenom').text
... nom = utilisateur.find('nom').text
... print(identifiant, prénom, nom)
...
1 Prénom NOM
2 MonPrénom MONNOM
3 Jesuis PERSONNE
4 Divain UNIVERSEL
5 Être DIFFÉRENT
Bon on lit directement le XML, mais comment transformer un fichier XML en un dictionnaire exploitable ?
Pour cela on utilise la bibliothèque xmlschema
Installons la bibliothèque.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/12_Données$ sudo pip install xmlschema
Utilisons là pour convertir un fichier XML avec son schéma XSD.
Testons d’abord xmlschema avec un schema, et validons le.
>>> import xmlschema
>>> schemaxml = xmlschema.XMLSchema('''<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
... <xs:element name="utilisateur" type="xs:string"/>
... </xs:schema>
... ''')
>>> schemaxml.is_valid('''<?xml version="1.0" encoding="UTF-8"?><utilisateur></utilisateur>''')
True
Testons avec les balises imbriquées.
>>> xsd = '''
... <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
... <xs:element name="utilisateurs">
... <xs:complexType>
... <xs:sequence>
... <xs:element name="utilisateur">
... <xs:complexType>
... <xs:sequence>
... <xs:element name="nom" type="xs:string"/>
... <xs:element name="prenom" type="xs:string"/>
... <xs:element name="age" type="xs:integer"/>
... </xs:sequence>
... </xs:complexType>
... </xs:element>
... </xs:sequence>
... </xs:complexType>
... </xs:element>
... </xs:schema>
... '''
>>> schemaxml = xmlschema.XMLSchema(xsd)
>>> schemaxml.is_valid('''<?xml version="1.0" encoding="UTF-8"?><utilisateurs><utilisateur><nom>MOI</nom><prenom>C'est</prenom><age>18</age></utilisateur></utilisateurs>''')
True
Puis testons enfin avec un attribut.
>>> xsd = '''
... <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
... <xs:element name="utilisateurs">
... <xs:complexType>
... <xs:sequence>
... <xs:element name="utilisateur">
... <xs:complexType>
... <xs:sequence>
... <xs:element name="nom" type="xs:string"/>
... <xs:element name="prenom" type="xs:string"/>
... <xs:element name="age" type="xs:integer"/>
... </xs:sequence>
... <xs:attribute name="identifiant" use="required" type="xs:positiveInteger"/>
... </xs:complexType>
... </xs:element>
... </xs:sequence>
... </xs:complexType>
... </xs:element>
... </xs:schema>
... '''
>>> schemaxml = xmlschema.XMLSchema(xsd)
>>> schemaxml.is_valid('''<?xml version="1.0" encoding="UTF-8"?><utilisateurs><utilisateur><nom>MOI</nom><prenom>C'est</prenom><age>18</age></utilisateur></utilisateurs>''')
False
>>> schemaxml.is_valid('''<?xml version="1.0" encoding="UTF-8"?><utilisateurs><utilisateur identifiant="1"><nom>MOI</nom><prenom>C'est</prenom><age>18</age></utilisateur></utilisateurs>''')
True
Convertissons tout cela en un dictionnaire Python.
>>> schemaxml.to_dict('''<?xml version="1.0" encoding="UTF-8"?><utilisateurs><utilisateur identifiant="1"><nom>MOI</nom><prenom>C'est</prenom><age>18</age></utilisateur></utilisateurs>''', schema=schemaxml, preserve_root=True)
{'utilisateurs': {'utilisateur': {'@identifiant': 1, 'nom': 'MOI', 'prenom': "C'est", 'age': 18}}}
On voit bien que les valeurs des variables XML ont été converties dans le type correspondant Python.
L’écriture#
Revenons sur nos exemples avec xml.
Changeons la valeur de l’attribut identifiant.
>>> import xml.etree.ElementTree as ArbreXML
>>> structurexml = ArbreXML.parse('personnes.xml')
>>> racinexml = structurexml.getroot()
>>> for enfant in racinexml:
... nouvel_identifiant = int(enfant.get('identifiant')) + 10
... enfant.set('identifiant', str(nouvel_identifiant))
...
>>> structurexml.write('personnes2.xml')
Ce qui nous donne avec le fichier «personnes2.xml».
<utilisateurs>
<utilisateur identifiant="11">
<nom>NOM</nom>
<prenom>Prénom</prenom>
<sexe biologique="H" />
<age>70</age>
<adresse>Lieu de vie</adresse>
<codepostal>34110</codepostal>
<ville>FRONTIGNAN</ville>
</utilisateur>
<utilisateur identifiant="12">
<nom>MONNOM</nom>
<prenom>MonPrénom</prenom>
<sexe biologique="F" />
<age>40</age>
<adresse>Mon lieu de vie</adresse>
<codepostal>34000</codepostal>
<ville>MONTPELLIER</ville>
</utilisateur>
<utilisateur identifiant="13">
<nom>PERSONNE</nom>
<prenom>Jesuis</prenom>
<sexe biologique="H" social="F" />
<age>25</age>
<adresse>Sans lieu de vie</adresse>
<codepostal>34200</codepostal>
<ville>SÈTE</ville>
</utilisateur>
<utilisateur identifiant="14">
<nom>UNIVERSEL</nom>
<prenom>Divain</prenom>
<sexe biologique="2" />
<age>15</age>
<adresse>Lieu sain</adresse>
<codepostal>34130</codepostal>
<ville>SAINT-AUNÈS</ville>
</utilisateur>
<utilisateur identifiant="15">
<nom>DIFFÉRENT</nom>
<prenom>Être</prenom>
<sexe biologique="S" />
<age>33</age>
<adresse>Lieu de vie normal</adresse>
<codepostal>34260</codepostal>
<ville>LE BOUSQUET-D'ORB</ville>
</utilisateur>
</utilisateurs>
Changeons la valeur d’un tag XML.
>>> import xml.etree.ElementTree as ArbreXML
>>> structurexml = ArbreXML.parse('personnes.xml')
>>> racinexml = structurexml.getroot()
>>> for nom in structurexml.iter('nom'):
... nouveau_nom = '«' + nom.text + '»'
... nom.text = nouveau_nom
...
>>> structurexml.write('personnes3.xml', encoding='utf-8', xml_declaration=True)
Ce qui nous donne avec le fichier «personnes3.xml».
<?xml version='1.0' encoding='utf-8'?>
<utilisateurs>
<utilisateur identifiant="11">
<nom>«NOM»</nom>
<prenom>Prénom</prenom>
<sexe biologique="H" />
<age>70</age>
<adresse>Lieu de vie</adresse>
<codepostal>34110</codepostal>
<ville>FRONTIGNAN</ville>
</utilisateur>
<utilisateur identifiant="12">
<nom>«MONNOM»</nom>
<prenom>MonPrénom</prenom>
<sexe biologique="F" />
<age>40</age>
<adresse>Mon lieu de vie</adresse>
<codepostal>34000</codepostal>
<ville>MONTPELLIER</ville>
</utilisateur>
<utilisateur identifiant="13">
<nom>«PERSONNE»</nom>
<prenom>Jesuis</prenom>
<sexe biologique="H" social="F" />
<age>25</age>
<adresse>Sans lieu de vie</adresse>
<codepostal>34200</codepostal>
<ville>SÈTE</ville>
</utilisateur>
<utilisateur identifiant="14">
<nom>«UNIVERSEL»</nom>
<prenom>Divain</prenom>
<sexe biologique="2" />
<age>15</age>
<adresse>Lieu sain</adresse>
<codepostal>34130</codepostal>
<ville>SAINT-AUNÈS</ville>
</utilisateur>
<utilisateur identifiant="15">
<nom>«DIFFÉRENT»</nom>
<prenom>Être</prenom>
<sexe biologique="S" />
<age>33</age>
<adresse>Lieu de vie normal</adresse>
<codepostal>34260</codepostal>
<ville>LE BOUSQUET-D'ORB</ville>
</utilisateur>
</utilisateurs>
Supprimer un tag <utilisateur>.
>>> import xml.etree.ElementTree as ArbreXML
>>> structurexml = ArbreXML.parse('personnes.xml')
>>> racinexml = structurexml.getroot()
>>> for enfant in racinexml:
... if enfant.get('identifiant') == '3':
... racinexml.remove(enfant)
...
>>> structurexml.write('personnes4.xml', encoding='utf-8', xml_declaration=True)
Ce qui nous donne avec le fichier «personnes4.xml».
<?xml version='1.0' encoding='utf-8'?>
<utilisateurs>
<utilisateur identifiant="1">
<nom>NOM</nom>
<prenom>Prénom</prenom>
<sexe biologique="H" />
<age>70</age>
<adresse>Lieu de vie</adresse>
<codepostal>34110</codepostal>
<ville>FRONTIGNAN</ville>
</utilisateur>
<utilisateur identifiant="2">
<nom>MONNOM</nom>
<prenom>MonPrénom</prenom>
<sexe biologique="F" />
<age>40</age>
<adresse>Mon lieu de vie</adresse>
<codepostal>34000</codepostal>
<ville>MONTPELLIER</ville>
</utilisateur>
<utilisateur identifiant="4">
<nom>UNIVERSEL</nom>
<prenom>Divain</prenom>
<sexe biologique="2" />
<age>15</age>
<adresse>Lieu sain</adresse>
<codepostal>34130</codepostal>
<ville>SAINT-AUNÈS</ville>
</utilisateur>
<utilisateur identifiant="5">
<nom>DIFFÉRENT</nom>
<prenom>Être</prenom>
<sexe biologique="S" />
<age>33</age>
<adresse>Lieu de vie normal</adresse>
<codepostal>34260</codepostal>
<ville>LE BOUSQUET-D'ORB</ville>
</utilisateur>
</utilisateurs>
Ajouter un tag <utilisateur>.
>>> import xml.etree.ElementTree as ArbreXML
>>> structurexml = ArbreXML.parse('personnes.xml')
>>> racinexml = structurexml.getroot()
>>> racinexml.tag
'utilisateurs'
>>> utilisateur = ArbreXML.SubElement(racinexml, 'utilisateur')
>>> utilisateur.set('identifiant', '6')
>>> nom = ArbreXML.SubElement(utilisateur, 'nom')
>>> nom.text = "NOUVEAU"
>>> prenom = ArbreXML.SubElement(utilisateur, 'prenom')
>>> prenom.text = "Super"
>>> sexe = ArbreXML.SubElement(utilisateur, 'sexe')
>>> sexe.set('biologique', 'H')
>>> age = ArbreXML.SubElement(utilisateur, 'age')
>>> age.text = '20'
>>> adresse = ArbreXML.SubElement(utilisateur, 'adresse')
>>> adresse.text = "Rue Paradi"
>>> codepostal = ArbreXML.SubElement(utilisateur, 'codepostal')
>>> codepostal.text = '00000'
>>> ville = ArbreXML.SubElement(utilisateur, 'ville')
>>> ville.text = "CIEUX"
>>> structurexml.write('personnes5.xml', encoding='utf-8', xml_declaration=True)
Ce qui nous donne avec le fichier «personnes5.xml».
<?xml version='1.0' encoding='utf-8'?>
<utilisateurs>
<utilisateur identifiant="1">
<nom>NOM</nom>
<prenom>Prénom</prenom>
<sexe biologique="H" />
<age>70</age>
<adresse>Lieu de vie</adresse>
<codepostal>34110</codepostal>
<ville>FRONTIGNAN</ville>
</utilisateur>
<utilisateur identifiant="2">
<nom>MONNOM</nom>
<prenom>MonPrénom</prenom>
<sexe biologique="F" />
<age>40</age>
<adresse>Mon lieu de vie</adresse>
<codepostal>34000</codepostal>
<ville>MONTPELLIER</ville>
</utilisateur>
<utilisateur identifiant="3">
<nom>PERSONNE</nom>
<prenom>Jesuis</prenom>
<sexe biologique="H" social="F" />
<age>25</age>
<adresse>Sans lieu de vie</adresse>
<codepostal>34200</codepostal>
<ville>SÈTE</ville>
</utilisateur>
<utilisateur identifiant="4">
<nom>UNIVERSEL</nom>
<prenom>Divain</prenom>
<sexe biologique="2" />
<age>15</age>
<adresse>Lieu sain</adresse>
<codepostal>34130</codepostal>
<ville>SAINT-AUNÈS</ville>
</utilisateur>
<utilisateur identifiant="5">
<nom>DIFFÉRENT</nom>
<prenom>Être</prenom>
<sexe biologique="S" />
<age>33</age>
<adresse>Lieu de vie normal</adresse>
<codepostal>34260</codepostal>
<ville>LE BOUSQUET-D'ORB</ville>
</utilisateur>
<utilisateur identifiant="6">
<nom>NOUVEAU</nom>
<prenom>Super</prenom>
<sexe biologique="H" />
<age>20</age>
<adresse>Rue Paradi</adresse>
<codepostal>00000</codepostal>
<ville>CIEUX</ville>
</utilisateur>
</utilisateurs>
Avec une copie et modification d’un élément existant.
>>> import xml.etree.ElementTree as ArbreXML
>>> structurexml = ArbreXML.parse('personnes.xml')
>>> racinexml = structurexml.getroot()
>>> nouveau_utilisateur = ArbreXML.fromstring(ArbreXML.tostring(racinexml[0]))
>>> nouveau_utilisateur.set('identifiant', '6')
>>> nouveau_utilisateur.find('nom').text = "NOUVEAU"
>>> nouveau_utilisateur.find('prenom').text = "Super"
>>> nouveau_utilisateur.find('sexe').set('biologique', 'H')
>>> nouveau_utilisateur.find('age').text = '20'
>>> nouveau_utilisateur.find('adresse').text = "Rue Paradi"
>>> nouveau_utilisateur.find('codepostal').text = '00000'
>>> nouveau_utilisateur.find('ville').text = "CIEUX"
>>> racinexml.append(nouveau_utilisateur)
>>> structurexml.write('personnes6.xml', encoding='utf-8', xml_declaration=True)
Ce qui nous donne avec le fichier «personnes5.xml».
<?xml version='1.0' encoding='utf-8'?>
<utilisateurs>
<utilisateur identifiant="1">
<nom>NOM</nom>
<prenom>Prénom</prenom>
<sexe biologique="H" />
<age>70</age>
<adresse>Lieu de vie</adresse>
<codepostal>34110</codepostal>
<ville>FRONTIGNAN</ville>
</utilisateur>
<utilisateur identifiant="2">
<nom>MONNOM</nom>
<prenom>MonPrénom</prenom>
<sexe biologique="F" />
<age>40</age>
<adresse>Mon lieu de vie</adresse>
<codepostal>34000</codepostal>
<ville>MONTPELLIER</ville>
</utilisateur>
<utilisateur identifiant="3">
<nom>PERSONNE</nom>
<prenom>Jesuis</prenom>
<sexe biologique="H" social="F" />
<age>25</age>
<adresse>Sans lieu de vie</adresse>
<codepostal>34200</codepostal>
<ville>SÈTE</ville>
</utilisateur>
<utilisateur identifiant="4">
<nom>UNIVERSEL</nom>
<prenom>Divain</prenom>
<sexe biologique="2" />
<age>15</age>
<adresse>Lieu sain</adresse>
<codepostal>34130</codepostal>
<ville>SAINT-AUNÈS</ville>
</utilisateur>
<utilisateur identifiant="5">
<nom>DIFFÉRENT</nom>
<prenom>Être</prenom>
<sexe biologique="S" />
<age>33</age>
<adresse>Lieu de vie normal</adresse>
<codepostal>34260</codepostal>
<ville>LE BOUSQUET-D'ORB</ville>
</utilisateur>
<utilisateur identifiant="6">
<nom>NOUVEAU</nom>
<prenom>Super</prenom>
<sexe biologique="H" />
<age>20</age>
<adresse>Rue Paradi</adresse>
<codepostal>00000</codepostal>
<ville>CIEUX</ville>
</utilisateur>
</utilisateurs>
Les annuaires LDAP#
Installation d’un annuaire LDAP#
Nous allons utiliser l’annuaire slapd.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/12_Données$ sudo apt install slapd
utilisateur@MachineUbuntu:~/repertoire_de_developpement/12_Données$ sudo ldapsearch -Q -LLL -Y EXTERNAL -H ldapi:/// -b cn=config dn:
dn: cn=config
dn: cn=module{0},cn=config
dn: cn=schema,cn=config
dn: cn={0}core,cn=schema,cn=config
dn: cn={1}cosine,cn=schema,cn=config
dn: cn={2}nis,cn=schema,cn=config
dn: cn={3}inetorgperson,cn=schema,cn=config
dn: olcDatabase={-1}frontend,cn=config
dn: olcDatabase={0}config,cn=config
dn: olcDatabase={1}mdb,cn=config
utilisateur@MachineUbuntu:~/repertoire_de_developpement/12_Données$ sudo ldapsearch -xLLL -H ldap:/// -b dc=domaine-perso,dc=fr dn
dn: dc=domaine-perso,dc=fr
Remplir l’annuaire LDAP#
Créer le fichier «modèle.ldif».
# fichier de données : ~/repertoire_de_developpement/12_Données/modèle.ldif
dn: ou=Utilisateurs,dc=domaine-perso,dc=fr
objectClass: organizationalUnit
ou: Utilisateurs
dn: ou=Groupes,dc=domaine-perso,dc=fr
objectClass: organizationalUnit
ou: Groupes
dn: cn=developpeurs,ou=Groupes,dc=domaine-perso,dc=fr
objectClass: posixGroup
cn: developpeurs
gidNumber: 5000
dn: uid=prenom.nom,ou=Utilisateurs,dc=domaine-perso,dc=fr
objectClass: inetOrgPerson
objectClass: posixAccount
objectClass: shadowAccount
uid: Prenom
sn: NOM
givenName: Prénom
cn: Prénom NOM
displayName: Prénom NOM
uidNumber: 10000
gidNumber: 5000
userPassword: prenom.nom
gecos: Prenom NOM
loginShell: /bin/bash
homeDirectory: /home/prenom-nom
utilisateur@MachineUbuntu:~/repertoire_de_developpement/12_Données$ ldapadd -x -D cn=admin,dc=domaine-perso,dc=fr -W -f ./modèle.ldif
Enter LDAP Password:
adding new entry "ou=Utilisateurs,dc=domaine-perso,dc=fr"
adding new entry "ou=Groupes,dc=domaine-perso,dc=fr"
adding new entry "cn=developpeurs,ou=Groupes,dc=domaine-perso,dc=fr"
adding new entry "uid=prenom.nom,ou=Utilisateurs,dc=domaine-perso,dc=fr"
utilisateur@MachineUbuntu:~/repertoire_de_developpement/12_Données$ ldapsearch -xLLL -b dc=domaine-perso,dc=fr cn
dn: dc=domaine-perso,dc=fr
dn: ou=Utilisateurs,dc=domaine-perso,dc=fr
dn: ou=Groupes,dc=domaine-perso,dc=fr
dn: cn=developpeurs,ou=Groupes,dc=domaine-perso,dc=fr
cn: developpeurs
dn: uid=prenom.nom,ou=Utilisateurs,dc=domaine-perso,dc=fr
cn:: UHLDqW5vbSBOT00=
utilisateur@MachineUbuntu:~/repertoire_de_developpement/12_Données$ ldapsearch -xLLL -b dc=domaine-perso,dc=fr ou
dn: dc=domaine-perso,dc=fr
dn: ou=Utilisateurs,dc=domaine-perso,dc=fr
ou: Utilisateurs
dn: ou=Groupes,dc=domaine-perso,dc=fr
ou: Groupes
utilisateur@MachineUbuntu:~/repertoire_de_developpement/12_Données$ ldapsearch -xLLL -b dc=domaine-perso,dc=fr 'uid=Prenom' cn gidNumber
dn: uid=prenom.nom,ou=Utilisateurs,dc=domaine-perso,dc=fr
cn:: UHLDqW5vbSBOT00=
gidNumber: 5000
Module Python LDAP#
Installation#
Installation les modules Python ldap et ldap3.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/12_Données$ sudo apt install python3-ldap python3-ldap3
Ajout des outils de la documentation
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo pip install pygments-ldif
Modifier le fichier «docs-requirements.txt»
sphinx
sphinx-intl
sphinxcontrib-inlinesyntaxhighlight
sphinx_copybutton
sphinx-tabs
sphinx_markdown_builder
sphinx-book-theme
anybadge
pygments-ldif
Se connecter au serveur LDAP#
Avec le module ldap
>>> import ldap
>>> try:
... connexion = ldap.initialize('ldap://localhost')
... connexion.set_option(ldap.OPT_REFERRALS, 0)
... connexion.simple_bind_s('cn=admin,dc=domaine-perso,dc=fr', 'motdepasse')
... except ldap.LDAPError:
... print('Erreur LDAP')
...
(97, [], 1, [])
Avec le module ldap3
>>> from ldap3 import Server, Connection, SAFE_SYNC
>>> serveur = Server('localhost')
>>> connexion = Connection(serveur, 'cn=admin,dc=domaine-perso,dc=fr', 'motdepasse', client_strategy=SAFE_SYNC, auto_bind=True)
>>> connexion.extend.standard.who_am_i()
'dn:cn=admin,dc=domaine-perso,dc=fr'
Lire des entrées LDAP#
Lire les données LDAP#
Avec le module ldap
>>> connexion.search_s('dc=domaine-perso,dc=fr', ldap.SCOPE_SUBTREE, '(objectclass=*)')
[('dc=domaine-perso,dc=fr', {'objectClass': [b'top', b'dcObject', b'organization'], 'o': [b'domaine-perso.fr'], 'dc': [b'domaine-perso']}), ('ou=Utilisateurs,dc=domaine-perso,dc=fr', {'objectClass': [b'organizationalUnit'], 'ou': [b'Utilisateurs']}), ('ou=Groupes,dc=domaine-perso,dc=fr', {'objectClass': [b'organizationalUnit'], 'ou': [b'Groupes']}),
('cn=developpeurs,ou=Groupes,dc=domaine-perso,dc=fr', {'objectClass': [b'posixGroup'], 'cn': [b'developpeurs'], 'gidNumber': [b'5000']}), ('uid=prenom.nom,ou=Utilisateurs,dc=domaine-perso,dc=fr', {'objectClass': [b'inetOrgPerson', b'posixAccount', b'shadowAccount'], 'uid': [b'Prenom', b'prenom.nom'], 'sn': [b'NOM'], 'givenName': [b'Pr\xc3\xa9nom'], 'cn': [b'Pr\xc3\xa9nom NOM'], 'displayName': [b'Pr\xc3\xa9nom NOM'], 'uidNumber': [b'10000'], 'gidNumber': [b'5000'], 'userPassword': [b'prenom.nom'], 'gecos': [b'Prenom NOM'], 'loginShell': [b'/bin/bash'], 'homeDirectory': [b'/home/prenom-nom']})]
>>> connexion.search_s('dc=domaine-perso,dc=fr', ldap.SCOPE_SUBTREE, '(uid=Prenom)')
[('uid=prenom.nom,ou=Utilisateurs,dc=domaine-perso,dc=fr', {'objectClass': [b'inetOrgPerson', b'posixAccount', b'shadowAccount'], 'uid': [b'Prenom', b'prenom.nom'], 'sn': [b'NOM'], 'givenName': [b'Pr\xc3\xa9nom'], 'cn': [b'Pr\xc3\xa9nom NOM'], 'displayName': [b'Pr\xc3\xa9nom NOM'], 'uidNumber': [b'10000'], 'gidNumber': [b'5000'], 'userPassword': [b'prenom.nom'], 'gecos': [b'Prenom NOM'], 'loginShell': [b'/bin/bash'], 'homeDirectory': [b'/home/prenom-nom']})]
>>> connexion.search_s('dc=domaine-perso,dc=fr', ldap.SCOPE_SUBTREE, '(uid=Prenom)', ['cn', 'gidNumber'])
[('uid=prenom.nom,ou=Utilisateurs,dc=domaine-perso,dc=fr', {'cn': [b'Pr\xc3\xa9nom NOM'], 'gidNumber': [b'5000']})]
Avec le module ldap3
>>> statut, resultat, reponse, _ = connexion.search('dc=domaine-perso,dc=fr', '(objectclass=*)')
>>> print(statut)
True
>>> print(resultat)
{'result': 0, 'description': 'success', 'dn': '', 'message': '', 'referrals': None, 'type': 'searchResDone'}
>>> print(reponse)
[{'raw_dn': b'dc=domaine-perso,dc=fr', 'dn': 'dc=domaine-perso,dc=fr', 'raw_attributes': {}, 'attributes': {}, 'type': 'searchResEntry'}, {'raw_dn': b'ou=Groupes,dc=domaine-perso,dc=fr', 'dn': 'ou=Groupes,dc=domaine-perso,dc=fr', 'raw_attributes': {}, 'attributes': {}, 'type': 'searchResEntry'}, {'raw_dn': b'ou=Utilisateurs,dc=domaine-perso,dc=fr', 'dn': 'ou=Utilisateurs,dc=domaine-perso,dc=fr', 'raw_attributes': {}, 'attributes': {}, 'type': 'searchResEntry'}, {'raw_dn': b'cn=developpeurs,ou=Groupes,dc=domaine-perso,dc=fr', 'dn': 'cn=developpeurs,ou=Groupes,dc=domaine-perso,dc=fr', 'raw_attributes': {}, 'attributes': {}, 'type': 'searchResEntry'}, {'raw_dn': b'uid=prenom.nom,ou=Utilisateurs,dc=domaine-perso,dc=fr', 'dn': 'uid=prenom.nom,ou=Utilisateurs,dc=domaine-perso,dc=fr', 'raw_attributes': {}, 'attributes': {}, 'type': 'searchResEntry'}]
>>> statut, resultat, reponse, _ = connexion.search('dc=domaine-perso,dc=fr', '(uid=Prenom)')
>>> print(reponse)
[{'raw_dn': b'uid=prenom.nom,ou=Utilisateurs,dc=domaine-perso,dc=fr', 'dn': 'uid=prenom.nom,ou=Utilisateurs,dc=domaine-perso,dc=fr', 'raw_attributes': {}, 'attributes': {}, 'type': 'searchResEntry'}]
>>> statut, resultat, reponse, _ = connexion.search('dc=domaine-perso,dc=fr', '(uid=Prenom)', attributes=['cn', 'gidNumber'])
>>> print(reponse)
[{'raw_dn': b'uid=prenom.nom,ou=Utilisateurs,dc=domaine-perso,dc=fr', 'dn': 'uid=prenom.nom,ou=Utilisateurs,dc=domaine-perso,dc=fr', 'raw_attributes': {'cn': [b'Pr\xc3\xa9nom NOM'], 'gidNumber': [b'5000']}, 'attributes': {'cn': ['Prénom NOM'], 'gidNumber': 5000}, 'type': 'searchResEntry'}]
Lire le schema LDAP#
Avec le module ldap
>>> import ldap.schema as schema
>>> resultat = connexion.search_s('cn=subschema', ldap.SCOPE_BASE, '(objectclass=*)', ['*','+'] )
>>> entree_schemas = resultat[0]
>>> sousentree_schemas = ldap.cidict.cidict(entree_schemas[1])
>>> sousschemas = schema.SubSchema(sousentree_schemas)
>>> objets_oids = sousschemas.listall(schema.models.ObjectClass)
>>> classesobjets = []
>>> for oid in objets_oids:
... classesobjets.append(sousschemas.get_obj(schema.models.ObjectClass, oid).names[0])
...
>>> classesobjets
['top', 'extensibleObject', 'alias', 'referral', 'OpenLDAProotDSE', 'subentry', 'subschema', 'dynamicObject', 'olcConfig', 'olcGlobal', 'olcSchemaConfig', 'olcBackendConfig', 'olcDatabaseConfig', 'olcOverlayConfig', 'olcIncludeFile', 'olcFrontendConfig', 'olcModuleList', 'olcLdifConfig', 'olcMdbConfig', 'country', 'locality', 'organization', 'organizationalUnit', 'person', 'organizationalPerson', 'organizationalRole', 'groupOfNames', 'residentialPerson', 'applicationProcess', 'applicationEntity', 'dSA', 'device', 'strongAuthenticationUser', 'certificationAuthority', 'groupOfUniqueNames', 'userSecurityInformation', 'certificationAuthority-V2', 'cRLDistributionPoint', 'dmd', 'pkiUser', 'pkiCA', 'deltaCRL', 'labeledURIObject', 'simpleSecurityObject', 'dcObject', 'uidObject', 'pilotPerson', 'account', 'document', 'room', 'documentSeries', 'domain', 'RFC822localPart', 'dNSDomain', 'domainRelatedObject', 'friendlyCountry', 'pilotOrganization', 'pilotDSA', 'qualityLabelledData', 'posixAccount', 'shadowAccount', 'posixGroup', 'ipService', 'ipProtocol', 'oncRpc', 'ipHost', 'ipNetwork', 'nisNetgroup', 'nisMap', 'nisObject', 'ieee802Device', 'bootableDevice', 'inetOrgPerson']
>>> schema_ou = sousschemas.get_obj(schema.models.ObjectClass, 'organizationalUnit')
>>> schema_ou.names
('organizationalUnit',)
>>> schema_ou.oid
'2.5.6.5'
>>> schema_ou.desc
'RFC2256: an organizational unit'
>>> schema_ou.sup
('top',)
>>> schema_ou.must
('ou',)
>>> schema_ou.may
('userPassword', 'searchGuide', 'seeAlso', 'businessCategory', 'x121Address', 'registeredAddress', 'destinationIndicator', 'preferredDeliveryMethod', 'telexNumber', 'teletexTerminalIdentifier', 'telephoneNumber', 'internationaliSDNNumber', 'facsimileTelephoneNumber', 'street', 'postOfficeBox', 'postalCode', 'postalAddress', 'physicalDeliveryOfficeName', 'st', 'l', 'description')
>>> schema_ou.token_defaults
{'NAME': (), 'DESC': (None,), 'OBSOLETE': None, 'SUP': (), 'STRUCTURAL': None, 'AUXILIARY': None, 'ABSTRACT': None, 'MUST': (), 'MAY': (), 'X-ORIGIN': ()}
Avec le module ldap3
>>> serveur.schema.object_classes.keys()
dict_keys(['top', 'extensibleObject', 'alias', 'referral', 'OpenLDAProotDSE', 'subentry', 'subschema', 'dynamicObject', 'olcConfig', 'olcGlobal', 'olcSchemaConfig', 'olcBackendConfig', 'olcDatabaseConfig', 'olcOverlayConfig', 'olcIncludeFile', 'olcFrontendConfig', 'olcModuleList', 'olcLdifConfig', 'olcMdbConfig', 'country', 'locality', 'organization', 'organizationalUnit', 'person', 'organizationalPerson', 'organizationalRole', 'groupOfNames', 'residentialPerson', 'applicationProcess', 'applicationEntity', 'dSA', 'device', 'strongAuthenticationUser', 'certificationAuthority', 'groupOfUniqueNames', 'userSecurityInformation', 'certificationAuthority-V2', 'cRLDistributionPoint', 'dmd', 'pkiUser', 'pkiCA', 'deltaCRL', 'labeledURIObject', 'simpleSecurityObject', 'dcObject', 'uidObject', 'pilotPerson', 'account', 'document', 'room', 'documentSeries', 'domain', 'RFC822localPart', 'dNSDomain', 'domainRelatedObject', 'friendlyCountry', 'pilotOrganization', 'pilotDSA', 'qualityLabelledData', 'posixAccount', 'shadowAccount', 'posixGroup', 'ipService', 'ipProtocol', 'oncRpc', 'ipHost', 'ipNetwork', 'nisNetgroup', 'nisMap', 'nisObject', 'ieee802Device', 'bootableDevice', 'inetOrgPerson'])
>>> serveur.schema.object_classes['organizationalUnit']
Object class: 2.5.6.5
Short name: organizationalUnit
Description: RFC2256: an organizational unit
Type: Structural
Superior: top
Must contain attributes: ou
May contain attributes: userPassword, searchGuide, seeAlso, businessCategory, x121Address, registeredAddress, destinationIndicator, preferredDeliveryMethod, telexNumber, teletexTerminalIdentifier, telephoneNumber, internationaliSDNNumber, facsimileTelephoneNumber, street, postOfficeBox, postalCode, postalAddress, physicalDeliveryOfficeName, st, l, description
OidInfo: ('2.5.6.5', 'OBJECT_CLASS', 'organizationalUnit', 'RFC4519')
>>> serveur.schema.object_classes['organizationalUnit'].raw_definition
"( 2.5.6.5 NAME 'organizationalUnit' DESC 'RFC2256: an organizational unit' SUP top STRUCTURAL MUST ou MAY ( userPassword $ searchGuide $ seeAlso $ businessCategory $ x121Address $ registeredAddress $ destinationIndicator $ preferredDeliveryMethod $ telexNumber $ teletexTerminalIdentifier $ telephoneNumber $ internationaliSDNNumber $ facsimileTelephoneNumber $ street $ postOfficeBox $ postalCode $ postalAddress $ physicalDeliveryOfficeName $ st $ l $ description ) )"
Écrire des entrées LDAP#
Avec le module ldap
>>> import ldap.modlist as modlist
>>> dn = 'ou=cour-python,dc=domaine-perso,dc=fr'
>>> operation = {'ou': [b'cour-python'], 'objectClass': [b'organizationalunit']}
>>> connexion.add_s(dn, modlist.addModlist(operation))
(105, [], 3, [])
>>> connexion.search_s('dc=domaine-perso,dc=fr', ldap.SCOPE_SUBTREE, '(ou=cour-python)')
[('ou=cour-python,dc=domaine-perso,dc=fr', {'ou': [b'cour-python'], 'objectClass': [b'top', b'organizationalUnit']})]
>>> dn = 'cn=nouvelle.personne,ou=cour-python,dc=domaine-perso,dc=fr'
>>> operation = {'ou': [b'cour-python'], 'objectClass': [b'inetOrgPerson'], 'givenName': [b'Nouvelle'], 'sn': [b'PERSONNE']}
>>> connexion.add_s(dn, modlist.addModlist(operation))
(105, [], 10, [])
>>> connexion.search_s('dc=domaine-perso,dc=fr', ldap.SCOPE_SUBTREE, '(cn=nouvelle.personne)')
[('cn=nouvelle.personne,ou=cour-python,dc=domaine-perso,dc=fr', {'ou': [b'cour-python'], 'objectClass': [b'inetOrgPerson'], 'givenName': [b'Nouvelle'], 'sn': [b'PERSONNE'], 'cn': [b'nouvelle.personne']})]
Avec le module ldap3
>>> connexion.add('ou=cour-python,dc=domaine-perso,dc=fr', 'organizationalUnit')
(True, {'result': 0, 'description': 'success', 'dn': '', 'message': '', 'referrals': None, 'type': 'addResponse'}, None, {'entry': 'ou=cour-python,dc=domaine-perso,dc=fr', 'attributes': {'objectClass': ['organizationalUnit']}, 'type': 'addRequest', 'controls': None})
>>> connexion.add('cn=nouvelle.personne,ou=cour-python,dc=domaine-perso,dc=fr', 'inetOrgPerson', {'givenName': 'Nouvelle', 'sn': 'PERSONNE'})
(True, {'result': 0, 'description': 'success', 'dn': '', 'message': '', 'referrals': None, 'type': 'addResponse'}, None, {'entry': 'cn=nouvelle.personne,ou=cour-python,dc=domaine-perso,dc=fr', 'attributes': {'givenName': ['Nouvelle'], 'sn': ['PERSONNE'], 'objectClass': ['inetOrgPerson']}, 'type': 'addRequest', 'controls': None})
>>> statut, resultat, reponse, _ = connexion.search('dc=domaine-perso,dc=fr', '(objectclass=*)')
>>> print(reponse)
[{'raw_dn': b'dc=domaine-perso,dc=fr', 'dn': 'dc=domaine-perso,dc=fr', 'raw_attributes': {}, 'attributes': {}, 'type': 'searchResEntry'}, {'raw_dn': b'ou=Utilisateurs,dc=domaine-perso,dc=fr', 'dn': 'ou=Utilisateurs,dc=domaine-perso,dc=fr', 'raw_attributes': {}, 'attributes': {}, 'type': 'searchResEntry'}, {'raw_dn': b'ou=Groupes,dc=domaine-perso,dc=fr', 'dn': 'ou=Groupes,dc=domaine-perso,dc=fr', 'raw_attributes': {}, 'attributes': {}, 'type': 'searchResEntry'}, {'raw_dn': b'cn=developpeurs,ou=Groupes,dc=domaine-perso,dc=fr', 'dn': 'cn=developpeurs,ou=Groupes,dc=domaine-perso,dc=fr', 'raw_attributes': {}, 'attributes': {}, 'type': 'searchResEntry'}, {'raw_dn': b'uid=prenom.nom,ou=Utilisateurs,dc=domaine-perso,dc=fr', 'dn': 'uid=prenom.nom,ou=Utilisateurs,dc=domaine-perso,dc=fr', 'raw_attributes': {}, 'attributes': {}, 'type': 'searchResEntry'}, {'raw_dn': b'ou=cour-python,dc=domaine-perso,dc=fr', 'dn': 'ou=cour-python,dc=domaine-perso,dc=fr', 'raw_attributes': {}, 'attributes': {}, 'type': 'searchResEntry'}, {'raw_dn': b'cn=nouvelle.personne,ou=cour-python,dc=domaine-perso,dc=fr', 'dn': 'cn=nouvelle.personne,ou=cour-python,dc=domaine-perso,dc=fr', 'raw_attributes': {}, 'attributes': {}, 'type': 'searchResEntry'}]
Renommer des entrées LDAP#
Avec le module ldap
>>> dn = 'cn=nouvelle.personne,ou=cour-python,dc=domaine-perso,dc=fr'
>>> connexion.rename_s(dn, 'cn=nouv-personne')
(109, [], 20, [])
>>> connexion.search_s('dc=domaine-perso,dc=fr', ldap.SCOPE_SUBTREE, '(cn=nouv-personne)')
[('cn=nouv-personne,ou=cour-python,dc=domaine-perso,dc=fr', {'ou': [b'cour-python'], 'objectClass': [b'inetOrgPerson'], 'givenName': [b'Nouvelle'], 'sn': [b'PERSONNE'], 'cn': [b'nouv-personne']})]
>>> dn = 'cn=nouv-personne,ou=cour-python,dc=domaine-perso,dc=fr'
>>> connexion.rename_s(dn, 'cn=nouv.personne')
(109, [], 27, [])
>>> connexion.search_s('dc=domaine-perso,dc=fr', ldap.SCOPE_SUBTREE, '(cn=nouv.personne)')
[('cn=nouv.personne,ou=cour-python,dc=domaine-perso,dc=fr', {'ou': [b'cour-python'], 'objectClass': [b'inetOrgPerson'], 'givenName': [b'Nouvelle'], 'sn': [b'PERSONNE'], 'cn': [b'nouv.personne']})]
Avec le module ldap3
>>> connexion.modify_dn('cn=nouvelle.personne,ou=cour-python,dc=domaine-perso,dc=fr', 'cn=nouv.personne')
(True, {'result': 0, 'description': 'success', 'dn': '', 'message': '', 'referrals': None, 'type': 'modDNResponse'}, None, {'entry': 'cn=nouvelle.personne,ou=cour-python,dc=domaine-perso,dc=fr', 'newRdn': 'cn=nouv.personne', 'deleteOldRdn': True, 'newSuperior': None, 'type': 'modDNRequest', 'controls': None})
>>> statut, resultat, reponse, _ = connexion.search('dc=domaine-perso,dc=fr', '(objectclass=inetOrgPerson)')
>>> print(reponse)
[{'raw_dn': b'uid=prenom.nom,ou=Utilisateurs,dc=domaine-perso,dc=fr', 'dn': 'uid=prenom.nom,ou=Utilisateurs,dc=domaine-perso,dc=fr', 'raw_attributes': {}, 'attributes': {}, 'type': 'searchResEntry'}, {'raw_dn': b'cn=nouv.personne,ou=cour-python,dc=domaine-perso,dc=fr', 'dn': 'cn=nouv.personne,ou=cour-python,dc=domaine-perso,dc=fr', 'raw_attributes': {}, 'attributes': {}, 'type': 'searchResEntry'}]
Déplacer une entrée LDAP#
Avec le module ldap
>>> dn = 'cn=nouv.personne,ou=cour-python,dc=domaine-perso,dc=fr'
>>> connexion.rename_s(dn, 'cn=nouv.personne', 'ou=Utilisateurs,dc=domaine-perso,dc=fr')
(109, [], 29, [])
>>> connexion.search_s('dc=domaine-perso,dc=fr', ldap.SCOPE_SUBTREE, '(cn=nouv.personne)')
[('cn=nouv.personne,ou=Utilisateurs,dc=domaine-perso,dc=fr', {'ou': [b'cour-python'], 'objectClass': [b'inetOrgPerson'], 'givenName': [b'Nouvelle'], 'sn': [b'PERSONNE'], 'cn': [b'nouv.personne']})]
Avec le module ldap3
>>> connexion.modify_dn('cn=nouv.personne,ou=cour-python,dc=domaine-perso,dc=fr', 'cn=nouv.personne', new_superior='ou=Utilisateurs,dc=domaine-perso,dc=fr')
(True, {'result': 0, 'description': 'success', 'dn': '', 'message': '', 'referrals': None, 'type': 'modDNResponse'}, None, {'entry': 'cn=nouv.personne,ou=cour-python,dc=domaine-perso,dc=fr', 'newRdn': 'cn=nouv.personne', 'deleteOldRdn': True, 'newSuperior': 'ou=Utilisateurs,dc=domaine-perso,dc=fr', 'type': 'modDNRequest', 'controls': None})
>>> statut, resultat, reponse, _ = connexion.search('dc=domaine-perso,dc=fr', '(objectclass=inetOrgPerson)')
>>> print(reponse)
[{'raw_dn': b'uid=prenom.nom,ou=Utilisateurs,dc=domaine-perso,dc=fr', 'dn': 'uid=prenom.nom,ou=Utilisateurs,dc=domaine-perso,dc=fr', 'raw_attributes': {}, 'attributes': {}, 'type': 'searchResEntry'}, {'raw_dn': b'cn=nouv.personne,ou=Utilisateurs,dc=domaine-perso,dc=fr', 'dn': 'cn=nouv.personne,ou=Utilisateurs,dc=domaine-perso,dc=fr', 'raw_attributes': {}, 'attributes': {}, 'type': 'searchResEntry'}]
Supprimer des entrées LDAP#
Avec le module ldap
>>> connexion.delete('cn=nouv.personne,ou=Utilisateurs,dc=domaine-perso,dc=fr')
31
>>> connexion.search_s('dc=domaine-perso,dc=fr', ldap.SCOPE_SUBTREE, '(objectclass=*)')
[('dc=domaine-perso,dc=fr', {'objectClass': [b'top', b'dcObject', b'organization'], 'o': [b'domaine-perso.fr'], 'dc': [b'domaine-perso']}), ('ou=Groupes,dc=domaine-perso,dc=fr', {'objectClass': [b'organizationalUnit'], 'ou': [b'Groupes']}), ('ou=cour-python,dc=domaine-perso,dc=fr', {'ou': [b'cour-python'], 'objectClass': [b'top', b'organizationalUnit']}), ('ou=Utilisateurs,dc=domaine-perso,dc=fr', {'objectClass': [b'organizationalUnit'], 'ou': [b'Utilisateurs']}), ('cn=developpeurs,ou=Groupes,dc=domaine-perso,dc=fr', {'objectClass': [b'posixGroup'], 'cn': [b'developpeurs'], 'gidNumber': [b'5000']}), ('uid=prenom.nom,ou=Utilisateurs,dc=domaine-perso,dc=fr', {'objectClass': [b'inetOrgPerson', b'posixAccount', b'shadowAccount'], 'uid': [b'Prenom', b'prenom.nom'], 'sn': [b'NOM'], 'givenName': [b'Pr\xc3\xa9nom'], 'cn': [b'Pr\xc3\xa9nom NOM'], 'displayName': [b'Pr\xc3\xa9nom NOM'], 'uidNumber': [b'10000'], 'gidNumber': [b'5000'], 'userPassword': [b'renom.nom'], 'gecos': [b'Prenom NOM'], 'loginShell': [b'/bin/bash'], 'homeDirectory': [b'/home/prenom-nom']})]
Avec le module ldap3
>>> connexion.delete('cn=nouv.personne,ou=Utilisateurs,dc=domaine-perso,dc=fr')
(True, {'result': 0, 'description': 'success', 'dn': '', 'message': '', 'referrals': None, 'type': 'delResponse'}, None, {'entry': 'cn=nouv.personne,ou=Utilisateurs,dc=domaine-perso,dc=fr', 'type': 'delRequest', 'controls': None})
>>> statut, resultat, reponse, _ = connexion.search('dc=domaine-perso,dc=fr', '(objectclass=inetOrgPerson)')
>>> print(reponse)
[{'raw_dn': b'uid=prenom.nom,ou=Utilisateurs,dc=domaine-perso,dc=fr', 'dn': 'uid=prenom.nom,ou=Utilisateurs,dc=domaine-perso,dc=fr', 'raw_attributes': {}, 'attributes': {}, 'type': 'searchResEntry'}]
Modifier des données#
Avec le module ldap
>>> dn = 'cn=nouvelle.personne,ou=cour-python,dc=domaine-perso,dc=fr'
>>> operation = {'ou': [b'cour-python'], 'objectClass': [b'inetOrgPerson'], 'givenName': [b'Nouvelle'], 'sn': [b'PERSONNE']}
>>> connexion.add_s(dn, modlist.addModlist(operation))
(105, [], 35, [])
>>> connexion.search_s('dc=domaine-perso,dc=fr', ldap.SCOPE_SUBTREE, '(cn=nouvelle.personne)')
[('cn=nouvelle.personne,ou=cour-python,dc=domaine-perso,dc=fr', {'ou': [b'cour-python'], 'objectClass': [b'inetOrgPerson'], 'givenName': [b'Nouvelle'], 'sn': [b'PERSONNE'], 'cn': [b'nouvelle.personne']})]
>>> connexion.modify_s(dn, [(ldap.MOD_ADD, 'sn', [b'Nouvelle PERSONNE'])])
(103, [], 37, [])
>>> connexion.search_s('dc=domaine-perso,dc=fr', ldap.SCOPE_SUBTREE, '(cn=nouvelle.personne)')
[('cn=nouvelle.personne,ou=cour-python,dc=domaine-perso,dc=fr', {'ou': [b'cour-python'], 'objectClass': [b'inetOrgPerson'], 'givenName': [b'Nouvelle'], 'sn': [b'PERSONNE', b'Nouvelle PERSONNE'], 'cn': [b'nouvelle.personne']})]
>>> connexion.modify_s(dn, [(ldap.MOD_DELETE, 'sn', [b'PERSONNE'])])
(103, [], 39, [])
>>> connexion.search_s('dc=domaine-perso,dc=fr', ldap.SCOPE_SUBTREE, '(cn=nouvelle.personne)')
[('cn=nouvelle.personne,ou=cour-python,dc=domaine-perso,dc=fr', {'ou': [b'cour-python'], 'objectClass': [b'inetOrgPerson'], 'givenName': [b'Nouvelle'], 'sn': [b'Nouvelle PERSONNE'], 'cn': [b'nouvelle.personne']})]
>>> connexion.modify_s(dn, [(ldap.MOD_REPLACE, 'sn', [b'Personne'])])
(103, [], 41, [])
>>> connexion.search_s('dc=domaine-perso,dc=fr', ldap.SCOPE_SUBTREE, '(cn=nouvelle.personne)')
[('cn=nouvelle.personne,ou=cour-python,dc=domaine-perso,dc=fr', {'ou': [b'cour-python'], 'objectClass': [b'inetOrgPerson'], 'givenName': [b'Nouvelle'], 'cn': [b'nouvelle.personne'], 'sn': [b'Personne']})]
Avec le module ldap3
>>> from ldap3 import MODIFY_ADD, MODIFY_REPLACE, MODIFY_DELETE
>>> connexion.add('cn=nouvelle.personne,ou=Utilisateurs,dc=domaine-perso,dc=fr', 'inetOrgPerson', {'sn': 'Personne', 'uid': 'uid=nouvelle.personne,ou=Utilisateurs,dc=domaine-perso,dc=fr', 'displayName': 'Nouvelle PERSONNE', 'givenName': 'Nouvelle', 'mail': 'nouvelle.personne@domaine-perso.fr'})
(True, {'result': 0, 'description': 'success', 'dn': '', 'message': '', 'referrals': None, 'type': 'addResponse'}, None, {'entry': 'cn=nouvelle.personne,ou=Utilisateurs,dc=domaine-perso,dc=fr', 'attributes': {'sn': ['Personne'], 'uid': ['uid=nouvelle.personne,ou=Utilisateurs,dc=domaine-perso,dc=fr'], 'displayName': ['Nouvelle PERSONNE'], 'givenName': ['Nouvelle'], 'mail': ['nouvelle.personne@domaine-perso.fr'], 'objectClass': ['inetOrgPerson']}, 'type': 'addRequest', 'controls': None})
>>> connexion.modify('cn=nouvelle.personne,ou=Utilisateurs,dc=domaine-perso,dc=fr', {'sn': [(MODIFY_ADD, ['Nouvelle PERSONNE'])]})
(True, {'result': 0, 'description': 'success', 'dn': '', 'message': '', 'referrals': None, 'type': 'modifyResponse'}, None, {'entry': 'cn=nouvelle.personne,ou=Utilisateurs,dc=domaine-perso,dc=fr', 'changes': [{'operation': 0, 'attribute': {'type': 'sn', 'value': ['Nouvelle PERSONNE']}}], 'type': 'modifyRequest', 'controls': None})
>>> connexion.modify('cn=nouvelle.personne,ou=Utilisateurs,dc=domaine-perso,dc=fr', {'sn': [(MODIFY_DELETE, ['Personne'])]})
(True, {'result': 0, 'description': 'success', 'dn': '', 'message': '', 'referrals': None, 'type': 'modifyResponse'}, None, {'entry': 'cn=nouvelle.personne,ou=Utilisateurs,dc=domaine-perso,dc=fr', 'changes': [{'operation': 1, 'attribute': {'type': 'sn', 'value': ['Personne']}}], 'type': 'modifyRequest', 'controls': None})
>>> statut, resultat, reponse, _ = connexion.search('dc=domaine-perso,dc=fr', '(cn=nouvelle.personne)', attributes=['cn', 'sn'])
>>> print(reponse)
[{'raw_dn': b'cn=nouvelle.personne,ou=Utilisateurs,dc=domaine-perso,dc=fr', 'dn': 'cn=nouvelle.personne,ou=Utilisateurs,dc=domaine-perso,dc=fr', 'raw_attributes': {'sn': [b'Nouvelle PERSONNE'], 'cn': [b'nouvelle.personne']}, 'attributes': {'sn': ['Nouvelle PERSONNE'], 'cn': ['nouvelle.personne']}, 'type': 'searchResEntry'}]
>>> connexion.modify('cn=nouvelle.personne,ou=Utilisateurs,dc=domaine-perso,dc=fr', {'sn': [(MODIFY_REPLACE, ['Personne'])]})
(True, {'result': 0, 'description': 'success', 'dn': '', 'message': '', 'referrals': None, 'type': 'modifyResponse'}, None, {'entry': 'cn=nouvelle.personne,ou=Utilisateurs,dc=domaine-perso,dc=fr', 'changes': [{'operation': 2, 'attribute': {'type': 'sn', 'value': ['Personne']}}], 'type': 'modifyRequest', 'controls': None})
>>> statut, resultat, reponse, _ = connexion.search('dc=domaine-perso,dc=fr', '(cn=nouvelle.personne)', attributes=['cn', 'sn'])
>>> print(reponse)
[{'raw_dn': b'cn=nouvelle.personne,ou=Utilisateurs,dc=domaine-perso,dc=fr', 'dn': 'cn=nouvelle.personne,ou=Utilisateurs,dc=domaine-perso,dc=fr', 'raw_attributes': {'cn': [b'nouvelle.personne'], 'sn': [b'Personne']}, 'attributes': {'cn': ['nouvelle.personne'], 'sn': ['Personne']}, 'type': 'searchResEntry'}]
Générer un fichier LDIF#
Avec le module ldap
>>> import sys, ldif
>>> affiche_ldif = ldif.LDIFWriter(sys.stdout)
>>> for dn, resultat in connexion.search_s('dc=domaine-perso,dc=fr', ldap.SCOPE_SUBTREE, '(cn=nouvelle.personne)'):
... affiche_ldif.unparse(dn, resultat)
...
dn: cn=nouvelle.personne,ou=cour-python,dc=domaine-perso,dc=fr
cn: nouvelle.personne
givenName: Nouvelle
objectClass: inetOrgPerson
ou: cour-python
sn: Personne
Vous pouvez exporter le contenu de la variable sortie_ldif dans un fichier.
Mais le module ldif permet de travailler directement à la création d’un fichier LDIF.
>>> genereldif = ldif.LDIFWriter(open('test.ldif', 'w'))
>>> for dn, resultat in connexion.search_s('dc=domaine-perso,dc=fr', ldap.SCOPE_SUBTREE, '(cn=nouvelle.personne)'):
... genereldif.unparse(dn, resultat)
...
Ce qui nous donne comme fichier repertoire_de_developpement/12_Données/test.ldif :
dn: cn=nouvelle.personne,ou=cour-python,dc=domaine-perso,dc=fr
cn: nouvelle.personne
givenName: Nouvelle
objectClass: inetOrgPerson
ou: cour-python
sn: Personne
Générons un fichier LDIF pour ajouter et supprimer une entrée LDAP.
>>> with open('monfichier.ldif', 'w') as fichier:
... genereldif = ldif.LDIFWriter(fichier)
... dn = 'cn=nouvelle.personne,ou=cour-python,dc=domaine-perso,dc=fr'
... operation = {'changetype': [b'delete']}
... genereldif.unparse(dn, operation)
... dn = 'cn=un.individu,ou=Utilisateurs,dc=domaine-perso,dc=fr'
... operation = {'changetype': [b'add'], 'objectClass': [b'inetOrgPerson', b'posixAccount', b'shadowAccount'], 'uid': [b'un.individu'], 'sn': [b'INDIVIDU'], 'givenName': [b'Un'], 'uidNumber': [b'100001'], 'gidNumber': [b'5001'], 'userPassword': [b'un.individu'], 'gecos': [b'Un INDIVIDU'], 'loginShell': [b'/bin/bash'], 'homeDirectory': [b'/home/un-individu']}
... genereldif.unparse(dn, operation)...
Ce qui nous donne le fichier LDIF
dn: cn=nouvelle.personne,ou=cour-python,dc=domaine-perso,dc=fr
changetype: delete
dn: cn=un.individu,ou=Utilisateurs,dc=domaine-perso,dc=fr
changetype: add
gecos: Un INDIVIDU
gidNumber: 5001
givenName: Un
homeDirectory: /home/un-individu
loginShell: /bin/bash
objectClass: inetOrgPerson
objectClass: posixAccount
objectClass: shadowAccount
sn: INDIVIDU
uid: un.individu
uidNumber: 100001
userPassword: un.individu
Avec le module ldap3
Avertissement
Attention la version 2.8.1 du module ldap3 est buguée mettre à jour avec sudo pip install --upgrade ldap3
>>> statut, resultat, reponse, _ = connexion.search('dc=domaine-perso,dc=fr', '(objectclass=inetOrgPerson)', attributes=['cn', 'sn'])
>>> resultat = connexion.response_to_ldif(reponse)
>>> print(resultat)
version: 1
dn: uid=prenom.nom,ou=Utilisateurs,dc=domaine-perso,dc=fr
sn: NOM
cn:: UHLDqW5vbSBOT00=
dn: cn=nouvelle.personne,ou=Utilisateurs,dc=domaine-perso,dc=fr
cn: nouvelle.personne
sn: Personne
# total number of entries: 2
>>> from ldap3 import LDIF
>>> generateldif = Connection(server=None, client_strategy=LDIF)
>>> with generateldif:
... generateldif.add('ou=cour-python,dc=domaine-perso,dc=fr', 'organizationalUnit')
... generateldif.add('cn=nouvelle.personne,ou=cour-python,dc=domaine-perso,dc=fr', 'inetOrgPerson', {'givenName': 'Nouvelle', 'sn': 'PERSONNE'})
... generateldif.delete('cn=utilisateur.bidon,ou=Utilisateurs,dc=domaine-perso,dc=fr')
... result = generateldif.stream.getvalue()
...
'version: 1\ndn: ou=cour-python,dc=domaine-perso,dc=fr\nchangetype: add\nobjectClass: organizationalUnit'
'version: 1\ndn: cn=nouvelle.personne,ou=cour-python,dc=domaine-perso,dc=fr\nchangetype: add\nobjectClass: inetOrgPerson\ngivenName: Nouvelle\nsn: PERSONNE'
'version: 1\ndn: cn=utilisateur.bidon,ou=Utilisateurs,dc=domaine-perso,dc=fr\nchangetype: delete'
Exporter un contenu LDIF dans un fichier LDIF.
>>> generateldif = Connection(server=None, client_strategy=LDIF)
>>> generateldif.stream = open('test.ldif', 'w')
>>> with generateldif:
... generateldif.add('ou=cour-python,dc=domaine-perso,dc=fr', 'organizationalUnit')
... generateldif.add('cn=nouvelle.personne,ou=cour-python,dc=domaine-perso,dc=fr', 'inetOrgPerson', {'givenName': 'Nouvelle', 'sn': 'PERSONNE'})
... generateldif.delete('cn=utilisateur.bidon,ou=Utilisateurs,dc=domaine-perso,dc=fr')
...
'version: 1\ndn: ou=cour-python,dc=domaine-perso,dc=fr\nchangetype: add\nobjectClass: organizationalUnit'
'version: 1\ndn: cn=nouvelle.personne,ou=cour-python,dc=domaine-perso,dc=fr\nchangetype: add\nobjectClass: inetOrgPerson\ngivenName: Nouvelle\nsn: PERSONNE'
'version: 1\ndn: cn=utilisateur.bidon,ou=Utilisateurs,dc=domaine-perso,dc=fr\nchangetype: delete'
Ce qui nous donne comme fichier repertoire_de_developpement/12_Données/test.ldif :
version: 1
dn: ou=cour-python,dc=domaine-perso,dc=fr
changetype: add
objectClass: organizationalUnit
dn: cn=nouvelle.personne,ou=cour-python,dc=domaine-perso,dc=fr
changetype: add
objectClass: inetOrgPerson
givenName: Nouvelle
sn: PERSONNE
dn: cn=utilisateur.bidon,ou=Utilisateurs,dc=domaine-perso,dc=fr
changetype: delete
Générons un fichier LDIF pour ajouter et supprimer une entrée LDAP.
>>> from ldap3 import Connection, LDIF
>>> generateldif = Connection(server=None, client_strategy=LDIF)
>>> generateldif.stream = open('monfichier.ldif', 'w')
>>> with generateldif:
... generateldif.delete('cn=nouvelle.personne,ou=cour-python,dc=domaine-perso,dc=fr')
... generateldif.add('cn=un.individu,ou=Utilisateurs,dc=domaine-perso,dc=fr', 'inetOrgPerson, , posixAccount, shadowAccount', {'gecos': 'Un INDIVIDU', 'gidNumber': 5001, 'givenName': 'Un', 'homeDirectory': '/home/un-individu', 'loginShell': '/bin/bash', 'sn': 'INDIVIDU', 'uid': 'un.individu', 'uidNumber': 100001, 'userPassword': 'un.individu'})
...
'version: 1\ndn: cn=nouvelle.personne,ou=cour-python,dc=domaine-perso,dc=fr\nchangetype: delete'
'version: 1\ndn: cn=un.individu,ou=Utilisateurs,dc=domaine-perso,dc=fr\nchangetype: add\nobjectClass: inetOrgPerson, , posixAccount, shadowAccount\ngecos: Un INDIVIDU\ngidNumber: 5001\ngivenName: Un\nhomeDirectory: /home/un-individu\nloginShell: /bin/bash\nsn: INDIVIDU\nuid: un.individu\nuidNumber: 100001\nuserPassword: un.individu'
Ce qui nous donne le fichier LDIF
version: 1
dn: cn=nouvelle.personne,ou=cour-python,dc=domaine-perso,dc=fr
changetype: delete
dn: cn=un.individu,ou=Utilisateurs,dc=domaine-perso,dc=fr
changetype: add
objectClass: inetOrgPerson, , posixAccount, shadowAccount
gecos: Un INDIVIDU
gidNumber: 5001
givenName: Un
homeDirectory: /home/un-individu
loginShell: /bin/bash
sn: INDIVIDU
uid: un.individu
uidNumber: 100001
userPassword: un.individu
Importer un fichier LDIF dans l’annuaire#
Avec le module ldap
>>> with open('monfichier.ldif') as fichier:
... parser = ldif.LDIFRecordList(fichier)
... parser.parse()
...
>>> for dn, entree in parser.all_records:
... if entree['changetype'] == [b'add']:
... entree.pop('changetype')
... connexion.add_s(dn, modlist.addModlist(entree))
... if entree['changetype'] == [b'delete']:
... connexion.delete(dn)
...
54
[b'add']
(105, [], 57, [])
>>> connexion.search_s('dc=domaine-perso,dc=fr', ldap.SCOPE_SUBTREE, '(objectclass=*)')
[('dc=domaine-perso,dc=fr', {'objectClass': [b'top', b'dcObject', b'organization'], 'o': [b'domaine-perso.fr'], 'dc': [b'domaine-perso']}), ('ou=Utilisateurs,dc=domaine-perso,dc=fr', {'objectClass': [b'organizationalUnit'], 'ou': [b'Utilisateurs']}), ('ou=Groupes,dc=domaine-perso,dc=fr', {'objectClass': [b'organizationalUnit'], 'ou': [b'Groupes']}), ('cn=developpeurs,ou=Groupes,dc=domaine-perso,dc=fr', {'objectClass': [b'posixGroup'], 'cn': [b'developpeurs'], 'gidNumber': [b'5000']}), ('uid=prenom.nom,ou=Utilisateurs,dc=domaine-perso,dc=fr', {'objectClass': [b'inetOrgPerson', b'posixAccount', b'shadowAccount'], 'uid': [b'Prenom', b'prenom.nom'], 'sn': [b'NOM'], 'givenName': [b'Pr\xc3\xa9nom'], 'cn': [b'Pr\xc3\xa9nom NOM'], 'displayName': [b'Pr\xc3\xa9nom NOM'], 'uidNumber': [b'10000'], 'gidNumber': [b'5000'], 'userPassword': [b'renom.nom'], 'gecos': [b'Prenom NOM'], 'loginShell': [b'/bin/bash'], 'homeDirectory': [b'/home/prenom-nom']}), ('ou=cour-python,dc=domaine-perso,dc=fr', {'ou': [b'cour-python'], 'objectClass': [b'top', b'organizationalUnit']}), ('cn=un.individu,ou=Utilisateurs,dc=domaine-perso,dc=fr', {'gecos': [b'Un INDIVIDU'], 'gidNumber': [b'5001'], 'givenName': [b'Un'], 'homeDirectory': [b'/home/un-individu'], 'loginShell': [b'/bin/bash'], 'objectClass': [b'inetOrgPerson', b'posixAccount', b'shadowAccount'], 'sn': [b'INDIVIDU'], 'uid': [b'un.individu'], 'uidNumber': [b'100001'], 'userPassword': [b'un.individu'], 'cn': [b'un.individu']})]
>>> connexion.unbind()
Les bases de données#
SQLite3#
Installation#
utilisateur@MachineUbuntu:~/repertoire_de_developpement/12_Données$ sudo apt install sqlite3
Créer une base de données SQLite#
>>> import sqlite3
>>> mabasesqlite = sqlite3.connect('BaseDonnéesSQLite') # Création ou ouverture de la base
Un fichier BaseDonnéesSQLite vient d’être créer dans repertoire_de_developpement/12_Données/
Vérifions que la base de données a bien été crée
utilisateur@MachineUbuntu:~/repertoire_de_developpement/12_Données$ sqlite3 BaseDonnéesSQLite
SQLite version 3.34.1 2021-01-20 14:10:07
Enter ".help" for usage hints.
sqlite> .databases
main: /home/utilisateur/repertoire_de_developpement/12_Données/BaseDonnéesSQLite r/w
sqlite> .quit
Créer des tables#
>>> curseurbd = mabasesqlite.cursor() # Curseur pour exécuté des requettes SQL
>>> curseurbd.execute('''create table personne (identifiant integer primary key, prénom text, nom text)''') # Création SQL de la table «personne» avec les attributs «prénom» et «nom»
<sqlite3.Cursor object at 0x7f35d6c8c030>
>>> mabasesqlite.commit() # sauvegarde des modifications dans la base SQLite
>>> curseurbd.close() # Ferme le curseur de requêtes SQL
Vérifions que la table a bien été crée
sqlite> .table
personne
sqlite> select name from PRAGMA_TABLE_INFO('personne');
identifiant
prénom
nom
sqlite> PRAGMA table_info(personne);
0 identifiant integer 0 1
1 prénom text 0 0
2 nom text 0 0
Insérer des données#
>>> curseurbd = mabasesqlite.cursor()
>>> for donnée in [('Prénom', 'NOM'), ('Utilisateur', 'DÉVELOPPEUR'), ('Stagiaire', 'PYTHON')]:
... curseurbd.execute('insert into personne (prénom, nom) values (?,?)', donnée)
...
<sqlite3.Cursor object at 0x7f35d6c8c110>
<sqlite3.Cursor object at 0x7f35d6c8c110>
<sqlite3.Cursor object at 0x7f35d6c8c110>
>>> mabasesqlite.commit()
>>> curseurbd.close()
Vérifions que les données ont été bien ajoutées
sqlite> select * from personne;
1 Prénom NOM
2 Utilisateur DÉVELOPPEUR
3 Stagiaire PYTHON
Mais cette façon de coder n’est pas bonne.
>>> with mabasesqlite:
... curseurbd = mabasesqlite.cursor()
... for donnée in [('Prénom2', 'NOM2'), ('Utilisateur2', 'DÉVELOPPEUR2'), ('Stagiaire2', 'PYTHON2')]:
... curseurbd.execute('insert into personne (prénom, nom) values (?,?)', donnée)
... mabasesqlite.commit()
... curseurbd.close()
...
<sqlite3.Cursor object at 0x7f35d6b93e30>
<sqlite3.Cursor object at 0x7f35d6b93e30>
<sqlite3.Cursor object at 0x7f35d6b93e30>
Vérifions que les données ont été bien ajoutées
sqlite> select * from personne;
1 Prénom NOM
2 Utilisateur DÉVELOPPEUR
3 Stagiaire PYTHON
4 Prénom2 NOM2
5 Utilisateur2 DÉVELOPPEUR2
6 Stagiaire2 PYTHON2
Lire des données#
>>> with mabasesqlite:
... cuseurbd = mabasesqlite.cursor()
... cuseurbd.execute('select * from personne')
... for valeur in cuseurbd:
... print('{}|{}|{}'.format(*valeur))
... cuseurbd.close()
...
<sqlite3.Cursor object at 0x7f35d6b93e30>
1|Prénom|NOM
2|Utilisateur|DÉVELOPPEUR
3|Stagiaire|PYTHON
4|Prénom2|NOM2
5|Utilisateur2|DÉVELOPPEUR2
6|Stagiaire2|PYTHON2
Effacer des données#
>>> with mabasesqlite:
... cuseurbd = mabasesqlite.cursor()
... cuseurbd.execute('delete from personne where nom like \'%2\'')
... mabasesqlite.commit()
... cuseurbd.close()
...
<sqlite3.Cursor object at 0x7f35d6b93e30>
>>> with mabasesqlite:
... cuseurbd = mabasesqlite.cursor()
... cuseurbd.execute('select * from personne')
... for valeur in cuseurbd:
... print('{}|{}|{}'.format(*valeur))
... cuseurbd.close()
...
<sqlite3.Cursor object at 0x7f35d6c8c030>
1|Prénom|NOM
2|Utilisateur|DÉVELOPPEUR
3|Stagiaire|PYTHON
SQLAlchemy#
Installation#
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo apt install python3-sqlalchemy
connexion à la base de données#
Exécuter des requêtes SQL directement.
>>> from sqlalchemy import create_engine
>>> mabasesqlite = create_engine('sqlite:///BaseDonnéesSQLite', echo=True)
>>> resultat = mabasesqlite.execute('select * from personne')
2021-11-19 12:42:41,875 INFO sqlalchemy.engine.base.Engine SELECT CAST('test plain returns' AS VARCHAR(60)) AS anon_1
2021-11-19 12:42:41,875 INFO sqlalchemy.engine.base.Engine ()
2021-11-19 12:42:41,876 INFO sqlalchemy.engine.base.Engine SELECT CAST('test unicode returns' AS VARCHAR(60)) AS anon_1
2021-11-19 12:42:41,876 INFO sqlalchemy.engine.base.Engine ()
2021-11-19 12:42:41,877 INFO sqlalchemy.engine.base.Engine select * from personne
2021-11-19 12:42:41,877 INFO sqlalchemy.engine.base.Engine ()
>>> resultat.fetchall()
[(1, 'Prénom', 'NOM'), (2, 'Utilisateur', 'DÉVELOPPEUR'), (3, 'Stagiaire', 'PYTHON')]
Exécuter des requêtes SQL en mode transactionnel.
>>> from sqlalchemy import create_engine
>>> mabasesqlite = create_engine('sqlite:///BaseDonnéesSQLite', echo=True)
>>> transactionnel = mabasesqlite.connect()
>>> transaction = transactionnel.begin()
2021-11-19 12:50:00,985 INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
>>> resultat = transactionnel.execute('select * from personne')
2021-11-19 12:50:15,513 INFO sqlalchemy.engine.base.Engine select * from personne
2021-11-19 12:50:15,514 INFO sqlalchemy.engine.base.Engine ()
>>> transaction.commit()
2021-11-19 12:50:23,568 INFO sqlalchemy.engine.base.Engine COMMIT
>>> resultat.fetchall()
[(1, 'Prénom', 'NOM'), (2, 'Utilisateur', 'DÉVELOPPEUR'), (3, 'Stagiaire', 'PYTHON')]
>>> transaction = transactionnel.begin()
2021-11-19 12:52:26,793 INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
>>> resultat = transactionnel.execute('select * from personne').fetchall()
2021-11-19 12:52:38,307 INFO sqlalchemy.engine.base.Engine select * from personne
2021-11-19 12:52:38,307 INFO sqlalchemy.engine.base.Engine ()
>>> resultat
[(1, 'Prénom', 'NOM'), (2, 'Utilisateur', 'DÉVELOPPEUR'), (3, 'Stagiaire', 'PYTHON')]
>>> transaction.commit()
2021-11-19 12:52:47,537 INFO sqlalchemy.engine.base.Engine COMMIT
Mais SQLAlchemy est ce que l’on appelle un ORM, c’est-à-dire une interface logicielle standardisée pour transformer une base relationnelle en une base de données orientée objet.
L”ORM doit avoir une session pour s’interfacer entre le moteur, qui communique réellement avec la base de données, et les objets que nous traiterons en Python.
>>> from sqlalchemy import create_engine
>>> mabasesqlite = create_engine('sqlite:///BaseDonnéesSQLite', echo=True)
>>> from sqlalchemy.orm import sessionmaker
>>> Sessionbd = sessionmaker(bind=mabasesqlite)
>>> sessionsql = Sessionbd()
>>> resultat = sessionsql.execute('select * from personne').fetchall()
2021-11-19 13:10:11,087 INFO sqlalchemy.engine.base.Engine select * from personne
2021-11-19 13:10:11,088 INFO sqlalchemy.engine.base.Engine ()
>>> resultat
[(1, 'Prénom', 'NOM'), (2, 'Utilisateur', 'DÉVELOPPEUR'), (3, 'Stagiaire', 'PYTHON')]
Création d’une base de données#
>>> from sqlalchemy import create_engine
>>> from sqlalchemy.ext.declarative import declarative_base
>>> mabasesqlite = create_engine('sqlite:///BaseDonnées.db', echo=True)
>>> outilbd = declarative_base()
>>> outilbd.metadata.create_all(mabasesqlite)
2021-11-19 13:23:12,544 INFO sqlalchemy.engine.base.Engine SELECT CAST('test plain returns' AS VARCHAR(60)) AS anon_1
2021-11-19 13:23:12,544 INFO sqlalchemy.engine.base.Engine ()
2021-11-19 13:23:12,545 INFO sqlalchemy.engine.base.Engine SELECT CAST('test unicode returns' AS VARCHAR(60)) AS anon_1
2021-11-19 13:23:12,545 INFO sqlalchemy.engine.base.Engine ()
Création avec une table#
Création d’une base de données avec une table «personnes» et les colonnes «identifiant», «prénom» et «nom».
>>> from sqlalchemy import create_engine
>>> from sqlalchemy import Column, Integer, String
>>> from sqlalchemy.ext.declarative import declarative_base
>>> mabasesqlite = create_engine('sqlite:///BaseDonnées.db', echo=True)
>>> basesqlite = declarative_base()
>>> class Personne(basesqlite):
... __tablename__ = 'personnes'
... identifiant = Column(Integer, primary_key=True)
... prénom = Column(String)
... nom = Column(String)
... def __init__(self, prénom, nom):
... self.prénom = prénom
... self.nom = nom
...
>>> Personne.metadata.create_all(mabasesqlite)
2021-11-19 13:59:46,534 INFO sqlalchemy.engine.base.Engine SELECT CAST('test plain returns' AS VARCHAR(60)) AS anon_1
2021-11-19 13:59:46,534 INFO sqlalchemy.engine.base.Engine ()
2021-11-19 13:59:46,534 INFO sqlalchemy.engine.base.Engine SELECT CAST('test unicode returns' AS VARCHAR(60)) AS anon_1
2021-11-19 13:59:46,535 INFO sqlalchemy.engine.base.Engine ()
2021-11-19 13:59:46,535 INFO sqlalchemy.engine.base.Engine PRAGMA main.table_info("personnes")
2021-11-19 13:59:46,535 INFO sqlalchemy.engine.base.Engine ()
2021-11-19 13:59:46,536 INFO sqlalchemy.engine.base.Engine PRAGMA temp.table_info("personnes")
2021-11-19 13:59:46,536 INFO sqlalchemy.engine.base.Engine ()
2021-11-19 13:59:46,538 INFO sqlalchemy.engine.base.Engine
CREATE TABLE personnes (
identifiant INTEGER NOT NULL,
"prénom" VARCHAR,
nom VARCHAR,
PRIMARY KEY (identifiant)
)
2021-11-19 13:59:46,538 INFO sqlalchemy.engine.base.Engine ()
2021-11-19 13:59:46,572 INFO sqlalchemy.engine.base.Engine COMMIT
Vérifions que la base de données a été bien crée.
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sqlite3 12_Données/BaseDonnées.db SQLite version 3.34.1 2021-01-20 14:10:07 Enter « .help » for usage hints.
sqlite> select name from PRAGMA_TABLE_INFO('personnes');
identifiant
prénom
nom
sqlite> PRAGMA table_info(personnes);
0|identifiant|INTEGER|1||1
1|prénom|VARCHAR|0||0
2|nom|VARCHAR|0||0
Ajout d’un enregistrement#
>>> from sqlalchemy import create_engine
>>> mabasesqlite = create_engine('sqlite:///BaseDonnées.db')
>>> from sqlalchemy.orm import sessionmaker
>>> Sessionbd = sessionmaker(bind=mabasesqlite)
>>> sessionsql = Sessionbd()
>>> resultat = sessionsql.execute('select * from personnes').fetchall()
>>> resultat
[]
>>> from sqlalchemy.ext.declarative import declarative_base
>>> basesqlite = declarative_base()
>>> from sqlalchemy import Column, Integer, String
>>> class Personne(basesqlite):
... __tablename__ = 'personnes'
... identifiant = Column(Integer, primary_key=True)
... prénom = Column(String)
... nom = Column(String)
... def __init__(self, prénom, nom):
... self.prénom = prénom
... self.nom = nom
...
>>> utilisateur1 = Personne('Prénom', 'NOM')
>>> sessionsql.add(utilisateur1)
>>> utilisateur1.identifiant
>>> sessionsql.flush()
>>> sessionsql.commit()
>>> utilisateur1.identifiant
1
>>> utilisateur2 = Personne('Utilisateur', 'DÉVELOPPEUR')
>>> sessionsql.add(utilisateur2)
>>> sessionsql.flush()
>>> utilisateur2.identifiant
2
>>> sessionsql.commit()
>>> utilisateur2.identifiant
2
>>> resultat = sessionsql.execute('select * from personnes').fetchall()
>>> resultat
[(1, 'Prénom', 'NOM'), (2, 'Utilisateur', 'DÉVELOPPEUR')]
Faire des recherches#
>>> recherche = sessionsql.query(Personne).filter_by(nom='NOM')
>>> for index in range(recherche.count()):
... print('{}|{}|{}'.format(recherche[index - 1].identifiant, recherche[index].prénom, recherche[index].nom))
...
1|Prénom|NOM
Ajouter une table#
>>> class Programmeur(basesqlite):
... __tablename__ = 'programmeur'
... identifiant = Column(Integer, primary_key=True)
... langage = Column(String)
...
>>> Programmeur.__table__.create(mabasesqlite)
sqlite> .tables
personnes programmeur
sqlite> PRAGMA table_info(programmeur);
0|identifiant|INTEGER|1||1
1|langage|VARCHAR|0||0
Créer une relation#
Supprimez la base de données «repertoire_de_developpement/12_Données/BaseDonnées.db»
>>> from sqlalchemy import create_engine, Column, Integer, String, ForeignKey
>>> from sqlalchemy.orm import sessionmaker, relationship
>>> from sqlalchemy.ext.declarative import declarative_base
>>> basesqlite = declarative_base()
>>> mabasesqlite = create_engine('sqlite:///BaseDonnées.db')
>>> Sessionbd = sessionmaker(bind=mabasesqlite)
>>> sessionsql = Sessionbd()
>>> class Programmeur(basesqlite):
... __tablename__ = 'programmeur'
... identifiant = Column(Integer, primary_key=True)
... langage = Column(String)
... id_utilisateur = Column(Integer, ForeignKey('personnes.identifiant'))
... utilisateur = relationship('Personne')
... def __init__(self, langage, utilisateur):
... self.langage = langage
... self.utilisateur = utilisateur
...
>>> class Personne(basesqlite):
... __tablename__ = 'personnes'
... identifiant = Column(Integer, primary_key=True)
... prénom = Column(String)
... nom = Column(String)
... langage = relationship(Programmeur, backref='users')
... def __init__(self, prénom, nom, langage):
... self.prénom = prénom
... self.nom = nom
...
>>> utilisateur = Personne('Stagiaire', 'DÉVELOPPEUR', 'Python')
>>> programmeur = Programmeur('Python', utilisateur)
sqlite> .tables
personnes programmeur
sqlite> PRAGMA table_info(pragrammeur);
sqlite> .tables
personnes programmeur
sqlite> PRAGMA table_info(programmeur);
0|identifiant|INTEGER|1||1
1|langage|VARCHAR|0||0
2|id_utilisateur|INTEGER|0||0
sqlite> PRAGMA foreign_key_list(programmeur);
0|0|personnes|id_utilisateur|identifiant|NO ACTION|NO ACTION|NONE
sqlite> PRAGMA table_info(personnes);
0|identifiant|INTEGER|1||1
1|prénom|VARCHAR|0||0
2|nom|VARCHAR|0||0
sqlite> PRAGMA foreign_key_list(personnes);
sqlite> select * from personnes;
1|Stagiaire|DÉVELOPPEUR
sqlite> select * from programmeur;
1|Python|1
Le réseau#
Les services#
Pour lancer un serveur, généralement nous lançons ce serveur sous forme de service pour nos systèmes. Nous allons voir ici comment faire sur des systèmes Linux avec systemd.
systemd#
Systemd supporte des services systèmes ou utilisateurs. Il démarre ces services dans leur propre instance.
Creation d’un service utilisateur#
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ systemctl --user edit service_python.service --full --force
Saisir la définition de service ci-dessous
[Unit]
# Nom du service pour les humains ;-p
Description=Exemple de service Python
Vérifier la présence du service
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ systemctl --user list-unit-files | grep service_python
service_python.service static -
Créer un programme Python à exécuter comme service
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ mkdir 13_Services ; cd 13_Services
Créer le fichier «repertoire_de_developpement/13_Services/demo_service_python.py». Et saisissez :
if __name__ == '__main__':
import time
while True:
print('Réponse du service python de démonstration')
time.sleep(5)
Modifier le service pour intégrer le programme Python
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ systemctl --user edit service_python.service --full
Saisir la modification du service ci-dessous
[Unit]
# Nom du service pour les humains ;-p
Description=Exemple de service Python
[Service]
#Commande à exécuter quand le service est démarré
ExecStart=/usr/bin/python3 /home/utilisateur/repertoire_de_developpement/13_Services/demo_service_python.py
Démarrer le service
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ systemctl --user start service_python.service
utilisateur@MachineUbuntu:~/repertoire_de_developpement/13_Services$ systemctl --user status service_python.service
● service_python.service - Exemple de service Python
Loaded: loaded (/home/utilisateur/.config/systemd/user/service_python.service; static)
Active: active (running) since Mon 2021-11-22 10:05:30 CET; 9s ago
Main PID: 589845 (python3)
CGroup: /user.slice/user-1000.slice/user@1000.service/app.slice/service_python.service
└─589845 /usr/bin/python3 /home/utilisateur/repertoire_de_developpement/13_Services/demo_service_python.py
nov. 22 10:05:30 MachineUbuntu.domaine-perso.fr systemd[1897]: Started Exemple de service Python.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/13_Services$ journalctl --user -u service_python
-- Journal begins at Thu 2021-10-21 10:48:14 CEST, ends at Mon 2021-11-22 10:15:03 CET. --
nov. 22 10:05:30 MachineUbuntu.domaine-perso.fr systemd[1897]: Started Exemple de service Python.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/13_Services$ cat /var/log/syslog
…
Nov 22 10:17:22 MachineUbuntu systemd[1897]: service_python.service: Succeeded.
Nov 22 10:17:44 MachineUbuntu systemd[1897]: Started Exemple de service Python.
La sotie print('Réponse du service python de démonstration') n’apparait pas dans l’exécution du service dans votre terminal. Systemd exécute le service dans une instance séparée ce qui redirige donc STDOUT et STDERR.
Pour remédier à cela avec Python, modifier le service avec Environment=PYTHONUNBUFFERED=1 pour intégrer le programme Python
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ systemctl --user edit service_python --full
Saisir la modification du service ci-dessous
[Unit]
# Nom du service pour les humains ;-p
Description=Exemple de service Python
[Service]
Environment=PYTHONUNBUFFERED=1
#Commande à exécuter quand le service est démarré
ExecStart=/usr/bin/python3 /home/utilisateur/repertoire_de_developpement/13_Services/demo_service_python.py
utilisateur@MachineUbuntu:~/repertoire_de_developpement/13_Services$ systemctl --user restart service_python
utilisateur@MachineUbuntu:~/repertoire_de_developpement/13_Services$ tail -1 /var/log/syslog
Nov 22 10:31:37 MachineUbuntu python3[592413]: Réponse du service python de démonstration
utilisateur@MachineUbuntu:~/repertoire_de_developpement/13_Services$ systemctl --user status service_python
● service_python.service - Exemple de service Python
Loaded: loaded (/home/utilisateur/.config/systemd/user/service_python.service; static)
Active: active (running) since Mon 2021-11-22 10:30:22 CET; 1min 52s ago
Main PID: 592413 (python3)
CGroup: /user.slice/user-1000.slice/user@1000.service/app.slice/service_python.service
└─592413 /usr/bin/python3 /home/utilisateur/repertoire_de_developpement/13_Services/demo_service_python.py
nov. 22 10:31:27 MachineUbuntu.domaine-perso.fr python3[592413]: Réponse du service python de démonstration
nov. 22 10:31:32 MachineUbuntu.domaine-perso.fr python3[592413]: Réponse du service python de démonstration
nov. 22 10:31:37 MachineUbuntu.domaine-perso.fr python3[592413]: Réponse du service python de démonstration
nov. 22 10:31:42 MachineUbuntu.domaine-perso.fr python3[592413]: Réponse du service python de démonstration
nov. 22 10:31:47 MachineUbuntu.domaine-perso.fr python3[592413]: Réponse du service python de démonstration
utilisateur@MachineUbuntu:~/repertoire_de_developpement/13_Services$ journalctl --user-unit service_python
-- Journal begins at Thu 2021-10-21 10:23:23 CEST, ends at Mon 2021-11-22 10:35:32 CET. --
nov. 22 10:30:22 MachineUbuntu.domaine-perso.fr systemd[1897]: service_python.service: Succeeded.
nov. 22 10:30:22 MachineUbuntu.domaine-perso.fr systemd[1897]: Stopped Exemple de service Python.
nov. 22 10:30:22 MachineUbuntu.domaine-perso.fr systemd[1897]: Started Exemple de service Python.
nov. 22 10:30:22 MachineUbuntu.domaine-perso.fr python3[592413]: Réponse du service python de démonstration
nov. 22 10:30:27 MachineUbuntu.domaine-perso.fr python3[592413]: Réponse du service python de démonstration
nov. 22 10:30:32 MachineUbuntu.domaine-perso.fr python3[592413]: Réponse du service python de démonstration
nov. 22 10:30:37 MachineUbuntu.domaine-perso.fr python3[592413]: Réponse du service python de démonstration
nov. 22 10:30:42 MachineUbuntu.domaine-perso.fr python3[592413]: Réponse du service python de démonstration
Démarrer le service automatiquement#
Pour démarrer le service automatiquement au démarrage de votre machine Ubuntu.
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ systemctl --user edit service_python --full
Saisir la modification du service ci-dessous
[Unit]
# Nom du service pour les humains ;-p
Description=Exemple de service Python
[Service]
Environment=PYTHONUNBUFFERED=1
#Commande à exécuter quand le service est démarré
ExecStart=/usr/bin/python3 /home/utilisateur/repertoire_de_developpement/13_Services/demo_service_python.py
[Install]
WantedBy=default.target
Ajouter le service au démarrage du système
utilisateur@MachineUbuntu:~/repertoire_de_developpement/13_Services$ systemctl --user enable service_python
Created symlink /home/utilisateur/.config/systemd/user/default.target.wants/service_python.service → /home/utilisateur/.config/systemd/user/service_python.service.
Redémarrer le système.
utilisateur@MachineUbuntu:~$ systemctl --user list-unit-files | grep service_python
service_python.service enabled enabled
utilisateur@MachineUbuntu:~$ systemctl --user status service_python
● service_python.service - Exemple de service Python
Loaded: loaded (/home/utilisateur/.config/systemd/user/service_python.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2021-11-22 10:48:49 CET; 12min ago
Main PID: 2107 (python3)
CGroup: /user.slice/user-1000.slice/user@1000.service/app.slice/service_python.service
└─2107 /usr/bin/python3 /home/utilisateur/repertoire_de_developpement/13_Services/demo_service_python.py
nov. 22 11:01:34 MachineUbuntu.domaine-perso.fr python3[2107]: Réponse du service python de démonstration
nov. 22 11:01:39 MachineUbuntu.domaine-perso.fr python3[2107]: Réponse du service python de démonstration
nov. 22 11:01:44 MachineUbuntu.domaine-perso.fr python3[2107]: Réponse du service python de démonstration
nov. 22 11:01:49 MachineUbuntu.domaine-perso.fr python3[2107]: Réponse du service python de démonstration
…
Le service ne démarre que lorsque l’utilisateur se connecte. Si nous voulons que le service démarre au démarage du système il faut passer la commande
utilisateur@MachineUbuntu:~$ sudo loginctl enable-linger $USER
Redémarrage automatique après échec#
Avec systemd il est possible de redémarrer automatiquement le service en cas d’échec.
Si nous tuons le processus
utilisateur@MachineUbuntu:~$ systemctl --user --signal=SIGKILL kill service_python
utilisateur@MachineUbuntu:~$ systemctl --user status service_python
● service_python.service - Exemple de service Python
Loaded: loaded (/home/utilisateur/.config/systemd/user/service_python.service; enabled; vendor preset: enabled)
Active: failed (Result: signal) since Mon 2021-11-22 11:15:56 CET; 8s ago
Process: 2107 ExecStart=/usr/bin/python3 /home/utilisateur/repertoire_de_developpement/13_Services/demo_service_python.py (code=killed, signal=K>
Main PID: 2107 (code=killed, signal=KILL)
…
nov. 22 11:15:56 MachineUbuntu.domaine-perso.fr systemd[1892]: service_python.service: Sent signal SIGKILL to main process 2107 (python3) on client >
nov. 22 11:15:56 MachineUbuntu.domaine-perso.fr systemd[1892]: service_python.service: Main process exited, code=killed, status=9/KILL
nov. 22 11:15:56 MachineUbuntu.domaine-perso.fr systemd[1892]: service_python.service: Failed with result 'signal'.
On voit que le service s’arrête.
Pour que le service redémarre automatiquement il faut ajouter Restart=on-failure.
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ systemctl --user edit service_python --full
[Unit]
# Nom du service pour les humains ;-p
Description=Exemple de service Python
[Service]
Environment=PYTHONUNBUFFERED=1
#Commande à exécuter quand le service est démarré
ExecStart=/usr/bin/python3 /home/utilisateur/repertoire_de_developpement/13_Services/demo_service_python.py
Restart=on-failure
[Install]
WantedBy=default.target
utilisateur@MachineUbuntu:~$ systemctl --user restart service_python
utilisateur@MachineUbuntu:~$ systemctl --user status service_python
● service_python.service - Exemple de service Python
Loaded: loaded (/home/utilisateur/.config/systemd/user/service_python.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2021-11-22 11:25:17 CET; 8s ago
Main PID: 7249 (python3)
CGroup: /user.slice/user-1000.slice/user@1000.service/app.slice/service_python.service
└─7249 /usr/bin/python3 /home/utilisateur/repertoire_de_developpement/13_Services/demo_service_python.py
nov. 22 11:25:17 MachineUbuntu.domaine-perso.fr systemd[1892]: Started Exemple de service Python.
nov. 22 11:25:17 MachineUbuntu.domaine-perso.fr python3[7249]: Réponse du service python de démonstration
nov. 22 11:25:22 MachineUbuntu.domaine-perso.fr python3[7249]: Réponse du service python de démonstration
utilisateur@MachineUbuntu:~$ systemctl --user --signal=SIGKILL kill service_python
utilisateur@MachineUbuntu:~$ systemctl --user status service_python
● service_python.service - Exemple de service Python
Loaded: loaded (/home/utilisateur/.config/systemd/user/service_python.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2021-11-22 11:26:10 CET; 7s ago
Main PID: 7266 (python3)
CGroup: /user.slice/user-1000.slice/user@1000.service/app.slice/service_python.service
└─7266 /usr/bin/python3 /home/utilisateur/repertoire_de_developpement/13_Services/demo_service_python.py
nov. 22 11:26:10 MachineUbuntu.domaine-perso.fr systemd[1892]: service_python.service: Sent signal SIGKILL to main process 7249 (python3) on client >
nov. 22 11:26:13 MachineUbuntu.domaine-perso.fr python3[7266]: Réponse du service python de démonstration
nov. 22 11:26:10 MachineUbuntu.domaine-perso.fr systemd[1892]: service_python.service: Main process exited, code=killed, status=9/KILL
nov. 22 11:26:10 MachineUbuntu.domaine-perso.fr systemd[1892]: service_python.service: Failed with result 'signal'.
nov. 22 11:26:15 MachineUbuntu.domaine-perso.fr python3[7266]: Réponse du service python de démonstration
nov. 22 11:26:10 MachineUbuntu.domaine-perso.fr systemd[1892]: service_python.service: Scheduled restart job, restart counter is at 1.
nov. 22 11:26:10 MachineUbuntu.domaine-perso.fr systemd[1892]: Stopped Exemple de service Python.
nov. 22 11:26:10 MachineUbuntu.domaine-perso.fr systemd[1892]: Started Exemple de service Python.
nov. 22 11:26:25 MachineUbuntu.domaine-perso.fr python3[7266]: Réponse du service python de démonstration
nov. 22 11:26:30 MachineUbuntu.domaine-perso.fr python3[7266]: Réponse du service python de démonstration
nov. 22 11:26:35 MachineUbuntu.domaine-perso.fr python3[7266]: Réponse du service python de démonstration
Notification de démarrage à Systemd#
Maintenant nous allons agir avec Systend par l’intermédiaire de Python. Nous allons indiquer à Systemd quand le service Python a démarré.
Modifiez le fichier «repertoire_de_developpement/13_Services/demo_service_python.py»
if __name__ == '__main__':
import time
import systemd.deamon as service
print('Démarrage de service_python …')
time.sleep(5)
print('Démarrage OK')
service.notify('READY=1')
while True:
print('Réponse du service python de démonstration')
time.sleep(5)
Puis
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ systemctl --user edit service_python --full
[Unit]
# Nom du service pour les humains ;-p
Description=Exemple de service Python
[Service]
Environment=PYTHONUNBUFFERED=1
#Commande à exécuter quand le service est démarré
ExecStart=/usr/bin/python3 /home/utilisateur/repertoire_de_developpement/13_Services/demo_service_python.py
Restart=on-failure
Type=notify
#StandardOutput=journal+console
[Install]
WantedBy=default.target
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ systemctl --user restart service_python
utilisateur@MachineUbuntu:~$ systemctl --user status service_python
● service_python.service - Exemple de service Python
Loaded: loaded (/home/utilisateur/.config/systemd/user/service_python.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2021-11-22 11:54:39 CET; 8s ago
Main PID: 10233 (python3)
CGroup: /user.slice/user-1000.slice/user@1000.service/app.slice/service_python.service
└─10233 /usr/bin/python3 /home/utilisateur/repertoire_de_developpement/13_Services/demo_service_python.py
nov. 22 11:54:34 MachineUbuntu.domaine-perso.fr systemd[1892]: Starting Exemple de service Python...
nov. 22 11:54:34 MachineUbuntu.domaine-perso.fr python3[10233]: Démarrage de service_python …
nov. 22 11:54:39 MachineUbuntu.domaine-perso.fr python3[10233]: Démarrage OK
nov. 22 11:54:39 MachineUbuntu.domaine-perso.fr python3[10233]: Réponse du service python de démonstration
nov. 22 11:54:39 MachineUbuntu.domaine-perso.fr systemd[1892]: Started Exemple de service Python.
nov. 22 11:54:44 MachineUbuntu.domaine-perso.fr python3[10233]: Réponse du service python de démonstration
Supprimer le démarrage automatique du service#
utilisateur@MachineUbuntu:~/repertoire_de_developpement/13_Services$ systemctl --user disable service_python
Removed /home/utilisateur/.config/systemd/user/default.target.wants/service_python.service.
Transformer en service système#
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ systemctl --user stop service_python
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo mv ~/.config/systemd/user/service_python.service /etc/systemd/system/
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo chown root:root /etc/systemd/system/service_python.service
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo chmod 644 /etc/systemd/system/service_python.service
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo mkdir /usr/local/lib/demo_service_python
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo cp ~/repertoire_de_developpement/13_Services/demo_service_python.py /usr/local/lib/demo_service_python/
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo chown root:root /usr/local/lib/demo_service_python/demo_service_python.py
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo chmod 644 /usr/local/lib/demo_service_python/demo_service_python.py
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo systemctl edit service_python --full
[Unit]
# Nom du service pour les humains ;-p
Description=Exemple de service Python
[Service]
Environment=PYTHONUNBUFFERED=1
#Commande à exécuter quand le service est démarré
ExecStart=/usr/bin/python3 /usr/local/lib/demo_service_python/demo_service_python.py
Restart=on-failure
Type=notify
StandardOutput=journal+console
[Install]
WantedBy=default.target
Utiliser un service en tant que root est un risque en sécurité. Sécurisons cela en ajoutant un utilisateur service.
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo useradd -r -s /bin/false service_python
Définissons le service pour qu’il s’exécute avec l’utilisateur service_python
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo systemctl edit service_python --full
[Unit]
# Nom du service pour les humains ;-p
Description=Exemple de service Python
[Service]
User=service_python
Environment=PYTHONUNBUFFERED=1
#Commande à exécuter quand le service est démarré
ExecStart=/usr/bin/python3 /usr/local/lib/demo_service_python/demo_service_python.py
Restart=on-failure
Type=notify
StandardOutput=journal+console
[Install]
WantedBy=default.target
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo systemctl start service_python
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo systemctl status service_python
● service_python.service - Exemple de service Python
Loaded: loaded (/etc/systemd/system/service_python.service; disabled; vendor preset: enabled)
Active: active (running) since Mon 2021-11-22 13:00:31 CET; 9s ago
Main PID: 16955 (python3)
Tasks: 1 (limit: 9150)
Memory: 4.3M
CGroup: /system.slice/service_python.service
└─16955 /usr/bin/python3 /usr/local/lib/demo_service_python/demo_service_python.py
nov. 22 13:00:26 MachineUbuntu.domaine-perso.fr systemd[1]: Starting Exemple de service Python...
nov. 22 13:00:26 MachineUbuntu.domaine-perso.fr python3[16955]: Démarrage de service_python …
nov. 22 13:00:31 MachineUbuntu.domaine-perso.fr python3[16955]: Démarrage OK
nov. 22 13:00:31 MachineUbuntu.domaine-perso.fr python3[16955]: Réponse du service python de démonstration
nov. 22 13:00:31 MachineUbuntu.domaine-perso.fr systemd[1]: Started Exemple de service Python.
nov. 22 13:00:36 MachineUbuntu.domaine-perso.fr python3[16955]: Réponse du service python de démonstration
nov. 22 13:00:41 MachineUbuntu.domaine-perso.fr python3[16955]: Réponse du service python de démonstration
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo systemctl --property=MainPID show service_python
MainPID=16955
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ ps -o uname= -p 16955
service_python
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ ps -o user= -p 16955
service_python
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ ps -o command= -p 16955
/usr/bin/python3 /usr/local/lib/demo_service_python/demo_service_python.py
Les Sockets#
Le sujet de ce chapitre est de pouvoir utiliser des primitives réseau de bas niveau pour se connecter sur un serveur distant. Et de la même façon, monter un serveur distant pour répondre au client.
Principes du réseau#
Communication des machines distantes sur le réseau ?#
Une machine serveur (qui fournie un service) pour communiquer avec les autres machines informatiques sur un réseau doit être identifiable. Pour cela elle doit être munie de ce que l’on appelle une adresse pour le réseau. C’est une adresse IP. Elle est de la forme xxx.xxx.xxx.xxx pour le format d’adresse IPv4, ou de la forme XXXX:XXXX:…:XXXX:XXXX pour le format d’adresse IPv6.
Une machine cliente (c’est à dire qui demande un service) contacte cette machine serveur, suivant son adresse IP, et celle-ci une foi contacté répondra à sa demande.
On a donc un fonctionnement de client-serveur. L’un fait une demande, l’autre lui apporte une réponse.
Atteindre le bon service ?#
Un serveur peut cependant héberger plusieurs services à fournir aux clients. Par exemple un serveur peut héberger un serveur web mais également un serveur de messagerie.
Alors comment se connecter au bon service ?
En utilisant les ports. Les ports les plus connus sont 21 pour le FTP, 80 pour le HTTP, 443 pour le HTTPS, le 22 pour le SSH, 25 pour le SMTP, 110 pour le service POP, etc.
Si vous voulez voir sur quels ports tournent vos services vous pouvez exécuter la commande suivante:
sudo cat /etc/services
L’idée c’est que le client fasse une demande de ce type: 192.168.0.1:9696 (adresse IP 192.168.0.1 et port 9696 ) puis de créer un lien entre ce port 9696 et notre programme.
Pour réaliser ce besoin on utilise des stockets .
Un socket c’est quoi ?#
En anglais un socket est un « trou » qui laisse passer des choses, comme une prise électrique, un filtre à café, une passoire etc.
Le socket est donc dans notre cas, une passerelle au niveau de l’OS entre un programme qui tourne en boucle et le port de la machine qui lui a été dédié. On dit d’ailleurs que «le programme écoute le port qui lui a été réservé». Il récupère les informations de communications sur le port et répond à cette communication par ce port.
Sockets en python#
Pour comprendre le fonctionnement des sockets avec python, nous allons mettre en œuvre un client et un serveur avec deux fichiers «server.py» et «client.py». Le premier script Python sera le serveur qui écoutera les demandes des clients. Le deuxième script script Python «client.py» sera donc lancé comme machine cliente, c’est lui qui fera la demande du service au serveur distant.
Fichier «server.py» :
# -*- coding: utf-8 -*-
import socket
socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
socket.bind(('', 9696))
while True:
socket.listen(5)
client, addresse = socket.accept()
print("{} connecté".format(addresse))
response = client.recv(255)
if response != "":
print response
print("Close")
client.close()
stock.close()
client.py
# -*- coding: utf-8 -*-
import socket
hote = "localhost"
port = 9696
socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
socket.connect((hote, port))
print "Connection sur {}".format(port)
socket.send("Bonjour je suis un client!")
print "Close"
socket.close()
Si vous exécutez ces deux programmes vous verrez donc la demande du client se réaliser côté serveur.
Clients de serveurs#
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ mkdir 14_Serveurs ; cd 14_Serveurs
HTTP#
Connexion à un serveur http#
Nous allons utiliser l’objet HTTPConnection, http.client.HTTPConnection('www.serveur.web.fr', port=80, timeout=10), pour se connecter à un serveur http. Sa propriété request('GET', '/chemin/vers/page/web/') nous permettra de parcourir l’arborescence du serveur web. Enfin l’objet HTTPConnection.getresponse() nous renverra la réponse du serveur web à cette tentative de connexion avec les propriétés status et reason.
Fichier «repertoire_de_developpement/14_Serveurs/connexion_http.py» :
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
import http.client
connexion = http.client.HTTPConnection('utilisateur.documentation.domaine-perso.fr')
connexion.request('GET', '/initiation_developpement_python_pour_administrateur/')
resultat = connexion.getresponse()
print(resultat.status, resultat.reason)
connexion.close()
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ ./client_http.py
200 OK
Pour se connecter en https il suffit d’utiliser l’objet HTTPSConnection suivant le même procédé que ci-dessus.
Client à un serveur http#
Pour lire le contenu HTML renvoyé par le serveur web, nous allons maintenant utiliser la méthode readline() de l’objet getresponse(). Si on veut lire tout le contenu HTML il faut utiliser la propriété read().
Fichier «repertoire_de_developpement/14_Serveurs/client_http.py» :
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
import http.client
connexion = http.client.HTTPConnection('utilisateur.documentation.domaine-perso.fr')
connexion.request('GET', '/initiation_developpement_python_pour_administrateur/')
resultat = connexion.getresponse()
if resultat.status == 200:
for ligne in range(8): # Imprime les 8 premières ligne du retour HTML
print(resultat.readline())
connexion.close()
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ ./client_http.py
b'\n'
b'<!DOCTYPE html>\n'
b'\n'
b'<html lang="fr">\n'
b' <head>\n'
b' <meta charset="utf-8" />\n'
b' <meta name="viewport" content="width=device-width, initial-scale=1.0" />\n'
b' <title>Initiation \xc3\xa0 la programmation Python pour l\xe2\x80\x99administrateur syst\xc3\xa8mes — Initiation \xc3\xa0 la programmation Python pour l'administrateur syst\xc3\xa8mes</title>\n'
SMTP#
Connexion à un serveur de messagerie#
Rédiger et envoyer un email#
Préparons d’abord le serveur local Postfix.
Éditons le fichier «/etc/aliases»
postmaster: root
root: utilisateur
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ sudo dpkg-reconfigure postfix
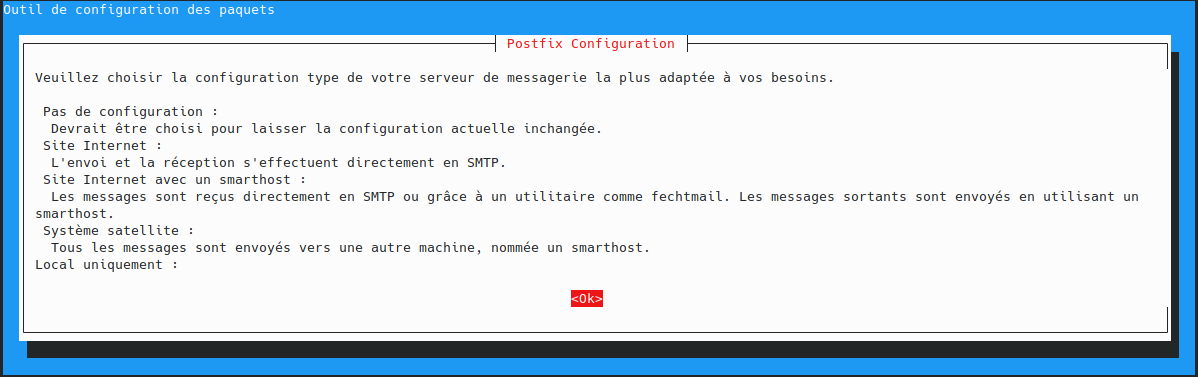
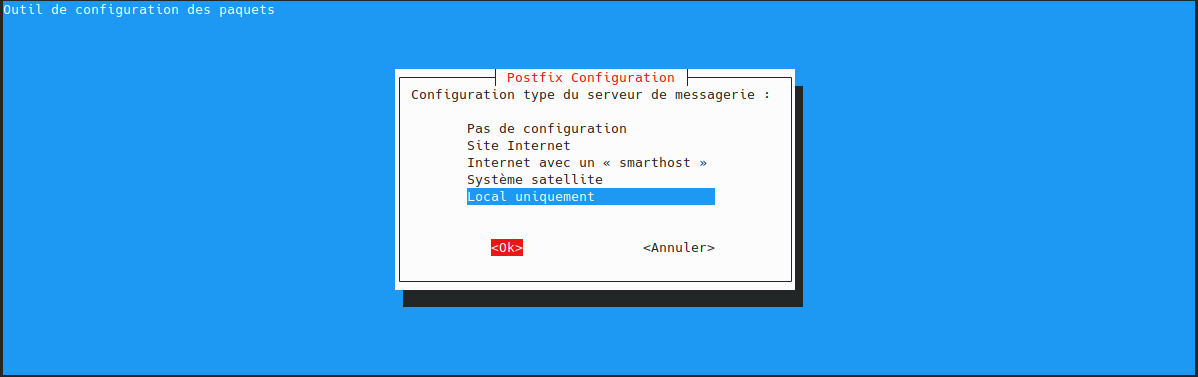
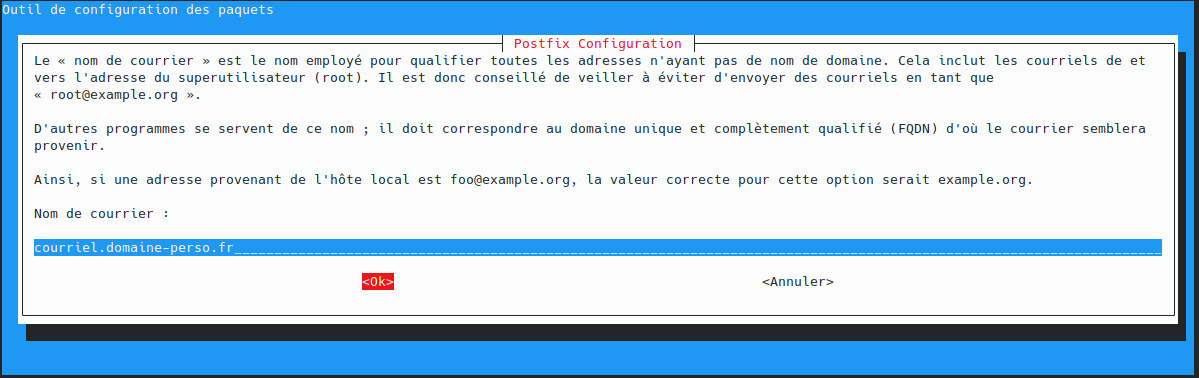
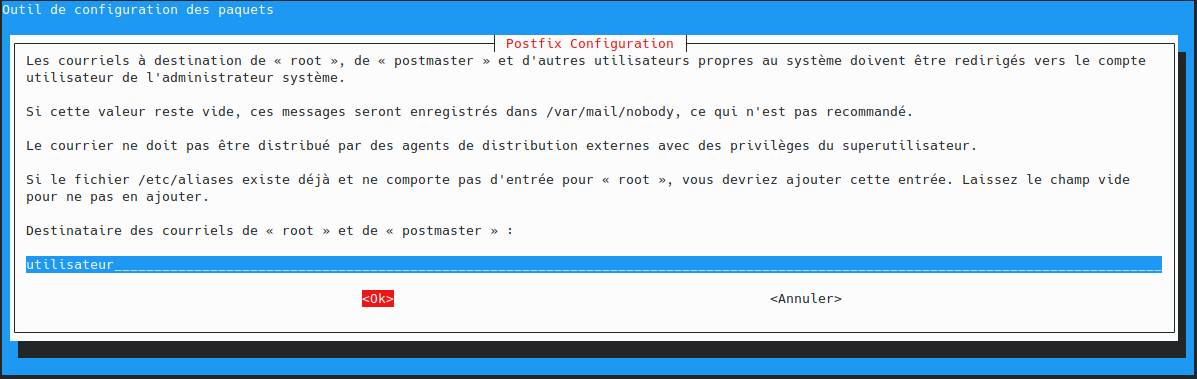
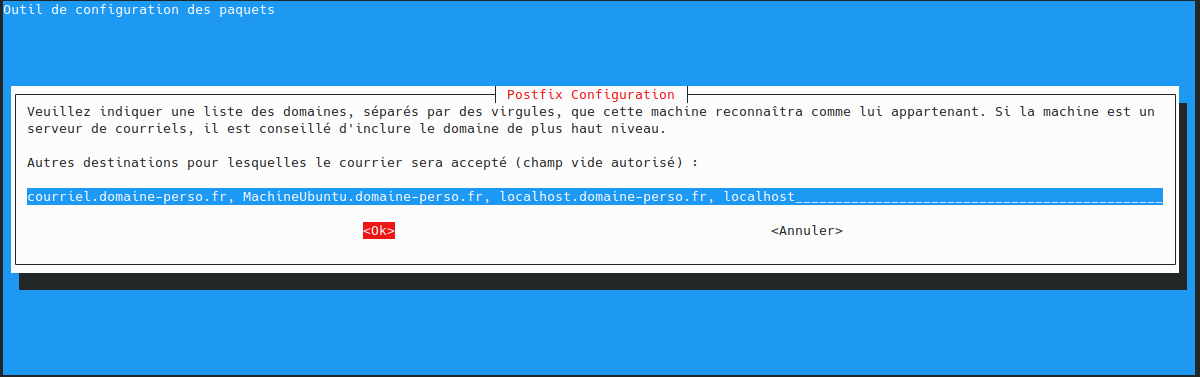
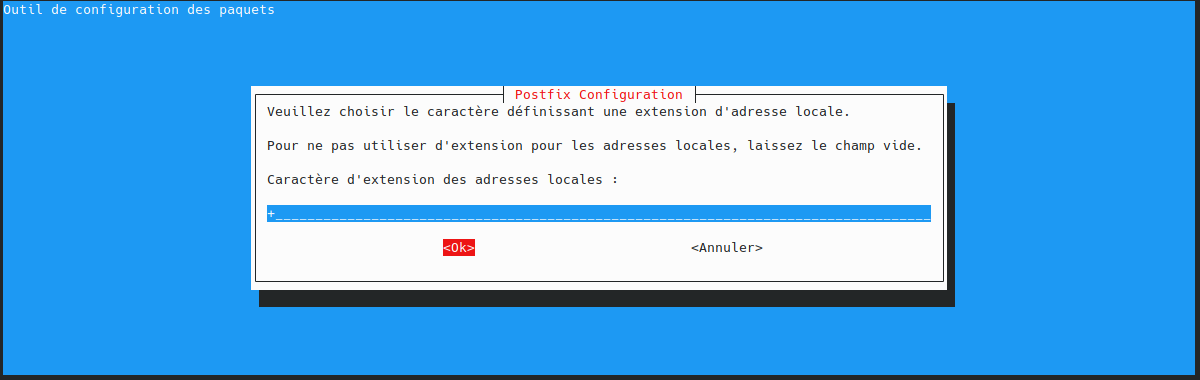
setting synchronous mail queue updates: true
setting myorigin
setting destinations: courriel.domaine-perso.fr, MachineUbuntu.domaine-perso.fr, localhost.domaine-perso.fr, localhost
setting relayhost:
setting mynetworks: 127.0.0.0/8 [::ffff:127.0.0.0]/104 [::1]/128
setting mailbox_size_limit: 0
setting recipient_delimiter: +
setting inet_interfaces: loopback-only
setting inet_protocols: all
WARNING: /etc/aliases exists, but does not have a root alias.
Postfix (main.cf) is now set up with the changes above. If you need to make
changes, edit /etc/postfix/main.cf (and others) as needed. To view Postfix
configuration values, see postconf(1).
After modifying main.cf, be sure to run 'systemctl reload postfix'.
Running newaliases
Traitement des actions différées (« triggers ») pour libc-bin (2.33-0ubuntu5) ...
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ telnet localhost 25
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
220 MachineUbuntu.domaine-perso.fr ESMTP Postfix (Ubuntu)
HELO MachineUbuntu.domaine-perso.fr
250 MachineUbuntu.domaine-perso.fr
MAIL FROM: prenom.nom
250 2.1.0 Ok
RCPT TO: utilisateur@localhost
250 2.1.5 Ok
DATA
354 End data with <CR><LF>.<CR><LF>
From: prenom.nom
To: utilisateur
Subject: Test de message sur port 25
Ceci est un test d’envoi sur port 25
Merci de votre coopération
.
250 2.0.0 Ok: queued as 4BD27C0566
QUIT
221 2.0.0 Bye
Connection closed by foreign host.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ mail
"/var/mail/utilisateur": 1 message 1 nouveau
>N 1 prenom.nom@courrie lun. nov. 22 15: 15/637 Test de message sur port 25
? 1
Return-Path: <prenom.nom@courriel.domaine-perso.fr>
X-Original-To: utilisateur@localhost
Delivered-To: utilisateur@localhost
Received: from MachineUbuntu.domaine-perso.fr (localhost [127.0.0.1])
by MachineUbuntu.domaine-perso.fr (Postfix) with SMTP id 4BD27C0566
for <utilisateur@localhost>; Mon, 22 Nov 2021 15:33:33 +0100 (CET)
From: prenom.nom@courriel.domaine-perso.fr
To: utilisateur@courriel.domaine-perso.fr
Subject: Test de message sur port 25
Message-Id: <20211122143406.4BD27C0566@MachineUbuntu.domaine-perso.fr>
Date: Mon, 22 Nov 2021 15:33:33 +0100 (CET)
Ceci est un test d’envoi sur port 25
Merci de votre coopération
? q
1 message sauvegardé dans /home/utilisateur/mbox
0 message conservé dans /var/mail/utilisateur
Pour nous connecter à un serveur SMTP en Python, nous allons utiliser l’objet SMTP('serveur'), et nous enverrons alors un message avec la propriété send_message(). Pour rédiger le message nous le ferons avec l’objet EmailMessage().
Fichier «repertoire_de_developpement/14_Serveurs/client_messagerie.py» :
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
import smtplib
from email.message import EmailMessage
monemail = EmailMessage()
monemail.set_content('Message du client Python')
monemail['Subject'] = 'Objet du message du client Python'
monemail['From'] = 'prenom.nom@domaine-perso.fr'
monemail['To'] = 'utilisateur@localhost'
serveursmtp = smtplib.SMTP('localhost')
serveursmtp.send_message(monemail)
serveursmtp.quit()
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ chmod u+x client_messagerie.py
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ mail
Pas de courrier pour utilisateur
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ ./client_messagerie.py
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ mail
"/var/mail/utilisateur": 1 message 1 nouveau
>N 1 prenom.nom@domaine lun. nov. 22 15: 17/654 Objet du message du client Python
? 1
Return-Path: <prenom.nom@domaine-perso.fr>
X-Original-To: utilisateur@localhost
Delivered-To: utilisateur@localhost
Received: from gitlab.domaine-perso.fr (localhost [127.0.0.1])
by MachineUbuntu.domaine-perso.fr (Postfix) with ESMTP id 19FCEC0566
for <utilisateur@localhost>; Mon, 22 Nov 2021 15:42:40 +0100 (CET)
Content-Type: text/plain; charset="utf-8"
Content-Transfer-Encoding: 7bit
MIME-Version: 1.0
Subject: Objet du message du client Python
From: prenom.nom@domaine-perso.fr
To: utilisateur@localhost
Message-Id: <20211122144240.19FCEC0566@MachineUbuntu.domaine-perso.fr>
Date: Mon, 22 Nov 2021 15:42:40 +0100 (CET)
Message du client Python
? q
1 message sauvegardé dans /home/utilisateur/mbox
0 message conservé dans /var/mail/utilisateur
Envoi avec un fichiers.
Fichier «repertoire_de_developpement/14_Serveurs/client_messagerie_fichiers.py»
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
import smtplib
import mimetypes
from email.message import EmailMessage
monemail = EmailMessage()
monemail.set_content('Message du client Python')
monemail['Subject'] = 'Objet du message du client Python'
monemail['From'] = 'prenom.nom@domaine-perso.fr'
monemail['To'] = 'utilisateur@localhost'
ctype, encodage = mimetypes.guess_type('./client_messagerie.py')
if ctype is None or encodage is not None:
ctype = 'application/octet-stream'
typeprincipal, soustype = ctype.split('/', 1)
with open('./client_messagerie.py', 'rb') as fichier:
monemail.add_attachment(fichier.read(), maintype=typeprincipal, subtype=soustype, filename='client_messagerie.py')
serveursmtp = smtplib.SMTP('localhost')
serveursmtp.send_message(monemail)
serveursmtp.quit()
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ ./client_messagerie_fichiers.py
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ mail
"/var/mail/utilisateur": 1 message 1 nouveau
>N 1 prenom.nom@domaine lun. nov. 22 16: 37/1573 Objet du message du client Python
? 1
Return-Path: <prenom.nom@domaine-perso.fr>
X-Original-To: utilisateur@localhost
Delivered-To: utilisateur@localhost
Received: from gitlab.domaine-perso.fr (localhost [127.0.0.1])
by MachineUbuntu.domaine-perso.fr (Postfix) with ESMTP id 0946BC0566
for <utilisateur@localhost>; Mon, 22 Nov 2021 16:17:26 +0100 (CET)
MIME-Version: 1.0
Subject: Objet du message du client Python
From: prenom.nom@domaine-perso.fr
To: utilisateur@localhost
Content-Type: multipart/mixed; boundary="===============6562121151377868138=="
Message-Id: <20211122151727.0946BC0566@MachineUbuntu.domaine-perso.fr>
Date: Mon, 22 Nov 2021 16:17:26 +0100 (CET)
--===============6562121151377868138==
Content-Type: text/plain; charset="utf-8"
Content-Transfer-Encoding: 7bit
Message du client Python
--===============6562121151377868138==
Content-Type: text/x-python
Content-Transfer-Encoding: base64
Content-Disposition: attachment; filename="client_messagerie.py"
MIME-Version: 1.0
IyEgL3Vzci9iaW4vZW52IHB5dGhvbjMKIyAtKi0gY29kaW5nOiB1dGYtOCAtKi0KCmltcG9ydCBz
bXRwbGliCmZyb20gZW1haWwubWVzc2FnZSBpbXBvcnQgRW1haWxNZXNzYWdlCgptb25lbWFpbCA9
IEVtYWlsTWVzc2FnZSgpCm1vbmVtYWlsLnNldF9jb250ZW50KCdNZXNzYWdlIGR1IGNsaWVudCBQ
eXRob24nKQptb25lbWFpbFsnU3ViamVjdCddID0gJ09iamV0IGR1IG1lc3NhZ2UgZHUgY2xpZW50
IFB5dGhvbicKbW9uZW1haWxbJ0Zyb20nXSA9ICdwcmVub20ubm9tQGRvbWFpbmUtcGVyc28uZnIn
Cm1vbmVtYWlsWydUbyddID0gJ3V0aWxpc2F0ZXVyQGxvY2FsaG9zdCcKCnNlcnZldXJzbXRwID0g
c210cGxpYi5TTVRQKCdsb2NhbGhvc3QnKQpzZXJ2ZXVyc210cC5zZW5kX21lc3NhZ2UobW9uZW1h
aWwpCnNlcnZldXJzbXRwLnF1aXQoKQo=
--===============6562121151377868138==--
FTP#
Connexion à un serveur ftp#
Pour se connecter à un serveur ftp, nous allons utiliser l’objet FTP du module ftplib. La méthode getwelcome() nous retournera le résultat de cette connection.
Fichier «repertoire_de_developpement/14_Serveurs/connexion_ftp.py» :
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
import ftplib
with ftplib.FTP('ftp.fr.debian.org') as serveurftp:
print(serveurftp.getwelcome())
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ ./connexion_ftp.py
220 Welcome to french Debian FTP server
Client à un serveur ftp#
Pour lire le contenu d’un serveur ftp nous allons utiliser la méthode dir() de l’objet FTP. Nous verons aussi la propriété login('nom_utilisateur', 'mot_de_passe') qui est la connexion effective au serveur ftp.
Fichier «repertoire_de_developpement/14_Serveurs/client_ftp.py» :
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
import ftplib
with ftplib.FTP('ftp.fr.debian.org') as serveurftp:
try:
serveurftp.login()
fichiers = []
serveurftp.dir(fichiers.append)
print(fichiers)
except ftplib.all_errors as e:
print('Erreur FTP :', e)
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ ./client_ftp.py
['drwxr-xr-x 9 1000 1000 4096 Nov 24 09:33 debian', 'drwxr-xr-x 8 1000 1000 4096 Mar 01 2015 debian-amd64', 'drwxr-sr-x 5 1000 1000 102 Mar 13 2016 debian-backports', 'drwxr-xr-x 6 1000 1000 143 Feb 10 2017 debian-non-US', 'drwxr-xr-x 7 1000 1000 142 Nov 23 22:32 debian-security', 'drwxr-sr-x 5 1000 1000 138 Nov 01 2011 debian-volatile', 'drwxr-xr-x 2 1000 1000 6 Nov 24 00:00 tmp']
Pour passer une commande au serveur ftp, nous allons utiliser la méthode sendcmd() pour passer une commande ftp. Nous utiliserons aussi la méthode ftplib.parse257() pour retourner uniquement le répertoire de l’information du serveur ftp. Et aussi l’utilisation de la méthode pwd() nous permettra de retourner le chemin ftp du serveur. Enfin nous allons changer de répertoire avec la méthode cwd().
Fichier «repertoire_de_developpement/14_Serveurs/commandes_ftp.py» :
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
import ftplib
with ftplib.FTP('ftp.fr.debian.org') as serveurftp:
try:
serveurftp.login()
# Envoie de la commande FTP PWD qui affiche le répertoire courant
répertoire_courant = serveurftp.sendcmd('PWD')
print(ftplib.parse257(répertoire_courant))
# La même chose avec la propriété pwd()
répertoire_courant = serveurftp.pwd()
print(répertoire_courant)
# Change de répertoire
serveurftp.cwd('debian')
répertoire_courant = serveurftp.pwd()
print(répertoire_courant)
except ftplib.all_errors as e:
print('Erreur FTP :', e)
De la même façon, nous pouvons créer des répertoires avec la méthode mkd('nouveau_répertoire'). Pour afficher le résultat nous pourrons alors utiliser serveurftp.retrlines('LIST', fichiers.append).
Pour lire la taille d’un fichier texte c’est taille = serveurftp.size('debian/README'). Par contre pour un fichier binaire, il faudra basculer en mode binaire avec la commande serveurftp.sendcmd('TYPE I') et faire alors la commande taille = serveurftp.size('debian/ls-lR.gz').
Pour télécharger un fichier, c’est par exemple avec :
import os
import ftplib
with ftplib.FTP('ftp.fr.debian.org') as serveurftp:
fichier_origine = 'debian/README'
nom_fichier_téléchargé = 'LISEZMOI'
try:
serveurftp.login()
with open(nom_fichier_téléchargé, 'w') as fichier:
resultat = serveurftp.retrlines('RETR ' + fichier_origine, serveurftp.write)
if not resultat.startswith('226 Transfer complete'):
print('Télécgargement échoué')
if os.path.isfile(nom_fichier_téléchargé):
os.remove(nom_fichier_téléchargé)
except ftplib.all_errors as e:
print('Erreur FTP :', e)
if os.path.isfile(nom_fichier_téléchargé):
os.remove(nom_fichier_téléchargé)
De la même façon pour envoyer un fichier il faudra utiliser la commande resultat = serveurftp.retrlines('STOR ' + nomdefichierdestination, fichier). L’option d”open() étant biensûr 'rb'.
Le WEB#
Il peut être intéressant, dans certains cas, d’implémenter un serveur web dans votre application. Cela permet notamment une communication entre vos programmes via un navigateur.
En Python créer un serveur web , c’est quelques lignes de code.
Créer un serveur HTTP#
Servir des pages statiques#
Fichier «repertoire_de_developpement/14_Serveurs/public_html/index.html» :
<!DOCTYPE html>
<html lang="fr">
<head>
<meta charset="utf-8">
<title>Serveur WEB Statique Python</title>
</head>
<body>
<header>Une page WEB</header>
<main>Le corps de la page</main>
<footer>Par un développeur Python</footer>
</body>
</html>
Fichier «repertoire_de_developpement/14_Serveurs/serveur_statique_http.py» :
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
import os
import http.server
import socketserver
PORT = 10000
os.chdir(os.path.expanduser('./public_html'))
with socketserver.TCPServer(('', PORT), http.server.SimpleHTTPRequestHandler) as httpd:
print('Serveur http sur port ', PORT)
httpd.serve_forever()
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ ./serveur_statique_http.py
Serveur http sur port 10000
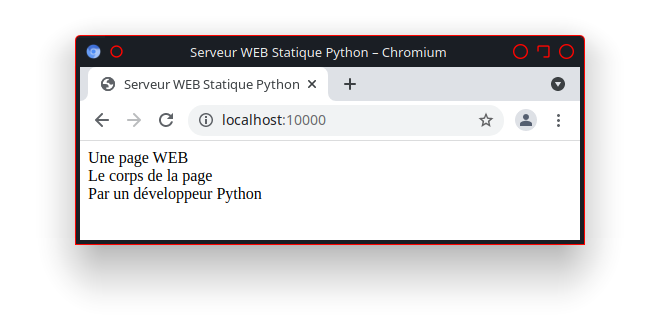
Servir des pages dynamiques#
Fichier «repertoire_de_developpement/14_Serveurs/serveur_dynamique_http.py» :
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
import os
import http.server
PORT = 10000
ref_serveur = ('', PORT)
os.chdir(os.path.expanduser('./public_html'))
entree = http.server.CGIHTTPRequestHandler
entree.cgi_directories = ['/']
print("Serveur actif sur le port :", PORT)
httpd = http.server.HTTPServer(ref_serveur, entree)
httpd.serve_forever()
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ ./serveur_dynamique_http.py
Serveur actif sur le port : 10000
Créer aussi une page cgi pour le serveur WEB afin d’afficher un contenu.
Créer un fichier «repertoire_de_developpement/14_Serveurs/public_html/index.py» à la racine de votre projet HTML :
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
import cgi
form = cgi.FieldStorage()
print("Content-type: text/html; charset=utf-8\n")
print(form.getvalue("nom"))
html = """<!DOCTYPE html>
<head>
<title>Mon site</title>
</head>
<body>
<form action="/index.py" method="post">
<input type="text" name="nom" value="Votre nom SVP" />
<input type="submit" name="send" value="Envoyer l'information au serveur">
</form>
</body>
</html>
"""
print(html)
Ouvrez votre navigateur et indiquez-lui l’url de votre serveur web, dans notre cas ce sera localhost:10000/index.py.
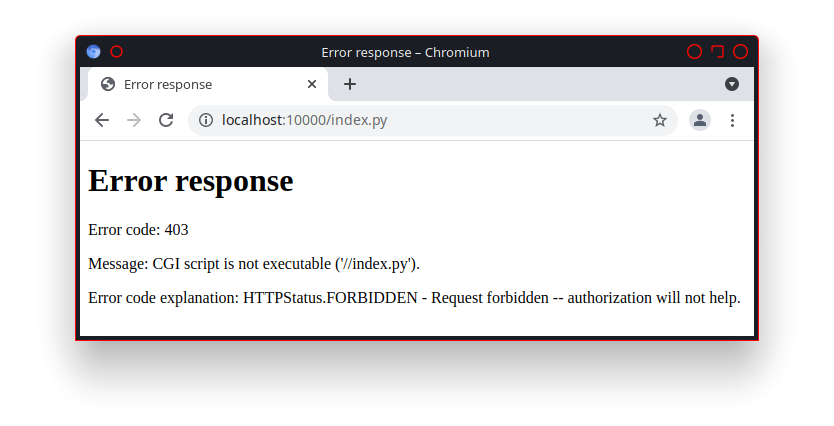
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ ./serveur_dynamique_http.py
Serveur actif sur le port : 10000
127.0.0.1 - - [24/Nov/2021 15:49:37] code 403, message CGI script is not executable ('//index.py')
127.0.0.1 - - [24/Nov/2021 15:49:37] "GET /index.py HTTP/1.1" 403 -
Arrêtez le serveur WEB avec Ctrl+c.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ chmod u+x public_html/index.py
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ ./serveur_dynamique_http.py
Serveur actif sur le port : 10000
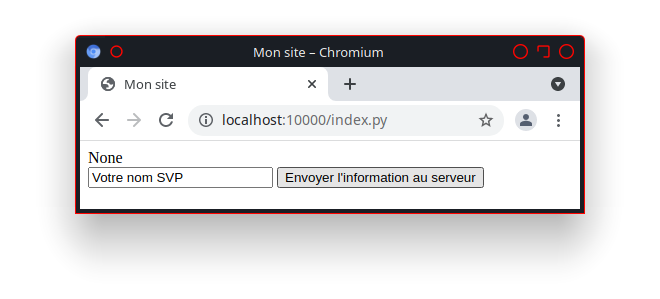
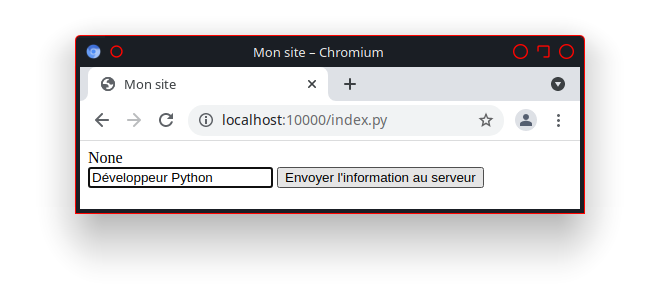
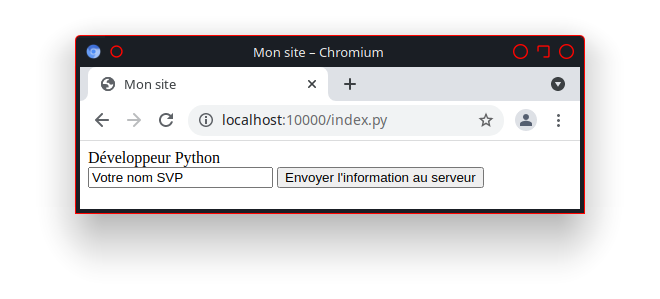
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ ./serveur_dynamique_http.py
Serveur actif sur le port : 10000
127.0.0.1 - - [24/Nov/2021 17:08:04] "GET /index.py HTTP/1.1" 200 -
127.0.0.1 - - [24/Nov/2021 17:10:33] "POST /index.py HTTP/1.1" 200 -
Python ne fait pas de différences entre POST et GET, vous pouvez passer une variable dans l’url le résultat sera le même http://localhost:10000/index.py?name=Prenom%20NOM
Pour afficher les erreurs sur votre page web, vous pouvez ajouter la fonction :
import cgitb
cgitb.enable()
Pour afficher les variables d’environnement, vous pouvez appeler la méthode test().
cgi.test()
Pour approfondir ces fonctionnalités allez jeter un œuil sur Common Gateway Interface support
Flask#
Flask est un framework WEB Python. C’est un ensemble d’outils qui vous permet grace à une API web de vous concentrer sur votre code applicatif orienté WEB.
Installer Flask#
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ sudo pip install Flask
Collecting Flask
Downloading Flask-2.0.2-py3-none-any.whl (95 kB)
|████████████████████████████████| 95 kB 579 kB/s
Collecting Werkzeug>=2.0
Downloading Werkzeug-2.0.2-py3-none-any.whl (288 kB)
|████████████████████████████████| 288 kB 1.6 MB/s
Collecting itsdangerous>=2.0
Downloading itsdangerous-2.0.1-py3-none-any.whl (18 kB)
Requirement already satisfied: click>=7.1.2 in /usr/lib/python3/dist-packages (from Flask) (7.1.2)
Requirement already satisfied: Jinja2>=3.0 in /usr/local/lib/python3.9/dist-packages (from Flask) (3.0.1)
Requirement already satisfied: MarkupSafe>=2.0 in /usr/local/lib/python3.9/dist-packages (from Jinja2>=3.0->Flask) (2.0.1)
Installing collected packages: Werkzeug, itsdangerous, Flask
Successfully installed Flask-2.0.2 Werkzeug-2.0.2 itsdangerous-2.0.1
Première page WEB#
Nous allons créer une application WEB minimale avec le framework Flask. Pour cela on utilise la classe Flask du module Python flask. La propriété @Flask.route() permet de préciser le chemin WEB du serveur. Une fonction à la suite de @Flask.route() va retourner le contenu à afficher.
Fichier «repertoire_de_developpement/14_Serveurs/flask_bonjour.py» :
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
from flask import Flask
application = Flask(__name__)
@application.route('/')
def bonjour():
return 'Bonjour de la part de Flask'
On va maintenant exécuter l’application WEB Flask. Pour cela il nous faut définir deux variables d’environnement FLASK_APP, qui correspond au fichier à exécuter, et FLASK_ENV qui est un paramètre d’exécution.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ export FLASK_APP=flask_bonjour.py
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ export FLASK_ENV=development
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ flask run
* Serving Flask app 'flask_bonjour.py' (lazy loading)
* Environment: development
* Debug mode: on
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
* Restarting with stat
* Debugger is active!
* Debugger PIN: 781-882-942
Structure des projets#
Lorsque l’on veut faire un projet Flask digne de ce nom, il faut impérativement structurer son code pour éviter des problèmes de maintenabilité avec le facteur d’échelle et de complexité du code Python.
Voici un exemple d’organisation structurelle typique pour Flask :
monprojet-flask
├── app
│ ├── appli.py
│ ├── auth.py
│ ├── db.py
│ ├── __init__.py
│ ├── schema.sql
│ ├── static
│ │ ├── css
│ │ │ └── styles.css
│ │ ├── font
│ │ └── img
│ └── templates
│ ├── appli
│ │ └── index.html
│ ├── auth
│ │ ├── login.html
│ │ └── register.html
│ └── base.html
├── CHANGELOG
├── CONTRIBUTING.md
├── docs
│ ├── documentation
│ ├── locales
│ ├── make.bat
│ ├── Makefile
│ └── sources-documents
│ ├── conf.py
│ ├── images
│ └── index.rst
├── LICENSE
├── makediagrammes
├── makedocs
├── MANIFEST.in
├── packages-docs.txt
├── packages.txt
├── README.md
├── requirements-docs.txt
├── requirements.txt
├── setup.py
├── tests
│ ├── conftest.py
│ ├── data.sql
│ ├── test_appli.py
│ ├── test_auth.py
│ ├── test_db.py
│ └── test_factory.py
└── venv
Et pour le fichier .gitignore
.directory
venv/
*.pyc
__pycache__/
db.sqlite3
.DS_Store
.gitstore
instance/
.pytest_cache/
.coverage
htmlcov/
css_compiled
dist/
build/
*.egg-info/
Configurer le projet#
Ici, il s’agit d’initialiser notre projet pour activer l’interface WEB.
Fichier «repertoire_de_developpement/14_Serveurs/monprojet-flask/app/__init__.py» :
from flask import Flask
def create_app():
app = Flask(__name__)
@app.route('/')
def racine():
return 'Page racine'
return app
Fichier «repertoire_de_developpement/14_Serveurs/monprojet-flask/execute» :
#! /usr/bin/env bash
export FLASK_APP=app
export FLASK_ENV=development
flask run
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ cd monprojet-flask/
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs/monprojet-flask$ chmod u+x execute
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs/monprojet-flask$ ./execute
* Serving Flask app 'app' (lazy loading)
* Environment: development
* Debug mode: on
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
* Restarting with stat
* Debugger is active!
* Debugger PIN: 781-882-942
Les routes#
Les routes permettent de faire le lien entre le chemin demandé en URL HTTP par un utilisateur et le contenu à afficher. Pour ajouter un chemin HTTP il suffit donc d’ajouter un @app.route('/mon/chemin/utilisateur/') avec une fonction décrivant le résultat renvoyé.
from flask import Flask
def create_app():
app = Flask(__name__)
@app.route('/')
def racine():
return 'Page racine'
@app.route('/apropos')
def apropos():
return 'Page À propos de l\'application Flask'
return app
Note
Vous n’avez pas besoin de relancer Flask, un simple rafraîchissement du navigateur prendra en charge vos modifications.
Si vous avez une erreur du code le débogueur de Flask vous l’indiquera avec l’option d’environnement export= FLASK_ENV=development.
Vous pouvez vérifier le bon fonctionnement en passant l’URL http://localhost:5000/apropos au navigateur WEB.
Saisissez maintenant l’URL http://localhost:5000/apropos/ dans le navigateur.
Pour éviter que la route Flask considère que http://localhost:5000/apropos et http://localhost:5000/apropos/ soit deux sites distincts, il siffit de modifier @app.route('/apropos') en @app.route('/apropos/'). Avec cette modification les deux URLs seront considérées par Flask comme identiques.
Avec paramètres#
Nous voulons maintenant identifier un utilisateur avec un paramètre dans l’URL, genre http://localhost:5000/utilisateur/programmeur. Où le chemin est http://localhost:5000/utilisateur/ et l’utilisateur programmeur.
from flask import Flask
def create_app():
app = Flask(__name__)
@app.route('/')
def racine():
return 'Page racine'
@app.route('/apropos/')
def apropos():
return 'À propos de l\'application Flask'
@app.route('/utilisateur/<nom>')
def utilisateur(nom):
return 'Bonjour {}!'.format(nom.capitalize())
return app
Saisissez l’URL http://localhost:5000/utilisateur/programmeur
Passez l’URL http://localhost:5000/utilisateur/ au navigateur WEB.
Corrigeons cela avec d’abord la prise en charge de l’URL, puis avec la définition d’une valeur par défaut .
@app.route('/utilisateur/')
@app.route('/utilisateur/<nom>')
def utilisateur(nom=''):
if nom != '':
return 'Bonjour {}!'.format(nom.capitalize())
else:
return 'vous n\'avez pas saisi votre nom!'
Serveur REST#
Une API REST permet une interaction avec le format JSON en utilisant simplement des requêtes HTTP. Flask permet simplement la cration d’un serveur WEB REST en retournant ces données au format JSON.
Ces données peuvent-être traitées au travers de requêtes HMTL GET, POST, PUT ou DELETE.
Renvoyer des données JSON#
Créons une route @app.route('/donnees') pour retourner des données JSON.
import json
from flask import Flask
def create_app():
app = Flask(__name__)
@app.route('/')
def racine():
return 'Page racine'
@app.route('/apropos/')
def apropos():
return 'À propos de l\'application Flask'
@app.route('/utilisateur/')
@app.route('/utilisateur/<nom>')
def utilisateur(nom):
return 'Bonjour {}!'.format(nom.capitalize())
@app.route('/donnees')
def donnees():
return json.dumps({'nom': 'programmeur', 'courriel': 'programmeur@fai.fr'})
return app
Cela nous retourne bien un contenu affiché JSON. Mais si on regarde ce que le navigateur comprend de ce contenu. Pour Chrome «Ctrl+Maj+i» (Ctrl+Alt+i sous windows, et Cmd+Maj+i sous Mac).
Appuyez sur la touche de rafraîchissement de votre navigateur (F5).
Cliquez sur «données» dans Name.
On voit alors dans «Response Headers», que la variable «Content-Type:» à la valeur «text/html». Ce n’est pas le format JSON.
Modifions notre code pour corriger cela avec Flask.
from flask import Flask, jsonify
def create_app():
app = Flask(__name__)
''''''
@app.route('/donnees')
def donnees():
return jsonify({'nom': 'programmeur', 'courriel': 'programmeur@fai.fr'})
return app
Maintenant notre serveur WEB Flask est en API REST.
Traitement de requêtes REST#
Pour le protocole HTTP nous avons six modes de requêtes :
GET
POST
PUT
DELETE
HEAD
PATCH
Avec Flask, pour préciser le mode de requêtes HTML, la méthode @Flask.route() utilise l’option methods=['MethodeHTML']. @app.route('/mon/chemin/web', methods=['MethodeHTML']).
Nous avons aussi besoin, dans le module flask, de la classe request pour traiter avec Python les retours de ces modes de requête HTTP.
Exemple avec la méthode GET :
from flask import Flask, request, jsonify
def create_app():
app = Flask(__name__)
''''''
@app.route('/donnees', methods=['GET'])
def donnees():
nom = request.args.get('nom')
return nom
return app
Passez l’URL http://localhost:5000/donnes?nom=programmeur au navigateur WEB.
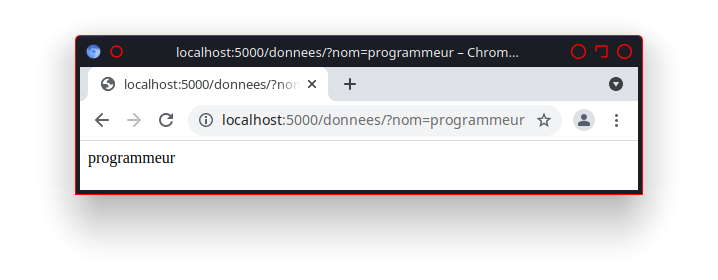
Nous allons maintenant mettre en œuvre les méthodes GET, PUT, POST et DELETE pour créer un serveur base de données REST rudimentaire avec Flask.
Pour cela nous avons besoin d’une application cliente «HTTPie» pour commander le serveur de base de données REST.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ sudo apt install httpie
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ touch monprojet-flask/app/donnees.txt
Créons ce serveur de base de données REST.
Fichier «repertoire_de_developpement/14_Serveurs/monprojet-flask/app/__init__.py» :
import json
from flask import Flask, request, jsonify
def create_app():
app = Flask(__name__)
@app.route('/')
def racine():
return 'Page racine'
@app.route('/apropos/')
def apropos():
return 'À propos de l\'application Flask'
@app.route('/utilisateur/')
@app.route('/utilisateur/<nom>')
def utilisateur(nom=''):
if nom != '':
return render_template('utilisateur.html', name=nom)
else:
return 'vous n\'avez pas saisi votre nom!'
@app.route('/donnees', methods=['GET'])
def recherche_donnee():
print('recherche_donnee()')
nom = request.args.get('nom')
print(nom)
with open('app/donnees.txt', 'r') as fichier:
donnees = fichier.read()
if donnees:
enregistrements = json.loads(donnees)
for enregistrement in enregistrements:
if enregistrement['nom'] == nom:
return jsonify(enregistrement)
return jsonify({'erreur': 'donnée non trouvée'})
return nom
@app.route('/donnees', methods=['PUT'])
def cree_donnee():
print('cree_donnee()')
nouveau = json.loads(request.data)
print(nouveau)
with open('app/donnees.txt', 'r') as fichier:
donnees = fichier.read()
if not donnees:
enregistrements = [nouveau]
else:
enregistrements = json.loads(donnees)
enregistrements.append(nouveau)
with open('app/donnees.txt', 'w') as fichier:
fichier.write(json.dumps(enregistrements, indent=2))
return jsonify(nouveau)
@app.route('/donnees', methods=['POST'])
def maj_donnee():
print('maj_donnee()')
enregistrement = json.loads(request.data)
misajours = []
with open('app/donnees.txt', 'r') as fichier:
donnees = fichier.read()
enregistrements = json.loads(donnees)
for element in enregistrements:
if element['nom'] == enregistrement['nom']:
element['courriel'] = enregistrement['courriel']
misajours.append(element)
with open('app/donnees.txt', 'w') as fichier:
fichier.write(json.dumps(misajours, indent=2))
return jsonify(enregistrement)
@app.route('/donnees', methods=['DELETE'])
def supprime_donnee():
print('supprime_donnee')
enregistrement = json.loads(request.data)
misajours = []
with open('app/donnees.txt', 'r') as fichier:
donnees = fichier.read()
enregistrements = json.loads(donnees)
for element in enregistrements:
if element['nom'] == enregistrement['nom']:
continue
misajours.append(element)
with open('app/donnees.txt', 'w') as fichier:
fichier.write(json.dumps(misajours, indent=2))
return jsonify(enregistrement)
return app
Vérifions le bon fonctionnement avec le client HTTPie :
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ http -v localhost:5000/donnees?nom=programmeur
GET /donnees?nom=programmeur HTTP/1.1
Accept: */*
Accept-Encoding: gzip, deflate
Connection: keep-alive
Host: localhost:5000
User-Agent: HTTPie/2.2.0
HTTP/1.0 200 OK
Content-Length: 47
Content-Type: application/json
Date: Fri, 26 Nov 2021 09:05:44 GMT
Server: Werkzeug/2.0.2 Python/3.9.5
{
"erreur": "donnée non trouvée"
}
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ http GET localhost:5000/donnees?nom=programmeur"
HTTP/1.0 200 OK
Content-Length: 47
Content-Type: application/json
Date: Fri, 26 Nov 2021 09:05:50 GMT
Server: Werkzeug/2.0.2 Python/3.9.5
{
"erreur": "donnée non trouvée"
}
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ http PUT localhost:5000/donnees nom=utilisateur courriel=utilisateur@fai.fr
HTTP/1.0 200 OK
Content-Length: 64
Content-Type: application/json
Date: Fri, 26 Nov 2021 09:07:30 GMT
Server: Werkzeug/2.0.2 Python/3.9.5
{
"courriel": "utilisateur@fai.fr",
"nom": "utilisateur"
}
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ http PUT localhost:5000/donnees nom=programmeur courriel=programmeur@fai.fr
HTTP/1.0 200 OK
Content-Length: 64
Content-Type: application/json
Date: Fri, 26 Nov 2021 09:08:16 GMT
Server: Werkzeug/2.0.2 Python/3.9.5
{
"courriel": "programmeur@fai.fr",
"nom": "programmeur"
}
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ http GET localhost:5000/donnees?nom=programmeur
HTTP/1.0 200 OK
Content-Length: 64
Content-Type: application/json
Date: Fri, 26 Nov 2021 09:09:38 GMT
Server: Werkzeug/2.0.2 Python/3.9.5
{
"courriel": "programmeur@fai.fr",
"nom": "programmeur"
}
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ http POST localhost:5000/donnees nom=utilisateur courriel=utilisateur@autrefai.fr
HTTP/1.0 200 OK
Content-Length: 69
Content-Type: application/json
Date: Fri, 26 Nov 2021 09:14:19 GMT
Server: Werkzeug/2.0.2 Python/3.9.5
{
"courriel": "utilisateur@autrefai.fr",
"nom": "utilisateur"
}
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ http GET localhost:5000/donnees?nom=utilisateur
HTTP/1.0 200 OK
Content-Length: 69
Content-Type: application/json
Date: Fri, 26 Nov 2021 09:15:03 GMT
Server: Werkzeug/2.0.2 Python/3.9.5
{
"courriel": "utilisateur@autrefai.fr",
"nom": "utilisateur"
}
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ http DELETE localhost:5000/donnees nom=utilisateur
HTTP/1.0 200 OK
Content-Length: 27
Content-Type: application/json
Date: Fri, 26 Nov 2021 09:18:03 GMT
Server: Werkzeug/2.0.2 Python/3.9.5
{
"nom": "utilisateur"
}
À la fin nous avons dans le fichier «repertoire_de_developpement/14_Serveurs/monprojet-flask/app/donnees.txt» :
[
{
"nom": "programmeur",
"courriel": "programmeur@fai.fr"
}
]
Notre base de données REST fonctionne.
Les templates#
Nous voulons maintenant retourner du contenu HTML. Pour cela nous pouvons retourner un texte ou un fichier HTML avec Python.
Mais Flask utilise un moteur de modèles (templates) nommé Jinja2 qui va nous permettre d’utiliser des fichiers lisibles en HTML. Pour retourner un modèle HTML avec Flask, nous utiliserons la classe render_template() du module flask.
Créer le fichier «repertoire_de_developpement/14_Serveursmonprojet-flask/app/templates/index.html» :
<!DOCTYPE html>
<html lang="fr">
<head>
<meta charset="utf-8">
<title>Application Flask</title>
</head>
<body>
<header>Page WEB d'entrée</header>
<main>Racine du site WEB</main>
<footer>fichier index.html</footer>
</body>
</html>
le fichier «repertoire_de_developpement/14_Serveursmonprojet-flask/app/templates/about.html» :
<!DOCTYPE html>
<html lang="fr">
<head>
<meta charset="utf-8">
<title>Application Flask</title>
</head>
<body>
<header>À propos</header>
<main></main>
<footer>fichier about.html</footer>
</body>
</html>
Et le fichier «repertoire_de_developpement/14_Serveursmonprojet-flask/app/templates/utilisateur.html» :
<!DOCTYPE html>
<html lang="fr">
<head>
<meta charset="utf-8">
<title>Application Flask</title>
</head>
<body>
<header>Utilisateur {{ name }}</header>
<main>Bonjour {{ name|capitalize }}</main>
<footer>fichier utilisateur.html</footer>
</body>
</html>
Enfin modifier «repertoire_de_developpement/14_Serveurs/monprojet-flask/app/__init__.py» :
import json
from flask import Flask, request, jsonify, render_template
def create_app():
app = Flask(__name__)
@app.route('/')
def racine():
return render_template('index.html')
@app.route('/apropos/')
def apropos():
return render_template('about.html')
@app.route('/utilisateur/')
@app.route('/utilisateur/<nom>')
def utilisateur(nom=''):
if nom != '':
return render_template('utilisateur.html', name=nom)
else:
return 'vous n\'avez pas saisi votre nom!'
''''''
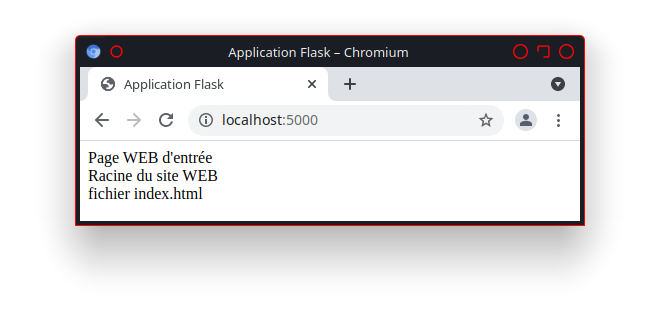
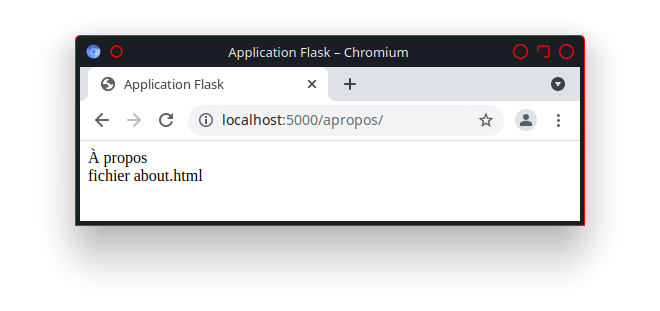
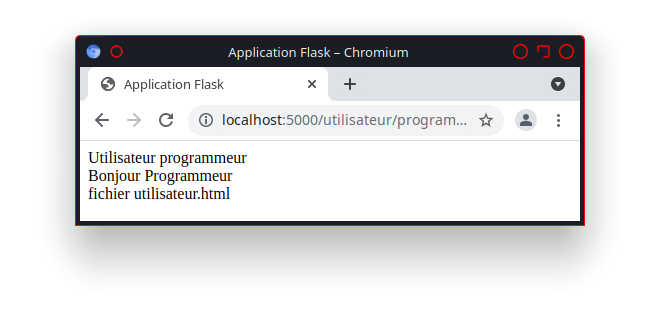
Ces pages WEB ont un rendu très primitif, maintenant nous allons ajouter des styles à notre application WEB pour la rendre plus sexy et ergonomique.
Les fichiers statiques#
Les feuilles de styles, les javascripts, les images, etc. sont appelés des fichiers statiques pour Flask.
Flask cherche ces fichiers dans le répertoire static, ici «repertoire_de_developpement/14_Serveurs/monprojet-flask/app/static».
créer le fichier «repertoire_de_developpement/14_Serveurs/monprojet-flask/app/static/css/styles.css» :
@import url('https://fonts.googleapis.com/css2?family=Raleway&display=swap');
body {
background-color: rgba(253, 245, 230, 0.5);
font-family: "Raleway", sans-sherif;
}
Nous allons maintenant utiliser cette feuille de style dans nos modèles HTML avec url_for().
Modifier le fichier «repertoire_de_developpement/14_Serveursmonprojet-flask/app/templates/index.html» :
<!DOCTYPE html>
<html lang="fr">
<head>
<meta charset="utf-8">
<title>Application Flask</title>
<link rel="stylesheet" type="text/css" href="{{ url_for('static', filename='css/styles.css') }}">
</head>
<body>
<header>Page WEB d'entrée</header>
<main>Racine du site WEB</main>
<footer>fichier index.html</footer>
</body>
</html>
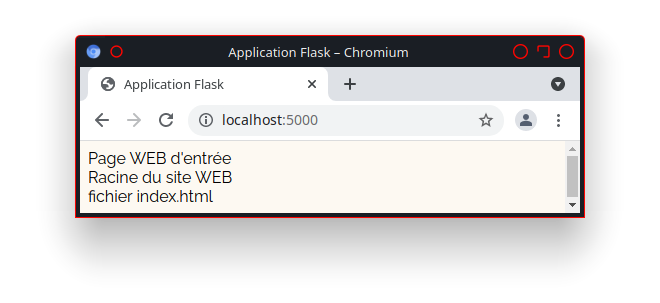
Bon ceci est bien joli, mais il faut rajouter la définition de style à tous nos fichiers HTML. Flask nous permet de résoudre ce problème en utilisant l’héritage de modèles HTML.
Héritages#
Nous allons créer un fichier HTML qui va contenir la structure de tous nos fichiers HTML.
Créer le fichier «repertoire_de_developpement/14_Serveursmonprojet-flask/app/templates/base.html» :
<!doctype html>
<html lang="fr">
<head>
<!-- Metas -->
<meta charset="utf-8">
<meta name="description" content="Héritages Flask">
<meta name="author" content="Stagiaire Python Développeur">
<meta name="dcterms.rightHolder" content="GNU General Public Licence 3">
<meta name="dcterms.rights" content="https://www.gnu.org/licences/gpl-3.0.fr.html">
<meta name="dcterms.dateCopyrighted" content="2021">
<meta name="keywords" content="Python, Flask, HTML, CSS">
<meta name="viewport" content="width=device-width, initial-scale=1">
{% block meta %}{% endblock %}
<!-- endMetas -->
<!-- Title -->
<title>{% block title %}Python Flask{% endblock %}</title>
<!-- endTitle -->
<!-- Links -->
<link rel="shortcut icon" type="image/png" href="{{ url_for('static', filename='img/favicon.png') }}" />
{% block links %}{% endblock %}
<!-- endLinks -->
<!-- Styles -->
<link rel="stylesheet" type="text/css" href="https://fonts.googleapis.com/css?family=Open+Sans" />
<link rel="stylesheet" type="text/css" href="{{ url_for('static', filename='font/font-awesome.min.css') }}" />
{% block styles %}{% endblock %}
<!-- endStyles -->
<!-- Scripts -->
{% block javascript %}{% endblock %}
<!-- endScripts -->
</head>
<body role="document">
<header role="banner">{% block header %}{% endblock %}</header>
<navbar role="navigation" id="navbaron">{% block navbar %}{% endblock %}</navbar>
{% block messages %}{% endblock %}
<main role="main">{% block content %}{% endblock %}</main>
<aside role="aside">{% block aside %}{% endblock %}</aside>
<footer role="footer">{% block footer %}{% endblock %}</footer>
{% block scripts %}{% endblock %}
</body>
</html>
Modifier le fichier «repertoire_de_developpement/14_Serveursmonprojet-flask/app/templates/index.html» :
{% extends "base.html" %}
{% block styles %}<link rel="stylesheet" type="text/css" href="{{ url_for('static', filename='css/styles.css') }}">{% endblock %}
{% block title %}Application Flask{% endblock %}
{% block header %}Page WEB d'entrée{% endblock %}
{% block content %}Racine du site WEB{% endblock %}
{% block footer %}fichier index.html{% endblock %}
Modifier le fichier «repertoire_de_developpement/14_Serveursmonprojet-flask/app/templates/about.html» :
{% extends "base.html" %}
{% block styles %}<link rel="stylesheet" type="text/css" href="{{ url_for('static', filename='css/styles.css') }}">{% endblock %}
{% block title %}Application Flask{% endblock %}
{% block header %}À propos{% endblock %}
{% block content %}Application de Développeur PYTHON{% endblock %}
{% block footer %}fichier about.html{% endblock %}
Modifier le fichier «repertoire_de_developpement/14_Serveursmonprojet-flask/app/templates/utilisateur.html» :
{% extends "base.html" %}
{% block styles %}<link rel="stylesheet" type="text/css" href="{{ url_for('static', filename='css/styles.css') }}">{% endblock %}
{% block title %}Application Flask{% endblock %}
{% block header %}Utilisateur {{ name }}{% endblock %}
{% block content %}Bonjour {{ name|capitalize }}{% endblock %}
{% block footer %}fichier utilisateur.html{% endblock %}
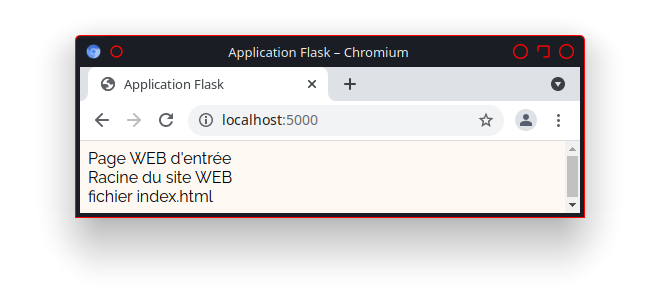
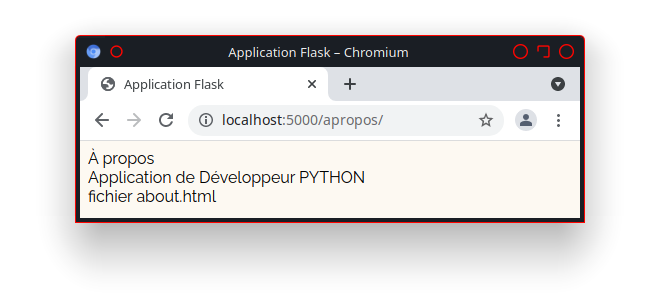
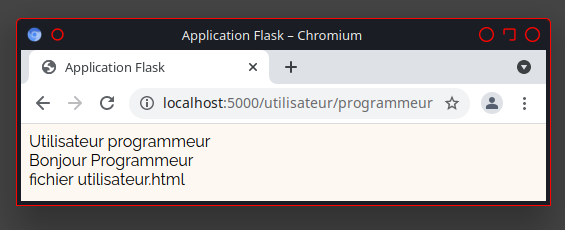
Bon c’est un peu plus joli, mais on veux rendre notre code plus ergonomique avec du code purecss.
Ajout de modules Flask#
Nous allons installer des modules à Flask pour pouvoir compiler et compresser des feuilles de styles CSS. Pour cela nous allons utiliser le compilateur lesscss. Ce code nous permettra d’implémenter une barre de menus responsive design (adaptée aux mobiles, tablettes et PC).
Installons d’abords les outils Flask lesscss, et créons la structure des fichiers lesscss.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ sudo apt install node-less
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ sudo pip install flask-assets lesscpy cssmin
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ mkdir ~/repertoire_de_developpement/14_Serveurs/monprojet-flask/app/static/css/less
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ touch ~/repertoire_de_developpement/14_Serveurs/monprojet-flask/app/static/css/less/main.less
Nous allons maintenant mettre en place le système de compilation et de compression lesscss dans Flask. Nous utilisons le module Python flask_assets avec ses classes Environment et Bundle pour cela.
Modifions d’abord l’architecture du code pour le rendre plus maintenable.
Créer «repertoire_de_developpement/14_Serveurs/monprojet-flask/config.py» :
class Config():
LESS_BIN = '/usr/bin/lessc'
ASSETS_DEBUG = False
ASSETS_AUTO_BUILD = True
Créer «repertoire_de_developpement/14_Serveurs/monprojet-flask/app/appli.py» :
import json
from app import app
from flask import request, jsonify, render_template
@app.route('/')
def racine():
return render_template('index.html')
@app.route('/apropos/')
def apropos():
return render_template('about.html')
@app.route('/utilisateur/')
@app.route('/utilisateur/<nom>')
def utilisateur(nom=''):
if nom != '':
return render_template('utilisateur.html', name=nom)
else:
return 'vous n\'avez pas saisi votre nom!'
@app.route('/donnees', methods=['GET'])
def recherche_donnee():
print('recherche_donnee()')
nom = request.args.get('nom')
print(nom)
with open('app/donnees.txt', 'r') as fichier:
donnees = fichier.read()
if donnees:
enregistrements = json.loads(donnees)
for enregistrement in enregistrements:
if enregistrement['nom'] == nom:
return jsonify(enregistrement)
return jsonify({'erreur': 'donnée non trouvée'})
return nom
@app.route('/donnees', methods=['PUT'])
def cree_donnee():
print('cree_donnee()')
nouveau = json.loads(request.data)
print(nouveau)
with open('app/donnees.txt', 'r') as fichier:
donnees = fichier.read()
if not donnees:
enregistrements = [nouveau]
else:
enregistrements = json.loads(donnees)
enregistrements.append(nouveau)
with open('app/donnees.txt', 'w') as fichier:
fichier.write(json.dumps(enregistrements, indent=2))
return jsonify(nouveau)
@app.route('/donnees', methods=['POST'])
def maj_donnee():
print('maj_donnee()')
enregistrement = json.loads(request.data)
misajours = []
with open('app/donnees.txt', 'r') as fichier:
donnees = fichier.read()
enregistrements = json.loads(donnees)
for element in enregistrements:
if element['nom'] == enregistrement['nom']:
element['courriel'] = enregistrement['courriel']
misajours.append(element)
with open('app/donnees.txt', 'w') as fichier:
fichier.write(json.dumps(misajours, indent=2))
return jsonify(enregistrement)
@app.route('/donnees', methods=['DELETE'])
def supprime_donnee():
print('supprime_donnee')
enregistrement = json.loads(request.data)
misajours = []
with open('app/donnees.txt', 'r') as fichier:
donnees = fichier.read()
enregistrements = json.loads(donnees)
for element in enregistrements:
if element['nom'] == enregistrement['nom']:
continue
misajours.append(element)
with open('app/donnees.txt', 'w') as fichier:
fichier.write(json.dumps(misajours, indent=2))
return jsonify(enregistrement)
Modifier «repertoire_de_developpement/14_Serveurs/monprojet-flask/app/__init__.py» :
from flask import Flask
from config import Config
from flask_assets import Environment, Bundle
app = Flask(__name__, instance_relative_config=False)
app.config.from_object(Config)
assets = Environment(app)
style_bundle = Bundle(
'css/less/main.less',
filters='less,cssmin',
output='css/styles.min.css',
extra={'rel': 'stylesheet/css'}
)
assets.register('main_styles', style_bundle)
style_bundle.build()
from app import appli
Maintenant construisons du code HTML et lesscss pour avoir une barre de menus responsive design en pur css.
Créer le fichier «repertoire_de_developpement/14_Serveursmonprojet-flask/app/templates/base.html» :
<!doctype html>
<html lang="fr">
<head>
<!-- Metas -->
<meta charset="utf-8">
<meta name="description" content="Héritages Flask">
<meta name="author" content="Stagiaire Python Développeur">
<meta name="dcterms.rightHolder" content="GNU General Public Licence 3">
<meta name="dcterms.rights" content="https://www.gnu.org/licences/gpl-3.0.fr.html">
<meta name="dcterms.dateCopyrighted" content="2021">
<meta name="keywords" content="Python, Flask, HTML, CSS">
{% block meta %}{% endblock %}
<!-- endMetas -->
<!-- Title -->
<title>{% block title %}Python Flask{% endblock %}</title>
<!-- endTitle -->
<!-- Links -->
<link rel="shortcut icon" type="image/png" href="{{ url_for('static', filename='img/favicon.png') }}" />
{% block links %}{% endblock %}
<!-- endLinks -->
<!-- Styles -->
<link rel="stylesheet" type="text/css" href="https://fonts.googleapis.com/css?family=Material+Icons" />
{% block styles %}{% endblock %}
<!-- endStyles -->
<!-- Scripts -->
{% block javascript %}{% endblock %}
<!-- endScripts -->
</head>
<body role="document">
<header role="banner">{% block header %}{% endblock %}</header>
<navbar role="navigation" id="navbaron">{% block navbar %}{% endblock %}</navbar>
{% block messages %}{% endblock %}
<main role="main">{% block content %}{% endblock %}</main>
<aside role="aside">{% block aside %}{% endblock %}</aside>
<footer role="footer">{% block footer %}{% endblock %}</footer>
{% block scripts %}{% endblock %}
</body>
</html>
Modifier le fichier «repertoire_de_developpement/14_Serveursmonprojet-flask/app/templates/index.html» :
{% extends "base.html" %}
{% block meta %}<meta name="viewport" content="width=device-width, initial-scale=1">{% endblock %}
{% block styles %}<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/4.7.0/css/font-awesome.min.css" />
<link rel="stylesheet" type="text/css" href="{{ url_for('static', filename='css/styles.min.css') }}">{% endblock %}
{% block title %}Application Flask{% endblock %}
{% block header %}<section class="Entete">
<h1>Page WEB d'entrée</h1>
<h4>Développeur PYTHON</h4>
</section>{% endblock %}
{% block navbar %}<ul class="navbar">
<li>
<a href="#navbaron"><i class="fa fa-bars"></i></a>
<a href="#"><i class="fa fa-minus-square"></i></a>
</li>
<li>
<a href="/"><i class="fa fa-home"></i>Racine<span class="hide-tablet"> du site Flask</span></a>
</li>
</ul>
<ul id="Sidenav">
<li>
<a href="/"><i class="fa fa-home"></i>Racine du site Flask</a>
</li>
</ul>{% endblock %}
{% block content %}<h1>Contenu du site WEB</h1>{% endblock %}
{% block footer %}<h2>fichier index.html</h2>{% endblock %}
Modifier le fichier «repertoire_de_developpement/14_Serveurs/monprojet-flask/app/static/css/less/main.less» :
/*Import graphic framework*/
@import "general";
/*Fin import graphic framework*/
/*Import widgets framework*/
@import "widgets";
/*Fin import widgets framework*/
Créer le fichier «repertoire_de_developpement/14_Serveurs/monprojet-flask/app/static/css/less/general.less» :
/*************************/
/* Mise en page générale */
/*************************/
/*Configuration de compatibilité navigateurs*/
*{-webkit-box-sizing:border-box;
-moz-box-sizing:border-box;
box-sizing:border-box}
html{-ms-text-size-adjust:100%;
-webkit-text-size-adjust:100%}
body{margin:0}
aside,footer,header,main,menu,section{display:block}
[hidden],template{display:none}
a{background-color:transparent}
a:active,a:hover{outline:0}
abbr[title]{border-bottom:1px dotted}
dfn{font-style:italic}
mark{background:#ff0;
color:#000}
small{font-size:80%}
sub,sup{font-size:75%;
line-height:0;
position:relative;
vertical-align:baseline}
sup{top:-0.5em}
sub{bottom:-0.25em}
img{border:0}
svg:not(:root){overflow:hidden}
body,h1,h2,h3,h4,h5 {font-family: "Raleway", sans-serif};
body{
background-color: @sand;
};
Créer le fichier «repertoire_de_developpement/14_Serveurs/monprojet-flask/app/static/css/less/colors.less» :
/* fichier Colors.less */
/*blues*/
@aqua: #00ffff;
@cyan:#00bcd4;
@blue: #2196f3;
@pale-blue: #ddffff;
@light-blue: #87ceeb;
@blue-grey: #607d8b;
@dark-blue: #4d636f;
@teal: #009688;
/*?*/
@indigo :#3f51b5;
@amber: #ffc107;
@brown: #795548;
/*greens*/
@green: #4caf50;
@pale-green: #ddffdd;
@light-green: #8bc34a;
@khaki: #f0e68c;
/*yellows*/
@yellow: #ffeb3b;
@pale-yellow: #ffffcc;
@sand: #fdf5e6;
@lime: #cddc39;
/*reds*/
@red: #f44336;
@pale-red: #ffdddd;
@light-red: #ff656c;
@orange: #ff9800;
@deep-orange: #ff5722;
@pink: #e91e63;
@purple: #9c27b0;
@deep-purple: #673ab7;
/*nuances*/
@grey: #9e9e9e;
@light-grey: #f1f1f1;
@dark-grey: #616161;
@white: #fff;
@black: #000;
@pale-grey: #ccc;
/*Color gesture*/
.front-color(@color){
.color(){
color: @color;
};
.color-important(){
color: @color !important;
};
.color-darken(){
color: darken(@color, @dark);
};
.color-darken-important(){
color: darken(@color, @dark) !important;
};
};
.bakground-color(@color){
.bg-color(){
background: @color;
};
.bg-color-important(){
background: @color !important;
};
.bg-color-darken(){
background: darken(@color, @dark);
};
.bg-color-darken-important(){
background: darken(@color, @dark) !important;
};
};
.border-color(@color){
.bd-color(){
border-color: @color;
};
.bd-color-important(){
border-color: @color !important;
};
};
.text-amber,.hover-text-amber{color:@amber!important};
.text-aqua,.hover-text-aqua{color:@aqua!important};
.text-blue,.hover-text-blue{color:@blue!important};
.text-light-blue,.hover-text-light-blue{color:@light-blue!important};
.text-brown,.hover-text-brown{color:@brown!important};
.text-cyan,.hover-text-cyan{color:@cyan!important};
.text-blue-grey,.hover-text-blue-grey{color:@blue-grey!important};
.text-green,.hover-text-green{color:@green!important};
.text-light-green,.hover-text-light-green{color:@light-green!important};
.text-indigo,.hover-text-indigo{color:@indigo!important};
.text-khaki,.hover-text-khaki{color:@khaki!important};
.text-lime,.hover-text-lime{color:@lime!important};
.text-orange,.hover-text-orange{color:@orange!important};
.text-deep-orange,.hover-text-deep-orange{color:@deep-orange!important};
.text-pink,.hover-text-pink{color:@pink!important};
.text-purple,.hover-text-purple{color:@purple!important};
.text-deep-purple,.hover-text-deep-purple{color:@deep-purple!important};
.text-red,.hover-text-red{color:@red!important};
.text-sand,.hover-text-sand{color:@sand!important};
.text-teal,.hover-text-teal{color:@teal!important};
.text-yellow,.hover-text-yellow{color:@yellow!important};
.text-white,.hover-text-white{color:@white!important};
.text-black,.hover-text-black{color:@black!important};
.text-grey,.hover-text-grey{color:@grey!important};
.text-light-grey,.hover-text-light-grey{color:@light-grey!important};
.text-dark-grey,.hover-text-dark-grey{color:@dark-grey!important};
.text-pale-red,.hover-text-pale-red{color:@pale-red!important};
.text-pale-green,.hover-text-pale-green{color:@pale-green!important};
.text-pale-yellow,.hover-text-pale-yellow{color:@pale-yellow!important};
.text-pale-blue,.hover-text-pale-blue{color:@pale-blue!important};
.text-dark-blue,.hover-text-dark-blue{color:@dark-blue!important};
.amber,.hover-amber{.text-black;background-color:@amber!important};
.aqua,.hover-aqua{.text-black;background-color:@aqua!important};
.blue,.hover-blue{.text-white;background-color:@blue!important};
.light-blue,.hover-light-blue{.text-black;background-color:@light-blue!important};
.brown,.hover-brown{.text-white;background-color:@brown!important};
.cyan,.hover-cyan{.text-black;background-color:@cyan!important};
.blue-grey,.hover-blue-grey{.text-white;background-color:@blue-grey!important};
.green,.hover-green{.text-white;background-color:@green!important};
.light-green,.hover-light-green{.text-black;background-color:@light-green!important};
.indigo,.hover-indigo{.text-white;background-color:@indigo!important};
.khaki,.hover-khaki{.text-black;background-color:@khaki!important};
.lime,.hover-lime{.text-black;background-color:@lime!important};
.orange,.hover-orange{.text-black;background-color:@orange!important};
.deep-orange,.hover-deep-orange{.text-white;background-color:@deep-orange!important};
.pink,.hover-pink{.text-white;background-color:@pink!important};
.purple,.hover-purple{.text-white;background-color:@purple!important};
.deep-purple,.hover-deep-purple{.text-white;background-color:@deep-purple!important};
.red,.hover-red{.text-white;background-color:@red!important};
.sand,.hover-sand{.text-black;background-color:@sand!important};
.teal,.hover-teal{.text-white;background-color:@teal!important};
.yellow,.hover-yellow{.text-black;background-color:@yellow!important};
.white,.hover-white{.text-black;background-color:@white!important};
.black,.hover-black{.text-white;background-color:@black!important};
.grey,.hover-grey{.text-black;background-color:@grey!important};
.light-grey,.hover-light-grey{.text-black;background-color:@light-grey!important};
.dark-grey,.hover-dark-grey{.text-white;background-color:@dark-grey!important};
.pale-red,.hover-pale-red{.text-black;background-color:@pale-red!important};
.pale-green,.hover-pale-green{.text-black;background-color:@pale-green!important};
.pale-yellow,.hover-pale-yellow{.text-black;background-color:@pale-yellow!important};
.pale-blue,.hover-pale-blue{.text-black;background-color:@pale-blue!important};
.dark-blue,.hover-dark-blue{.text-white;background-color:@dark-blue!important};
.info-bg-color,.hover-info-bg-color{.text-white;background-color:@teal!important};
.sheet-bg-color,.hover-sheet-bg-color{.text-white;background-color: @dark-blue!important};
.color-btn,.hover-color-btn{.text-dark-blue;background-color:@pale-green!important};
.border-amber,.hover-border-amber{border-color:@amber!important};
.border-aqua,.hover-border-aqua{border-color:@aqua!important};
.border-blue,.hover-border-blue{border-color:@blue!important};
.border-light-blue,.hover-border-light-blue{border-color:@light-blue!important};
.border-brown,.hover-border-brown{border-color:@brown!important};
.border-cyan,.hover-border-cyan{border-color:@cyan!important};
.border-blue-grey,.hover-blue-grey{border-color:@blue-grey!important};
.border-green,.hover-border-green{border-color:@green!important};
.border-light-green,.hover-border-light-green{border-color:@light-green!important};
.border-indigo,.hover-border-indigo{border-color:@indigo!important};
.border-khaki,.hover-border-khaki{border-color:@khaki!important};
.border-lime,.hover-border-lime{border-color:@lime!important};
.border-orange,.hover-border-orange{border-color:@orange!important};
.border-deep-orange,.hover-border-deep-orange{border-color:@deep-orange!important};
.border-pink,.hover-border-pink{border-color:@pink!important};
.border-purple,.hover-border-purple{border-color:@purple!important};
.border-deep-purple,.hover-border-deep-purple{border-color:@deep-purple!important};
.border-red,.hover-border-red{border-color:@red!important};
.border-sand,.hover-border-sand{border-color:@sand!important};
.border-teal,.hover-border-teal{border-color:@teal!important};
.border-yellow,.hover-border-yellow{border-color:@yellow!important};
.border-white,.hover-border-white{border-color:@white!important};
.border-black,.hover-border-black{border-color:@black!important};
.border-grey,.hover-border-grey{border-color:@grey!important};
.border-light-grey,.hover-border-light-grey{border-color:@light-grey!important};
.border-dark-grey,.hover-border-dark-grey{border-color:@dark-grey!important};
.border-pale-red,.hover-border-pale-red{border-color:@pale-red!important};
.border-pale-green,.hover-border-pale-green{border-color:@pale-green!important};
.border-pale-yellow,.hover-border-pale-yellow{border-color:@pale-yellow!important};
.border-pale-blue,.hover-border-pale-blue{border-color:@pale-blue!important};
.border-dark-blue,.hover-border-dark-blue{border-color:@dark-blue!important};
/* fin fichier colors.less */
Créer le fichier «repertoire_de_developpement/14_Serveurs/monprojet-flask/app/static/css/less/sizes.less» :
/* Sizes */
@tiny: 2px;
@small: 2 * @tiny;
@medium : 4 * @tiny;
@large : 6 * @tiny;
@xlarge : 8 * @tiny;
@xxlarge : 12 * @tiny;
@jumbo: 16 * @tiny;
.tiny{font-size:10px!important};
.small{font-size:12px!important};
.medium{font-size:15px!important};
.large{font-size:18px!important};
.xlarge{font-size:24px!important};
.xxlarge{font-size:36px!important};
.xxxlarge{font-size:48px!important};
.jumbo{font-size:64px!important};
Créer le fichier «repertoire_de_developpement/14_Serveurs/monprojet-flask/app/static/css/less/positions.less» :
/*Gestion affichages*/
.hide{display:none!important};
.show{display:block!important};
.show-inline{display:inline-block!important};
/*Dispositions*/
.position(){
/*Affichage absolu*/
.display-topleft(){position:absolute;left:0;top:0};
.display-topright(){position:absolute;right:0;top:0};
.display-bottomleft(){position:absolute;left:0;bottom:0};
.display-bottomright(){position:absolute;right:0;bottom:0};
.display-middle(){position:absolute;top:50%;left:50%;transform:translate(-50%,-50%);-ms-transform:translate(-50%,-50%)};
.display-topmiddle(){position:absolute;left:0;top:0;width:100%;text-align:center};
.display-bottommiddle(){position:absolute;left:0;bottom:0;width:100%;text-align:center}
/*Bandeau*/
.banner(){position:fixed;width:100%;z-index:1;};
/*Position block*/
.top(){top:0};
.bottom(){bottom:0};
.left(){float:left!important};
.right(){float:right!important};
/*Textes*/
.text-vertical(){word-break:break-all;line-height:1;text-align:center;width:0.6em};
.text-left(){text-align:left!important};
.text-right(){text-align:right!important};
.text-justify(){text-align:justify!important};
.text-center(){text-align:center!important};
};
.top{top:0};
.bottom{bottom:0};
.left{float:left!important};
.right{float:right!important};
/*.overlay{position:fixed;display:none;width:100%;height:100%;top:0;left:0;right:0;bottom:0;background-color:rgba(0,0,0,0.5);z-index:2};*/
.vertical{word-break:break-all;line-height:1;text-align:center;width:0.6em};
.left-align{text-align:left!important};
.right-align{text-align:right!important};
.justify{text-align:justify!important};
.center{text-align:center!important};
.top,.bottom{position:fixed;width:100%;z-index:1};
.display-topleft{position:absolute;left:0;top:0};
.display-topright{position:absolute;right:0;top:0};
.display-bottomleft{position:absolute;left:0;bottom:0};
.display-bottomright{position:absolute;right:0;bottom:0};
.display-middle{position:absolute;top:50%;left:50%;transform:translate(-50%,-50%);-ms-transform:translate(-50%,-50%)};
.display-topmiddle{position:absolute;left:0;top:0;width:100%;text-align:center};
.display-bottommiddle{position:absolute;left:0;bottom:0;width:100%;text-align:center}
Créer le fichier «repertoire_de_developpement/14_Serveurs/monprojet-flask/app/static/css/less/layouts.less» :
/*Mise en page*/
.margin(@margin: 16px){margin:@margin!important};
.margin-top(@margin: 16px){margin-top:@margin!important};
.margin-bottom(@margin: 16px){margin-bottom:@margin!important};
.margin-left(@margin: 16px){margin-left:@margin!important};
.margin-right(@margin: 16px){margin-right:@margin!important};
.padding(@padding){padding-top:@padding!important;padding-bottom:@padding!important};
.padding-size(@size){
padding:@size 2*@size !important;
};
.noborder{border:0!important};
.border(@color: #ccc){border:1px solid @color !important};
.border-top(@color: #ccc){border-top:1px solid @color !important};
.border-bottom(@color: #ccc){border-bottom:1px solid @color !important};
.border-left(@color: #ccc){border-left:1px solid @color !important};
.border-right(@color: #ccc){border-right:1px solid @color !important};
Créer le fichier «repertoire_de_developpement/14_Serveurs/monprojet-flask/app/static/css/less/effects.less» :
/*Effets*/
/*Import hover framework*/
@import "hover.css";
.opacity,.hover-opacity:hover{opacity:0.60;filter:alpha(opacity=60);-webkit-backface-visibility:hidden};
.shadow-large{box-shadow:0 8px 16px 0 rgba(255,255,255,0.2),0 6px 20px 0 rgba(255,255,255,0.19)};
.shadow-small{box-shadow:0 2px 4px 0 rgba(0,0,0,0.16),0 2px 10px 0 rgba(0,0,0,0.12)!important};
.hover-dark-blue {
-webkit-transition:background-color .3s,color .15s,box-shadow .3s,opacity 0.3s;
transition:background-color .3s,color .15s,box-shadow .3s,opacity 0.3s;
};
.border-radius(@radius: 10px){
-moz-border-radius: @radius;
-webkit-border-radius: @radius;
border-radius: @radius;
};
.animate-fading{
-webkit-animation:fading 10s infinite;
animation:fading 10s infinite;
};
@-webkit-keyframes fading{0%{opacity:0}50%{opacity:1}100%{opacity:0}};
@keyframes fading{0%{opacity:0}50%{opacity:1}100%{opacity:0}};
.animate-opacity{
-webkit-animation:opac 1.5s;
animation:opac 1.5s;
};
@-webkit-keyframes opac{from{opacity:0} to{opacity:1}};
@keyframes opac{from{opacity:0} to{opacity:1}};
.animate-top{
position:relative;
-webkit-animation:animatetop 0.4s;
animation:animatetop 0.4s;
};
@-webkit-keyframes animatetop{from{top:-300px;opacity:0} to{top:0;opacity:1}};
@keyframes animatetop{from{top:-300px;opacity:0} to{top:0;opacity:1}};
.animate-left{
position:relative;
-webkit-animation-timing-function: ease;
animation-timing-function: ease;
/*-webkit-animation:animateleft 1s;*/
-webkit-animation: animateleft 1s; /* Chrome, Safari, Opera */
/*animation:animateleft 1s*/
animation: animateleft 1s;
};
/* Chrome, Safari, Opera */
@-webkit-keyframes animateleft{from{left:-300px;opacity:0} to{left:0;opacity:1}};
/* Standard syntax */
@keyframes animateleft{from{left:-300px;opacity:0} to{left:0;opacity:1}};
.animate-right{
position:relative;
-webkit-animation:animateright 0.4s;
animation:animateright 0.4s
};
@-webkit-keyframes animateright{from{right:-300px;opacity:0} to{right:0;opacity:1}};
@keyframes animateright{from{right:-300px;opacity:0} to{right:0;opacity:1}};
.animate-bottom{
position:relative;
-webkit-animation:animatebottom 0.4s;
animation:animatebottom 0.4s
};
@-webkit-keyframes animatebottom{from{bottom:-300px;opacity:0} to{bottom:0px;opacity:1}};
@keyframes animatebottom{from{bottom:-300px;opacity:0} to{bottom:0;opacity:1}};
.animate-zoom {
-webkit-animation:animatezoom 0.6s;
animation:animatezoom 0.6s
};
@-webkit-keyframes animatezoom{from{-webkit-transform:scale(0)} to{-webkit-transform:scale(1)}};
@keyframes animatezoom{from{transform:scale(0)} to{transform:scale(1)}};
.animate-input{
-webkit-transition:width 0.4s ease-in-out;
transition:width 0.4s ease-in-out
};
.animate-input:focus{width:100%!important};
.user-select{
-webkit-touch-callout:none;
-webkit-user-select:none;
-khtml-user-select:none;
-moz-user-select:none;
-ms-user-select:none;
user-select:none;
};
.transition-btn{
-webkit-transition:background-color .3s,color .15s,box-shadow .3s,opacity 0.3s;
transition:background-color .3s,color .15s,box-shadow .3s,opacity 0.3s;
};
.btn,.btn-floating,.dropnav a,.btn-floating-large,.btn-block,.hover-shadow,.hover-opacity,#Sidenav a,.pagination li a,.hoverable tbody tr,.hoverable li,.accordion-content a,.dropdown-content a,.dropdown-click:hover,.dropdown-hover:hover,.opennav,.closenav,.closebtn,.hover-amber,.hover-aqua,.hover-blue,.hover-light-blue,.hover-brown,.hover-cyan,.hover-blue-grey,.hover-green,.hover-light-green,.hover-indigo,.hover-dark-blue,.hover-khaki,.hover-lime,.hover-orange,.hover-deep-orange,.hover-pink,.hover-purple,.hover-deep-purple,.hover-red,.hover-sand,.hover-teal,.hover-yellow,.hover-white,.hover-black,.hover-grey,.hover-light-grey,.hover-dark-grey,.hover-text-amber,.hover-text-aqua,.hover-text-blue,.hover-text-light-blue,.hover-text-brown,.hover-text-cyan,.hover-text-blue-grey,.hover-text-green,.hover-text-light-green,.hover-text-indigo,.hover-text-khaki,.hover-text-lime,.hover-text-orange,.hover-text-deep-orange,.hover-text-pink,.hover-text-purple,.hover-text-deep-purple,.hover-text-red,.hover-text-sand,.hover-text-teal,.hover-text-yellow,.hover-text-white,.hover-text-black,.hover-text-grey,.hover-text-light-grey,.hover-text-dark-grey
{-webkit-transition:background-color .3s,color .15s,box-shadow .3s,opacity 0.3s;transition:background-color .3s,color .15s,box-shadow .3s,opacity 0.3s};
.Sans-Defilement::-webkit-scrollbar {display:none;};
.Sans-Defilement::-moz-scrollbar {display:none;};
.Sans-Defilement::-o-scrollbar {display:none;};
.Sans-Defilement::-goole-ms-scrollbar {display:none;};
.Sans-Defilement::-khtml-scrollbar {display:none;};
.Sans-Defilement:disabled {background: white;};
Créer le fichier «repertoire_de_developpement/14_Serveurs/monprojet-flask/app/static/css/less/widgets.less» :
/*++++++++++++++++++++++++++++++++++++++++++++*/
/* Graphic Framework widget */
/*++++++++++++++++++++++++++++++++++++++++++++*/
/*Import colors framework*/
@import "colors";
/*Import colors framework*/
@import "sizes";
/*Import positions framework*/
@import "positions";
/*Fin import positions framework*/
/*Import layout framework*/
@import "layouts";
/*Fin import layout framework*/
/*Import effects framework*/
@import "effects";
/*Fin import effects framework*/
/*Entete*/
header{
max-width:100%;
.teal;
};
.Entete{
z-index:1;
.container;
.info-bg-color;
h1{.info-bg-color;};
h4{
.text-white;
.opacity;
};
};
/*Corps de l'application*/
main{
.container;
width:100%;
height:100%;
overflow:auto
};
/*barre lattérale*/
aside{
};
/*Pied de page*/
footer{
};
/**********/
/* Output */
/**********/
/* Label */
/* Tooltip/Balloon help */
/* Status bar */
/* Progress bar */
progress#avancement:hover:after{
display:block;
padding: 0px;
margin-top: -2px;
text-align: center;
content: attr(value)'%';
};
/* Infobar */
message{
.container;
width:100%;
height:100%;
overflow:auto;
p{
.error;
};
};
.error{ background: #f0d6d6; padding: 0.5em;};
/*-----------*/
/* Contenair */
/*-----------*/
.container{
padding:0.01em 16px;
&:after{
content:"";
display:table;
clear:both;
};
};
/**********/
/* Window */
/**********/
/*Collapsible panel*/
/*Accordion*/
/*Modal windows*/
/*Dialog box*/
/*Palette windows*/
/*Inspector windows*/
/*Frame*/
/*Fond de panneaux*/
/*Panels*/
.card{.shadow-small;};
/*.panel{padding:0.01em 16px;margin-top:16px!important;margin-bottom:16px!important};*/
.panel(@titre-text-color; @bg-titre-color; @bg-pannel-color) {
.left;
.margin-top;
.margin-bottom;
@media (min-width:626px) {
.margin-left;
.margin-right;
width: 95%;
};
@media (max-width:625px) {
.large;
width: 100%;
};
fieldset {
.container;
.padding(32px);
.card;
background-color: @bg-pannel-color !important;
/*
color:@white!important;
background-color:@teal!important;
*/
legend {
.card;
.border-radius;
color: @titre-text-color !important;
background-color: @bg-titre-color !important;
/*
color:@white!important;
background-color: @dark-blue!important;
*/
position: relative;
float: left;
height: 30px;
margin-top: -45px;
padding: 4px 8px;
opacity: 0.9;
};
};
};
/*Canvas*/
/*Covoer Flow*/
/*Bubble Flow*/
/************/
/* Menu bar */
/************/
/*Affichage de petites résolutions <=625px*/
@media screen and (max-width:625px) {
.navbar li:not(:first-child){float:none;width:100%!important}
.navbar li.right{float:none!important}
.navbar{text-align:center}
};
@media (max-width:430px) {
span.hide-phone {display:none!important;};
};
@media (max-width:625px) {
span.hide-mobile {display:none!important;};
/*Gestion de l'affichage de la barre de navigation*/
/*Supprime les texte de la barre de menu*/
navbar > ul.navbar > li:not(:first-child) {
display:none!important;
};
/*Supprime l'information principale*/
main > section > h2:first-child{
display:none!important;
};
/*Gestion de l'affichage du panneau de menu*/
navbar {
width:100%;
&:target #Sidenav {
.show;
margin-top:0px;
};
&:target ul.navbar > li:first-child > a:nth-child(2) {
.show;
overflow:hidden;
};
&:target ul.navbar > li:first-child > a:first-child {
.hide;
overflow:hidden;
};
};
};
/*Affichage entre 626px et 992px*/
@media (max-width:992px) and (min-width:626px) {
/*Supprime le texte superflu*/
span.hide-tablet {display:none!important;};
/*Supprime l'affichage du bouton panneau latéral*/
navbar > ul > li:first-child {
display:none!important;
};
};
@media screen and (max-width:992px) {
#Sidenav.collapse{display:none}
.main{margin-left:0!important;margin-right:0!important}
};
/*Affichage de plus de 992px*/
@media screen and (min-width:993px) {
span.hide-pc {display:none!important;};
#Sidenav.collapse{display:block!important}
};
@media (min-width:993px) {
/*Supprime l'affichage du bouton panneau latéral*/
navbar > ul > li:first-child {
display:none!important;
};
/*Affiche un texte différent de déconnexion*/
navbar > ul > li:nth-last-child(2) {
display:none!important;
};
};
/*Barre de menus tablette ou PC*/
navbar{
ul{
&.navbar{
/*text-color; bg-color; hover-text-color; bg-hother-color; defaut-menu + 1; defaut-menu-text-color; defaut-menu-bg-color; defaut-menu-hover-text-color; defaut-menu-hover-bg-color*/
.menubar(@white, @dark-blue, @dark-blue, @white, 2, @white, @teal, @white, @dark-blue);
};
};
};
/*Cacher menu latéral*/
navbar > ul.navbar > li:first-child > a:nth-child(2){
.hide;
};
/*Barre de menus portable*/
.sidenav(@text-menu-color: @black, @bg-menu-color: @white, @text-menu-color-hover: @white, @bg-menu-color-hover: @black, @defaut-menu: 1, @defaut-menu-text-color: @black, @defaut-menu-bg-color: @red, @defaut-menu-hover-text-color: @black, @defaut-menu-hover-bg-color: @white){
.animate-left;
/*mise en page panneau*/
margin-top:0px;
list-style-type:none;
margin:0;
padding:0;
overflow:auto;
/*width:320px;*/
/*z-index:5;*/
/*Mise en page texte*/
/*Couleur de fond des menus*/
background-color:@bg-menu-color !important;
.left-align;
/*liens panneau latéral*/
li {
display:block;
/*Apparence menu actif*/
&:nth-child(@{defaut-menu}){
/*fond texte*/
background-color:@defaut-menu-bg-color;
i{.margin-right;};
a{
color:@defaut-menu-text-color;
};
display:block;
padding:8px 16px;
};
/*Apparence menus*/
&:not(:nth-child(@{defaut-menu})){
i{.margin-right;};
/*Couleur texte menu*/
a{color:@text-menu-color;};
display:block;
padding:8px 16px;
};
&:hover{
/*Apparence survol menu actif*/
&:nth-child(@{defaut-menu}){
a {color:@defaut-menu-hover-text-color;};
background:@defaut-menu-hover-bg-color;
};
/*Apparence survol menus*/
&:not(:nth-child(@{defaut-menu})){
a {color:@text-menu-color-hover;};
background-color:@bg-menu-color-hover;
};
};
};
};
navbar > ul#Sidenav{
.hide;
/*text-color; bg-color; hover-text-color; bg-hother-color; defaut-menu; defaut-menu-text-color; defaut-menu-bg-color; defaut-menu-hover-text-color; defaut-menu-hover-bg-color*/
.sidenav(@white, @dark-blue, @dark-blue, @white, 1, @white, @teal, @white, @dark-blue);
};
/********/
/* Menu */
/********/
.menubar(@text-menu-color: @black, @bg-menu-color: @white, @text-menu-color-hover: @white, @bg-menu-color-hover: @black, @defaut-menu: 2, @defaut-menu-text-color: @black, @defaut-menu-bg-color: @red, @defaut-menu-hover-text-color: @black, @defaut-menu-hover-bg-color: @white) {
/*Apparence fond de barre navigation*/
background-color: @bg-menu-color !important;
/*.dark-blue;*/
/*Alignements et mise en page*/
.left-align;
.large;
list-style-type:none;
margin:0;
padding:0;
overflow:hidden;
/*Effet de click*/
li {
/*alignement des menus*/
float:left;
display:block;
padding:8px 16px;
/*Gestion alignement menus*/
/*Alignement bouton selecteur paneau*/
&:first-child, &:last-child, &:nth-last-child(2){
.right;
};
/*couleur menus*/
&:nth-child(@{defaut-menu}) a{
/*Couleur menu sélectionné*/
color: @defaut-menu-text-color !important;
i{.margin-right(8px);};
};
&:not(:nth-child(@{defaut-menu})) a{
/*Couleur autres menus*/
color: @text-menu-color !important;
i{.margin-right(8px);};
};
&:first-child a{
/*Couleur autres menus*/
color: @text-menu-color !important;
i{.margin-right(0px);};
};
/*Gestion des menus*/
&:hover{
&:first-child a{
/*Couleur du lien au survol*/
color: @text-menu-color-hover !important;
};
&:not(:first-child) a{
/*Couleur du lien au survol*/
color: @text-menu-color-hover !important;
/*Marge symbole*/
i{.margin-right(8px);};
};
/*couleur de fond du survol*/
background-color: @bg-menu-color-hover !important;
};
/*Gestion menu actif*/
&:nth-child(@{defaut-menu}){
/*Couleur fond menu actif*/
background-color: @defaut-menu-bg-color !important;
/*Marge a droite pour les icônes sauf pour le sélecteur panneau*/
&:hover{
/*couleur texte survol*/
a{
color: @defaut-menu-hover-text-color !important;
/*Marge symbole*/
i{.margin-right(8px);};
};
/*couleur de fond survolée*/
background-color: @defaut-menu-hover-bg-color !important;
cursor:pointer;
/*opacity:0.8;*/
};
};
};
};
/*Context nenu*/
/*Pie menu*/
/***********/
/* Toolbar */
/***********/
/*Ribbon*/
/*--------------------------------------*/
/* Selection and display of collections */
/*--------------------------------------*/
/**********/
/* Button */
/**********/
/*Button*/
.button {
.user-select;
.presentation-btn;
.padding-size(@medium);
.color-btn;
.border(@teal);
.hover-border-dark-blue;
.transition-btn;
&:disabled{
cursor:not-allowed;
opacity:0.3;
box-shadow:none;
};
.disabled *{
pointer-events:none;
&:hover{box-shadow:none};
};
&:hover{
.hover-border-white;
.shadow-large;
};
};
.presentation-btn(){
display:inline-block;
/*float:left;*/
cursor:pointer;
outline:0;
overflow:hidden;
vertical-align:middle;
padding:6px 16px;
box-sizing: border-box;
border:none;
.border-radius(5px);
font-weight: bold;
text-align:center;
text-decoration:none!important;
white-space:nowrap;
};
/*Radio button*/
/*Check box*/
/*Split button*/
/*Cycle button*/
/**********/
/* Slider */
/**********/
/************/
/* List Box */
/************/
/*Liste de sélection*/
s elect {.select;};
.select {
color:@black;
min-width:300px;
.margin-bottom(@margin: 5px);
/*.margin(@margin: 5px);*/
padding:9px 0;
border:1px solid transparent;
border-bottom:1px solid @teal;
&:focus{
color:@black;
border:1px solid @yellow;
.shadow-large;
}
option[disabled]{color: @sand};
};
/***********/
/* Spinner */
/***********/
/******************/
/* Drop-down list */
/******************/
/*************/
/* Combo box */
/*************/
/**********/
/* Icon */
/**********/
/*************/
/* Tree view */
/*************/
/*************/
/* Grid view */
/*************/
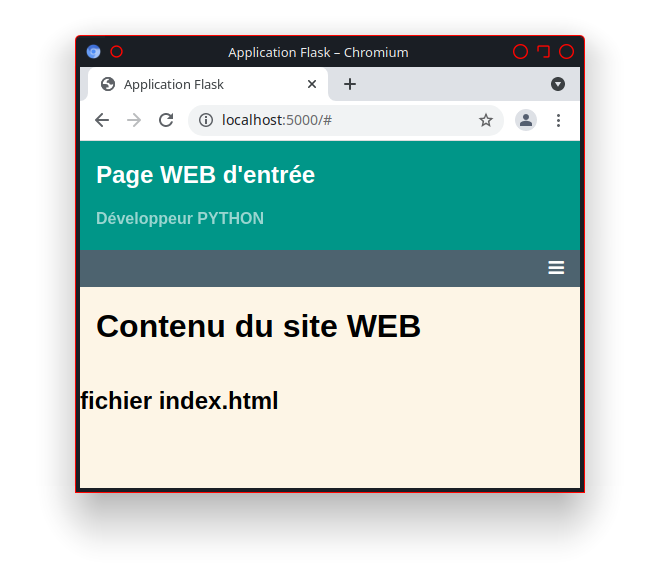
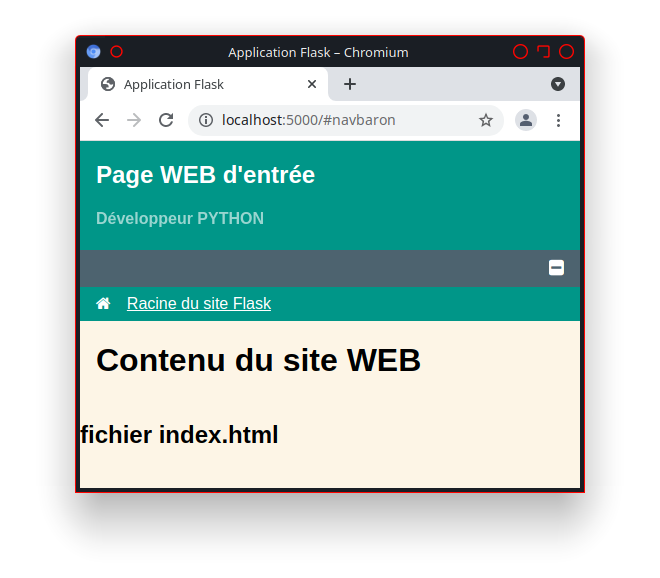
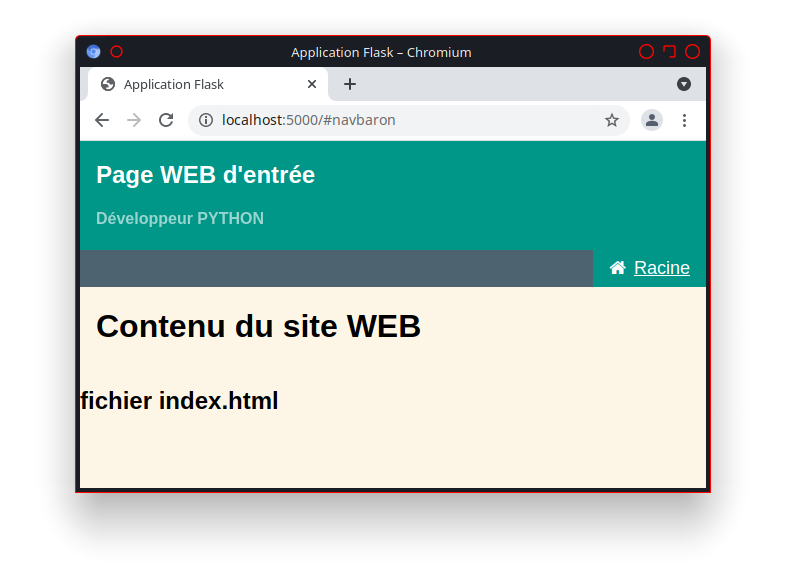
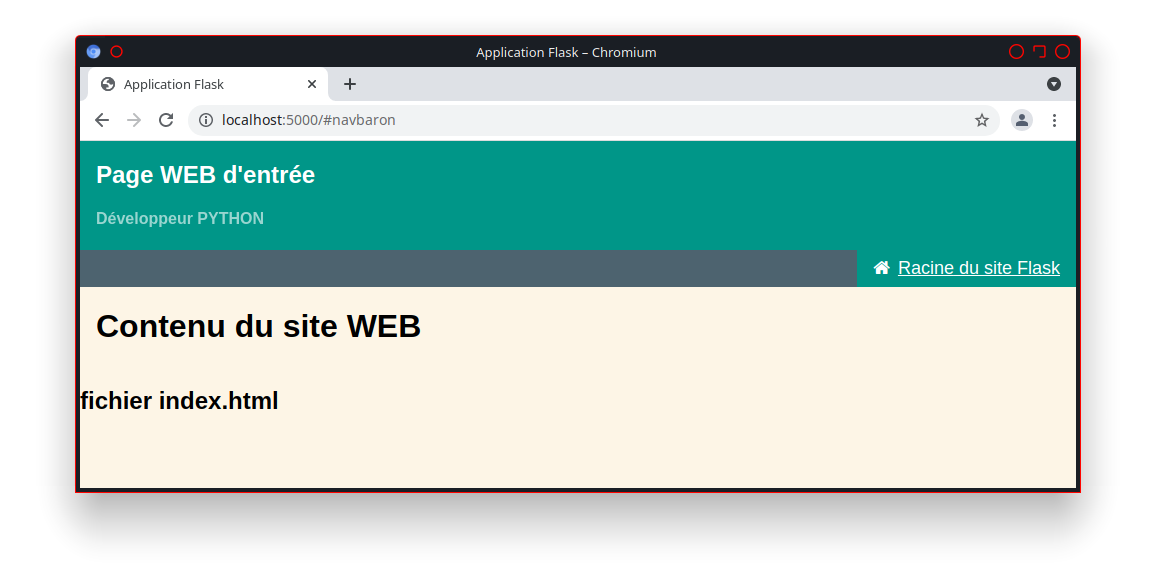
Contrôle d’accès#
Nous cherchons ici à faire une connexion utilisateur avant d’accèder au site.
Nous allons voir ce que l’on peut faire avec le module Flask-WTF de création de formulaires pour sécuriser l’accès, et rediriger vers la page d’accueil l’utilisateur suite à cette authentification.
Installation du module.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs/monprojet-flask$ sudo pip install flask-wtf
Modifier «repertoire_de_developpement/14_Serveurs/monprojet-flask/config.py» :
class Config():
SECRET_KEY = 'ma-clé-secrète'
LESS_BIN = '/usr/bin/lessc'
ASSETS_DEBUG = False
ASSETS_AUTO_BUILD = True
Modifier «repertoire_de_developpement/14_Serveurs/monprojet-flask/app/appli.py» :
import json
from app import app
from flask import request, jsonify, render_template, redirect
from app.auth import FormulaireConnexion
@app.route('/')
@app.route('/index')
def racine():
return render_template('index.html')
@app.route('/apropos/')
def apropos():
return render_template('about.html')
@app.route('/connexion', methods=['GET', 'POST'])
def connexion():
formulaire = FormulaireConnexion()
if formulaire.validate_on_submit():
if formulaire.nom_utilisateur.data == 'administrateur' and formulaire.motdepasse.data == 'motdepasse':
print('Connexion OK')
return redirect('index')
return render_template('connexion.html', formulaire=formulaire)
''''''
Créer «repertoire_de_developpement/14_Serveurs/monprojet-flask/app/auth.py» :
from flask_wtf import FlaskForm
from wtforms import StringField, PasswordField, SubmitField
from wtforms.validators import DataRequired
class FormulaireConnexion(FlaskForm):
nom_utilisateur = StringField('Nom d\'utilidateur : ', validators=[DataRequired()])
motdepasse = PasswordField('Mot de passe : ', validators=[DataRequired()])
submit = SubmitField('Connexion')
Créer «repertoire_de_developpement/14_Serveurs/monprojet-flask/app/templates/connexion.html» :
{% extends "base.html" %}
{% block meta %}<meta name="viewport" content="width=device-width, initial-scale=1">{% endblock %}
{% block styles %}<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/4.7.0/css/font-awesome.min.css" />
<link rel="stylesheet" type="text/css" href="{{ url_for('static', filename='css/styles.min.css') }}">{% endblock %}
{% block title %}Connexion Application Flask{% endblock %}
{% block header %}{% if formulaire.errors %}<p>{{ formulaire.bad_connect }}</p>{% endif %}{% if next %}{% if user.is_authenticated %}<p>{{ formulaire.bad_access }}</p>{% else %}<p>{{ formulaire.not_connected }}</p>{% endif %}{% endif %}{% endblock %}
{% block content %}<figure role="logo"></figure>
<section role="window">
<h1>S.V.P. Connectez vous</h1>
<form action="" method="post" novalidate>
{{ formulaire.csrf_token }}
<p>{{ formulaire.nom_utilisateur.label }}{{ formulaire.nom_utilisateur }}</p>
<p>{{ formulaire.motdepasse.label }}{{ formulaire.motdepasse }}</p>
<p>{{ formulaire.submit }}</p>
</form>
</section>{% endblock %}
Saisissez le lien «http://localhost:5000»
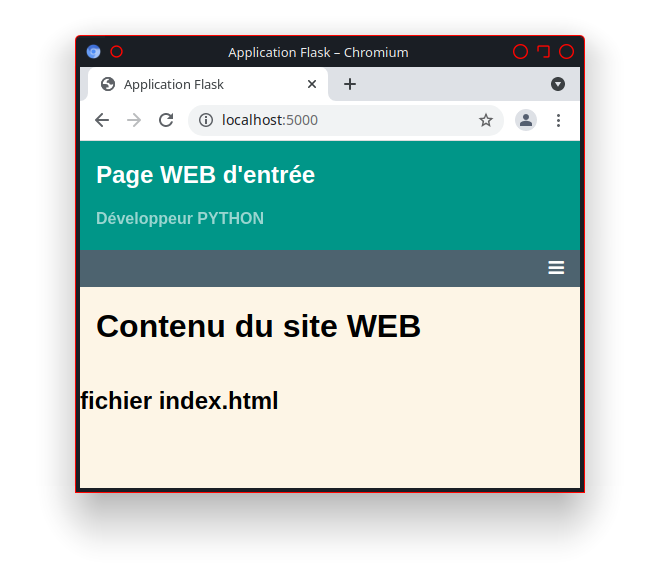
Saisissez le lien «http://localhost:5000/connexion»
Avec l’utilisateur «programmeur» et le mot de passe «motdepasse» cela ne valide pas l’identifiant.
Avec l’utilisateur «administrateur» et le mot de passe «motdepasse» ce la valide l’identifiant.
Et cela nous revoie ver la page index.
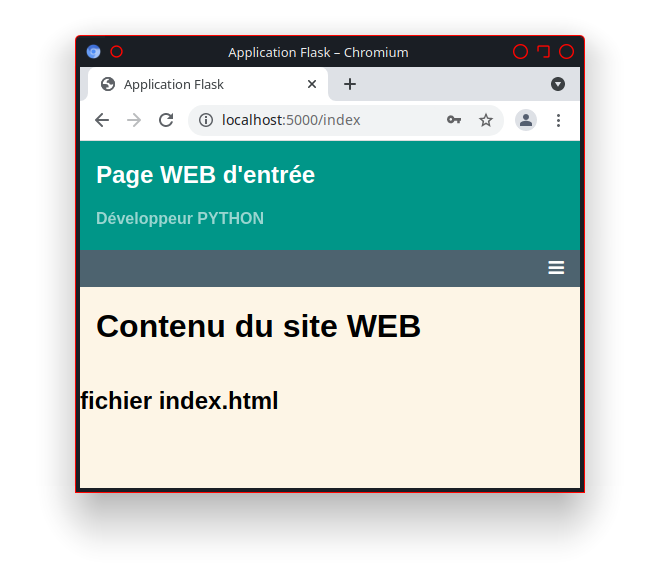
Bon tout ceci est bien joli, cela nous a permis de voir comment faire des formulaires et les protéger, comment rediriger vers un autre lien, mais cela ne protège pas les liens et cela n’est pas vraiment un système d’authentification digne de ce nom.
Avec Flask nous pouvons conditionner l’accès à un lien suivant une authentification utilisateur. Nous allons passer aux choses sérieuses avec le module Python Flask-Login.
Installation du module.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs/monprojet-flask$ sudo pip install Flask-Login
Modifier «repertoire_de_developpement/14_Serveurs/monprojet-flask/app/__init__.py» :
from flask import Flask
from config import Config
from flask_assets import Environment, Bundle
from flask_login import LoginManager
from app.auth import User, utilisateurs
app = Flask(__name__, instance_relative_config=False)
app.config.from_object(Config)
assets = Environment(app)
style_bundle = Bundle(
'css/less/main.less',
filters='less,cssmin',
output='css/styles.min.css',
extra={'rel': 'stylesheet/css'}
)
assets.register('main_styles', style_bundle)
style_bundle.build()
gestionnaire_de_connexion = LoginManager()
gestionnaire_de_connexion.init_app(app)
@gestionnaire_de_connexion.user_loader
def user_loader(identifiant):
if identifiant not in utilisateurs:
return
utilisateur = User()
utilisateur.id = identifiant
return utilisateur
@gestionnaire_de_connexion.request_loader
def request_loader(requête):
identifiant = requête.form.get('identifiant')
if identifiant not in utilisateurs:
return
utilisateur = User()
utilisateur.id = identifiant
return utilisateur
@gestionnaire_de_connexion.unauthorized_handler
def unauthorized_handler():
return 'Non autorisé'
from app import appli
Modifier «repertoire_de_developpement/14_Serveurs/monprojet-flask/app/appli.py» :
import json
from app import app
from app.auth import User, utilisateurs
from flask import request, jsonify, render_template, redirect, url_for
from flask_login import login_required, login_user, logout_user, current_user
@app.route('/')
@app.route('/index')
def racine():
if current_user.is_authenticated:
return render_template('index.html', user=current_user)
else:
return redirect(url_for('connexion'))
@app.route('/apropos/')
def apropos():
return render_template('about.html')
@app.route('/connexion', methods=['GET', 'POST'])
def connexion():
if request.method == 'GET':
return '''<form action='connexion' method='POST'>
<input type="text" name="identifiant" id="identifiant" placeholder="identifiant"/>
<input type="motdepasse" name="motdepasse" id="motdepasse" placeholder="motdepasse">
<input type="submit" name="submit">
</form>'''
identifiant = request.form['identifiant']
if identifiant in utilisateurs:
if request.form['motdepasse'] == utilisateurs[identifiant]['motdepasse']:
utilisateur = User()
utilisateur.id = identifiant
login_user((utilisateur))
return redirect(url_for('racine'))
else:
return 'Mauvais mot de passe'
else:
return 'Mauvais identifiant'
@app.route('/deconnexion')
def deconnexion():
logout_user()
return redirect(url_for('racine'))
@app.route('/utilisateur/')
@app.route('/utilisateur/<nom>')
def utilisateur(nom=''):
if nom != '':
return render_template('utilisateur.html', name=nom)
else:
return 'vous n\'avez pas saisi votre nom!'
@login_required
@app.route('/donnees', methods=['GET'])
def recherche_donnee():
print('recherche_donnee()')
nom = request.args.get('nom')
print(nom)
with open('app/donnees.txt', 'r') as fichier:
donnees = fichier.read()
if donnees:
enregistrements = json.loads(donnees)
for enregistrement in enregistrements:
if enregistrement['nom'] == nom:
return jsonify(enregistrement)
return jsonify({'erreur': 'donnée non trouvée'})
return nom
@login_required
@app.route('/donnees', methods=['PUT'])
def cree_donnee():
print('cree_donnee()')
nouveau = json.loads(request.data)
print(nouveau)
with open('app/donnees.txt', 'r') as fichier:
donnees = fichier.read()
if not donnees:
enregistrements = [nouveau]
else:
enregistrements = json.loads(donnees)
enregistrements.append(nouveau)
with open('app/donnees.txt', 'w') as fichier:
fichier.write(json.dumps(enregistrements, indent=2))
return jsonify(nouveau)
@login_required
@app.route('/donnees', methods=['POST'])
def maj_donnee():
print('maj_donnee()')
enregistrement = json.loads(request.data)
misajours = []
with open('app/donnees.txt', 'r') as fichier:
donnees = fichier.read()
enregistrements = json.loads(donnees)
for element in enregistrements:
if element['nom'] == enregistrement['nom']:
element['courriel'] = enregistrement['courriel']
misajours.append(element)
with open('app/donnees.txt', 'w') as fichier:
fichier.write(json.dumps(misajours, indent=2))
return jsonify(enregistrement)
@login_required
@app.route('/donnees', methods=['DELETE'])
def supprime_donnee():
print('supprime_donnee')
enregistrement = json.loads(request.data)
misajours = []
with open('app/donnees.txt', 'r') as fichier:
donnees = fichier.read()
enregistrements = json.loads(donnees)
for element in enregistrements:
if element['nom'] == enregistrement['nom']:
continue
misajours.append(element)
with open('app/donnees.txt', 'w') as fichier:
fichier.write(json.dumps(misajours, indent=2))
return jsonify(enregistrement)
Créer «repertoire_de_developpement/14_Serveurs/monprojet-flask/app/auth.py» :
from flask_login import UserMixin
# la base de données des utilisateurs
utilisateurs = {'administrateur': {'motdepasse': 'motdepasse'}, 'programmeur': {'motdepasse': 'motdepasse'}}
class User(UserMixin):
pass
Modifier le fichier «repertoire_de_developpement/14_Serveursmonprojet-flask/app/templates/index.html» :
{% extends "base.html" %}
{% block meta %}<meta name="viewport" content="width=device-width, initial-scale=1">{% endblock %}
{% block styles %}<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/4.7.0/css/font-awesome.min.css" />
<link rel="stylesheet" type="text/css" href="{{ url_for('static', filename='css/styles.min.css') }}">{% endblock %}
{% block title %}Application Flask{% endblock %}
{% block header %}<section class="Entete">
<h1>Page WEB d'entrée</h1>
{% if user.is_authenticated %}
<h4><a href="{{ url_for('deconnexion') }}">Déconnexion</a></h4>
<h2>{{ user.id }}</h2>
{% else %}
{% endif %}
</section>{% endblock %}
{% block navbar %}<ul class="navbar">
<li>
<a href="#navbaron"><i class="fa fa-bars"></i></a>
<a href="#"><i class="fa fa-minus-square"></i></a>
</li>
<li>
<a href="/"><i class="fa fa-home"></i>Racine<span class="hide-tablet"> du site Flask</span></a>
</li>
</ul>
<ul id="Sidenav">
<li>
<a href="/"><i class="fa fa-home"></i>Racine du site Flask</a>
</li>
</ul>{% endblock %}
{% block content %}<h1>Contenu du site WEB</h1>{% endblock %}
{% block footer %}<h2>fichier index.html</h2>{% endblock %}
Saisissez le lien «http://localhost:5000»
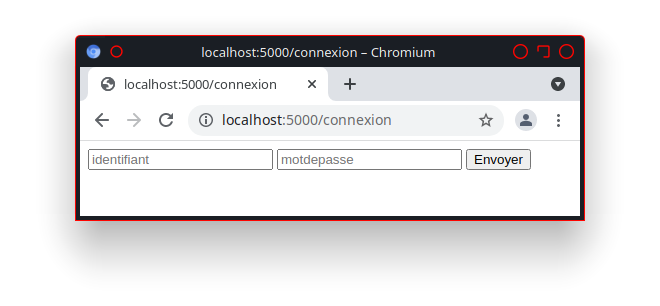
Avec l’utilisateur «bidon» et le mot de passe «motdepasse» cela ne valide pas l’identifiant.
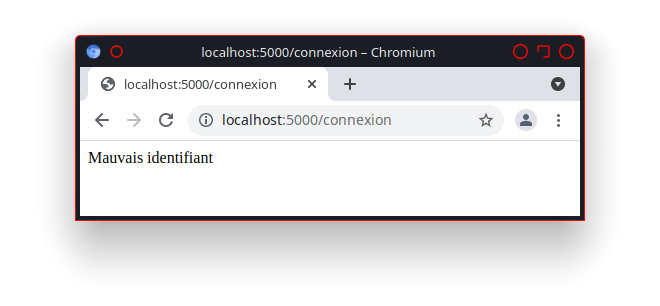
Saisissez le lien «http://localhost:5000/connexion»
Avec l’utilisateur «programmeur» et le mot de passe «motdepasse».
Cliquer sur «Déconnexion»
Avec l’utilisateur «administrateur» et le mot de passe «motdepasse».
Nous avons maintenant un système d’authentification correct.
Le programme demanderait à être retravailler avec un template de connexion formulaire, une apparence web dynamique en lesscss etc. Il manque aussi l’intégration avec un annuaire LDAP, une base de données ORM (SQLAlchemy) ou REST en XML :-).
Je vous le laisse en exercice pour chez vous…
Remi#
Après le framework Flask, qui permet un développement plus système et serveur WEB de vos applications WEB, Remi est une librairie qui permet un développement plus interface et client. C’est l’acronyme de REMote Interface.
Remi est donc une librairie Python pour le développement d’interfaces graphiques (GUI) accessible avec un navigateur WEB. Il a aussi un éditeur RAD «drag and drop».
Installer Remi#
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ sudo pip install remi
Le module Python remi permet la création d’interfaces pour votre navigateur sans utiliser du HTML. Le module traduit donc directement le code de sa syntaxe en interfaces HTML.
Regardons avec un exemple assez minimal de code REMI ce que cela donne.
Fichier «repertoire_de_developpement/14_Serveurs/remi-1.py» :
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
import remi.gui as gui
from remi import start, App
class MonAppliGUI(App):
''' Objet de création d'un exemple d'interface REMI '''
def __init__(self, *args):
''' Initialisations héritées de l'objet App avec les paramètres '''
super(MonAppliGUI, self).__init__(*args)
def main(self):
''' Création de la fenêtre principale '''
# Création des éléments de de l'espace de travail
espacetravail = gui.VBox(width=500, height=100) # Fixe la taille de l'espace de travail
self.content = gui.Label('Bonjour tout le monde !', width='80%', height='50%', style={"white-space":"pre"}) # Créé le texte à afficher dans l'espace de travail
self.button = gui.Button('OK', width=200, height=30) # Crée un bouton pour valider une action
# Configure l'action sur l'utilisation du bouton
self.button.onclick.do(self.action_du_bouton)
# Ajoute les objets de la GUI à l'espace de travail
espacetravail.append(self.content)
espacetravail.append(self.button)
return espacetravail
def action_du_bouton(self, widget):
''' Fonction de traitement de l'action du bouton '''
self.content.set_text('Click sur le bouton fait')
self.button.set_text('Salut')
if __name__ == "__main__":
# Démarrage de l'interface
start(MonAppliGUI, debug=True, address='0.0.0.0', port=0)
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ chmod u+x remi-1.py
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ ./remi-1.py
remi.server INFO Started httpserver http://127.0.0.1:36385/
remi.request INFO built UI (path=/)
127.0.0.1 - - [01/Dec/2021 10:37:56] "GET / HTTP/1.1" 200 -
127.0.0.1 - - [01/Dec/2021 10:37:56] "GET /res:style.css HTTP/1.1" 200 -
remi.server.ws INFO connection established: ('127.0.0.1', 59944)
remi.server.ws INFO handshake complete
127.0.0.1 - - [01/Dec/2021 10:37:56] "GET /res:font.woff2 HTTP/1.1" 200 -
Paramètres de lancement#
Normalement si tout est correct à l’exécution du script, l’interface GUI est automatiquement lancée avec votre navigateur. Si cela n’est pas le cas, il faudra ouvrir un navigateur sur l’adresse indiquée au lacement du script remi.server INFO Started httpserver http://127.0.0.1:36385/, donc ici http://127.0.0.1:36385/
Nous pouvons aussi fixer ce lien, ou d’autres paramètres de lancement, en précisant les paramètres start(MonAppliGUI, address='127.0.0.1', port=5000, multiple_instance=False, enable_file_cache=True, update_interval=0.1, start_browser=True).
address : Fixe l’adresse IP de lancement du serveur d’interface GUI.
port : Fixe le port réseau d’écoute.
multiple_instance : Si ce paramètre est vrai, cela permet la connection de clients mutiples dans des processus séparés (multiutilisateurs).
enable_file_cache : Ajoute une gestion du cache pour les clients.
update_interval : Vitesse de rafraîchissement de l’interface.
start_browser : Ouverture automatique du navigateur web au démarrage.
standalone : Exécute l’application comme une application Bureautique. Si faux, l’interface s’affiche dans votre navigateur en cour d’exécution.
Fichier «repertoire_de_developpement/14_Serveurs/remi-2.py» :
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
import remi.gui as gui
from remi import start, App
class MonAppliGUI(App):
''' Objet de création d'un exemple d'interface REMI '''
def __init__(self, *args):
''' Initialisations héritées de l'objet App avec les paramètres '''
super(MonAppliGUI, self).__init__(*args)
def main(self):
''' Création de la fenêtre principale '''
# Création des éléments de de l'espace de travail
content = gui.Label('Bonjour tout le monde !', width='80%', height='50%', style={"white-space":"pre"}) # Créé le texte à afficher dans l'espace de travail
return content
if __name__ == "__main__":
# Démarrage de l'interface
start(MonAppliGUI, debug=True, address='127.0.0.1', port=5000, multiple_instance=False, enable_file_cache=True, update_interval=0.1, start_browser=True)
Fonctionnement standalone#
Nous pouvons faire fonctionner l’application hors navigateur, c’est ce que l’on appelle le standalone. Pous cela nous avons besoin d’installer le module python pywebview.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ sudo pip install pywebview
Fichier «repertoire_de_developpement/14_Serveurs/remi-3.py» :
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
import remi.gui as gui
from remi import start, App
class MonAppliGUI(App):
''' Objet de création d'un exemple d'interface REMI '''
def __init__(self, *args):
''' Initialisations héritées de l'objet App avec les paramètres '''
super(MonAppliGUI, self).__init__(*args)
def main(self):
''' Création de la fenêtre principale '''
# Création des éléments de de l'espace de travail
content = gui.Label('Bonjour tout le monde !', width='80%', height='50%', style={"white-space":"pre"}) # Créé le texte à afficher dans l'espace de travail
return content
if __name__ == "__main__":
# Démarrage de l'interface
start(MonAppliGUI, standalone=True)
Gestion des événements#
Nous allons voir maintenant comment gérer les évènements de l’interface. Nous avons déjà vu la méthode .onclick.do() pour affecter une action à un événement. Nous allons voir comment passer des paramètres en fonction de l’événement.
Fichier «repertoire_de_developpement/14_Serveurs/remi-4.py» :
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
import remi.gui as gui
from remi import start, App
class MonAppliGUI(App):
''' Objet de création d'un exemple d'interface REMI '''
def __init__(self, *args):
''' Initialisations héritées de l'objet App avec les paramètres '''
super(MonAppliGUI, self).__init__(*args)
def main(self):
''' Création de la fenêtre principale '''
# Création des éléments de de l'espace de travail
espacetravail = gui.VBox(width=500, height=100) # Fixe la taille de l'espace de travail
self.content = gui.Label('Bonjour tout le monde !', width='80%', height='50%', style={"white-space":"pre"}) # Créé le texte à afficher dans l'espace de travail
self.button_ok = gui.Button('OK', width=200, height=30) # Crée un bouton pour valider une action
self.button_choix = gui.Button('Choix', width=200, height=30) # Crée un bouton pour valider une action
# Configure l'action sur l'utilisation du bouton
self.button_ok.onclick.do(self.action_du_bouton, 'OK')
self.button_choix.onclick.do(self.action_du_bouton, 'Choix', 'Vous avec cliquez sur le bouton «Choix»')
# Ajoute les objets de la GUI à l'espace de travail
espacetravail.append(self.content)
espacetravail.append(self.button_choix)
espacetravail.append(self.button_ok)
return espacetravail
def action_du_bouton(self, widget, type='', message=''):
''' Fonction de traitement de l'action du bouton '''
if type == 'Choix':
self.content.set_text(message)
if type == 'OK':
self.content.set_text('Cliquer sur le bouton «Choix»')
if __name__ == "__main__":
# Démarrage de l'interface
start(MonAppliGUI, address='127.0.0.1', port=5000)
Gestion de l’authentification#
REMI permet une simple authentification pour accéder à l’interface. Voici comment procéder.
Fichier «repertoire_de_developpement/14_Serveurs/remi-5.py» :
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
import remi.gui as gui
from remi import start, App
class MonAppliGUI(App):
''' Objet de création d'un exemple d'interface REMI '''
def __init__(self, *args):
''' Initialisations héritées de l'objet App avec les paramètres '''
super(MonAppliGUI, self).__init__(*args)
def main(self):
''' Création de la fenêtre principale '''
# Création des éléments de de l'espace de travail
content = gui.Label('Bonjour tout le monde !', width='80%', height='50%', style={"white-space":"pre"}) # Créé le texte à afficher dans l'espace de travail
return content
if __name__ == "__main__":
# Démarrage de l'interface
start(MonAppliGUI, address='127.0.0.1', port=5000, username='administrateur', password='motdepasse')
HTML avec REMI#
Vous pouvez fixer avec REMI des paramètres des balises HTML. Vous avez par exemple widget.attributes['title'] = 'Votre titre', widget.style['color'] = 'blue'. Il vous faudra connaître les attribus HTML bien sur. Les attributs de classe class sont utilisés par REMI pour identifier les types de widgets, et l’identifiant id est utilisé par REMI pour stocker l’instance du widget.
Tout ceci va nous permettre de créer éventuellement des feuilles de styles pour les plus experts en css.
class MonAppliGUI(App):
def __init__(self, *args):
css_path = os.path.join(os.path.dirname(__file__), 'css')
super(MonAppliGUI, self).__init__(*args, static_file_path={'res': css_path})
Le fichier «style.css» sera alors le fichier utilisé pour votre configuration css.
REMI n’est pas sexy pour configurer l’apparence de votre client, mais ce qui fait sa puissance c’est son outil de RAD que nous allons voir.
Éditeur WYSIWYG pour REMI#
Et oui, REMI nous donne la possibilité de construire ses interfaces clients avec un outil de RAD. Installons cet outil.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ mkdir remiediteur ; cd remiediteur
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs/remiediteur$ git clone https://github.com/dddomodossola/remi.git
Clonage dans 'remi'...
remote: Enumerating objects: 6420, done.
remote: Counting objects: 100% (78/78), done.
remote: Compressing objects: 100% (62/62), done.
remote: Total 6420 (delta 36), reused 44 (delta 16), pack-reused 6342
Réception d'objets: 100% (6420/6420), 4.19 Mio | 1.79 Mio/s, fait.
Résolution des deltas: 100% (4405/4405), fait.
À partir de là modifions l’application «repertoire_de_developpement/14_Serveurs/remiediteur/remi/editor/» pour changer le port et éviter tout risque de conflits.
''''''
if __name__ == "__main__":
start(Editor, debug=False, address='0.0.0.0', port=5000,
update_interval=0.05, multiple_instance=True)
Démarrons l’application.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs/remiediteur$ python3 remi/editor/editor.py
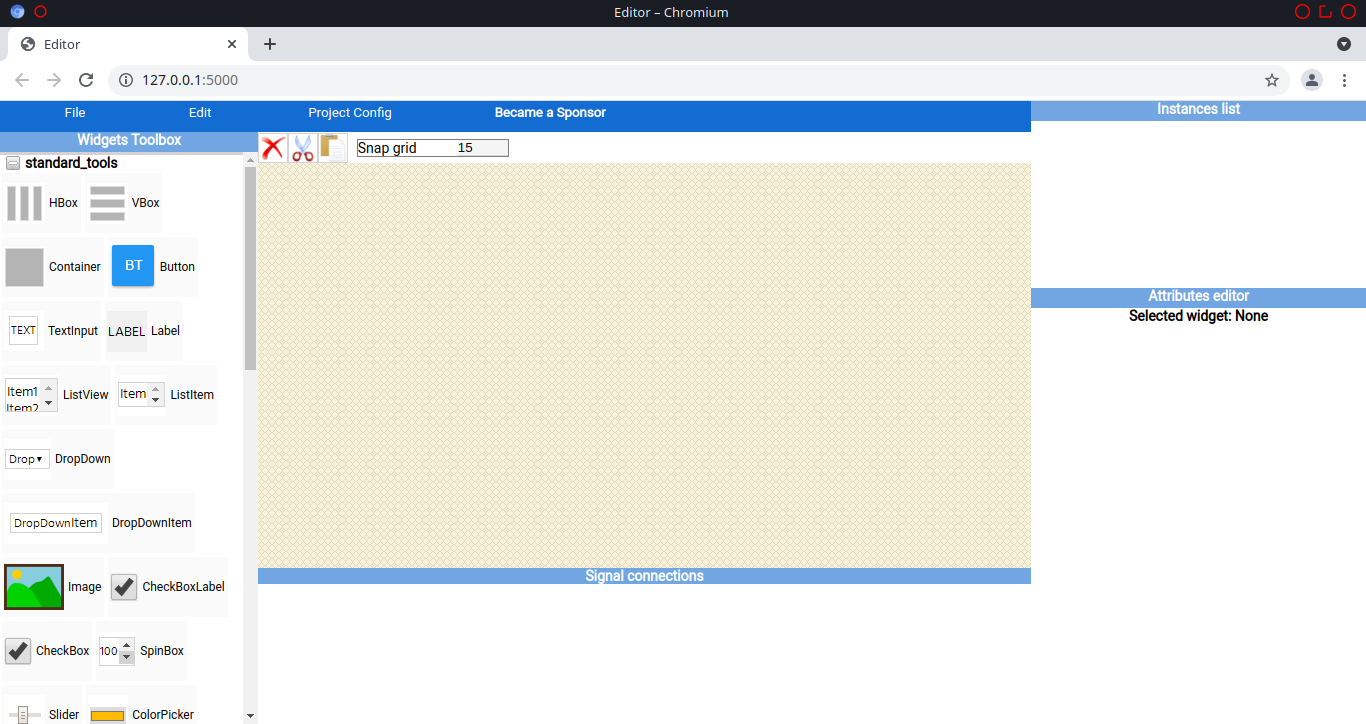
Configurons notre projet avec le menu «Project Config» :

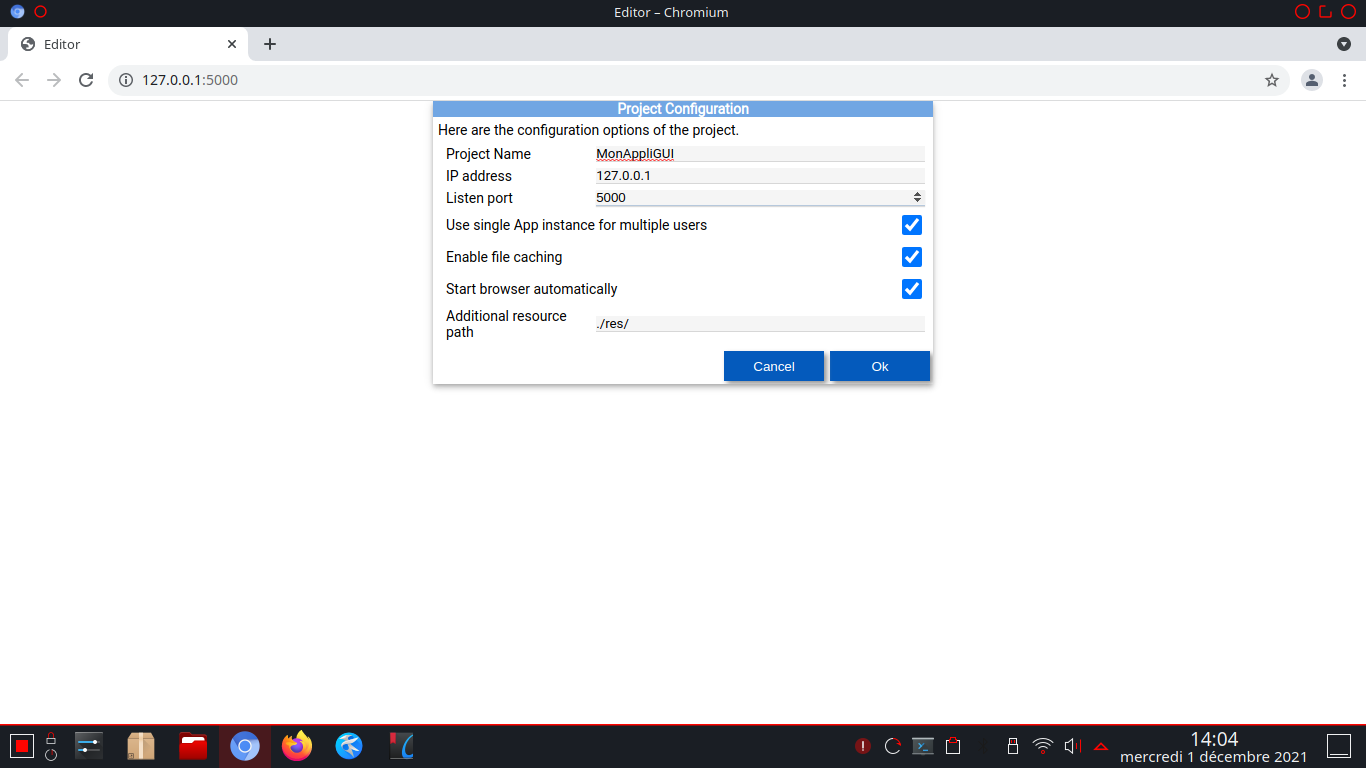
Nous allons maintenant créer un fenêtre avec un label Bonjour tout le monde !, pour vous montrer comment l’utiliser.
Pour commencer il faut sélectionner dans «Widgets Toolbox» le composant «Container».
L’espace d’édition des propriétés de votre wiget est alors :
Modifier «variable_name» en «espacedetravail».
Ajouter un widget «LABEL»
Double cliquer sur le widget pour l’éditer.
Modifier ses propriétés.
Ajoutons un bouton de la même façon.
Ajoutons lui maintenant une action «onclick» en sélectionnant «App» et «onclick_button_ok».
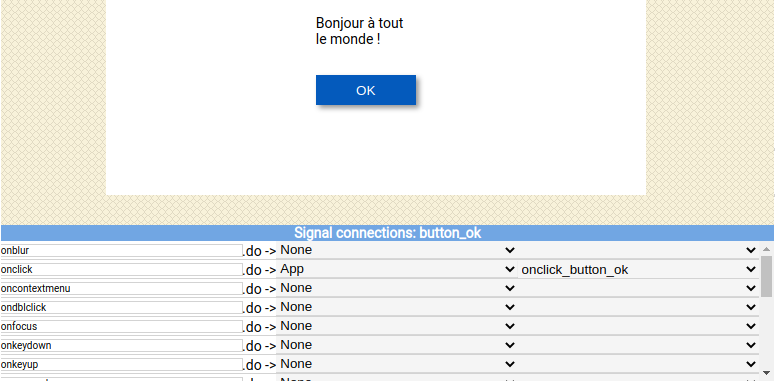
Maintenant nous avons fini notre interface.
Sauvons le projet.
Visualisons le contenu du code de «repertoire_de_developpement/14_Serveurs/remiediteur/monprojetremi.py».
# -*- coding: utf-8 -*-
from remi.gui import *
from remi import start, App
class MonAppliGUI(App):
def __init__(self, *args, **kwargs):
#DON'T MAKE CHANGES HERE, THIS METHOD GETS OVERWRITTEN WHEN SAVING IN THE EDITOR
if not 'editing_mode' in kwargs.keys():
super(MonAppliGUI, self).__init__(*args, static_file_path={'my_res':'./res/'})
def idle(self):
#idle function called every update cycle
pass
def main(self):
return MonAppliGUI.construct_ui(self)
@staticmethod
def construct_ui(self):
#DON'T MAKE CHANGES HERE, THIS METHOD GETS OVERWRITTEN WHEN SAVING IN THE EDITOR
espacedetravail = Container()
espacedetravail.attr_class = "Container"
espacedetravail.attr_editor_newclass = False
espacedetravail.css_height = "330.0px"
espacedetravail.css_left = "105.0px"
espacedetravail.css_position = "absolute"
espacedetravail.css_top = "45.0px"
espacedetravail.css_width = "540.0px"
espacedetravail.variable_name = "espacedetravail"
content = Label()
content.attr_class = "Label"
content.attr_editor_newclass = False
content.css_height = "30px"
content.css_left = "210.0px"
content.css_position = "absolute"
content.css_top = "150.0px"
content.css_width = "100px"
content.text = "Bonjour à tout le monde !"
content.variable_name = "content"
espacedetravail.append(content,'content')
button_ok = Button()
button_ok.attr_class = "Button"
button_ok.attr_editor_newclass = False
button_ok.css_height = "30px"
button_ok.css_left = "210.0px"
button_ok.css_position = "absolute"
button_ok.css_top = "210.0px"
button_ok.css_width = "100px"
button_ok.text = "OK"
button_ok.variable_name = "button_ok"
espacedetravail.append(button_ok,'button_ok')
espacedetravail.children['button_ok'].onclick.do(self.onclick_button_ok)
self.espacedetravail = espacedetravail
return self.espacedetravail
def onclick_button_ok(self, emitter):
pass
#Configuration
configuration = {'config_project_name': 'MonAppliGUI', 'config_address': '127.0.0.1', 'config_port': 5000, 'config_multiple_instance': True, 'config_enable_file_cache': True, 'config_start_browser': True, 'config_resourcepath': './res/'}
if __name__ == "__main__":
# start(MyApp,address='127.0.0.1', port=8081, multiple_instance=False,enable_file_cache=True, update_interval=0.1, start_browser=True)
start(MonAppliGUI, address=configuration['config_address'], port=configuration['config_port'],
multiple_instance=configuration['config_multiple_instance'],
enable_file_cache=configuration['config_enable_file_cache'],
start_browser=configuration['config_start_browser'])
Il nous suffit alors de modifier la fonction «onclick_button_ok».
def onclick_button_ok(self, emitter):
self.espacedetravail.children['content'].set_text('Click sur OK')
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs/remiediteur$ python3 monprojetremi.py
Django#
Jusqu’à maintenant nous avons utilisé le framework Flask pour fabriquer des serveurs WEBs d’infrastructures systèmes et pour générer un petit site WEB. Puis nous avons utilisé REMI pour générer des GUI WEB avec Python. GUI WEB pouvant servir d’interface utilisateur pour des administrateurs systèmes.
Maintenant nous passons à Django un framework Python Serveur WEB plus intégré site WEB applicatif, ORM et gros projets.
Installation#
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ sudo pip install Django
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ python3 -m django --version
3.2.9
Création d’un projet#
Django permet la création d’un projet avec la commande django-admin startproject «nom du projet».
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ django-admin startproject monsitedjango
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ tree monsitedjango
monsitedjango
├── manage.py
└── monsitedjango
├── __init__.py
├── settings.py
├── urls.py
├── asgi.py
└── wsgi.py
1 directory, 6 files
Le répertoire «monsitedjango» contient votre projet Django.
«manage.py» : Ce fichier est un utilitaire de gestion du site Django.
Le sous-répertoire «monsitedjango» : Paquet Python du site monsitedjango.
«__init__.py» : Les informations du paquet Python monsitedjango.
«setting.py» : Configuration de votre projet Django monsitedjango.
«urls.py» : Vos chemins d’accès WEB de votre projet.
«asgi.py» et «wsgi» : fichiers pour configurer les technologies WEB aSGI (Asynchronous Server Gateway Interface, technologie asynchrone de serveurs WEB genre Daphne, Hypercorn, Uvicorn, etc.), et WSGI (Web Server Gateway Interface, est un standard Python décrit dans la PEP 3333 sur des serveurs WEB genre Gunicorn, uWSGI, mod_wsgi d’apache) pour des déploiements sur des infrastructures de productions industrielles. Tout ceci ne sera pas abordé dans ce cour.
Modules applicatifs#
Avec Django il est préférable de développer son application sous forme de modules d’applications. Ceci permet de rendre son développement modulaire, d’avoir une meilleure maintenabilité du site, et une réutilisation du code applicatif pour d’autres projets.
Pour gérer le site Django nous utiliserons la commande manage.py.
Sous Ubuntu il faut préciser la version de Python dans manage.py pour que cela fonctionne. Corrigeons cela en modifiant le fichier «repertoire_de_developpement/14_Serveurs/monsitedjango/manage.py».
#!/usr/bin/env python3
Maintenant avec la commande manage.py startapp «mon application» nous pouvons créer des modules applicatifs Django.
Nous voulons pour notre projet monsitedjango une gestion de connexions utilisateurs sous forme de module. Nous devons donc créer une application de connexion pour notre projet.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs$ cd monsitedjango
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs/monsitedjango$ ./manage.py startapp connexion
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs/monsitedjango$ tree
.
├── connexion
│ ├── admin.py
│ ├── apps.py
│ ├── __init__.py
│ ├── migrations
│ │ └── __init__.py
│ ├── models.py
│ ├── tests.py
│ └── views.py
├── manage.py
└── monsitedjango
├── asgi.py
├── __init__.py
├── __pycache__
│ ├── __init__.cpython-39.pyc
│ ├── settings.cpython-39.pyc
├── settings.py
├── urls.py
└── wsgi.py
4 directories, 15 files
Nous allons maintenant intégrer ce module applicatif dans notre projet. Pour cela il nous faut modifier INSTALLED_APPS = ['«module applicatif Django»',] du fichier «settings.py» du répertoire «repertoire_de_developpement/14_Serveurs/monsitedjango/monsitedjango» :
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'connexion',
]
Une fois le module connexion développé, on pourra l’intègrer dans d’autres projets en copiant le dossier dans le répertoire projet. On activera ce module en modifiant «settings.py» du projet.
Lancer le serveur#
Pour démarrer le serveur Django utiliser la commande manage.py runserver, et pour l’arrêter tapez Ctrl+C.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs/monsitedjango$ ./manage.py runserver
Watching for file changes with StatReloader
Performing system checks...
System check identified no issues (0 silenced).
You have 18 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions.
Run 'python manage.py migrate' to apply them.
December 02, 2021 - 08:50:33
Django version 3.2.9, using settings 'monsitedjango.settings'
Starting development server at http://127.0.0.1:8000/
Quit the server with CONTROL-C.
^C
Nous remarquons que nous avons l’erreur You have 18 unapplied migration(s). lors de l’exécution de notre serveur Django. Corrigeons cela comme suit :
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs/monsitedjango$ ./manage.py makemigrations
No changes detected
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs/monsitedjango$ ./manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, sessions
Running migrations:
Applying contenttypes.0001_initial... OK
Applying auth.0001_initial... OK
Applying admin.0001_initial... OK
Applying admin.0002_logentry_remove_auto_add... OK
Applying admin.0003_logentry_add_action_flag_choices... OK
Applying contenttypes.0002_remove_content_type_name... OK
Applying auth.0002_alter_permission_name_max_length... OK
Applying auth.0003_alter_user_email_max_length... OK
Applying auth.0004_alter_user_username_opts... OK
Applying auth.0005_alter_user_last_login_null... OK
Applying auth.0006_require_contenttypes_0002... OK
Applying auth.0007_alter_validators_add_error_messages... OK
Applying auth.0008_alter_user_username_max_length... OK
Applying auth.0009_alter_user_last_name_max_length... OK
Applying auth.0010_alter_group_name_max_length... OK
Applying auth.0011_update_proxy_permissions... OK
Applying auth.0012_alter_user_first_name_max_length... OK
Applying sessions.0001_initial... OK
Nous reviendrons plus tard sur ces commandes Django manage.py makemigrations et manage.py migrate.
Nous pouvons maintenant démarrer normalement Django.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs/monsitedjango$ ./manage.py runserver
Watching for file changes with StatReloader
Performing system checks...
System check identified no issues (0 silenced).
December 02, 2021 - 08:54:22
Django version 3.2.9, using settings 'monsitedjango.settings'
Starting development server at http://127.0.0.1:8000/
Quit the server with CONTROL-C.
Le serveur démarre sur http://127.0.0.1:8000.
Vous pouvez préciser avec la commande manage.py sur quel port, ou même quelle adresse démarrer votre serveur Django.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs/monsitedjango$ ./manage.py runserver 5000
…
Starting development server at http://127.0.0.1:5000/
…
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs/monsitedjango$ ./manage.py runserver 10.10.10.1:5000
…
Starting development server at http://10.10.10.1:5000/
…
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs/monsitedjango$ ./manage.py runserver 0:5000
…
Starting development server at http://0:5000/
…
0 est un raccourci vers 0.0.0.0
On peut aussi préciser cela dans le fichier «settings.py» du répertoire «repertoire_de_developpement/14_Serveurs/monsitedjango/monsitedjango» en ajoutant l’import from django.core.management.commands.runserver import Command as runserver, et les variables runserver.default_addr = '«ip»', runserver.default_port = '«port»'. Pour que le serveur Django accède à l’addresse ip il faut aussi l’autoriser avec ALLOWED_HOSTS = ['«ip»'].
from django.core.management.commands.runserver import Command as runserver
''''''
ALLOWED_HOSTS = ['10.10.10.1']
runserver.default_port = '5000'
runserver.default_addr = '10.10.10.1'
''''''
Profitons aussi de l’édition du fichier «settings.py» pour passer le site en Français.
LANGUAGE_CODE = 'fr-fr'
Ce qui nous donne à l’exécution.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs/monsitedjango$ ./manage.py runserver
…
Starting development server at http://10.10.10.1:5000/
…
Les vues#
Django est développé suivant l’architecture MVC (Modèle Vues Contrôleurs). Dans cette section, nous allons voir comment élaborer une vue et gérer son articulation dans le site avec un contrôleur.
Écrivons d’abord la première vue de l’application Django connexion en modifiant le fichier des vues «views.py» dans «repertoire_de_developpement/14_Serveurs/monsitedjango/connexion».
from django.shortcuts import render
from django.http import HttpResponse
def racine(request):
return HttpResponse('Bonjour tout le monde!')
Les contrôleurs sont, pour les vues, les fichiers «urls.py» que nous allons modifier.
Les vues seront prises en compte dans ce fichier avec la commande path(route='«chemin»', view=«vue», kwarg, name='«nom django»').
«route» : indique l’URL de la vue.
«view» : l’objet vue.
«kwarg» : Des paramètres à passer à la vue.
«name» : le nom Django du lien pour être utilisé lors de renvois URL dans le code.
Créons le fichier «urls.py», contrôleur du module applicatif connexion, dans le répertoire «repertoire_de_developpement/14_Serveurs/monsitedjango/connexion» de l’application connexion. Ce fichier va prendre en compte la vue d’affichage lors d’une connexion.
Éditons ce fichier comme suit :
from django.urls import path
from . import views
urlpatterns = [
path('connexion/', views.racine, name='connexion'),
]
Modifions le fichier contrôleur «urls.py» du répertoire «repertoire_de_developpement/14_Serveurs/monsitedjango» pour qu’il prenne en compte la vue du module apllicatif connexion.
On peut déjà remarqué qu’il n’est pas vide, et qu’il contient un lien vers «/admin».
from django.contrib import admin
from django.urls import path
urlpatterns = [
path('admin/', admin.site.urls),
]
Nous pouvons alors ajouter un renvoi vers le module applicatif connexion avec l’objet include('mon_module_applicatif_django.urls') du module Python django.urls.
Ajoutons l’URL de l’application connexion à notre projet dans le fichier.
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('', include('connexion.urls')),
path('admin/', admin.site.urls),
]
On peut remarquer que la racine du site n’est plus accéssible.
Modèles#
Ici nous abordons le traitement des données de l’application Django. Généralement celles-ci se font sous forme de Base de données.
Regardons comment est configuré notre projet Django au niveau de la base de données en consultant le fichier «settings.py».
# Database
# https://docs.djangoproject.com/en/3.2/ref/settings/#databases
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': BASE_DIR / 'db.sqlite3',
}
}
Donc par défaut Django utilise une base de données SQLite3, et nous avons vu comment l’utiliser avec Python dans la section SQLite3.
Nous pouvons remarquer qu’après l’exécution du projet Django, un fichier «db.sqlite3» a été créé à la racine du projet.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs/monsitedjango$ tree --dirsfirst -L 1
.
├── connexion
├── monsitedjango
├── db.sqlite3
└── manage.py
2 directories, 2 files
C’est le modèle de données de gestion du site Django.
Utiliser le modèle Django#
Regardons le contenu de cette base de données Django SQLite3 avec la commande SQL SELECT name FROM sqlite_master WHERE type='table';.
>>> import sqlite3
>>> mabasedjango = sqlite3.connect('db.sqlite3')
>>> with mabasedjango:
... curseurbd = mabasedjango.cursor()
... curseurbd.execute("SELECT name FROM sqlite_master WHERE type='table';")
... print(curseurbd.fetchall())
... curseurbd.close()
...
<sqlite3.Cursor object at 0x7f57b1b720a0>
[('django_migrations',), ('sqlite_sequence',), ('auth_group_permissions',), ('auth_user_groups',), ('auth_user_user_permissions',), ('django_admin_log',), ('django_content_type',), ('auth_permission',), ('auth_group',), ('auth_user',), ('django_session',)]
>>> with mabasedjango:
... curseurbd = mabasedjango.cursor()
... curseurbd.execute("SELECT * FROM auth_user;")
... list(map(lambda x: x[0], curseurbd.description))
... print(curseurbd.fetchall())
... curseurbd.close()
...
<sqlite3.Cursor object at 0x7f57b1a78f10>
['id', 'password', 'last_login', 'is_superuser', 'username', 'last_name', 'email', 'is_staff', 'is_active', 'date_joined', 'first_name']
[]
>>> with mabasedjango:
... curseurbd = mabasedjango.cursor()
... curseurbd.execute("SELECT * FROM auth_group;")
... list(map(lambda x: x[0], curseurbd.description))
... print(curseurbd.fetchall())
... curseurbd.close()
...
<sqlite3.Cursor object at 0x7f57b1b720a0>
['id', 'name']
[]
>>> with mabasedjango:
... curseurbd = mabasedjango.cursor()
... curseurbd.execute("SELECT * FROM auth_user_groups;")
... list(map(lambda x: x[0], curseurbd.description))
... print(curseurbd.fetchall())
... curseurbd.close()
...
<sqlite3.Cursor object at 0x7f57b1a78f10>
['id', 'user_id', 'group_id']
[]
>>> with mabasedjango:
... curseurbd = mabasedjango.cursor()
... curseurbd.execute("SELECT * FROM auth_permission;")
... list(map(lambda x: x[0], curseurbd.description))
... print(curseurbd.fetchall())
... curseurbd.close()
...
<sqlite3.Cursor object at 0x7f57b1b72180>
['id', 'content_type_id', 'codename', 'name']
[(1, 1, 'add_logentry', 'Can add log entry'), (2, 1, 'change_logentry', 'Can change log entry'), (3, 1, 'delete_logentry', 'Can delete log entry'), (4, 1, 'view_logentry', 'Can view log entry'), (5, 2, 'add_permission', 'Can add permission'), (6, 2, 'change_permission', 'Can change permission'), (7, 2, 'delete_permission', 'Can delete permission'), (8, 2, 'view_permission', 'Can view permission'), (9, 3, 'add_group', 'Can add group'), (10, 3, 'change_group', 'Can change group'), (11, 3, 'delete_group', 'Can delete group'), (12, 3, 'view_group', 'Can view group'), (13, 4, 'add_user', 'Can add user'), (14, 4, 'change_user', 'Can change user'), (15, 4, 'delete_user', 'Can delete user'), (16, 4, 'view_user', 'Can view user'), (17, 5, 'add_contenttype', 'Can add content type'), (18, 5, 'change_contenttype', 'Can change content type'), (19, 5, 'delete_contenttype', 'Can delete content type'), (20, 5, 'view_contenttype', 'Can view content type'), (21, 6, 'add_session', 'Can add session'), (22, 6, 'change_session', 'Can change session'), (23, 6, 'delete_session', 'Can delete session'), (24, 6, 'view_session', 'Can view session')]
>>> with mabasedjango:
... curseurbd = mabasedjango.cursor()
... curseurbd.execute("SELECT * FROM auth_user_user_permissions;")
... list(map(lambda x: x[0], curseurbd.description))
... print(curseurbd.fetchall())
... curseurbd.close()
...
<sqlite3.Cursor object at 0x7f57b1b720a0>
['id', 'user_id', 'permission_id']
[]
Nous n’avons pas d’utilisateurs dans la base de données, ni même de groupe de gestion des autorisations. Django a un système de gestion simple des permissions. Ce système permet l’attribution de permissions ou de groupes ouvrant à des autorisations pour un utilisateur.
Ce système est utilisé par la partie administration du site de Django, et vous pouvez l’utiliser dans votre code pour gérer l’accès de vos utilisateurs.
Il existe des sortes de templates d’autorisations que l’on peut ajouter dans Django avec le fichier «settings.py». Par exemple django.contrib.auth, déjà présent dans la configuration, qui ajoute les droits d’ajout, de suppression et de visualisation ; ou aussi django.contrib.auth.models.Group qui permet d’attribuer des permissions au travers de groupes.
INSTALLED_APPS = [
'django.contrib.auth',
'django.contrib.contenttypes', # Gère les utilisateurs
''''''
]
Pour la gestion des connexions pour le site, nous avons aussi besoins des briques Django pour gérer les authentifications. C’est ce que l’on appelle un «middleware». Il nous faut donc django.contrib.sessions.middleware.SessionMiddleware et django.contrib.auth.middleware.AuthenticationMiddleware pour avoir les outils Django de gestion des connexions. Ils sont normalement présent par défaut dans le fichier «settings.py».
MIDDLEWARE = [
'django.contrib.sessions.middleware.SessionMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
''''''
]
Nous allons maintenant créer un administrateur du site et voir le résultat dans le modèle de la base de données.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs/monsitedjango$ ./manage.py createsuperuser --username=programmeur --email=programmeur.python@fai.fr
Password:
Password (again):
Ce mot de passe est trop courant.
Bypass password validation and create user anyway? [y/N]: y
Superuser created successfully.
Regardons ce qu’il s’est passé sur la base de données Django.
>>> with mabasedjango:
... curseurbd = mabasedjango.cursor()
... curseurbd.execute("SELECT * FROM auth_user;")
... list(map(lambda x: x[0], curseurbd.description))
... print(curseurbd.fetchall())
... curseurbd.close()
...
<sqlite3.Cursor object at 0x7f57b1b72180>
['id', 'password', 'last_login', 'is_superuser', 'username', 'last_name', 'email', 'is_staff', 'is_active', 'date_joined', 'first_name']
[(2, 'pbkdf2_sha256$260000$Tqv2p77phrnn0eaEcEbPAK$Tijor0UG6MTkOkKPTjQScflflncw13iizO1SorHKaU0=', None, 1, 'programmeur', '', 'programmeur.python@fai.fr', 1, 1, '2021-12-03 12:39:26.109575', '')]
>>> with mabasedjango:
... curseurbd = mabasedjango.cursor()
... curseurbd.execute("SELECT * FROM auth_user_user_permissions;")
... list(map(lambda x: x[0], curseurbd.description))
... print(curseurbd.fetchall())
... curseurbd.close()
...
<sqlite3.Cursor object at 0x7f57b1a78f10>
['id', 'user_id', 'permission_id']
[]
Créons l’interface de connexion avec Djando. Commençons par créer le fichier de formulaire de connection «formulaire.py» dans «repertoire_de_developpement/14_Serveurs/monsitedjango/connexion».
from django import forms
class FormulaireDeConnexion(forms.Form):
utilisateur = forms.CharField(label='Utilisateur : ', max_length=30)
motdepasse = forms.CharField(label='Mot de passe : ', widget=forms.PasswordInput)
Créer le répertoire «repertoire_de_developpement/14_Serveurs/monsitedjango/connexion/templates». Editer dedans le fichier «connexion.html»
<h1>Se connecter</h1>
{% if mauvaisutilisateur %}<p><strong>L'utilisateur n'est pas reconnu</strong></p>{% endif %}
{% if mauvaismotdepasse %}<p><strong>Vérifiez votre mot de passe</strong></p>{% endif %}
{% if utilisateur.is_authenticated %}{{ utilisateur.username }} vous êtes connecté :-){% else %}
<form method="post" action=".">
{% csrf_token %}
{{ formulaire.as_p }}
<input type="submit"/>
</form>
{% endif %}
Puis modifions le fichier des vues «views.py» dans «repertoire_de_developpement/14_Serveurs/monsitedjango/connexion».
from django.shortcuts import render, redirect
from django.contrib.auth import authenticate, login
from django.contrib.auth.models import User
from connexion.formulaire import FormulaireDeConnexion
def connexion(request):
mauvaisutilisateur = False
mauvaismotdepasse = False
utilisateurexiste = False
if request.method == 'POST':
formulaire = FormulaireDeConnexion(request.POST)
if formulaire.is_valid():
nomutilisateur = formulaire.cleaned_data['utilisateur']
motdepasseutilisateur = formulaire.cleaned_data['motdepasse']
try: # Teste si l'utilisateur est dans la base de données du modèle
User.objects.get(username=nomutilisateur)
utilisateurexiste = True
except User.DoesNotExist:
mauvaisutilisateur = True
if utilisateurexiste:
utilisateur = authenticate(username=nomutilisateur, password=motdepasseutilisateur) # Teste si le nom d'utilisateur et le mot de passe correspondent
if utilisateur:
login(request, utilisateur)
#return redirect('/admin/')
else:
mauvaismotdepasse = True
else:
formulaire = FormulaireDeConnexion()
return render(request, 'connexion.html', locals())
Enfin mettez à jours «urls.py» dans «repertoire_de_developpement/14_Serveurs/monsitedjango/connexion».
from django.urls import path
from . import views
urlpatterns = [
path('connexion/', views.connexion, name='connexion'),
]
Nous avons une erreur lorsque nous nous connectons directement avec l’adresse http://10.10.10.1:5000/. Pour cela nous devrons créer une vue racine avec un module d’application, par exemple ./manage.py startapp appli, importer le décorateur login_required du module django.contrib.auth.decorators, et ajouter @login_required() en début de fonction de vue racine pour renvoyer vers la fenêtre de connexion.
from django.shortcuts import render
from django.http import HttpResponse
from django.contrib.auth.decorators import login_required
@login_required()
def racine(request):
return HttpResponse('Bonjour tout le monde!')
Il faudra en suite éditer le fichier «settings.py» dans «repertoire_de_developpement/14_Serveurs/monsitedjango/monsitedjango», et préciser le lien http de connexion en ajoutant la variable LOGIN_URL.
# URL de connexion
LOGIN_URL = '/connexion/'
INSTALLED_APPS = [
''''''
'connexion',
'appli',
]
Rajouter le lien dans le fichier «urls.py» du module applicatif appli :
from django.urls import path
from . import views
urlpatterns = [
path('', views.racine, name='racine'),
]
Et bien sur rajouter le lien du module applicatif appli dans le fichier «urls.py» du projet.
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('', include('appli.urls')),
path('', include('connexion.urls')),
path('admin/', admin.site.urls),
]
Note
On peut aussi directement préciser le lien avec @login_required(login_url='/autre_système_connexion'), pour éventuellement gérer plusieurs types d’authentifications.
Pour créer un lien de déconnexion, il suffira de créer une fonction de déconnexion dans le fichier «views.py» du module applicatif connexion.
from django.shortcuts import render, redirect
from django.contrib.auth import authenticate, login, logout
from django.contrib.auth.models import User
from connexion.formulaire import FormulaireDeConnexion
''''''
def deconnexion(request):
logout(request)
return redirect('/connexion')
de modifier «urls.py» du module applicatif connexion.
from django.urls import path
from . import views
urlpatterns = [
path('connexion/', views.connexion, name='connexion'),
path('deconnexion/', views.deconnexion, name='deconnexion'),
]
Avec ces exemples, nous venons de voir comment interagir avec le modèle des utilisateurs de Django. Cela nous renvoi aussi sur l’interface d’administration où l’on peut créer des utilisateurs, se déconnecter et plein de choses…
Mais comment créer son propre modèle de données ?
Créer son modèle#
Pour voir comment on utilise les modèles, nous allons étendre le modèle User de Django.
Par défaut nous avons les données ['id', 'password', 'last_login', 'is_superuser', 'username', 'last_name', 'email', 'is_staff', 'is_active', 'date_joined', 'first_name'] pour l’utilisateur. Nous souhaiterions donc un modèle Administratif avec en plus la date de naissance, le sexe, la ville, le code postal, l”adresse et le numéro de téléphone.
Modifions le modèle en éditant «models.py» dans «repertoire_de_developpement/14_Serveurs/monsitedjango/appli».
from django.db import models
from django.contrib.auth.models import User
from django.core.validators import RegexValidator
class Administratif(models.Model):
utilisateur = models.OneToOneField(User, on_delete=models.PROTECT) # Lien avec le modèle User
datenaissance = models.DateField()
SEXES = (
('M', 'Masculin'),
('F', 'Féminin'),
('H', 'Hermaphrodite'),
('I', 'Itersexuation'),
)
sexe = models.CharField('Sexe', max_length=100, choices = SEXES)
ville = models.CharField('Ville', max_length=180)
message_codepostal = 'Le code postal doit-être de la forme 00000'
codepostal_regex = RegexValidator(
regex = r'^[0-9]{5}$',
message = message_codepostal,
)
codepostal = models.CharField('Code postal', validators=[codepostal_regex], max_length=12)
addresse = models.TextField(blank=True)
message_téléphone = 'Le numéro de téléphone saisi doit être de la forme : 0000000000'
téléphone_regex = RegexValidator(
regex = r'^(0|\+33|0033)[1-9][0-9]{8}$'',
message = message_téléphone,
)
telephone = models.CharField(validators=[téléphone_regex], max_length=60, null=True, blank=True)
def __str__(self):
return "Administratif de {0}".format(self.utilisateur.username)
Maintenant nous allons voir à quoi servent les commandes makemigrations et migrate. Ces commande servent à mettre à jours les modèles avec la base de données.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs/monsitedjango$ ./manage.py makemigrations appli
Migrations for 'appli':
appli/migrations/0001_initial.py
- Create model Administratif
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs/monsitedjango$ ./manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, connexion, contenttypes, sessions
Running migrations:
Applying appli.0001_initial... OK
utilisateur@MachineUbuntu:~/repertoire_de_developpement/14_Serveurs/monsitedjango$ ./manage.py runserver
Vérifions cela avec la base de données.
>>> with mabasedjango:
... curseurbd = mabasedjango.cursor()
... curseurbd.execute("SELECT name FROM sqlite_master WHERE type='table';")
... print(curseurbd.fetchall())
... curseurbd.close()
...
<sqlite3.Cursor object at 0x7f57b09a1960>
[('django_migrations',), ('sqlite_sequence',), ('auth_group_permissions',), ('auth_user_groups',), ('auth_user_user_permissions',), ('django_admin_log',), ('django_content_type',), ('auth_permission',), ('auth_group',), ('auth_user',), ('django_session',), ('appli_administratif',)]
>>> with mabasedjango:
... curseurbd = mabasedjango.cursor()
... curseurbd.execute("SELECT * FROM appli_administratif;")
... list(map(lambda x: x[0], curseurbd.description))
... print(curseurbd.fetchall())
... curseurbd.close()
...
<sqlite3.Cursor object at 0x7f57b1a78f10>
['id', 'datenaissance', 'sexe', 'ville', 'codepostal', 'addresse', 'telephone', 'utilisateur_id']
[]
Le modèle Administratif a bien été créé. Mais comment le renseigner ?
Administration#
Pour renseigner le modèle Administratif, nous allons utiliser l’interface d’administration de Django.
Pour cela éditer «admin.py» dans «repertoire_de_developpement/14_Serveurs/monsitedjango/appli».
from django.contrib import admin
from . import models
admin.site.register(models.Administratif)
Rien de plus simple…
Ce qui nous donne :
Le modèle Administratif prend aussi en charge la gestion des erreurs de saisies.
On peut modifier tout modèle de données ainsi déclaré avec l’interface d’administration. Comme pour le modèle système User.
Vous pouvez pousser ce tutoriel sur l’apparence, les tests, les modules Django, les paquets applicatifs, etc avec le tutoriel Django.
Je conseille aussi le site Zeste de savoir.
Générer des documents#
PDF#
Installation#
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo pip install fpdf2
Premiers documents#
Créer le fichier «PremierPDF.py» dans le répertoire «repertoire_de_developpement/15_Documents».
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
from fpdf import FPDF
# Création du contenu PDF
contenupdf = FPDF()
# Ajout d'une page
contenupdf.add_page()
# Police de carractères
contenupdf.set_font('Helvetica', size=15)
# Création d'un cadre texte
contenupdf.cell(200, 10, txt='Cour Python 3 pour l\'administrateur systèmes', ln=1, align='C')
# Ajout d'un autre cadre de texte
contenupdf.cell(200, 10, txt='Création d\'un PDF.', ln=2, align='C')
# Sauvegarde du PDF dans un fichier
contenupdf.output('PremierPDF.pdf')
utilisateur@MachineUbuntu:~/repertoire_de_developpement/15_Documents$ chmod u+x PremierPDF.py
utilisateur@MachineUbuntu:~/repertoire_de_developpement/15_Documents$ ./PremierPDF.py
Transformons maintenant un fichier texte en PDF.
Créer le fichier «texte.txt» dans le répertoire «repertoire_de_developpement/15_Documents».
«Il est certains esprits dont les sombres pensées
sont d'un nuage épais toujours embarrassées;
Le jour de la raison ne le saurait percer.
Avant donc que d'écrire, apprenez à penser.
Selon que notre idée est plus ou moins obscure,
l'expression la suit, ou moins nette ou plus pure.
Ce que l'on conçoit bien s'énonce clairement,
et les mots pour le dire arrivent aisément.»
Boileau, L'Art poétique (1669-1674), Chant premier,
v. 147-154, éd. ULB, p. 52
«Dans un monde où,
avec Google et les moteurs de recherche,
même les mots ont un prix,
l'idéal de liberté,
de démocratie et de gratuité absolue
cache des opérations financières.»
Alain Rey - février 2008, p. 102,
(ISSN 0036-8369), nº 1085
Créer le fichier «SecondPDF.py» dans le répertoire «repertoire_de_developpement/15_Documents».
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
from fpdf import FPDF
# Création du contenu PDF
contenupdf = FPDF()
# Ajout d'une page
contenupdf.add_page()
# Police de carractères
contenupdf.set_font('Helvetica', size=15)
with open('texte.txt', 'r') as fichier:
# Ajout du texte pour le convertir en PDF
for ligne in fichier:
contenupdf.cell(200, 10, txt=ligne, ln=1, align='C')
# Sauvegarde du PDF dans un fichier
contenupdf.output('SecondPDF.pdf')
utilisateur@MachineUbuntu:~/repertoire_de_developpement/15_Documents$ ./SecondPDF.py
Mise en page#
Créer le fichier «pdf-3.py» dans le répertoire «repertoire_de_developpement/15_Documents».
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
import fpdf
# Création du contenu PDF
# Orientation : 'P' pour portrait, 'L' pour paysage.
# format : Format général du document 'A3', 'A4', 'A5', 'letter', 'legal'
# unit : 'mm', 'cm', 'in', 'pt'
contenupdf = fpdf.FPDF(unit='mm')
# Police de carractères
#contenupdf.add_font('Mafonte', '', 'ttf/CooperHewitt-Book.ttf', uni=True)
#contenupdf.add_font('Mafonte', 'I', 'ttf/CooperHewitt-BookItalic.ttf', uni=True)
#contenupdf.add_font('Mafonte', 'B', 'ttf/CooperHewitt-Bold.ttf', uni=True)
#contenupdf.add_font('Mafonte', 'BI', 'ttf/CooperHewitt-BoldItalic.ttf', uni=True)
#contenupdf.add_font('MafonteThin', '', 'ttf/CooperHewitt-Thin.ttf', uni=True)
#contenupdf.add_font('MafonteThin', 'I', 'ttf/CooperHewitt-ThinItalic.ttf', uni=True)
#contenupdf.add_font('MafonteThin', 'B', 'ttf/CooperHewitt-Light.ttf', uni=True)
#contenupdf.add_font('MafonteThin', 'BI', 'ttf/CooperHewitt-LightItalic.ttf', uni=True)
#contenupdf.add_font('MafonteMedium', '', 'ttf/CooperHewitt-Medium.ttf', uni=True)
#contenupdf.add_font('MafonteMedium', 'I', 'ttf/CooperHewitt-MediumItalic.ttf', uni=True)
#contenupdf.add_font('MafonteBold', '', 'ttf/CooperHewitt-Semibold.ttf', uni=True)
#contenupdf.add_font('MafonteBold', 'I', 'ttf/CooperHewitt-SemiboldItalic.ttf', uni=True)
#contenupdf.add_font('MafonteBold', 'B', 'ttf/CooperHewitt-Heavy.ttf', uni=True)
contenupdf.add_font('MafonteBold', 'BI', 'ttf/CooperHewitt-HeavyItalic.ttf', uni=True)
# Options du document
contenupdf.set_compression(True)
contenupdf.set_display_mode('fullpage', 'two')
contenupdf.set_title('Mon PDF de développeur')
contenupdf.set_author('Développeur Python')
contenupdf.set_creator('FPDF Ubuntu')
contenupdf.set_subject('Document de test FPDF généré avec Python')
contenupdf.set_keywords('Python FPDF Ubuntu')
#Pied de page
def footer():
# À 10 mm du bas
contenupdf.set_y(-10)
contenupdf.set_font('Helvetica', 'B', 8)
contenupdf.cell(0, 10, 'Page ' + str(contenupdf.page_no()) + '/{nb}', 0, 0, 'C')
contenupdf.footer = footer
# Ajout d'une page paysage A5
contenupdf.add_page(orientation='L', format='A5')
# Choix police de caractère
contenupdf.set_font('MafonteBold', 'BIU', 15)
contenupdf.set_text_color(150, 150, 150)
# Création d'un cadre texte
contenupdf.cell(200, 10, txt='Cour Python 3 pour l\'administrateur systèmes', ln=1, align='C')
# Affichage des fontes de carractères
taille_police = 8
for fonte in contenupdf.core_fonts:
if any([lettre for lettre in fonte if lettre.isupper()]):
continue
contenupdf.set_font('MafonteBold', 'BIU', 8)
contenupdf.cell(0, 10, txt='Fonte {} - {} pts'.format(fonte, taille_police), ln=1, align='C')
contenupdf.set_font(fonte, size=taille_police)
contenupdf.cell(0, 10, txt='abcdefghijklmnopqrstuvwxyz', ln=1, align='C')
contenupdf.cell(0, 10, txt='ABCDEFGHIJKLMNOPQRSTUVWXYZ', ln=1, align='C')
taille_police += 2
# Ajout nouvelle page portrait A5
contenupdf.add_page(orientation='P', format='A5')
contenupdf.set_font('MafonteBold', 'BIU', 12)
contenupdf.cell(0, 10, txt='UTF-8 : éÉèÈàÀùÙçÇœŒ€±≠¹²³«»…®™←↑→↓', ln=1, align='C')
# Sauvegarde du PDF dans un fichier
contenupdf.output('pdf-3.pdf')
Dessin#
Créer le fichier «pdf-4.py» dans le répertoire «repertoire_de_developpement/15_Documents».
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
from fpdf import FPDF
# Création du contenu PDF
# Orientation : 'P' pour portrait, 'L' pour paysage.
contenupdf = FPDF(orientation='L', unit='mm', format='A4')
# Ajout d'une page
contenupdf.add_page()
# Couleur du dessin
contenupdf.set_draw_color(139, 0, 0)
# Épaisseur du trait
contenupdf.set_line_width(1)
# Tracé d'une ligne
contenupdf.line(10, 10, 100, 100)
# Tracé d'un rectangle
contenupdf.set_draw_color(255, 0, 0)
contenupdf.set_fill_color(210, 105, 30)
contenupdf.rect(20, 20, 60, 60, 'F')
# Tracé d'une ellipse
contenupdf.set_draw_color(0, 255, 0)
contenupdf.set_fill_color(255, 140, 0)
contenupdf.ellipse(30, 30, 40, 40, 'F')
# Ajout d'une image
contenupdf.image('images/graph1.png', x=120, y=30, w=150)
# Sauvegarde du PDF dans un fichier
contenupdf.output('pdf-4.pdf')
Tableaux#
Créer le fichier «pdf-5.py» dans le répertoire «repertoire_de_developpement/15_Documents».
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
from fpdf import FPDF
données = [['Prénom', 'NOM', 'Age'],
['Moi', 'EGAUCENTRE', '25'],
['Lui', 'VECU', '35'],
['Sage', 'EXPERIENCE', '45']]
# Création du contenu PDF
contenupdf = FPDF()
# Ajout d'une page
contenupdf.add_page()
# Police de carractères
contenupdf.set_font('Helvetica', size=15)
largeur_col = contenupdf.w / 4.5
hauteur_lin = contenupdf.font_size
for ligne in données:
for element in ligne:
contenupdf.cell(largeur_col, hauteur_lin * 2, txt=element, border=1, align='C')
contenupdf.ln(hauteur_lin * 2)
# Sauvegarde du PDF dans un fichier
contenupdf.output('Tableau.pdf')
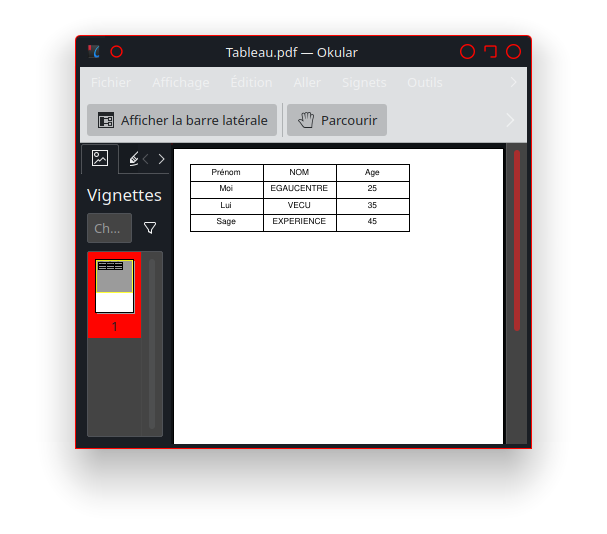
HTML vers PDF#
Créer le fichier «pdf-6.py» dans le répertoire «repertoire_de_developpement/15_Documents».
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
from fpdf import FPDF, HTMLMixin
class HTMLtoPDF(FPDF, HTMLMixin):
pass
# Création du contenu PDF
contenupdf = HTMLtoPDF()
# Ajout d'une page
contenupdf.add_page()
# Police de carractères
contenupdf.write_html('''
<!DOCTYPE html>
<html>
<head>
<style>.article {
background-color: black;
color: white;
padding: 20px;
}</style>
</head>
<body>
<h2>Mon site</h2>
<p>Utilisation des styles CSS avec la classe "article" dans un tag HTML :</p>
<div class="artivle">
<h2>Mon titre</h2>
<p>Texte de l'article.</p>
<p>Encore du texte.</p>
</div>
</body>
</html>
''')
# Sauvegarde du PDF dans un fichier
contenupdf.output('HTML.pdf')
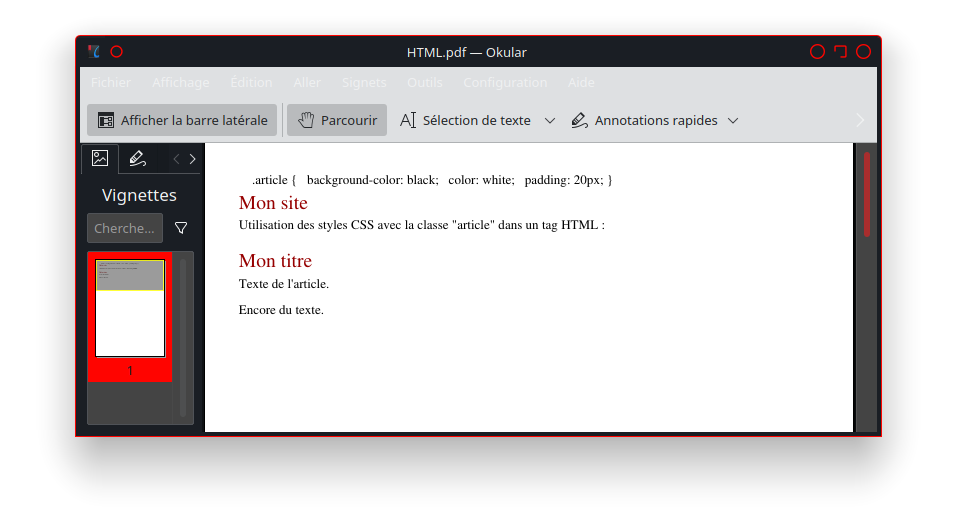
On peut voir que le CSS du HTML n’est pas converti. Mais la structure HTML est mise en page :-).
Si nous voulons des mises en pages plus complexes, il est préférable d’utiliser du xsl-fo ou du LaTeX sous peine de faire de la PAO/DAO avec votre code.
XSL-FO#
Même si beaucoup de développeur estiment que le langage XSL-FO est dépassé par le HTML5, il peut être très confortable pour fabriquer des interfaces sécurisées sur la modification du contenu des données, tout en permettant de générer des documentations PDF d’archivage ou des mises à jour avec la dernière charte graphique.
En plus nous avons un générateur (parser) de document open source fop pour créer ces documents à partir d’un fichier XML. Nous pouvons aussi utiliser une feuille de style XSLT (fo2html.xsl) et du css pour transformer les données XML en affichage HTML.
Et dans le meilleur des mondes qu’est Python, nous avons même un module pour générer des documents PDF à partir de la mise en page XSL-FO.
Installation#
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo apt install fop
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo pip install pypfop==1.0a1
Générer un PDF#
Créer le fichier «bonjouràtous.fo.mako» dans le répertoire «repertoire_de_developpement/15_Documents».
<%inherit file="A4-portrait.fo.mako" />
<block>Bonjour ${nom}!</block>
>>> import os
>>> from pypfop import generate_document
>>> chemin_pdf = generate_document('bonjouràtous.fo.mako', {'nom': 'Programmeur PYTHON'})
>>> chemin_pdf
'/tmp/tmpon_o8chz.pdf'
>>> chemin_pdf = generate_document('bonjouràtous.fo.mako', {'nom': 'Programmeur PYTHON'}, tempdir='.')
>>> chemin_pdf
'/home/utilisateur/repertoire_de_developpement/15_Documents/tmpsbjw0mbg.pdf'
>>> os.rename(chemin_pdf, os.path.join(os.path.dirname(chemin_pdf), 'fop.pdf'))
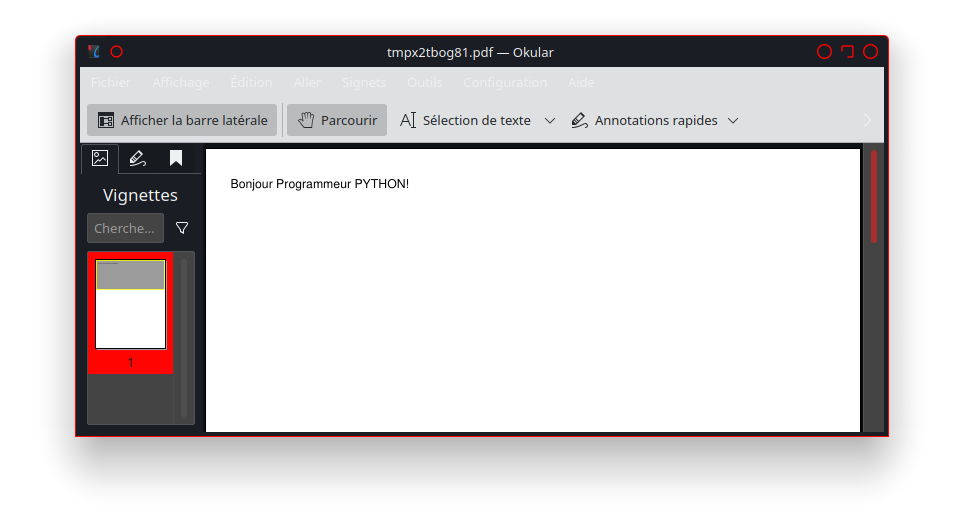
Nous venons de voir qu’il est assez facile de créer un document PDF avec Python et FOP. Mais ce qui est intéressent avec le xsl-fo, c’est que l’on peut séparer le contenu, la structure rédactionnelle, la mise en page et le rendu de sortie.
Mais ici, nous allons ne contenter du processus suivant :
modèle xml de structure rédactionnelle avec paramètres -> transformation Python mako des paramètres -> mise en forme css -> résultat xsl-fo -> rendu parser FOP -> Document généré
Modèle XSL-FO#
Créer le fichier «tableau.fo.mako» dans le répertoire «repertoire_de_developpement/15_Documents».
<%inherit file="A4-portrait.fo.mako" />
<table id="table-principale">
<table-header>
<table-row>
% for nom in entete:
<table-cell>
<block>${nom}</block>
</table-cell>
% endfor
</table-row>
</table-header>
<table-body>
% for ligne in lignes:
<table-row>
% for cellule in ligne:
<table-cell>
<block>${cellule}</block>
</table-cell>
% endfor
</table-row>
% endfor
</table-body>
</table>
Créer le fichier «tableau.css» dans le répertoire «repertoire_de_developpement/15_Documents».
@import url("base.css");
@import url("couleurs.css");
#table-principale > table-header > table-row{
text-align: center;
font-weight: bold;
}
#table-principale > table-header table-cell{
padding: 2mm 0 0mm;
}
Créer le fichier «base.css» dans le répertoire «repertoire_de_developpement/15_Documents».
flow[flow-name="xsl-region-body"] {
font-size: 10pt;
font-family: Helvetica;
}
Créer le fichier «couleurs.css» dans le répertoire «repertoire_de_developpement/15_Documents».
#table-principale > table-body > table-row > table-cell:first-child{
color: red;
}
#table-principale > table-body > table-row > table-cell:nth-child(2){
color: green;
}
#table-principale > table-body > table-row > table-cell:nth-child(3){
color: blue;
}
#table-principale > table-body > table-row > table-cell:last-child{
color: purple;
}
Créer le fichier «tableau-xsl-fo.py» dans le répertoire «repertoire_de_developpement/15_Documents».
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
import os, pypfop
format_de_fichier = 'pdf' # 'pdf', 'rtf', 'tiff', 'png', 'pcl', 'ps', 'txt'
donnees = {
'entete': ['Nom', 'Prénom', 'Age', 'Sexe'],
'lignes': [
('PYTHON', 'Programmeur', 25, 'M'),
('ANONYME', 'Personne', 30, 'F'),
('INCONNU', 'Utilisateur', 43, 'H')
]
}
chemin_document = pypfop.generate_document('tableau.fo.mako', donnees, 'tableau.css', tempdir='.', out_format=format_de_fichier)
os.rename(chemin_document, os.path.join(os.path.dirname(chemin_document), 'tableau-xsl-fo.pdf'))
Nous voyons que le fichier est rendu suivant la configuration des fichiers css.
WeasyPrint#
Bon, vous ne voulez vraiment pas de xsl-fo parce qu’il est soit disant dépassé par HTML5. Et vous voulez rendre les fichiers CSS3 dans vos PDF. Il vous reste la solution WeasyPrint.
Installation#
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo pip install weasyprint
Conversion directe#
Créer le fichier «exemple.html» dans le répertoire «repertoire_de_developpement/15_Documents».
<!DOCTYPE html>
<html lang="fr">
<head>
<title>Modèle CSS</title>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<style>
* {
box-sizing: border-box;
}
body {
font-family: Arial, Helvetica, sans-serif;
}
.en-tête {
background-color: #f1f1f1;
padding: 30px;
text-align: center;
font-size: 35px;
}
.colonne {
float: left;
padding: 10px;
height: 300px; /* Should be removed. Only for demonstration */
}
.colonne.coté {
width: 25%;
}
.colonne.milieu {
width: 50%;
}
.ligne:after {
content: "";
display: table;
clear: both;
}
.pie-de-page {
background-color: #f1f1f1;
padding: 10px;
text-align: center;
}
@media (max-width: 600px) {
.colonne.coté, .colonne.milieu {
width: 100%;
}
}
</style>
</head>
<body>
<h2>Exemple de ducument HTML avec du CSS</h2>
<p>Ce texte est là pour tester un rendu PDF d'un document HTML avec une mise en page CSS.</p>
<p>Ce document quand il est ouvert avec un navigateur peut modifier son apparence.</p>
<div class="en-tête">
<h2>En-tête</h2>
</div>
<div class="ligne">
<div class="colonne coté" style="background-color:#aaa;">Colonne de gauche</div>
<div class="colonne milieu" style="background-color:#bbb;">Colonne centrale</div>
<div class="colonne coté" style="background-color:#ccc;">Colonne de droite</div>
</div>
<div class="pied-de-page">
<p>Pied de page</p>
</div>
</body>
</html>
utilisateur@MachineUbuntu:~/repertoire_de_developpement/15_Documents$ weasyprint exemple.html weasyprint_exemple_direct.pdf
WARNING: Expected a media type, got '(max-width: 600px)'
WARNING: Invalid media type ' (max-width: 600px) ' the whole @media rule was ignored at 43:1.
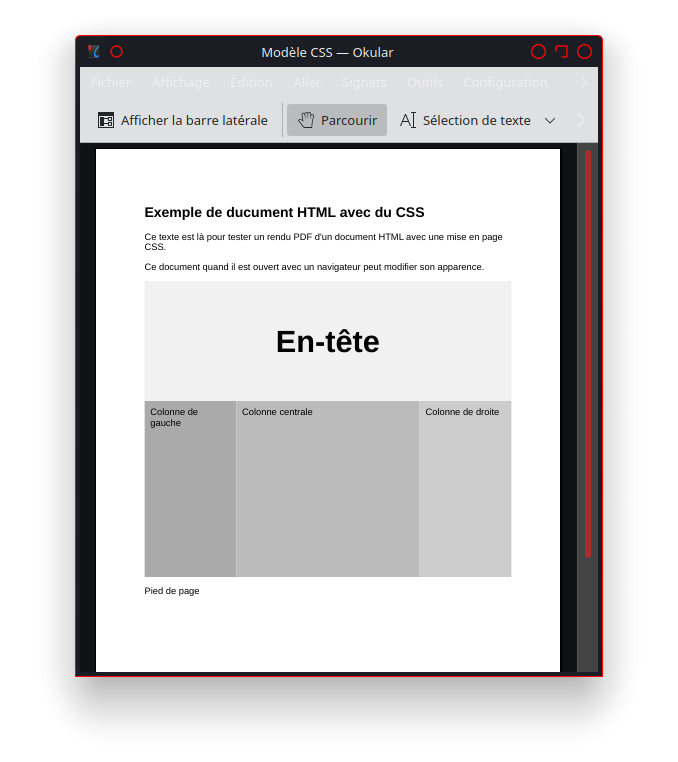
Code#
Créer le fichier «createpdf.py» dans le répertoire «repertoire_de_developpement/15_Documents».
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
from weasyprint import HTML
document_html = HTML(filename='exemple.html')
document_html.write_pdf('weasyprint_exemple_code.pdf')
LaTeX vers PDF#
Oui tout cela est bien jolie, nous avons généré un rendu WEB en PDF. Mais si on veut passer à la gamme au dessus, pour avoir un vrai rendu/gestion PAO, on peut utiliser LaTeX.
LaTeX est un outil de WYSIMING. Donc les documents sont construit suivant ce que vous pensez, et non pas ce que vous voyez, mais vous êtes sûr d’avoir un rendu PAO. La structure des documents LaTeX est la suivante :
Classe de document (fichier .class) qui définit la PAO de base du document -> les extensions du document qui définissent la mise en forme du texte ou la mise en page (fichiers .sty) -> le contenu du document.
Pour l’élaboration d’une classe ou d’une extension de document LaTeX, je vous renvoie vers Extensions et classes du site de Gutenberg Europe.
Pour affiner le développement TeX lire Apprendre à programmer en TeX
Nous allons ici utiliser le module Python Pylatex pour gérer le rendu PDF avec des documents LaTeX.
Installation#
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo pat install fonts-linuxlibertine
utilisateur@MachineUbuntu:~/repertoire_de_developpement$ sudo pip install pylatex
Utilisation#
Créer le fichier «latex2pdf.py» dans le répertoire «repertoire_de_developpement/15_Documents».
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
from pylatex import Command, Package, Document, Section, Subsection, Tabular, TextColor
from pylatex.utils import italic, bold, NoEscape
from pylatex import Math
options_mise_en_page = {'tmargin': '1cm', 'lmargin': '10cm'}
document = Document(geometry_options=options_mise_en_page, fontenc=None, inputenc=None)
document.documentclass = Command('documentclass', options=['a4paper', 'landscape', '12pt'], arguments=['article'])
document.packages.append(Package('babel', 'french'))
#document.packages.append(Package('french'))
document.preamble.append(Command('selectlanguage', 'french'))
document.preamble.append(Command('title', NoEscape(r'\color{red}Le titre de mon document\color{black}')))
document.preamble.append(Command('author', 'Programmeur PYTHON'))
document.preamble.append(Command('date', NoEscape(r'\today')))
document.append(NoEscape(r'\maketitle'))
with document.create(Section('La section de mon document')):
document.append('Une phrase comme ça… \n')
document.append(italic('Du texte italique.'))
document.append(bold('Du texte en gras.\n'))
document.append(TextColor('violet', bold('Gras et en violet.\n')))
document.append('Des caractères spéciaux : àÀéÉèÈçÇûÛùÙœŒ±≠×÷€$£µ…¿¡§¹²³™©\n')
document.append('Une phrase "entre guillemets". «ou ici» l\'apostrophe, fi.')
with document.create(Subsection(NoEscape(r'\color{gray}Les mathématiques\color{black}'))):
document.append(Math(data=['3*3', '=', 9]))
with document.create(Subsection(NoEscape(r'\color{gray}Un tableau\color{black}'))):
with document.create(Tabular('rc|cl')) as tableau:
tableau.add_hline()
tableau.add_row((TextColor('teal', 'C1'), TextColor('orange', 'C2'), 'C3', 'C4'))
tableau.add_hline(1, 2)
tableau.add_empty_row()
tableau.add_row(('C5', 'C6', 'C7', 'C8'))
document.generate_pdf('latex', clean_tex=False, compiler='xelatex')
Graphiques#
Créer le fichier «graphiques2pdf.py» dans le répertoire «repertoire_de_developpement/15_Documents».
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
import os
from pylatex import Command, Package, Document, Section, Subsection, TextColor
from pylatex.utils import italic, bold, NoEscape
from pylatex import Math, TikZ, Figure, Axis, Plot, TikZNode, TikZOptions, TikZCoordinate, TikZDraw, TikZUserPath
options_mise_en_page = {'tmargin': '1cm', 'lmargin': '3cm'}
document = Document(geometry_options=options_mise_en_page, fontenc=None, inputenc=None)
document.documentclass = Command('documentclass', options=['a4paper', '10pt'], arguments=['article'])
document.packages.append(Package('xcolor'))
document.packages.append(Package('babel', 'french'))
#document.packages.append(Package('french'))
document.preamble.append(Command('selectlanguage', 'french'))
document.preamble.append(Command('title', NoEscape(r'\color{red}Des graphiques\color{black}')))
document.preamble.append(Command('author', 'Programmeur PYTHON'))
document.preamble.append(Command('date', NoEscape(r'\today')))
document.append(NoEscape(r'\maketitle'))
with document.create(Section(NoEscape(r'\color{gray}Les graphiques\color{black}'))):
with document.create(Subsection(NoEscape(r'\color{teal}Une image\color{black}'))):
with document.create(Figure(position='h!')) as image:
image.add_image(os.path.abspath('./images/graph1.png'), width='360pt')
image.add_caption('Une image')
with document.create(Subsection(NoEscape(r'\color{teal}Une courbe\color{black}'))):
with document.create(TikZ()):
options_de_trace = 'height=8cm, width=12cm, grid=major, domain=0.001:10'
with document.create(Axis(options=options_de_trace)) as graphe:
graphe.append(Plot(name='Courbe', func='sin(deg(x))/x', options=['samples=200', 'patch type=quadratic spline', 'blue', 'mark=None']))
coordonees = [(0.0, 1.0), (1.0, 0.85), (2.0, 0.45), (3.0, 0.05), (4.0, -0.2), (5.0, -0.2), (6.0, -0.05), (7.0, 0.1), (8.0, 0.10), (9.0, 0.05), (10.0, -0.05)]
graphe.append(Plot(name='Mesures', coordinates=coordonees, options=['only marks', 'red', 'mark=x']))
with document.create(Subsection(NoEscape(r'\color{teal}Un diagramme\color{black}'))):
with document.create(TikZ()) as diagramme:
noderond_kwargs = {'draw': 'green!60', 'fill': 'green!5', 'minimum size': '7mm'}
noeud_rond = TikZOptions('circle','very thick', **noderond_kwargs)
nodecarre_kwargs = {'draw': 'red!60', 'fill': 'red!5', 'minimum size': '5mm'}
noeud_carre = TikZOptions('rectangle','very thick', **nodecarre_kwargs)
position_noeud1 = TikZCoordinate(0, 2)
noeud1 = TikZNode(text='1', handle='node1', options=noeud_rond, at=position_noeud1)
position_noeud2 = TikZCoordinate(0, 1)
noeud2 = TikZNode(text='2', handle='node2', options=noeud_carre, at=position_noeud2)
position_noeud3 = TikZCoordinate(1, 1)
noeud3 = TikZNode(text='3', handle='node3', options=noeud_carre, at=position_noeud3)
position_noeud4 = TikZCoordinate(0, 0)
noeud4 = TikZNode(text='4', handle='node4', options=noeud_rond, at=position_noeud4)
diagramme.append(noeud1)
diagramme.append(noeud2)
diagramme.append(noeud3)
diagramme.append(noeud4)
diagramme.append(TikZDraw([noeud1.south, '--', noeud2.north], options=TikZOptions('->')))
diagramme.append(TikZDraw([noeud2.east, '--', noeud3.west], options=TikZOptions('->')))
diagramme.append(TikZDraw([noeud3.south, TikZUserPath('.. controls +(down:7mm) and +(right:7mm) ..'), noeud4.east], options=TikZOptions('->')))
document.generate_pdf('graphiques', clean_tex=False, compiler='xelatex')
Opendocument#
Installation#
utilisateur@MachineUbuntu:~/repertoire_de_developpement/15_Documents$ sudo pip install odfpy
Pour visualiser les documents générés nous installons libre office.
utilisateur@MachineUbuntu:~/repertoire_de_developpement/15_Documents$ sudo apt install libreoffice
Générer des documents textes#
Éditer «OpenDocumentText.py»
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
from odf.opendocument import OpenDocumentText
from odf.style import PageLayout, MasterPage, Footer, Style, TextProperties, ParagraphProperties, TableProperties, TableColumnProperties
from odf.text import H, P, Span
from odf.table import Table, TableColumn, TableRow, TableCell
document_texte = OpenDocumentText()
# Mise en page
mise_en_page = PageLayout(name='Mise en page')
document_texte.automaticstyles.addElement(mise_en_page)
page_principale = MasterPage(name='Standard', pagelayoutname=mise_en_page)
document_texte.masterstyles.addElement(page_principale)
# Styles
style = document_texte.styles
# Création d'un style
style_de_titre = Style(name='Titre principal', parentstylename='Standard', family='paragraph')
style_de_titre.addElement(TextProperties(attributes={'fontsize':'24pt', 'fontweight':'bold'}))
style.addElement(style_de_titre)
# Un style automatique
style_gras = Style(name='Texte en Gras', family='text')
en_gras = TextProperties(fontweight='bold')
style_gras.addElement(en_gras)
document_texte.automaticstyles.addElement(style_gras)
# Un tableau
contenu_tableau = Style(name='Contenu tableau', family='paragraph')
contenu_tableau.addElement(ParagraphProperties(numberlines='false', linenumber='0'))
style.addElement(contenu_tableau)
# Styles automatiques du tableau
pagination_tableau = Style(name='Pagination tableau', family='table')
pagination_tableau.addElement(TableProperties(width='10cm', align='center'))
document_texte.automaticstyles.addElement(pagination_tableau)
colonne1 = Style(name='Colonne de gauche', family='table-column')
colonne1.addElement(TableColumnProperties(columnwidth='2cm'))
document_texte.automaticstyles.addElement(colonne1)
colonne2 = Style(name='Colonne de droite', family='table-column')
colonne2.addElement(TableColumnProperties(columnwidth='8cm'))
document_texte.automaticstyles.addElement(colonne2)
# Un paragraphe avec un saut de page
saut_de_page = Style(name='Saut de page', parentstylename='Standard', family='paragraph')
saut_de_page.addElement(ParagraphProperties(breakbefore='page'))
document_texte.automaticstyles.addElement(saut_de_page)
# Titre de document
ligne_de_titre = H(outlinelevel=1, stylename=style_de_titre, text="Mon titre de document")
document_texte.text.addElement(ligne_de_titre)
# Texte
paragraphe1 = P(text="Bonjour à tous!")
document_texte.text.addElement(paragraphe1)
paragraphe2 = P(text="")
section_en_gras = Span(stylename=style_gras, text="Ceci est un passage en gras.")
paragraphe2.addElement(section_en_gras)
paragraphe2.addText(" Ceci est après la section en gras.")
document_texte.text.addElement(paragraphe2)
# Tableau
tableau = Table(name='Tableau_Python3', stylename='Pagination tableau')
tableau.addElement(TableColumn(numbercolumnsrepeated=1, stylename='colonne1'))
tableau.addElement(TableColumn(numbercolumnsrepeated=1, stylename='colonne2'))
ligne1_tableau = TableRow()
cellule1 = TableCell(stylename='colonne1')
ligne1_tableau.addElement(cellule1)
cellule2 = TableCell(stylename='colonne2')
ligne1_tableau.addElement(cellule2)
tableau.addElement(ligne1_tableau)
ligne2_tableau = TableRow()
tableau.addElement(ligne2_tableau)
cellule3 = TableCell(stylename='colonne1')
ligne2_tableau.addElement(cellule3)
cellule4 = TableCell(stylename='colonne2')
ligne2_tableau.addElement(cellule4)
cellule1.addElement(P(stylename=contenu_tableau, text="Colonne 1"))
cellule2.addElement(P(stylename=contenu_tableau, text="Colonne 2"))
cellule3.addElement(P(stylename=contenu_tableau, text="Contenu 1"))
cellule4.addElement(P(stylename=contenu_tableau, text="Contenu 2"))
document_texte.text.addElement(tableau)
# Saut de page
paragraphe3 = P(stylename=saut_de_page, text='Texte de deuxième page')
document_texte.text.addElement(paragraphe3)
document_texte.save('monpremierdocument.odt')
Générer des documents classeur#
Éditer «OpenDocumentCalc.py»
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
from odf.opendocument import OpenDocumentSpreadsheet
from odf.style import Style, TextProperties, ParagraphProperties, TableColumnProperties, TableCellProperties, Map
from odf.number import NumberStyle, CurrencyStyle, CurrencySymbol, Number, Text
from odf.text import P
from odf.table import Table, TableColumn, TableRow, TableCell
classeur = OpenDocumentSpreadsheet()
# Création des styles du tableau
style_contenu_classeur = Style(name='argent', family='table-cell')
style_contenu_classeur.addElement(TableCellProperties(textalignsource='fix', repeatcontent='false', verticalalign='middle', border='1.0pt solid #808080'))
style_contenu_classeur.addElement(ParagraphProperties(textalign='center'))
style_contenu_classeur.addElement(TextProperties(fontfamily='Noto Sans', fontsize='15pt'))
classeur.styles.addElement(style_contenu_classeur)
# Style automatiques
# Colonne tableurs
style_colonne = Style(name='colonne1', family='table-column')
style_colonne.addElement(TableColumnProperties(columnwidth='5.0cm', breakbefore='auto'))
classeur.automaticstyles.addElement(style_colonne)
# Style cellules
# Création du style de valeur monétaire financière français euro négative
style_euro_negatif = CurrencyStyle(name='monnaie-euro-negative', volatile='true')
# Change la couleur du texte en rouge
style_euro_negatif.addElement(TextProperties(color='#ff0000'))
# Préfixe le texte avec le symbole négatif
style_euro_negatif.addElement(Text(text=u'-'))
# Met la valeur numérique en forme avec deux décimales après la virgule, avec au minimum 1 digit et en séparant les milliers
style_euro_negatif.addElement(Number(decimalplaces='2', minintegerdigits='1', grouping='true'))
# afficher le synmbole €
style_euro_negatif.addElement(CurrencySymbol(language='fr', country='FR', text=u' €'))
# Ajout du style
classeur.styles.addElement(style_euro_negatif)
# Création du style de valeur monétaire financière français euro
style_euro = CurrencyStyle(name='monnaie-euro')
# Met la valeur numérique en forme avec deux décimales après la virgule, avec au minimum 1 digit et en séparant les milliers
style_euro.addElement(Number(decimalplaces='2', minintegerdigits='1', grouping='true'))
# formatage conditionnel si négatif afficher le style négatif
style_euro.addElement(Map(condition='value()<0', applystylename='monnaie-euro-negative'))
# Afficher le symbole € à la fin
style_euro.addElement(CurrencySymbol(language='fr', country='FR', text=u' €'))
# Ajout du style
classeur.styles.addElement(style_euro)
# Création du style monétaire de cellule
style_monetaire = Style(name="monnaie", family="table-cell", parentstylename=style_contenu_classeur, datastylename="monnaie-euro")
classeur.automaticstyles.addElement(style_monetaire)
# Création d'un tableau de données monétaires
tableau = Table(name='Tableau de valeurs monétaires')
tableau.addElement(TableColumn(stylename=style_colonne, defaultcellstylename='monnaie'))
ligne1 = TableRow()
tableau.addElement(ligne1)
cellule1 = TableCell(valuetype='currency', currency='EUR', value="-1025.25")
ligne1.addElement(cellule1)
ligne2 = TableRow()
tableau.addElement(ligne2)
cellule2 = TableCell(valuetype="currency", currency="EUR", value="5000023.8")
ligne2.addElement(cellule2)
ligne3 = TableRow()
tableau.addElement(ligne3)
cellule3 = TableCell(valuetype='currency', currency='EUR', value="10089")
ligne3.addElement(cellule3)
ligne4 = TableRow()
tableau.addElement(ligne4)
cellule4 = TableCell(valuetype='currency', currency='EUR', value="-10")
ligne4.addElement(cellule4)
classeur.spreadsheet.addElement(tableau)
#print(classeur.contentxml())
classeur.save("monpremiertableur.ods")
Approfondir ce cour#
Faire ce tutoriel pour approfondir l’initiation à Python3 et parfaire son savoir faire.
Vous pouvez profiter aussi, comme complément à ce cour, du cour Apprendre à programmer avec Python et de son module avancé Notions de Python avancées.